
本課時我們主要講解深入淺出 GC 監控與調優。
在前面的課時中不止一次談到了監控,但除了 GC Log,大多數都是一些“瞬時監控”工具,也就是看到的問題,基本是當前發生的。
你可能見過在地鐵上抱著電腦處理故障的照片,由此可見,大部分程序員都是隨身攜帶電腦的,它體現了兩個問題:第一,自動化應急處理機制并不完善;第二,缺乏能夠跟蹤定位問題的工具,只能靠“苦力”去解決。
我們在前面第 11 課時中提到的一系列命令,就是一個被分解的典型腳本,這個腳本能夠在問題發生的時候,自動觸發并保存順時態的現場。除了這些工具,我們還需要有一個與時間序列相關的監控系統。這就是監控工具的必要性。
我們來盤點一下對于問題的排查,現在都有哪些資源:
* GC 日志,能夠反映每次 GC 的具體狀況,可根據這些信息調整一些參數及容量;
* 問題發生點的堆快照,能夠在線下找到具體內存泄漏的原因;
* 問題發生點的堆棧信息,能夠定位到當前正在運行的業務,以及一些死鎖問題;
* 操作系統監控,比如 CPU 資源、內存、網絡、I/O 等,能夠看到問題發生前后整個操作系統的資源狀況;
* 服務監控,比如服務的訪問量、響應時間等,可以評估故障堆服務的影響面,或者找到一些突增的流量來源;
* JVM 各個區的內存變化、GC 變化、耗時等監控,能夠幫我們了解到 JVM 在整個故障周期的時間跨度上,到底發生了什么。
在實踐課時中,我們也不止一次提到,優化和問題排查是一個綜合的過程。故障相關信息越多越好,哪怕是同事不經意間透露的一次壓測信息,都能夠幫助你快速找到問題的根本。
本課時將以一個實際的監控解決方案,來看一下監控數據是怎么收集和分析的。使用的工具主要集中在 Telegraf、InfluxDB 和 Grafana 上,如果你在用其他的監控工具,思路也是類似的。
#### 監控指標
在前面的一些示例代碼中,會看到如下的 JMX 代碼片段:
```
static?void?memPrint()?{
????????for?(MemoryPoolMXBean?memoryPoolMXBean?:?ManagementFactory.getMemoryPoolMXBeans())?{
????????????System.out.println(memoryPoolMXBean.getName()?+
????????????????????"??committed:"?+?memoryPoolMXBean.getUsage().getCommitted()?+
????????????????????"??used:"?+?memoryPoolMXBean.getUsage().getUsed());
????????}
????}
```
這就是 JMX 的作用。除了使用代碼,通過 jmc 工具也可以簡單地看一下它們的值(前面提到的 VisualVM 通過安裝插件,也可以看到這些信息)。
新版本的 JDK 不再包含 jmc 這個工具,可點擊這里自行下載。
如下圖所示,可以看到一個 Java 進程的資源概覽,包括內存、CPU、線程等。
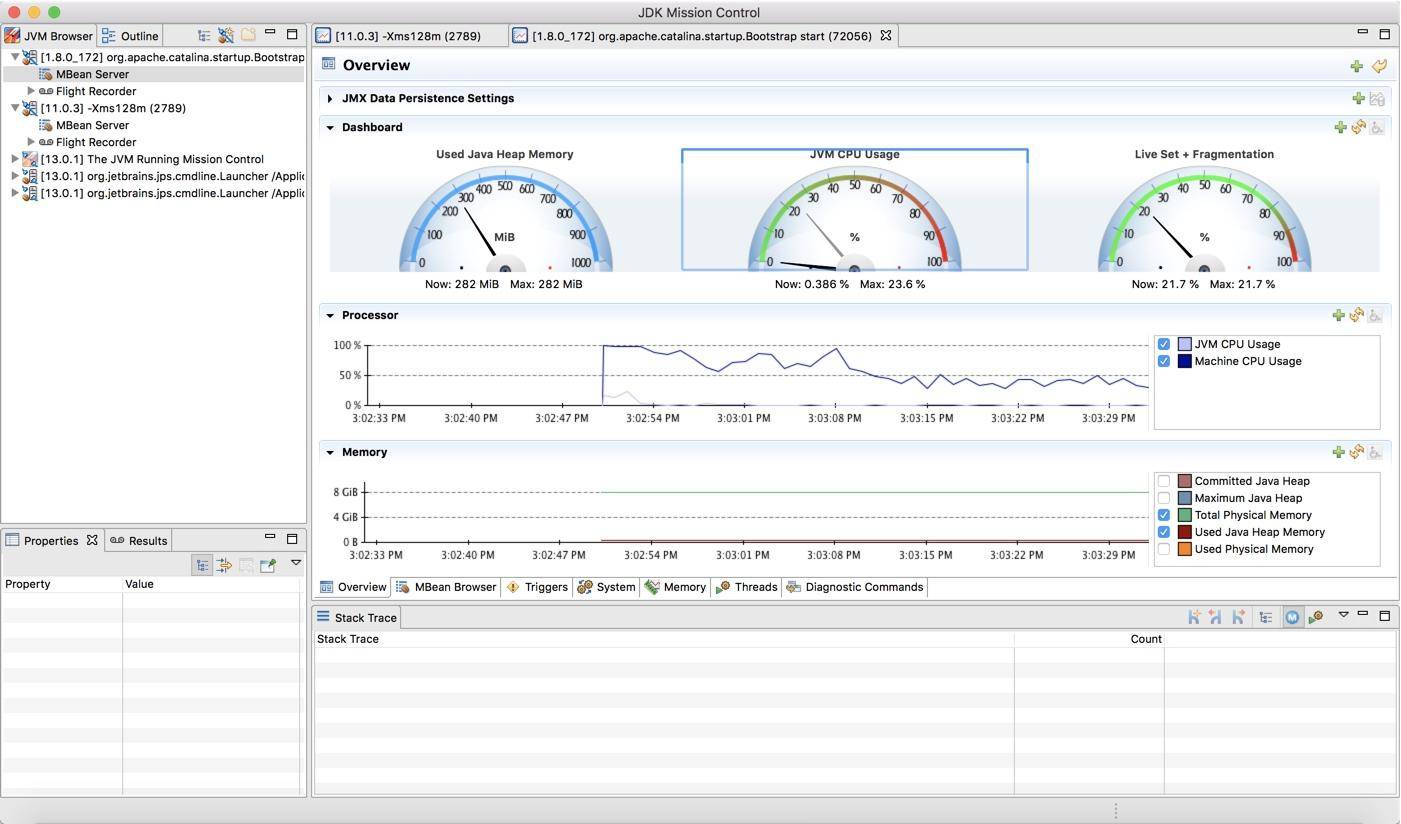
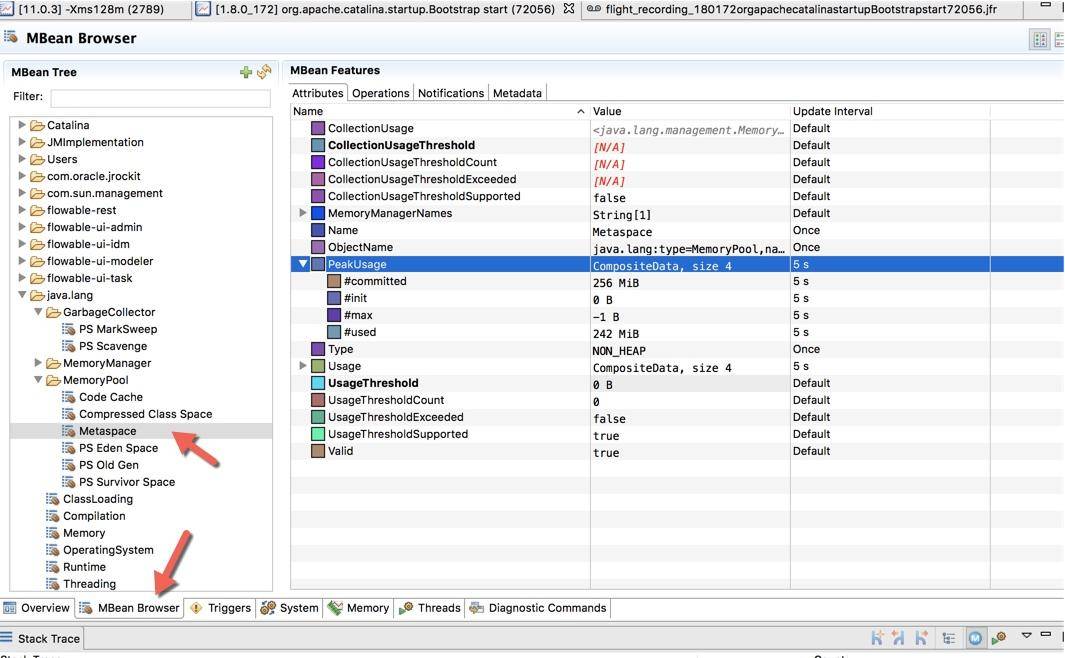
下圖是切換到 MBean 選項卡之后的截圖,可以看到圖中展示的 Metaspace 詳細信息。
jmc 還是一個性能分析平臺,可以錄制、收集正在運行的 Java 程序的診斷數據和概要分析數據,感興趣的可以自行探索。但還是那句話,線上環境可能沒有條件讓我們使用一些圖形化分析工具,相對比 Arthas 這樣的命令行工具就比較吃香。
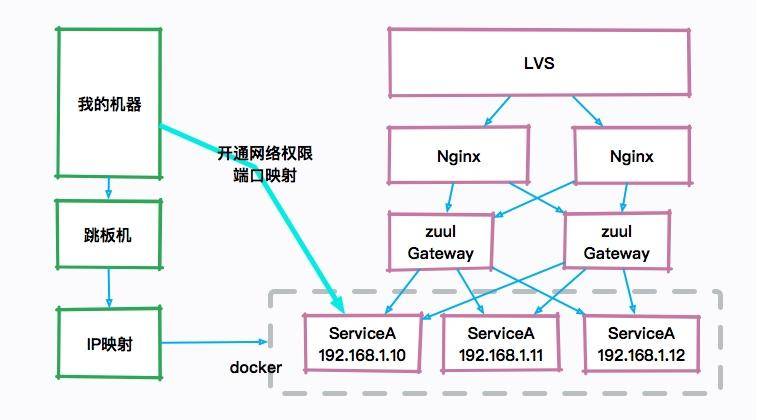
比如,下圖就是一個典型的互聯網架構圖,真正的服務器可能是一群 docker 實例,如果自己的機器想要訪問 JVM 的宿主機器,則需要配置一些復雜的安全策略和權限開通。圖像化的工具在平常的工作中不是非常有用,而且,由于性能損耗和安全性的考慮,也不會讓研發主動去通過 JMX 連接這些機器。
所以面試的時候如果你一直在提一些圖形化工具,面試官只能無奈的笑笑,這個話題也無法進行下去了。?
在必要的情況下,JMX 還可以通過加上一些參數,進行遠程訪問。
```
-Djava.rmi.server.hostname=127.0.0.1
-Dcom.sun.management.jmxremote?
-Dcom.sun.management.jmxremote.port=14000?
-Dcom.sun.management.jmxremote.ssl=false?
-Dcom.sun.management.jmxremote.authenticate=false
```
無論是哪種方式,我們發現每個內存區域,都有四個值:init、used、committed 和 max,下圖展示了它們之間的大小關系。
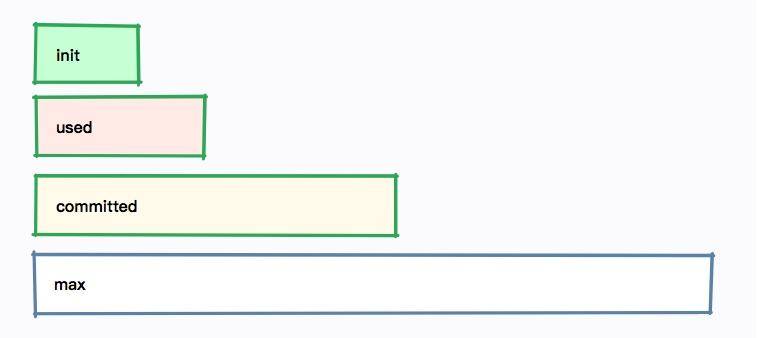
以堆內存大小來說:
* -Xmx 就是 max
* -Xms 就是 init
* committed 指的是當前可用的內存大小,它的大小包括已經使用的內存
* used 指的是實際被使用的內存大小,它的值總是小于 committed
如果在啟動的時候,指定了 -Xmx = -Xms,也就是初始值和最大值是一樣的,可以看到這四個值,只有 used 是變動的。
#### Jolokia
單獨看這些 JMX 的瞬時監控值,是沒有什么用的,需要使用程序收集起來并進行分析。
但是 JMX 的客戶端 API 使用起來非常的不方便,Jolokia 就是一個將 JMX 轉換成 HTTP 的適配器,方便了 JMX 的使用。?
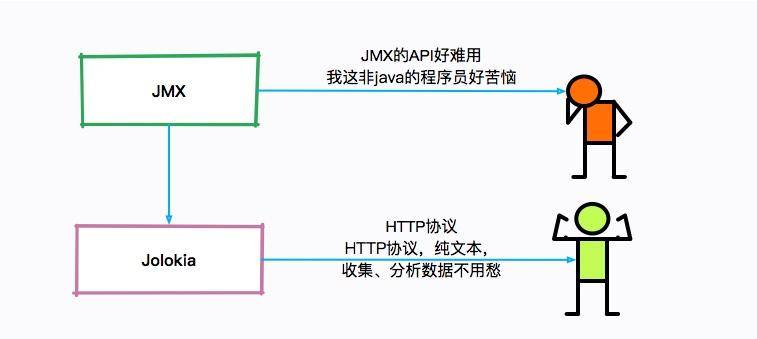
Jokokia 可以通過 jar 包和 agent 的方式啟動,在一些框架中,比如 Spring Boot 中,很容易進行集成。
訪問?http://start.spring.io,生成一個普通的 Spring Boot 項目。
直接在 pom 文件里加入 jolokia 的依賴。
```
<dependency>
????????<groupId>org.springframework.boot</groupId>
????????<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
????????<groupId>org.jolokia</groupId>
????????<artifactId>jolokia-core</artifactId>
</dependency>
```
在 application.yml 中簡單地加入一點配置,就可以通過 HTTP 接口訪問 JMX 的內容了。
```
management:
??endpoints:
????web:
??????exposure:
????????include:?jolokia
```
你也可以直接下載倉庫中的 monitor-demo 項目,啟動后訪問 8084 端口,即可獲取 JMX 的 json 數據。訪問鏈接 /demo 之后,會使用 guava 持續產生內存緩存。
接下來,我們將收集這個項目的 JMX 數據。
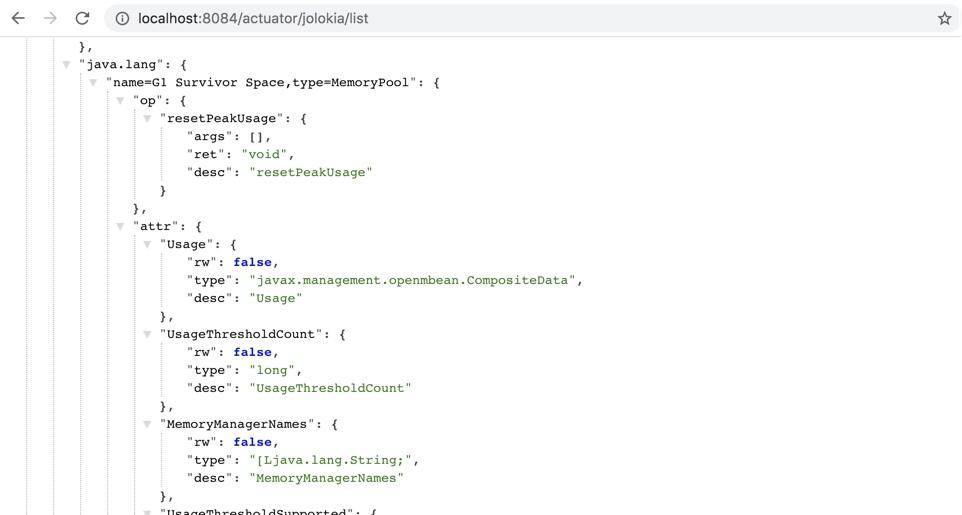
```
http://localhost:8084/actuator/jolokia/list
```
附上倉庫地址:https://gitee.com/xjjdog/jvm-lagou-res。
#### JVM 監控搭建
我們先簡單看一下 JVM 監控的整體架構圖:
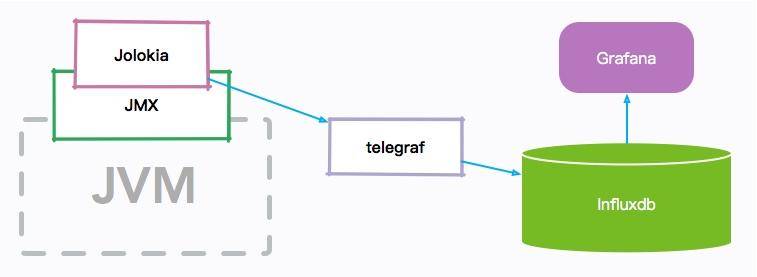
JVM 的各種內存信息,會通過 JMX 接口進行暴露;Jolokia 組件負責把 JMX 信息翻譯成容易讀取的 HTTP 請求。
telegraf 組件作為一個通用的監控 agent,和 JVM 進程部署在同一臺機器上,通過訪問轉化后的 HTTP 接口,以固定的頻率拉取監控信息;然后把這些信息存放到 influxdb 時序數據庫中;最后,通過高顏值的 Grafana 展示組件,設計 JVM 監控圖表。
整個監控組件是可以熱拔插的,并不會影響原有服務。監控部分也是可以復用的,比如 telegraf 就可以很容易的進行操作系統監控。
* influxdb
influxdb 是一個性能和壓縮比非常高的時序數據庫,在中小型公司非常流行,點擊這里可獲取 influxdb。
在 CentOS 環境中,可以使用下面的命令下載。
```
wget?-c?https://dl.influxdata.com/influxdb/releases/influxdb-1.7.9_linux_amd64.tar.gz
tar?xvfz?influxdb-1.7.9_linux_amd64.tar.gz
```
解壓后,然后使用 nohup 進行啟動。?
```
nohup?./influxd?&
```
InfluxDB 將在 8086 端口進行監聽。
* Telegraf
Telegraf 是一個監控數據收集工具,支持非常豐富的監控類型,其中就包含內置的 Jolokia 收集器。
接下來,下載并安裝 Telegraf:
```
wget?-c?https://dl.influxdata.com/telegraf/releases/telegraf-1.13.1-1.x86_64.rpm
sudo?yum?localinstall?telegraf-1.13.1-1.x86_64.rpm
```
Telegraf 通過 jolokia 配置收集數據相對簡單,比如下面就是收集堆內存使用狀況的一段配置。
```
[[inputs.jolokia2_agent.metric]]
????name??=?"jvm"
????field_prefix?=?"Memory_"
????mbean?=?"java.lang:type=Memory"
????paths?=?["HeapMemoryUsage",?"NonHeapMemoryUsage",?"ObjectPendingFinalizationCount"]
```
設計這個配置文件的主要難點在于對 JVM 各個內存分區的理解。由于配置文件比較長,可以參考倉庫中的 jvm.conf 和 sys.conf,你可以把這兩個文件,復制到 /etc/telegraf/telegraf.d/ 目錄下面,然后執行 systemctl restart telegraf 重啟 telegraf。
* grafana
grafana 是一個顏值非常高的監控展示組件,支持非常多的數據源類型,對 influxdb 的集成度也比較高,可通過以下地址進行下載:https://grafana.com/grafana/download
```
wget?-c?https://dl.grafana.com/oss/release/grafana-6.5.3.linux-amd64.tar.gz
tar?-zxvf?grafana-6.5.3.linux-amd64.tar.gz
```
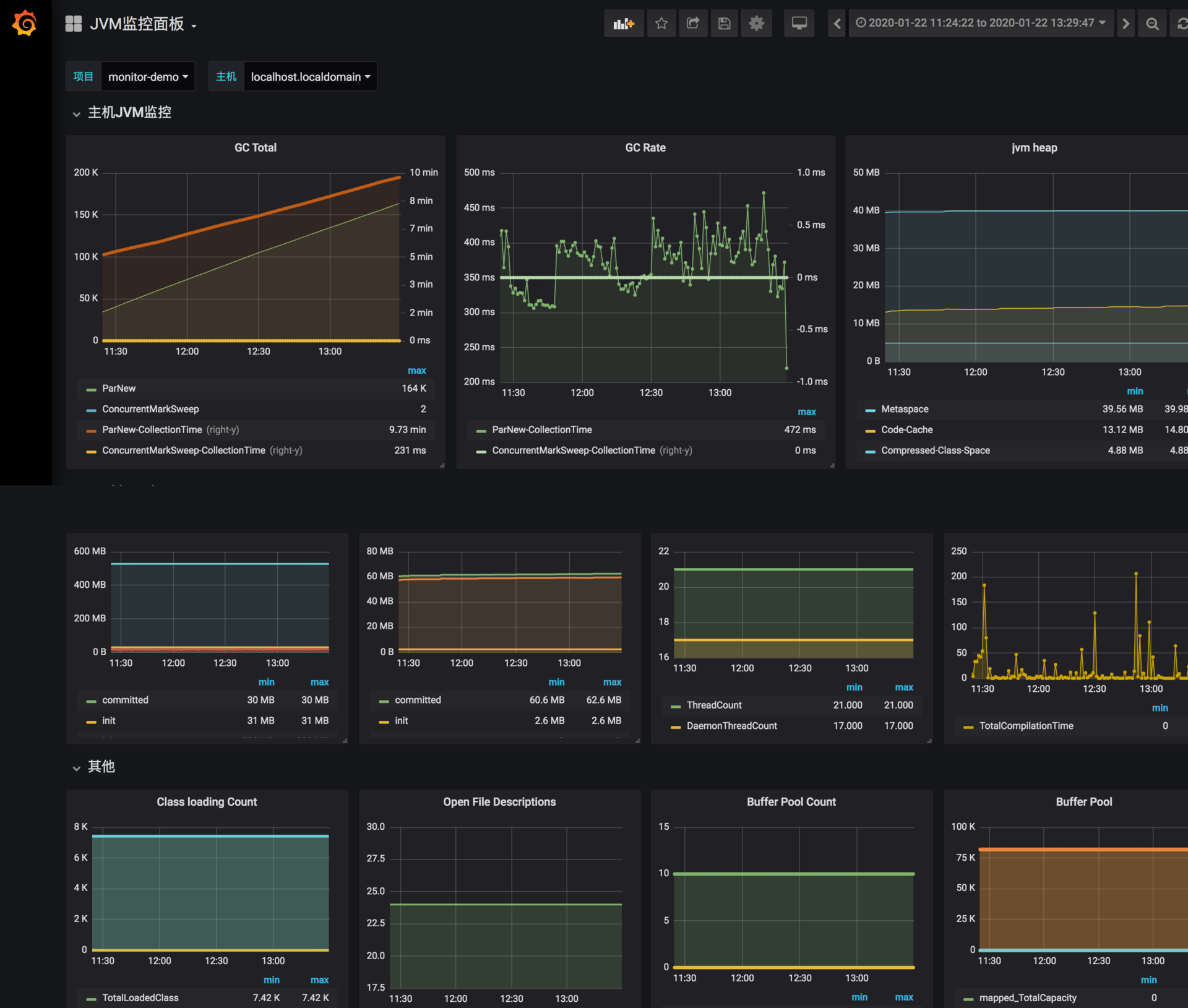
下面是我已經做好的一張針對于 CMS 垃圾回收器的監控圖,你可以導入 grafana-jvm-influxdb.json 文件進行測試。?
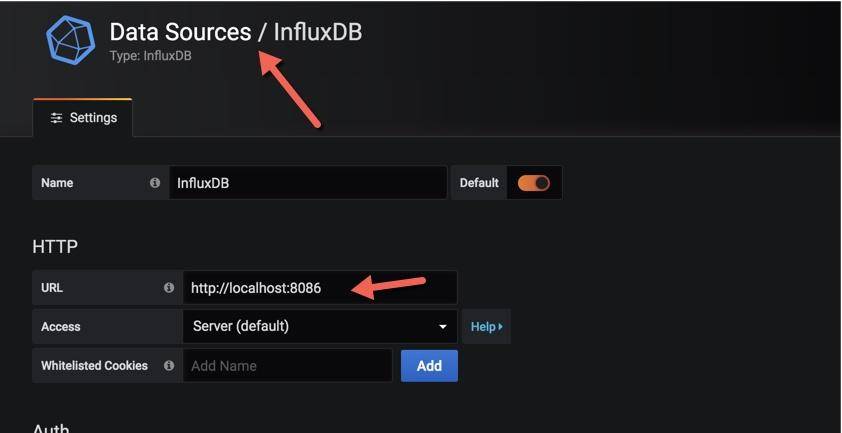
在導入之前,還需要創建一個數據源,選擇 influxdb,填入 db 的地址即可。?
* 集成
把我們的 Spring Boot 項目打包(見倉庫),然后上傳到服務器上去執行。
打包方式:
```
mvn?package?-Dmaven.tesk.skip=true
```
執行方式(自行替換日志方面配置):
```
mkdir?/tmp/logs
nohup??java???-XX:+UseConcMarkSweepGC?-Xmx512M?-Xms512M?-Djava.rmi.server.hos
tname=192.168.99.101?-Dcom.sun.management.jmxremote??-Dcom.sun.management.jmx
remote.port=14000??-Dcom.sun.management.jmxremote.ssl=false??-Dcom.sun.manage
ment.jmxremote.authenticate=false?-verbose:gc?-XX:+PrintGCDetails?-XX:+PrintG
CDateStamps?-XX:+PrintGCApplicationStoppedTime?-XX:+PrintTenuringDistributio
n?-Xloggc:/tmp/logs/gc_%p.log?-XX:+HeapDumpOnOutOfMemoryError?-XX:HeapDumpPat
h=/tmp/logs?-XX:ErrorFile=/tmp/logs/hs_error_pid%p.log?-XX:-OmitStackTraceInF
astThrow??-jar?monitor-demo-0.0.1-SNAPSHOT.jar??2>&1??&
```
請將 IP 地址改成自己服務器的實際 IP 地址,這樣就可以使用 jmc 或者 VisualVM 等工具進行連接了。
確保 Telegraf、InfluxDB、Grafana 已經啟動,這樣,Java 進程的 JVM 相關數據,將會以 10 秒一次的頻率進行收集,我們可以選擇 Grafana 的時間軸,來查看實時的或者歷史的監控曲線。
這類監控信息,可以保存長達 1 ~ 2 年,也就是說非常久遠的問題,也依然能夠被追溯到。如果你想要對 JVM 盡可能地進行調優,就要時刻關注這些監控圖。
舉一個例子:我們發現有一個線上服務,運行一段時間以后,CPU 升高、程序執行變慢,登錄相應的服務器進行分析,發現 C2 編譯線程一直處在高耗 CPU 的情況。
但是我們無法解決這個問題,一度以為是 JVM 的 Bug。
通過分析 CPU 的監控圖和 JVM 每個內存分區的曲線,發現 CodeCache 相應的曲線,在增加到 32MB 之后,就變成了一條直線,同時 CPU 的使用也開始增加。
通過檢查啟動參數和其他配置,最終發現一個開發環境的 JVM 參數被一位想要練手的同學給修改了,他本意是想要通過參數 “-XX:ReservedCodeCacheSize” 來限制 CodeCache 的大小,這個參數被誤推送到了線上環境。
JVM 通過 JIT 編譯器來增加程序的執行效率,JIT 編譯后的代碼,都會放在 CodeCache 里。如果這個空間不足,JIT 則無法繼續編譯,編譯執行會變成解釋執行,性能會降低一個數量級。同時,JIT 編譯器會一直嘗試去優化代碼,造成了 CPU 的占用上升。
由于我們收集了這些分區的監控信息,所以很容易就發現了問題的相關性,這些判斷也會反向支持我們的分析,而不僅僅是靠猜測。
#### 小結
本課時簡要介紹了基于 JMX 的 JVM 監控,并了解了一系列觀測這些數據的工具。但通常,使用 JMX 的 API 還是稍顯復雜一些,Jolokia 可以把這些信息轉化成 HTTP 的 json 信息。
還介紹了一個可用的監控體系,來收集這些暴露的數據,這也是有點規模的公司采用的正統思路。收集的一些 GC 數據,和前面介紹的 GC 日志是有一些重合的,但我們的監控更突出的是實時性,以及追蹤一些可能比較久遠的問題數據。
附錄:代碼清單
* sys.conf?操作系統監控數據收集配置文件,Telegraf 使用。
* ?jvm.conf?JVM 監控配置文件,Telegraf 使用。
* grafana-jvm-influxdb.json?JVM 監控面板,Grafana 使用。
* monitor-demo?被收集的 Spring Boot 項目。
- 前言
- 開篇詞
- 基礎原理
- 第01講:一探究竟:為什么需要 JVM?它處在什么位置?
- 第02講:大廠面試題:你不得不掌握的 JVM 內存管理
- 第03講:大廠面試題:從覆蓋 JDK 的類開始掌握類的加載機制
- 第04講:動手實踐:從棧幀看字節碼是如何在 JVM 中進行流轉的
- 垃圾回收
- 第05講:大廠面試題:得心應手應對 OOM 的疑難雜癥
- 第06講:深入剖析:垃圾回收你真的了解嗎?(上)
- 第06講:深入剖析:垃圾回收你真的了解嗎?(下)
- 第07講:大廠面試題:有了 G1 還需要其他垃圾回收器嗎?
- 第08講:案例實戰:億級流量高并發下如何進行估算和調優
- 實戰部分
- 第09講:案例實戰:面對突如其來的 GC 問題如何下手解決
- 第10講:動手實踐:自己模擬 JVM 內存溢出場景
- 第11講:動手實踐:遇到問題不要慌,輕松搞定內存泄漏
- 第12講:工具進階:如何利用 MAT 找到問題發生的根本原因
- 第13講:動手實踐:讓面試官刮目相看的堆外內存排查
- 第14講:預警與解決:深入淺出 GC 監控與調優
- 第15講:案例分析:一個高死亡率的報表系統的優化之路
- 第16講:案例分析:分庫分表后,我的應用崩潰了
- 進階部分
- 第17講:動手實踐:從字節碼看方法調用的底層實現
- 第18講:大廠面試題:不要搞混 JMM 與 JVM
- 第19講:動手實踐:從字節碼看并發編程的底層實現
- 第20講:動手實踐:不為人熟知的字節碼指令
- 第21講:深入剖析:如何使用 Java Agent 技術對字節碼進行修改
- 第22講:動手實踐:JIT 參數配置如何影響程序運行?
- 第23講:案例分析:大型項目如何進行性能瓶頸調優?
- 彩蛋
- 第24講:未來:JVM 的歷史與展望
- 第25講:福利:常見 JVM 面試題補充