
本課時我們重點剖析 JVM 的垃圾回收機制。關于 JVM 垃圾回收機制面試中主要涉及這三個考題:
* JVM 中有哪些垃圾回收算法?它們各自有什么優劣?
* CMS 垃圾回收器是怎么工作的?有哪些階段?
* 服務卡頓的元兇到底是誰?
雖然 Java 不用“手動管理”內存回收,代碼寫起來很順暢。但是你有沒有想過,這些內存是怎么被回收的?
其實,JVM 是有專門的線程在做這件事情。當我們的內存空間達到一定條件時,會自動觸發。這個過程就叫作 GC,負責 GC 的組件,就叫作垃圾回收器。
JVM 規范并沒有規定垃圾回收器怎么實現,它只需要保證不要把正在使用的對象給回收掉就可以。在現在的服務器環境中,經常被使用的垃圾回收器有 CMS 和 G1,但 JVM 還有其他幾個常見的垃圾回收器。
按照語義上的意思,垃圾回收,首先就需要找到這些垃圾,然后回收掉。但是 GC 過程正好相反,它是先找到活躍的對象,然后把其他不活躍的對象判定為垃圾,然后刪除。所以垃圾回收只與活躍的對象有關,和堆的大小無關。這個概念是我們一直在強調的,你一定要牢記。
本課時將首先介紹幾種非常重要的回收算法,然后著重介紹分代垃圾回收的內存劃分和 GC 過程,最后介紹當前 JVM 中的幾種常見垃圾回收器。
這部分內容比較多,也比較細。為了知識的連貫性,這里我直接將它們放在一個課時。篇幅有點長,你一定要有耐心學完,也希望你可以對 JVM 的了解上一個檔次。
為什么這部分這么重要呢?是因為幾乎所有的垃圾回收器,都是在這些基本思想上演化出來的,如果你對此不熟悉,那么我們后面講解 CMS、G1、ZGC 的時候,就會有諸多障礙。這將直接影響到我們對實踐課的理解。
#### 標記(Mark)
垃圾回收的第一步,就是找出活躍的對象。我們反復強調 GC 過程是逆向的。
我們在前面的課時談到 GC Roots。根據 GC Roots 遍歷所有的可達對象,這個過程,就叫作標記。
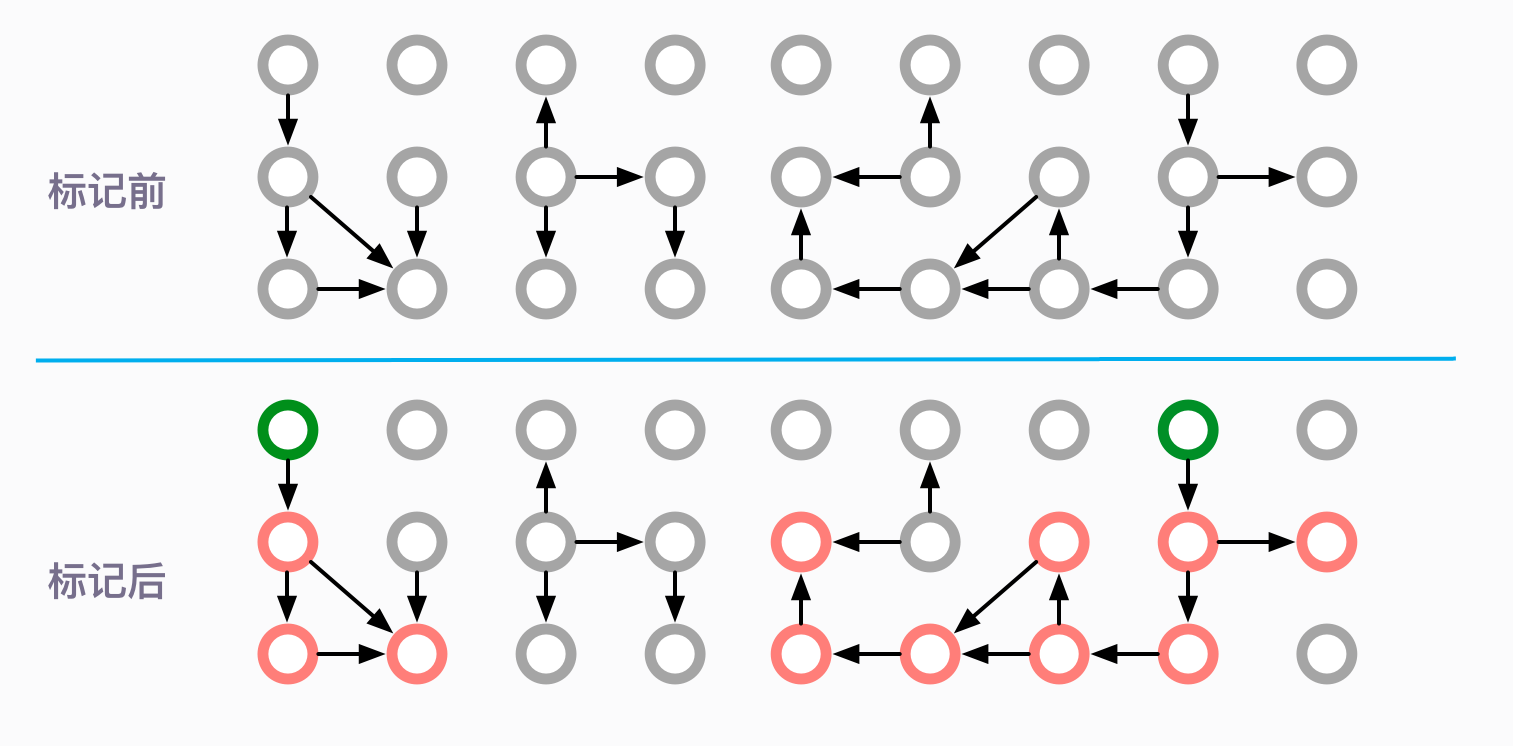
如圖所示,圓圈代表的是對象。綠色的代表 GC Roots,紅色的代表可以追溯到的對象。可以看到標記之后,仍然有多個灰色的圓圈,它們都是被回收的對象。
#### 清除(Sweep)
清除階段就是把未被標記的對象回收掉。
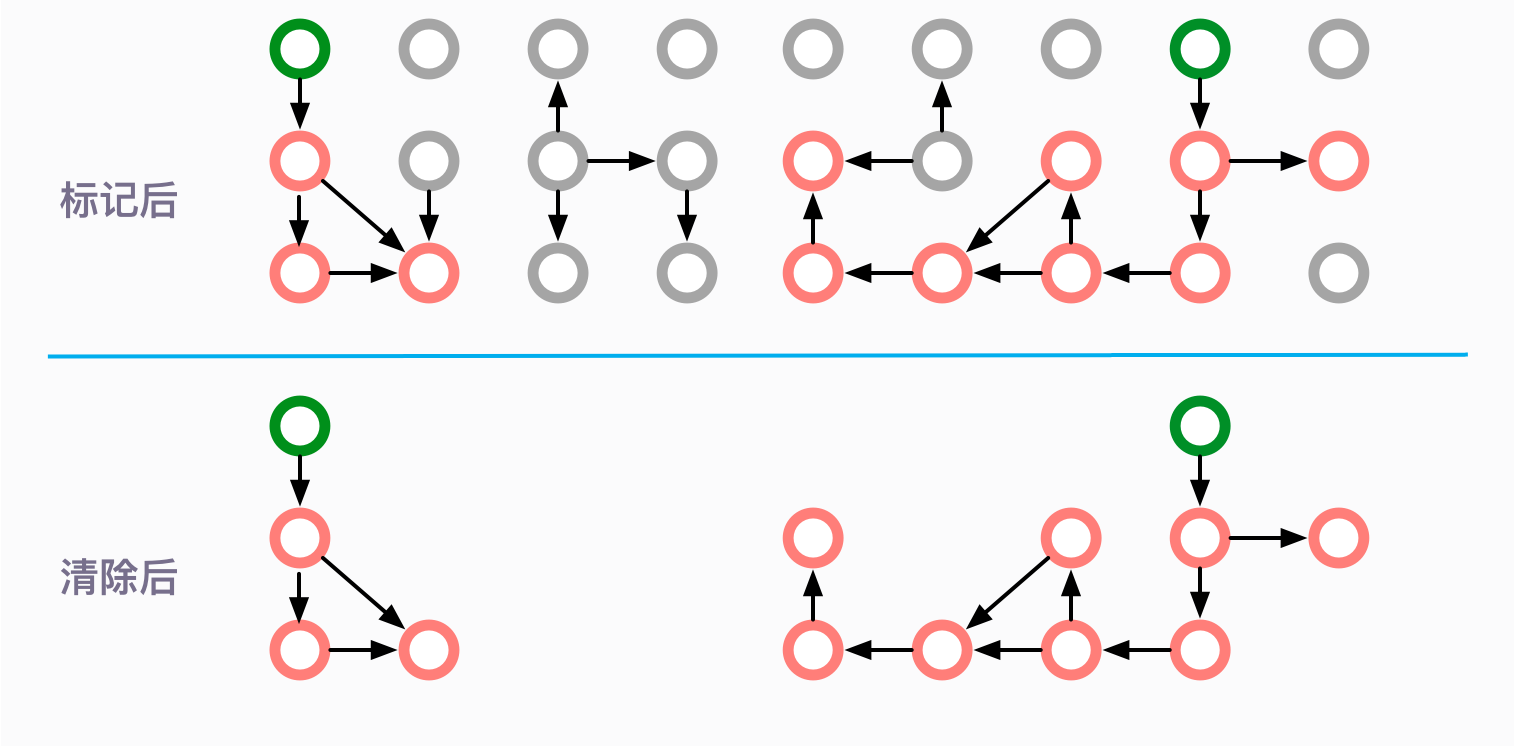
但是這種簡單的清除方式,有一個明顯的弊端,那就是碎片問題。
比如我申請了 1k、2k、3k、4k、5k 的內存。

由于某種原因 ,2k 和 4k 的內存,我不再使用,就需要交給垃圾回收器回收。

這個時候,我應該有足足 6k 的空閑空間。接下來,我打算申請另外一個 5k 的空間,結果系統告訴我內存不足了。系統運行時間越長,這種碎片就越多。
在很久之前使用 Windows 系統時,有一個非常有用的功能,就是內存整理和磁盤整理,運行之后有可能會顯著提高系統性能。這個出發點是一樣的。
#### 復制(Copy)
解決碎片問題沒有銀彈,只有老老實實的進行內存整理。
有一個比較好的思路可以完成這個整理過程,就是提供一個對等的內存空間,將存活的對象復制過去,然后清除原內存空間。
在程序設計中,一般遇到擴縮容或者碎片整理問題時,復制算法都是非常有效的。比如:HashMap 的擴容也是使用同樣的思路,Redis 的 rehash 也是類似的。
整個過程如圖所示:
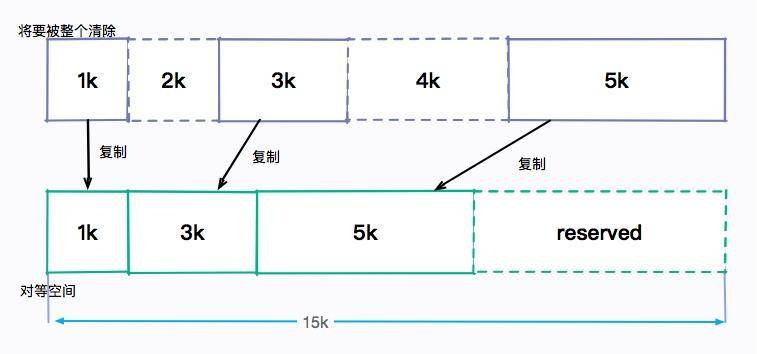
這種方式看似非常完美的,解決了碎片問題。但是,它的弊端也非常明顯。它浪費了幾乎一半的內存空間來做這個事情,如果資源本來就很有限,這就是一種無法容忍的浪費。
#### 整理(Compact)
其實,不用分配一個對等的額外空間,也是可以完成內存的整理工作。
你可以把內存想象成一個非常大的數組,根據隨機的 index 刪除了一些數據。那么對整個數組的清理,其實是不需要另外一個數組來進行支持的,使用程序就可以實現。
它的主要思路,就是移動所有存活的對象,且按照內存地址順序依次排列,然后將末端內存地址以后的內存全部回收。
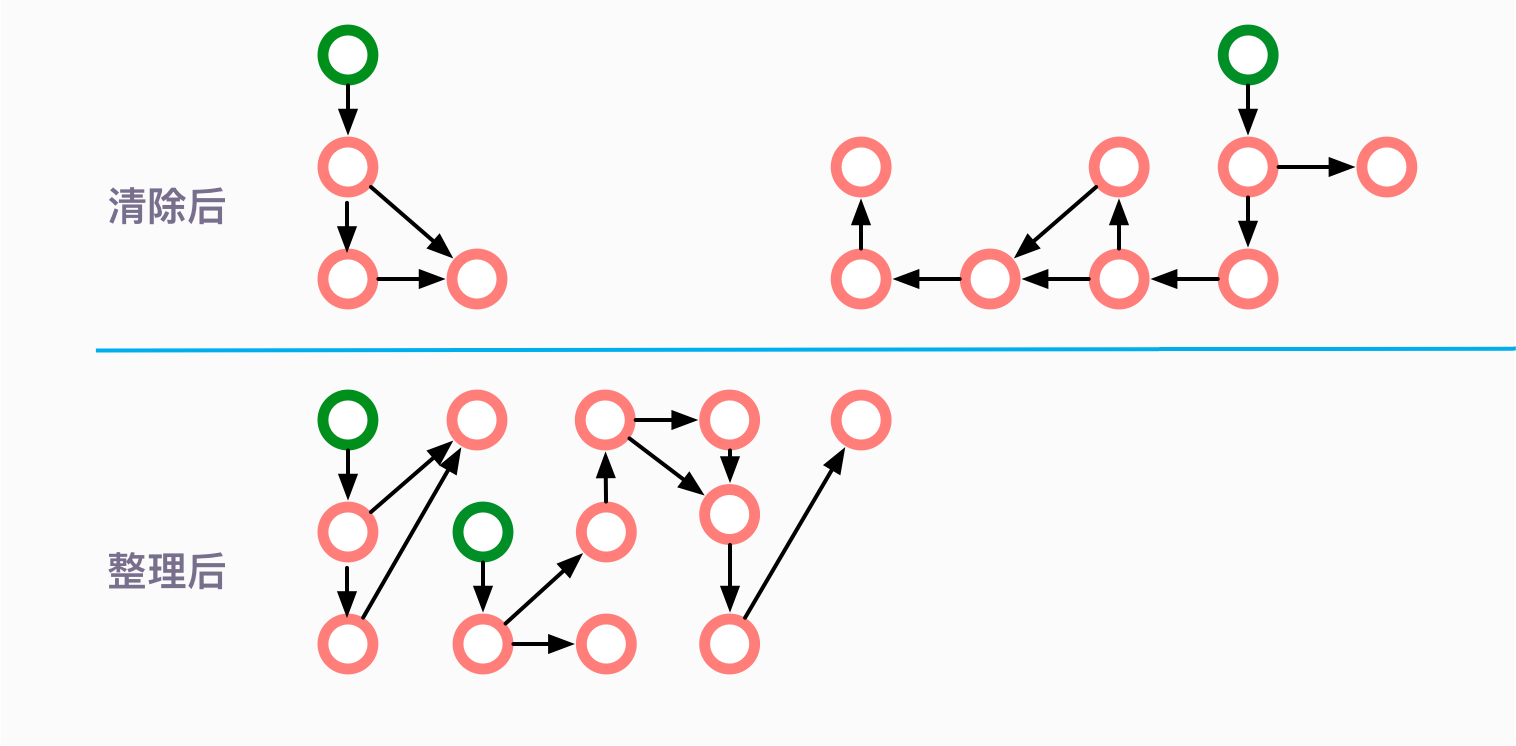
我們可以用一個理想的算法來看一下這個過程。
```
last = 0
for(i=0;i<mems.length;i++){
if(mems[i] != null){
mems[last++] = mems[i]
changeReference(mems[last])
}
}
clear(mems,last,mems.length)
```
但是需要注意,這只是一個理想狀態。對象的引用關系一般都是非常復雜的,我們這里不對具體的算法進行描述。你只需要了解,從效率上來說,一般整理算法是要低于復制算法的。
#### 分代
我們簡要介紹了一些常見的內存回收算法,目前,JVM 的垃圾回收器,都是對幾種樸素算法的發揚光大。簡單看一下它們的特點:
* 復制算法(Copy)
復制算法是所有算法里面效率最高的,缺點是會造成一定的空間浪費。
* 標記-清除(Mark-Sweep)
效率一般,缺點是會造成內存碎片問題。
* 標記-整理(Mark-Compact)
效率比前兩者要差,但沒有空間浪費,也消除了內存碎片問題。
所以,沒有最優的算法,只有最合適的算法。
JVM 是計算節點,而不是存儲節點。最理想的情況,就是對象在用完之后,它的生命周期立馬就結束了。而那些被頻繁訪問的資源,我們希望它能夠常駐在內存里。
研究表明,大部分對象,可以分為兩類:
* 大部分對象的生命周期都很短;
* 其他對象則很可能會存活很長時間。
大部分死的快,其他的活的長。這個假設我們稱之為弱代假設(weak generational hypothesis)。
接下來劃重點。
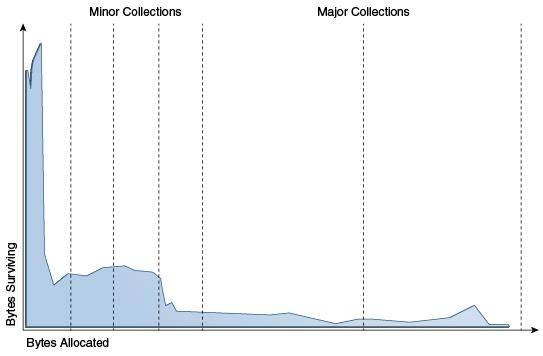
從圖中可以看到,大部分對象是朝生夕滅的,其他的則活的很久。
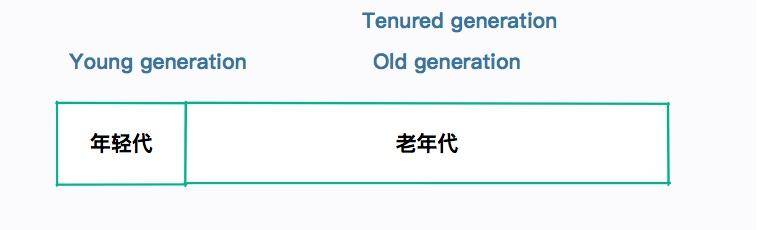
現在的垃圾回收器,都會在物理上或者邏輯上,把這兩類對象進行區分。我們把死的快的對象所占的區域,叫作年輕代(Young generation)。把其他活的長的對象所占的區域,叫作老年代(Old generation)。
老年代在有些地方也會叫作 Tenured Generation,你在看到時明白它的意思就可以了。
#### 年輕代
年輕代使用的垃圾回收算法是復制算法。因為年輕代發生 GC 后,只會有非常少的對象存活,復制這部分對象是非常高效的。
我們前面也了解到復制算法會造成一定的空間浪費,所以年輕代中間也會分很多區域。
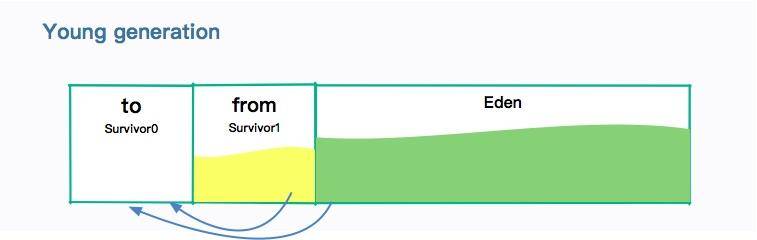
如圖所示,年輕代分為:一個伊甸園空間(Eden ),兩個幸存者空間(Survivor )。
當年輕代中的 Eden 區分配滿的時候,就會觸發年輕代的 GC(Minor GC)。具體過程如下:
* 在 Eden 區執行了第一次 GC 之后,存活的對象會被移動到其中一個 Survivor 分區(以下簡稱from);
* Eden 區再次 GC,這時會采用復制算法,將 Eden 和 from 區一起清理。存活的對象會被復制到 to 區;接下來,只需要清空 from 區就可以了。
所以在這個過程中,總會有一個 Survivor 分區是空置的。Eden、from、to 的默認比例是 8:1:1,所以只會造成 10% 的空間浪費。
這個比例,是由參數 -XX:SurvivorRatio 進行配置的(默認為 8)。
一般情況下,我們只需要了解到這一層面就 OK 了。但是在平常的面試中,還有一個點會經常提到,雖然頻率不太高,它就是 TLAB,我們在這里也簡單介紹一下。
TLAB 的全稱是 Thread Local Allocation Buffer,JVM 默認給每個線程開辟一個 buffer 區域,用來加速對象分配。這個 buffer 就放在 Eden 區中。
這個道理和 Java 語言中的 ThreadLocal 類似,避免了對公共區的操作,以及一些鎖競爭。
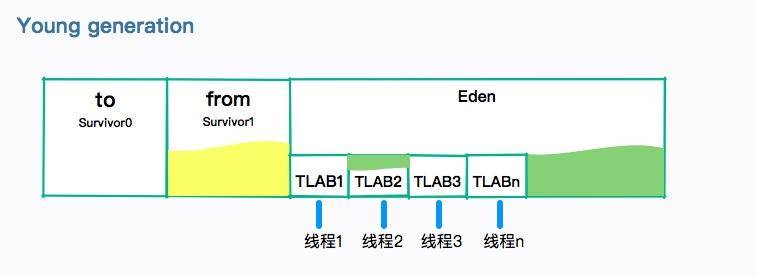
對象的分配優先在 TLAB上 分配,但 TLAB 通常都很小,所以對象相對比較大的時候,會在 Eden 區的共享區域進行分配。
TLAB 是一種優化技術,類似的優化還有對象的棧上分配(這可以引出逃逸分析的話題,默認開啟)。這屬于非常細節的優化,不做過多介紹,但偶爾面試也會被問到。
#### 老年代
老年代一般使用“標記-清除”、“標記-整理”算法,因為老年代的對象存活率一般是比較高的,空間又比較大,拷貝起來并不劃算,還不如采取就地收集的方式。
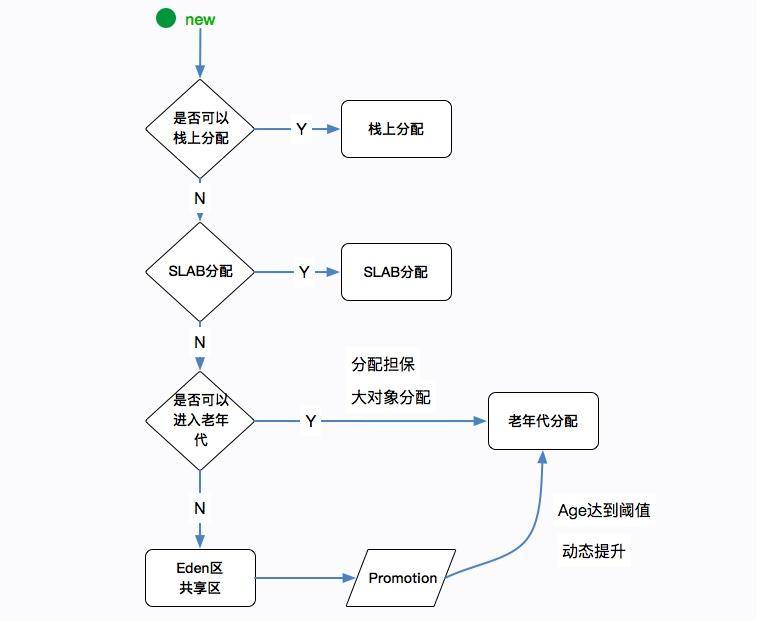
那么,對象是怎么進入老年代的呢?有多種途徑。
**(1)提升(Promotion)**
如果對象夠老,會通過“提升”進入老年代。
關于對象老不老,是通過它的年齡(age)來判斷的。每當發生一次 Minor GC,存活下來的對象年齡都會加 1。直到達到一定的閾值,就會把這些“老頑固”給提升到老年代。
這些對象如果變的不可達,直到老年代發生 GC 的時候,才會被清理掉。
這個閾值,可以通過參數 ‐XX:+MaxTenuringThreshold 進行配置,最大值是 15,因為它是用 4bit 存儲的(所以網絡上那些要把這個值調的很大的文章,是沒有什么根據的)。
**(2)分配擔保**
看一下年輕代的圖,每次存活的對象,都會放入其中一個幸存區,這個區域默認的比例是 10%。但是我們無法保證每次存活的對象都小于 10%,當 Survivor 空間不夠,就需要依賴其他內存(指老年代)進行分配擔保。這個時候,對象也會直接在老年代上分配。
**(3)大對象直接在老年代分配**
超出某個大小的對象將直接在老年代分配。這個值是通過參數 -XX:PretenureSizeThreshold 進行配置的。默認為 0,意思是全部首選 Eden 區進行分配。
**(4)動態對象年齡判定**
有的垃圾回收算法,并不要求 age 必須達到 15 才能晉升到老年代,它會使用一些動態的計算方法。比如,如果幸存區中相同年齡對象大小的和,大于幸存區的一半,大于或等于 age 的對象將會直接進入老年代。
這些動態判定一般不受外部控制,我們知道有這么回事就可以了。通過下圖可以看一下一個對象的分配邏輯。
#### 卡片標記(card marking)
你可以看到,對象的引用關系是一個巨大的網狀。有的對象可能在 Eden 區,有的可能在老年代,那么這種跨代的引用是如何處理的呢?由于 Minor GC 是單獨發生的,如果一個老年代的對象引用了它,如何確保能夠讓年輕代的對象存活呢?
對于是、否的判斷,我們通常都會用 Bitmap(位圖)和布隆過濾器來加快搜索的速度。如果你不知道這個概念就需要課后補補課了。
JVM 也是用了類似的方法。其實,老年代是被分成眾多的卡頁(card page)的(一般數量是 2 的次冪)。
卡表(Card Table)就是用于標記卡頁狀態的一個集合,每個卡表項對應一個卡頁。
如果年輕代有對象分配,而且老年代有對象指向這個新對象, 那么這個老年代對象所對應內存的卡頁,就會標識為 dirty,卡表只需要非常小的存儲空間就可以保留這些狀態。
垃圾回收時,就可以先讀這個卡表,進行快速判斷。
#### HotSpot 垃圾回收器
接下來介紹 HotSpot 的幾個垃圾回收器,每種回收器都有各自的特點。我們在平常的 GC 優化時,一定要搞清楚現在用的是哪種垃圾回收器。
在此之前,我們把上面的分代垃圾回收整理成一張大圖,在介紹下面的收集器時,你可以對應一下它們的位置。
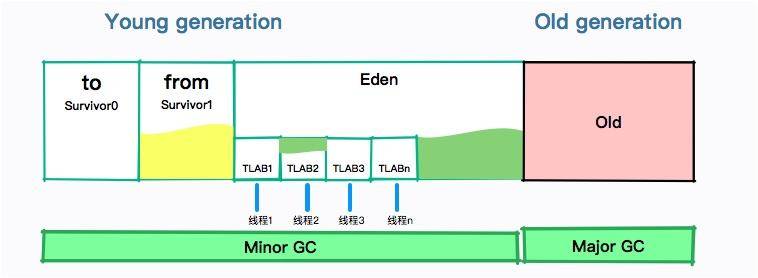
* [ ] 年輕代垃圾回收器
**(1)Serial 垃圾收集器**
處理 GC 的只有一條線程,并且在垃圾回收的過程中暫停一切用戶線程。
這可以說是最簡單的垃圾回收器,但千萬別以為它沒有用武之地。因為簡單,所以高效,它通常用在客戶端應用上。因為客戶端應用不會頻繁創建很多對象,用戶也不會感覺出明顯的卡頓。相反,它使用的資源更少,也更輕量級。
**(2)ParNew 垃圾收集器**
ParNew 是 Serial 的多線程版本。由多條 GC 線程并行地進行垃圾清理。清理過程依然要停止用戶線程。
ParNew 追求“低停頓時間”,與 Serial 唯一區別就是使用了多線程進行垃圾收集,在多 CPU 環境下性能比 Serial 會有一定程度的提升;但線程切換需要額外的開銷,因此在單 CPU 環境中表現不如 Serial。
**(3)Parallel Scavenge 垃圾收集器**
另一個多線程版本的垃圾回收器。它與 ParNew 的主要區別是:
* Parallel Scavenge:追求 CPU 吞吐量,能夠在較短時間內完成指定任務,適合沒有交互的后臺計算。弱交互強計算。
* ParNew:追求降低用戶停頓時間,適合交互式應用。強交互弱計算。
* [ ] 老年代垃圾收集器
**(1)Serial Old 垃圾收集器**
與年輕代的 Serial 垃圾收集器對應,都是單線程版本,同樣適合客戶端使用。
年輕代的 Serial,使用復制算法。
老年代的 Old Serial,使用標記-整理算法。
**(2)Parallel Old**
Parallel Old 收集器是 Parallel Scavenge 的老年代版本,追求 CPU 吞吐量。
**(3)CMS 垃圾收集器**
CMS(Concurrent Mark Sweep)收集器是以獲取最短 GC 停頓時間為目標的收集器,它在垃圾收集時使得用戶線程和 GC 線程能夠并發執行,因此在垃圾收集過程中用戶也不會感到明顯的卡頓。我們會在后面的課時詳細介紹它。
長期來看,CMS 垃圾回收器,是要被 G1 等垃圾回收器替換掉的。在 Java8 之后,使用它將會拋出一個警告。
```
Java HotSpot(TM) 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
```
**配置參數**
除了上面幾個垃圾回收器,我們還有 G1、ZGC 等更加高級的垃圾回收器,它們都有專門的配置參數來使其生效。
通過 -XX:+PrintCommandLineFlags 參數,可以查看當前 Java 版本默認使用的垃圾回收器。你可以看下我的系統中 Java13 默認的收集器就是 G1。
```
java -XX:+PrintCommandLineFlags -version
-XX:G1ConcRefinementThreads=4 -XX:GCDrainStackTargetSize=64 -XX:InitialHeapSize=134217728 -XX:MaxHeapSize=2147483648 -XX:MinHeapSize=6815736 -XX:+PrintCommandLineFlags -XX:ReservedCodeCacheSize=251658240 -XX:+SegmentedCodeCache -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseG1GC
java version "13.0.1" 2019-10-15
Java(TM) SE Runtime Environment (build 13.0.1+9)
Java HotSpot(TM) 64-Bit Server VM (build 13.0.1+9, mixed mode, sharing)
```
以下是一些配置參數:
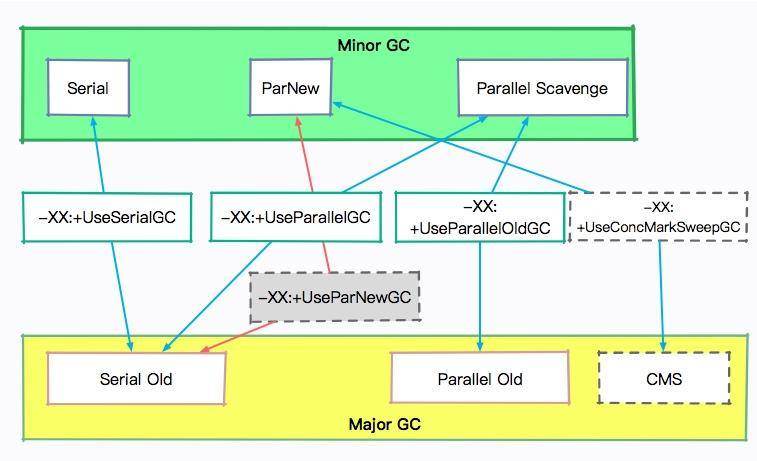
* -XX:+UseSerialGC 年輕代和老年代都用串行收集器
* -XX:+UseParNewGC 年輕代使用 ParNew,老年代使用 Serial Old
* -XX:+UseParallelGC 年輕代使用 ParallerGC,老年代使用 Serial Old
* -XX:+UseParallelOldGC 新生代和老年代都使用并行收集器
* -XX:+UseConcMarkSweepGC,表示年輕代使用 ParNew,老年代的用 CMS
* -XX:+UseG1GC 使用 G1垃圾回收器
* -XX:+UseZGC 使用 ZGC 垃圾回收器
為了讓你有個更好的印象,請看下圖。它們的關系還是比較復雜的。尤其注意 -XX:+UseParNewGC 這個參數,已經在 Java9 中就被拋棄了。很多程序(比如 ES)會報這個錯誤,不要感到奇怪。
有這么多垃圾回收器和參數,那我們到底用什么?在什么地方優化呢?
目前,雖然 Java 的版本比較高,但是使用最多的還是 Java8。從 Java8 升級到高版本的 Java 體系,是有一定成本的,所以 CMS 垃圾回收器還會持續一段時間。
線上使用最多的垃圾回收器,就有 CMS 和 G1,以及 Java8 默認的 Parallel Scavenge。
* CMS 的設置參數:-XX:+UseConcMarkSweepGC。
* Java8 的默認參數:-XX:+UseParallelGC。
* Java13 的默認參數:-XX:+UseG1GC。
我們的實戰練習的課時中,就集中會使用這幾個參數。
#### STW
你有沒有想過,如果在垃圾回收的時候(不管是標記還是整理復制),又有新的對象進入怎么辦?
為了保證程序不會亂套,最好的辦法就是暫停用戶的一切線程。也就是在這段時間,你是不能 new 對象的,只能等待。表現在 JVM 上就是短暫的卡頓,什么都干不了。這個頭疼的現象,就叫作 Stop the world。簡稱 STW。
標記階段,大多數是要 STW 的。如果不暫停用戶進程,在標記對象的時候,有可能有其他用戶線程會產生一些新的對象和引用,造成混亂。
現在的垃圾回收器,都會盡量去減少這個過程。但即使是最先進的 ZGC,也會有短暫的 STW 過程。我們要做的就是在現有基礎設施上,盡量減少 GC 停頓。
你可能對 STW 的影響沒有什么概念,我舉個例子來說明下。
某個高并發服務的峰值流量是 10 萬次/秒,后面有 10 臺負載均衡的機器,那么每臺機器平均下來需要 1w/s。假如某臺機器在這段時間內發生了 STW,持續了 1 秒,那么本來需要 10ms 就可以返回的 1 萬個請求,需要至少等待 1 秒鐘。
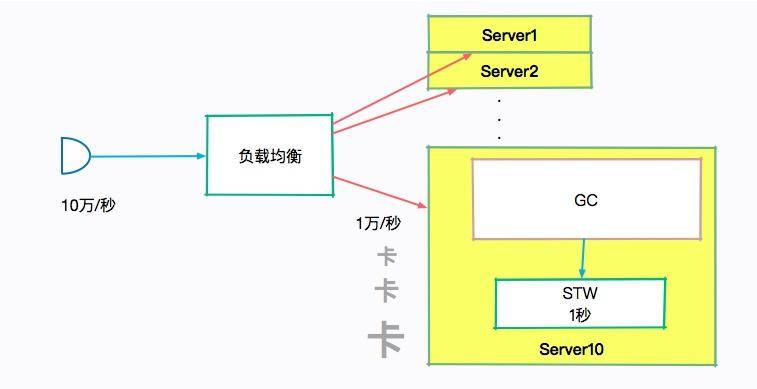
在用戶那里的表現,就是系統發生了卡頓。如果我們的 GC 非常的頻繁,這種卡頓就會特別的明顯,嚴重影響用戶體驗。
雖然說 Java 為我們提供了非常棒的自動內存管理機制,但也不能濫用,因為它是有 STW 硬傷的。
### 小結
本課時的內容很多。由于篇幅有限,我們僅介紹了最重要的點,要是深挖下去,估計一本書都寫不完。
歸根結底,各色的垃圾回收器就是為了解決頭疼的 STW 問題,讓 GC 時間更短,停頓更小,吞吐量更大。
現在的回收器,基于弱代假設,大多是分代回收的理念。針對年輕代和老年代,有多種不同的垃圾回收算法,有些可以組合使用。
我們尤其講解了年輕代的垃圾回收。
1. 年輕代是 GC 的重災區,大部分對象活不到老年代;
2. 面試經常問,都是些非常樸素的原理;
3. 為我們后面對 G1 和 ZGC 的介紹打下基礎。
我們也接觸了大量的名詞。讓我們來總結一下:
#### 算法
* Mark
* Sweep
* Copy
* Compact
#### 分代
* Young generation
* Survivor
* Eden
* Old generation | Tenured Generation
* GC
* Minor GC
* Major GC
#### 名詞
* weak generational hypothesis
* 分配擔保
* 提升
* 卡片標記
* STW
文中圖片關于 Eden、from、to 區的劃分以及堆的劃分,是很多面試官非常喜歡問的。但是有些面試官的問題非常陳舊,因為 JVM 的更新迭代有點快,你不要去反駁。有些痛點是需要實踐才能體驗到,心平氣和的講解這些變化,會讓你在面試中掌握主動地位。
#### 課后問答
* 1、為什么要兩個surivor區呢?一個也能完成復制
答案:任何復制有src和dst,怎么會有一個?
* 2、疑問:在老年代對象中引用了年輕代的對象場景中,在minor GC的過程中,可達性分析不能判定年輕代的對象為living狀態嗎,又或者老年代的這個對象如果已死,那么年輕代的這個對象會判定為dead,那么回收也不會有問題吧
答案:你說的就是卡片標記的功能,文中有講,是能夠判斷這些跨區引用的。垃圾回收器不怕少回收對象,就怕把正在使用的對象給回收了。所以不必每次都把垃圾清理的干干凈凈。
* 3、整理部分的算法代碼示例不完整
答案:文中是一個理想狀態的“偽代碼”。具體過程復雜的多,請參考hotspot/share/gc/cms/concurrentMarkSweepGeneration.cpp的do_compaction_work方法(jdk13)。
* 4、有個疑問,就是你在評論中說的【參考代碼share/gc/shared/ageTable.cpp中的compute_tenuring_threshold函數,重新表述如下:從年齡最小的對象開始累加,如果累加的對象大小,大于幸存區的一半,則講當前的對象age將作為新的閾值,年齡大于此閾值的對象直接進入老年代】這里面的幸存區的一半是指from與to兩塊區域總和的一半嗎,還是其它情況呢?
答案:指的是from或者to。
```
while (age < table_size) { total += sizes[age];if (total > desired_survivor_size) break;age++;}
```
desired_survivor_size就是配置一半的地方。
* 5、GC roots是引用而不是對象,這一節中,好多地方把GC roots當作對象了。是指GC roots所指向的對象嗎?
答案:GC roots是入口,回收的目標是對象。為了便于理解,你可以認為GC roots是GC發生時刻所引用的所有對象。
- 前言
- 開篇詞
- 基礎原理
- 第01講:一探究竟:為什么需要 JVM?它處在什么位置?
- 第02講:大廠面試題:你不得不掌握的 JVM 內存管理
- 第03講:大廠面試題:從覆蓋 JDK 的類開始掌握類的加載機制
- 第04講:動手實踐:從棧幀看字節碼是如何在 JVM 中進行流轉的
- 垃圾回收
- 第05講:大廠面試題:得心應手應對 OOM 的疑難雜癥
- 第06講:深入剖析:垃圾回收你真的了解嗎?(上)
- 第06講:深入剖析:垃圾回收你真的了解嗎?(下)
- 第07講:大廠面試題:有了 G1 還需要其他垃圾回收器嗎?
- 第08講:案例實戰:億級流量高并發下如何進行估算和調優
- 實戰部分
- 第09講:案例實戰:面對突如其來的 GC 問題如何下手解決
- 第10講:動手實踐:自己模擬 JVM 內存溢出場景
- 第11講:動手實踐:遇到問題不要慌,輕松搞定內存泄漏
- 第12講:工具進階:如何利用 MAT 找到問題發生的根本原因
- 第13講:動手實踐:讓面試官刮目相看的堆外內存排查
- 第14講:預警與解決:深入淺出 GC 監控與調優
- 第15講:案例分析:一個高死亡率的報表系統的優化之路
- 第16講:案例分析:分庫分表后,我的應用崩潰了
- 進階部分
- 第17講:動手實踐:從字節碼看方法調用的底層實現
- 第18講:大廠面試題:不要搞混 JMM 與 JVM
- 第19講:動手實踐:從字節碼看并發編程的底層實現
- 第20講:動手實踐:不為人熟知的字節碼指令
- 第21講:深入剖析:如何使用 Java Agent 技術對字節碼進行修改
- 第22講:動手實踐:JIT 參數配置如何影響程序運行?
- 第23講:案例分析:大型項目如何進行性能瓶頸調優?
- 彩蛋
- 第24講:未來:JVM 的歷史與展望
- 第25講:福利:常見 JVM 面試題補充