
本課時我們主要分享一個實踐案例,JIT 參數配置是如何影響程序運行的。
我們在前面的課時中介紹了很多字節碼指令,這也是 Java 能夠跨平臺的保證。程序在運行的時候,這些指令會按照順序解釋執行,但是,這種解釋執行的方式是非常低效的,它需要把字節碼先翻譯成機器碼,才能往下執行。另外,字節碼是 Java 編譯器做的一次初級優化,許多代碼可以滿足語法分析,但還有很大的優化空間。
所以,為了提高熱點代碼的執行效率,在運行時,虛擬機將會把這些代碼編譯成與本地平臺相關的機器碼,并進行各種層次的優化。完成這個任務的編譯器,就稱為即時編譯器(Just In Time Compiler),簡稱 JIT 編譯器。
熱點代碼,就是那些被頻繁調用的代碼,比如調用次數很高或者在 for 循環里的那些代碼。這些再次編譯后的機器碼會被緩存起來,以備下次使用,但對于那些執行次數很少的代碼來說,這種編譯動作就純屬浪費。
在第 14 課時我們提到了參數“-XX:ReservedCodeCacheSize”,用來限制 CodeCache 的大小。也就是說,JIT 編譯后的代碼都會放在 CodeCache 里。
如果這個空間不足,JIT 就無法繼續編譯,編譯執行會變成解釋執行,性能會降低一個數量級。同時,JIT 編譯器會一直嘗試去優化代碼,從而造成了 CPU 占用上升。
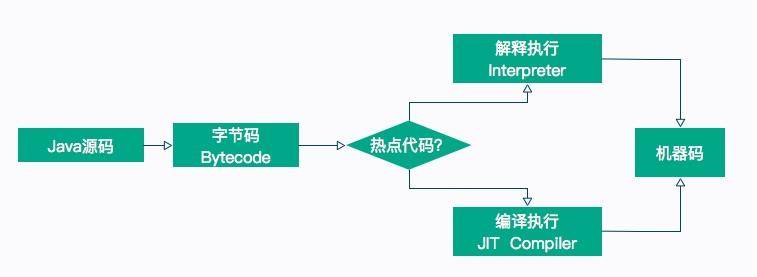
#### JITWatch
在開始之前,我們首先介紹一個觀察 JIT 執行過程的圖形化工具:JITWatch,這個工具非常好用,可以解析 JIT 的日志并友好地展示出來。項目地址請點擊這里查看。
下載之后,進入解壓目錄,執行 ant 即可編譯出執行文件。
* [ ] 產生 JIT 日志
我們觀察下面的一段代碼,這段代碼沒有什么意義,而且寫得很爛。在 test 函數中循環 cal 函數 1 千萬次,在 cal 函數中,還有一些冗余的上鎖操作和賦值操作,這些操作在解釋執行的時候,會加重 JVM 的負擔。
```
public?class?JITDemo?{
????Integer?a?=?1000;
????public?void?setA(Integer?a)?{
????????this.a?=?a;????}
????public?Integer?getA()?{
????????return?this.a;
????}
????public?Integer?cal(int?num)?{
????????synchronized?(new?Object())?{
????????????Integer?a?=?getA();
????????????int?b?=?a?*?10;
????????????b?=?a?*?100;
????????????return?b?+?num;
????????}
????}
????public?int?test()?{
????????synchronized?(new?Object())?{
????????????int?total?=?0;
????????????int?count?=?100_000_00;
????????????for?(int?i?=?0;?i?<?count;?i++)?{
????????????????total?+=?cal(i);
????????????????if?(i?%?1000?==?0)?{
????????????????????System.out.println(i?*?1000);
????????????????}
????????????}
????????????return?total;
????????}
????}
????public?static?void?main(String[]?args)?{
????????JITDemo?demo?=?new?JITDemo();
????????int?total?=?demo.test();
```
在方法執行的時候,我們加上一系列參數,用來打印 JIT 最終生成的機器碼,執行命令如下所示:
```
$JAVA_HOME_13/bin/java?-server?-XX:+UnlockDiagnosticVMOptions?-XX:+TraceClassLoading??-XX:+PrintAssembly?-XX:+LogCompilation?-XX:LogFile=jitdemo.log?JITDemo
```
執行的過程,會輸入到 jitdemo.log 文件里,接下來我們分析這個文件。
#### 使用
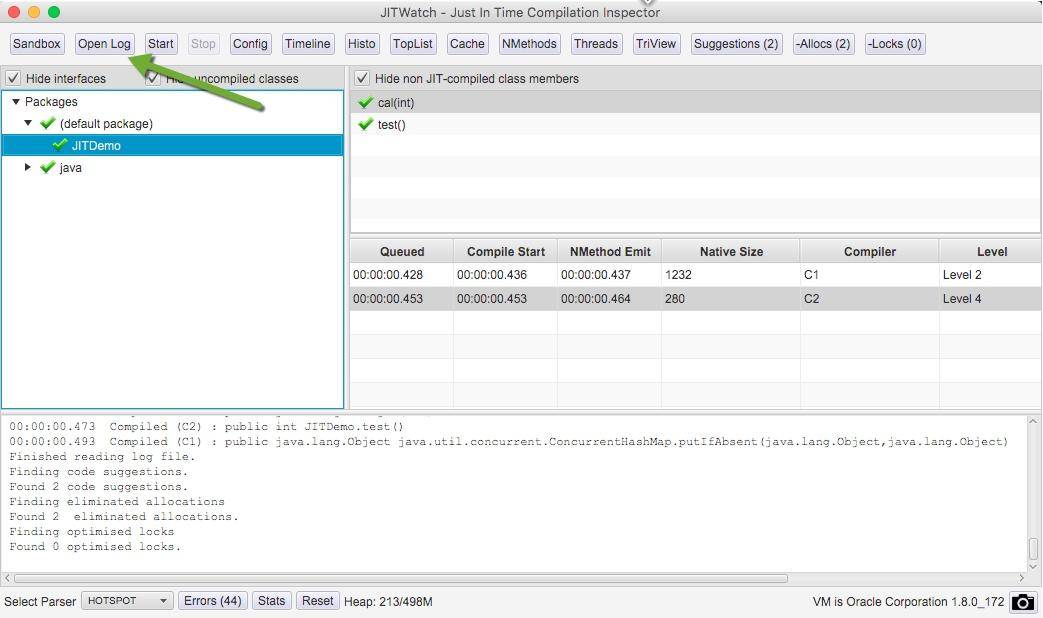
單擊 open log 按鈕,打開我們生成的日志文件。
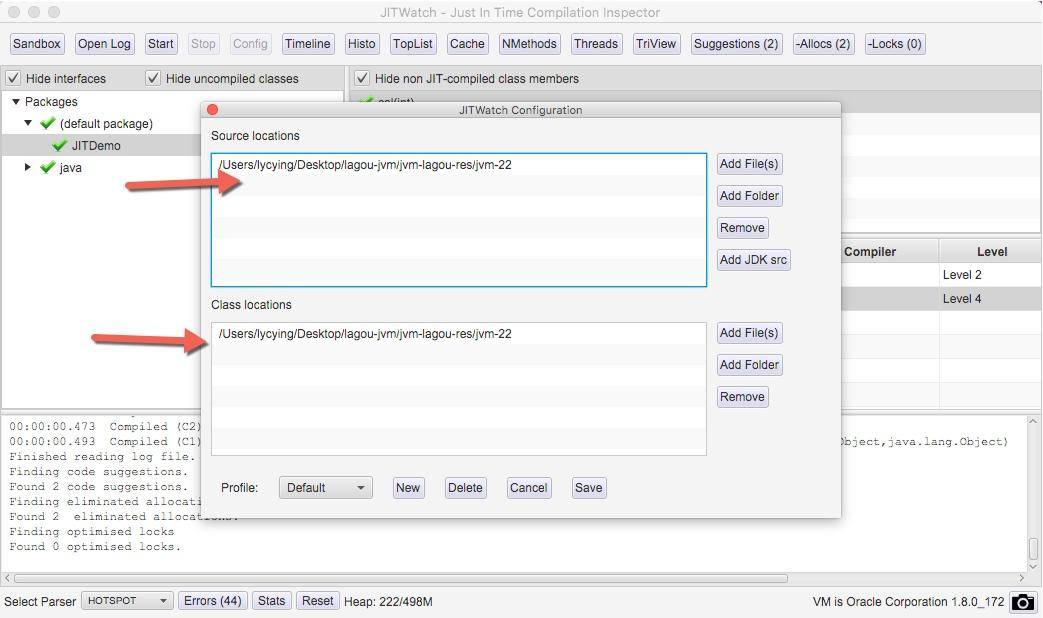
單擊 config 按鈕,加入要分析的源代碼目錄和字節碼目錄。確認后,單擊 start 按鈕進行分析。
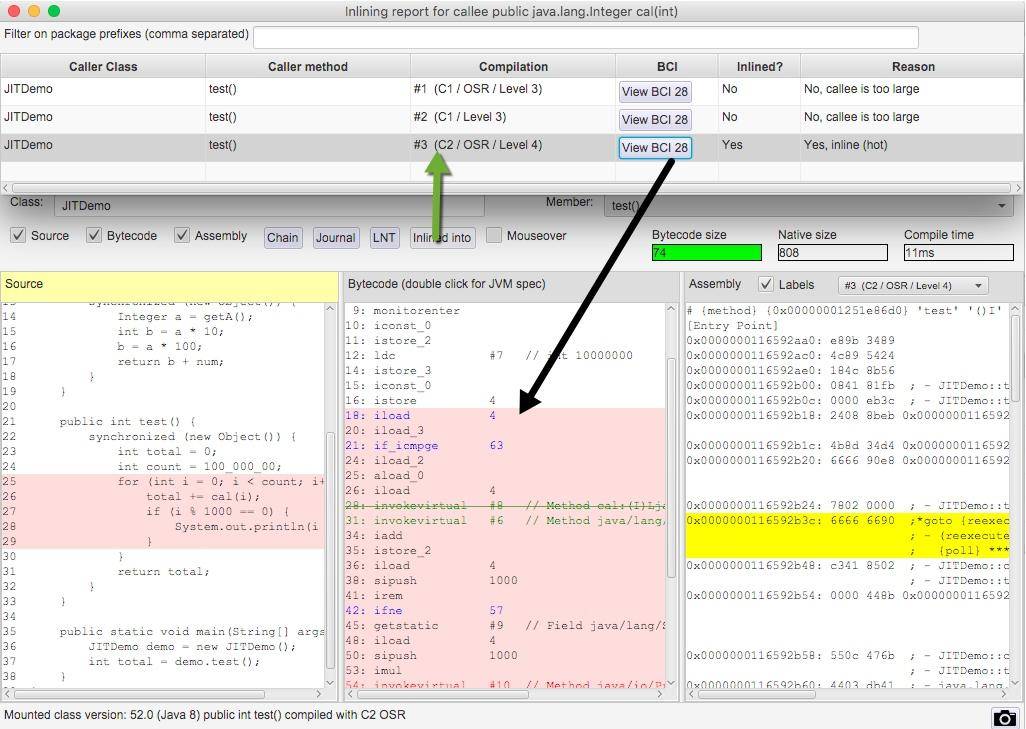
在右側找到我們的 test 方法,聚焦光標后,將彈出我們要分析的主要界面。
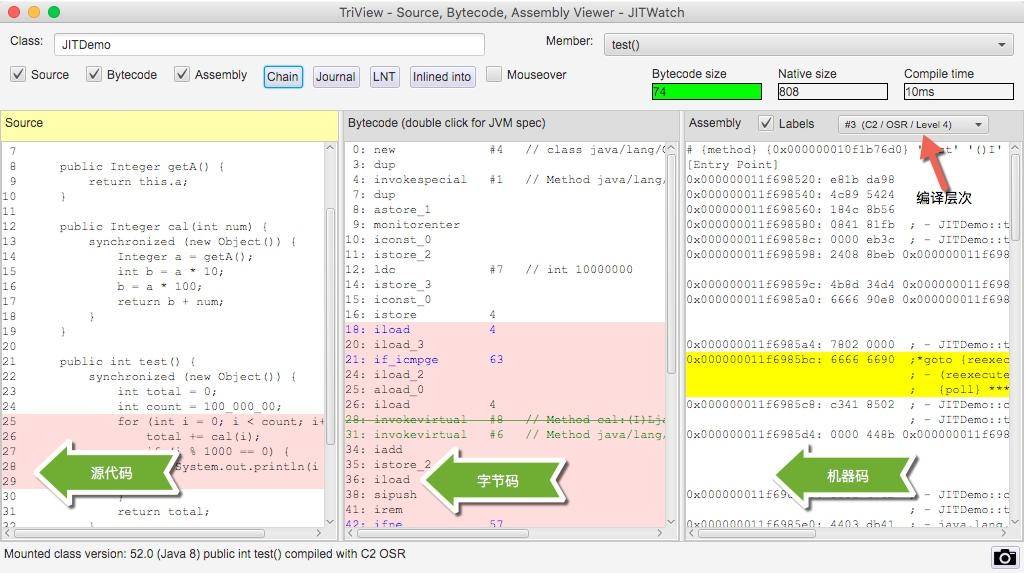
在同一個界面上,我們能夠看到源代碼、字節碼、機器碼的對應關系。在右上角,還有 C2/OSR/Level4 這樣的字樣,可以單擊切換。
單擊上圖中的 Chain 按鈕,還會彈出一個依賴鏈界面,該界面顯示了哪些方法已經被編譯了、哪些被內聯、哪些是通過普通的方法調用運行的。
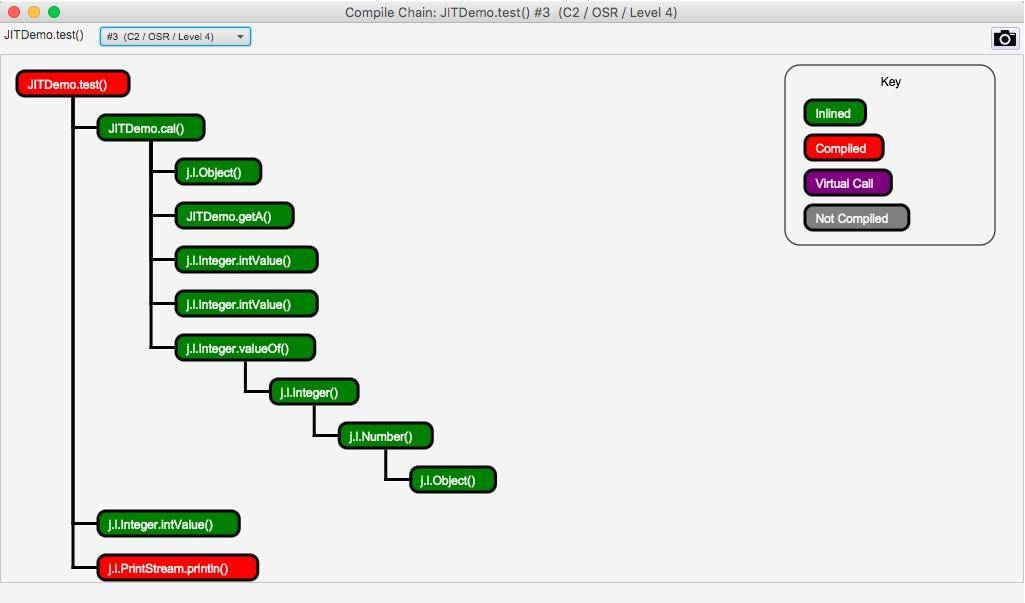
使用 JITWatch 可以看到,調用了 1 千萬次的 for 循環代碼,已經被 C2 進行編譯了。
#### 編譯層次
HotSpot 虛擬機包含多個即時編譯器,有 C1、C2 和 Graal,采用的是分層編譯的模式。使用 jstack 獲得的線程信息,經常能看到它們的身影。
實驗性質的 Graal 可以通過追加 JVM 參數進行開啟,命令行如下:
```
$JAVA_HOME_13/bin/java?-server?-XX:+UnlockDiagnosticVMOptions?-XX:+TraceClassLoading
??-XX:+PrintAssembly?-XX:+LogCompilation?-XX:+UnlockExperimentalVMOptions
???-XX:+UseJVMCICompiler?-XX:LogFile=jitdemo.log?JITDemo
```
不同層次的編譯器會產生不一樣的效果,機器碼也會不同,我們僅看 C1、C2 的一些特點。
JIT 編譯方式有兩種:一種是編譯方法,另一種是編譯循環。分層編譯將 JVM 的執行狀態分為了五個層次:
* 字節碼的解釋執行;
* 執行不帶 profiling 的 C1 代碼;
* 執行僅帶方法調用次數,以及循環執行次數 profiling 的 C1 代碼;
* 執行帶所有 profiling 的 C1 代碼;
* 執行 C2 代碼。
其中,profiling 指的是運行時的程序執行狀態數據,比如循環調用的次數、方法調用的次數、分支跳轉次數、類型轉換次數等。JDK 中的 hprof 工具就是一種 profiler。
在不啟用分層編譯的情況下,當方法的調用次數和循環回邊的次數總和,超過由參數 -XX:CompileThreshold 指定的閾值時,便會觸發即時編譯;當啟用分層編譯時,這個參數將會失效,會采用動態調整的方式進行。
常見的優化方法有以下幾種:
* 公共子表達式消除
* 數組范圍檢查消除
* 方法內聯
* 逃逸分析
我們重點看一下方法內聯和逃逸分析。
#### 方法內聯
在第 17 課時里,我們可以看到方法調用的開銷是比較大的,尤其是在調用量非常大的情況下。拿簡單的 getter/setter 方法來說,這種方法在 Java 代碼中大量存在,我們在訪問的時候,需要創建相應的棧幀,訪問到需要的字段后,再彈出棧幀,恢復原程序的執行。
如果能夠把這些對象的訪問和操作,納入到目標方法的調用范圍之內,就少了一次方法調用,速度就能得到提升,這就是方法內聯的概念。
C2 編譯器會在解析字節碼的過程中完成方法內聯。內聯后的代碼和調用方法的代碼,會組成新的機器碼,存放在 CodeCache 區域里。
在 JDK 的源碼里,有很多被 @ForceInline 注解的方法,這些方法會在執行的時候被強制進行內聯;而被 @DontInline 注解的方法,則始終不會被內聯,比如下面的一段代碼。
java.lang.ClassLoader 的 getClassLoader 方法將會被強制內聯。
```
@CallerSensitive
????@ForceInline?//?to?ensure?Reflection.getCallerClass?optimization
????public?ClassLoader?getClassLoader()?{
????????ClassLoader?cl?=?getClassLoader0();
????????if?(cl?==?null)
????????????return?null;
????????SecurityManager?sm?=?System.getSecurityManager();
????????if?(sm?!=?null)?{
????????????ClassLoader.checkClassLoaderPermission(cl,?Reflection.getCallerClass());
????????}
????????return?cl;
}
```
方法內聯的過程是非常智能的,內聯后的代碼,會按照一定規則進行再次優化。最終的機器碼,在保證邏輯正確的前提下,可能和我們推理的完全不一樣。在非常小的概率下,JIT 會出現 Bug,這時候可以關閉問題方法的內聯,或者直接關閉 JIT 的優化,保持解釋執行。實際上,這種 Bug 我從來沒碰到過。
```
-XX:CompileCommand=exclude,com/lagou/Test,test
```
上面的參數,表示 com.lagou.Test 的 test 方法將不會進行 JIT 編譯,一直解釋執行。
另外,C2 支持的內聯層次不超過 9 層,太高的話,CodeCache 區域會被擠爆,這個閾值可以通過 -XX:MaxInlineLevel 進行調整。相似的,編譯后的代碼超過一定大小也不會再內聯,這個參數由 -XX:InlineSmallCode 進行調整。
有非常多的參數,被用來控制對內聯方法的選擇,整體來說,短小精悍的小方法更容易被優化。
這和我們在日常中的編碼要求是一致的:代碼塊精簡,邏輯清晰的代碼,更容易獲得優化的空間。
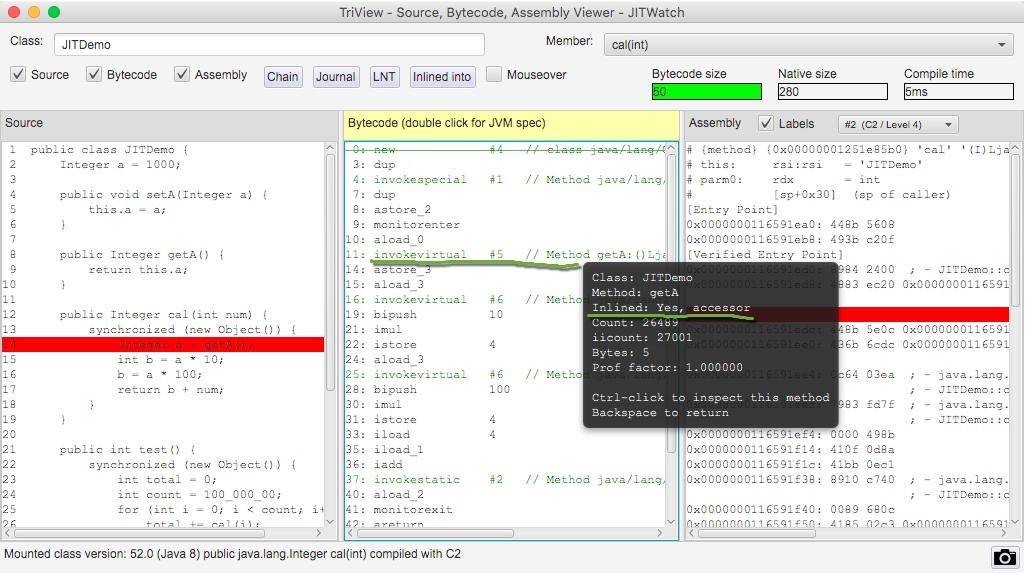
我們使用 JITWatch 再看一下對于 getA() 方法的調用,將鼠標懸浮在字節碼指令上,可以看到方法已經被內聯了。
#### 逃逸分析
逃逸分析(Escape Analysis)是目前 JVM 中比較前沿的優化技術。通過逃逸分析,JVM 能夠分析出一個新的對象使用范圍,從而決定是否要將這個對象分配到堆上。
使用 -XX:+DoEscapeAnalysis 參數可以開啟逃逸分析,逃逸分析現在是 JVM 的默認行為,這個參數可以忽略。
JVM 判斷新創建的對象是否逃逸的依據有:
* 對象被賦值給堆中對象的字段和類的靜態變量;
* 對象被傳進了不確定的代碼中去運行。
舉個例子,在代碼 1 中,雖然 map 是一個局部變量,但是它通過 return 語句返回,其他外部方法可能會使用它,這就是方法逃逸。另外,如果被其他線程引用或者賦值,則成為線程逃逸。
代碼 2,用完 Map 之后就直接銷毀了,我們就可以說 map 對象沒有逃逸。
代碼1:
```
public?Map?fig(){
????Map?map?=?new?HashMap();
????...
????return?map;
}
```
代碼2:
```
public?void?fig(){
????Map?map?=?new?HashMap();
????...
}
```
那逃逸分析有什么好處呢?
* 同步省略,如果一個對象被發現只能從一個線程被訪問到,那么對于這個對象的操作可以不考慮同步。
* 棧上分配,如果一個對象在子程序中被分配,那么指向該對象的指針永遠不會逃逸,對象有可能會被優化為棧分配。
* 分離對象或標量替換,有的對象可能不需要作為一個連續的內存結構存在也可以被訪問到,那么對象的部分(或全部)可以不存儲在內存,而是存儲在 CPU 寄存器中。標量是指無法再分解的數據類型,比如原始數據類型及 reference 類型。

再來看一下 JITWatch 對 synchronized 代碼塊的分析。根據提示,由于逃逸分析了解到新建的鎖對象 Object 并沒有逃逸出方法 cal,它將會在棧上直接分配。
查看 C2 編譯后的機器碼,發現并沒有同步代碼相關的生成。這是因為 JIT 在分析之后,發現針對 new Object() 這個對象并沒有發生線程競爭的情況,則會把這部分的同步直接給優化掉。我們在代碼層次做了一些無用功,字節碼無法發現它,而 JIT 智能地找到了它并進行了優化。
因此,并不是所有的對象或者數組都會在堆上分配。由于 JIT 的存在,如果發現某些對象沒有逃逸出方法,那么就有可能被優化成棧分配。
#### intrinsic
另外一個不得不提的技術點那就是 intrinsic,這來源于一道面試題:為什么 String 類的 indexOf 方法,比我們使用相同代碼實現的方法,執行效率要高得多?
在翻看 JDK 的源碼時,能夠看到很多地方使用了 HotSpotIntrinsicCandidate 注解。比如 StringBuffer 的 append 方法:
```
?@Override
@HotSpotIntrinsicCandidate
public?synchronized?StringBuffer?append(char?c)?{
????????toStringCache?=?null;
????????super.append(c);
????????return?this;
}
```
被 @HotSpotIntrinsicCandidate 標注的方法,在 HotSpot 中都有一套高效的實現,該高效實現基于 CPU 指令,運行時,HotSpot 維護的高效實現會替代 JDK 的源碼實現,從而獲得更高的效率。
上面的問題中,我們往下跟蹤實現,可以發現 StringLatin1 類中的 indexOf 方法,同樣適用了 HotSpotIntrinsicCandidate 注解,原因也就在于此。
```
@HotSpotIntrinsicCandidate
????public?static?int?indexOf(byte[]?value,?byte[]?str)?{
????????if?(str.length?==?0)?{
????????????return?0;
????????}
????????if?(value.length?==?0)?{
????????????return?-1;
????????}
????????return?indexOf(value,?value.length,?str,?str.length,?0);
????}
????@HotSpotIntrinsicCandidate
????public?static?int?indexOf(byte[]?value,?int?valueCount,?byte[]?str,?int?strCount,?int?fromIndex)?{
????????byte?first?=?str[0];
```
JDK 中這種方法有接近 400 個,可以在 IDEA 中使用 Find Usages 找到它們。
#### 小結
JIT 是現代 JVM 主要的優化點,能夠顯著地增加程序的執行效率,從解釋執行到最高層次的 C2,一個數量級的性能提升也是有可能的。但即時編譯的過程是非常緩慢的,耗時間也費空間,所以這些優化操作會和解釋執行同時進行。
一般,方法首先會被解釋執行,然后被 3 層的 C1 編譯,最后被 4 層的 C2 編譯,這個過程也不是一蹴而就的。
常用的優化手段,有公共子表達式消除、數組范圍檢查消除、方法內聯、逃逸分析等。
其中,方法內聯通過將短小精悍的代碼融入到調用方法的執行邏輯里,來減少方法調用上的開支;逃逸分析通過分析變量的引用范圍,對象可能會使用棧上分配的方式來減少 GC 的壓力,或者使用標量替換來獲取更多的優化。
這個過程的執行細節并不是那么“確定”,在不同的 JVM 中,甚至在不同的 HotSpot 版本中,效果也不盡相同。
使用 JITWatch 工具,能夠看到字節碼和機器碼的對應關系,以及執行過程中的一系列優化操作。若想要了解這個工具的更多功能,可以點擊這里參考 wiki。
- 前言
- 開篇詞
- 基礎原理
- 第01講:一探究竟:為什么需要 JVM?它處在什么位置?
- 第02講:大廠面試題:你不得不掌握的 JVM 內存管理
- 第03講:大廠面試題:從覆蓋 JDK 的類開始掌握類的加載機制
- 第04講:動手實踐:從棧幀看字節碼是如何在 JVM 中進行流轉的
- 垃圾回收
- 第05講:大廠面試題:得心應手應對 OOM 的疑難雜癥
- 第06講:深入剖析:垃圾回收你真的了解嗎?(上)
- 第06講:深入剖析:垃圾回收你真的了解嗎?(下)
- 第07講:大廠面試題:有了 G1 還需要其他垃圾回收器嗎?
- 第08講:案例實戰:億級流量高并發下如何進行估算和調優
- 實戰部分
- 第09講:案例實戰:面對突如其來的 GC 問題如何下手解決
- 第10講:動手實踐:自己模擬 JVM 內存溢出場景
- 第11講:動手實踐:遇到問題不要慌,輕松搞定內存泄漏
- 第12講:工具進階:如何利用 MAT 找到問題發生的根本原因
- 第13講:動手實踐:讓面試官刮目相看的堆外內存排查
- 第14講:預警與解決:深入淺出 GC 監控與調優
- 第15講:案例分析:一個高死亡率的報表系統的優化之路
- 第16講:案例分析:分庫分表后,我的應用崩潰了
- 進階部分
- 第17講:動手實踐:從字節碼看方法調用的底層實現
- 第18講:大廠面試題:不要搞混 JMM 與 JVM
- 第19講:動手實踐:從字節碼看并發編程的底層實現
- 第20講:動手實踐:不為人熟知的字節碼指令
- 第21講:深入剖析:如何使用 Java Agent 技術對字節碼進行修改
- 第22講:動手實踐:JIT 參數配置如何影響程序運行?
- 第23講:案例分析:大型項目如何進行性能瓶頸調優?
- 彩蛋
- 第24講:未來:JVM 的歷史與展望
- 第25講:福利:常見 JVM 面試題補充