
本課時我們主要來看下這兩個高頻的面試考題:
* G1?的回收原理是什么?為什么 G1 比傳統 GC 回收性能好?
* 為什么 G1 如此完美仍然會有 ZGC?
我們在上一課時,簡要的介紹了 CMS 垃圾回收器,下面我們簡單回憶一下它的一個極端場景(而且是經常發生的場景)。
在發生 Minor GC 時,由于 Survivor 區已經放不下了,多出的對象只能提升(promotion)到老年代。但是此時老年代因為空間碎片的緣故,會發生 concurrent mode failure 的錯誤。這個時候,就需要降級為 Serail Old 垃圾回收器進行收集。這就是比 concurrent mode failure 更加嚴重的 promotion failed 問題。
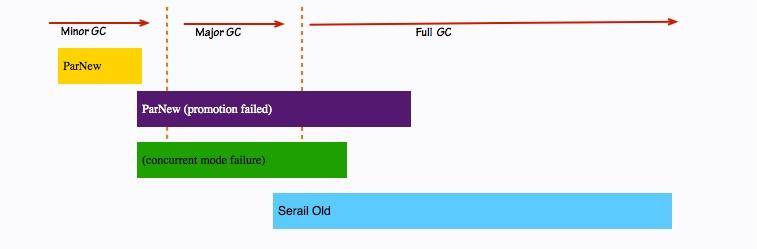
一次簡單的 Major GC,竟然能演化成耗時最長的 Full GC。最要命的是,這個停頓時間是不可預知的。
有沒有一種辦法,能夠首先定義一個停頓時間,然后反向推算收集內容呢?就像是領導在年初制定 KPI 一樣,分配的任務多就多干些,分配的任務少就少干點。
很久之前就有領導教導過我,如果你列的目標太大,看起來無法完成,不要怕。有一個叫作里程碑的名詞,可以讓我們以小跑的姿態,完成一次馬拉松。
G1 的思路說起來也類似,它不要求每次都把垃圾清理的干干凈凈,它只是努力做它認為對的事情。
我們要求 G1,在任意 1 秒的時間內,停頓不得超過 10ms,這就是在給它制定 KPI。G1 會盡量達成這個目標,它能夠推算出本次要收集的大體區域,以增量的方式完成收集。
這也是使用 G1 垃圾回收器不得不設置的一個參數:
```
-XX:MaxGCPauseMillis=10
```
#### 為什么叫 G1
G1 的目標是用來干掉 CMS 的,它同樣是一款軟實時垃圾回收器。相比 CMS,G1 的使用更加人性化。比如,CMS 垃圾回收器的相關參數有 72 個,而 G1 的參數只有 26 個。
G1 的全稱是 Garbage-First GC,為了達成上面制定的 KPI,它和前面介紹的垃圾回收器,在對堆的劃分上有一些不同。
其他的回收器,都是對某個年代的整體收集,收集時間上自然不好控制。G1 把堆切成了很多份,把每一份當作一個小目標,部分上目標很容易達成。
那又有一個面試題來啦:G1 有年輕代和老年代的區分嗎?
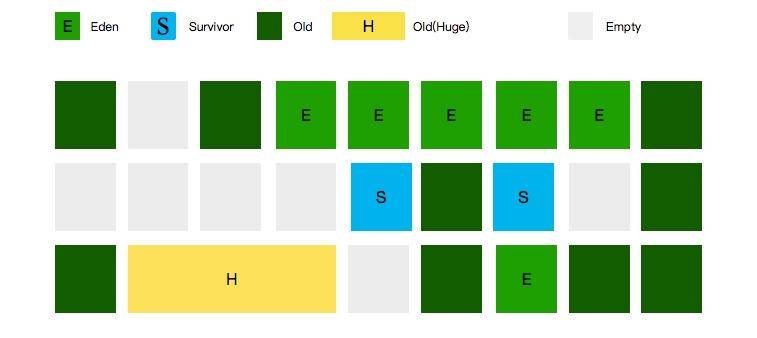
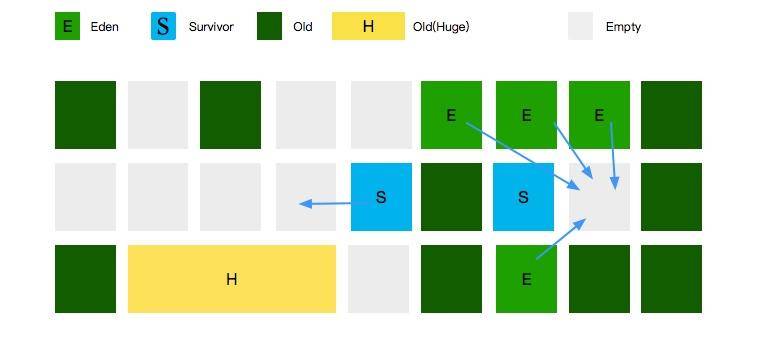
如圖所示,G1 也是有 Eden 區和 Survivor 區的概念的,只不過它們在內存上不是連續的,而是由一小份一小份組成的。
這一小份區域的大小是固定的,名字叫作小堆區(Region)。小堆區可以是 Eden 區,也可以是 Survivor 區,還可以是 Old 區。所以 G1 的年輕代和老年代的概念都是邏輯上的。
每一塊 Region,大小都是一致的,它的數值是在 1M 到 32M 字節之間的一個 2 的冪值數。
但假如我的對象太大,一個 Region 放不下了怎么辦?注意圖中有一塊面積很大的黃色區域,它的名字叫作 Humongous Region,大小超過 Region 50% 的對象,將會在這里分配。
Region 的大小,可以通過參數進行設置:
```
-XX:G1HeapRegionSize=<N>M
```
那么,回收的時候,到底回收哪些小堆區呢?是隨機的么?
這當然不是。事實上,垃圾最多的小堆區,會被優先收集。這就是 G1 名字的由來。
#### G1 的垃圾回收過程
在邏輯上,G1 分為年輕代和老年代,但它的年輕代和老年代比例,并不是那么“固定”,為了達到 MaxGCPauseMillis 所規定的效果,G1 會自動調整兩者之間的比例。
如果你強行使用 -Xmn 或者 -XX:NewRatio 去設定它們的比例的話,我們給 G1 設定的這個目標將會失效。
G1 的回收過程主要分為 3 類:
* (1)G1“年輕代”的垃圾回收,同樣叫 Minor GC,這個過程和我們前面描述的類似,發生時機就是 Eden 區滿的時候。
* (2)老年代的垃圾收集,嚴格上來說其實不算是收集,它是一個“并發標記”的過程,順便清理了一點點對象。
* (3)真正的清理,發生在“混合模式”,它不止清理年輕代,還會將老年代的一部分區域進行清理。
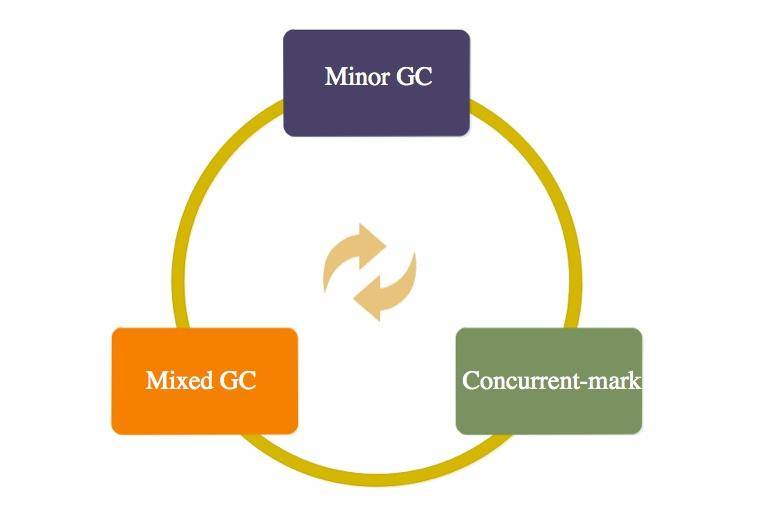
在 GC 日志里,這個過程描述特別有意思,(1)的過程,叫作 [GC pause (G1 Evacuation Pause) (young),而(2)的過程,叫作 [GC pause (G1 Evacuation Pause) (mixed)。Evacuation 是轉移的意思,和 Copy 的意思有點類似。
這三種模式之間的間隔也是不固定的。比如,1 次 Minor GC 后,發生了一次并發標記,接著發生了 9 次 Mixed GC。
#### RSet
RSet 是一個空間換時間的數據結構。
在第 6 課時中,我們提到過一個叫作卡表(Card Table)的數據結構,用來解決跨代引用的問題。RSet 的功能與此類似,它的全稱是 Remembered Set,用于記錄和維護 Region 之間的對象引用關系。
但 RSet 與 Card Table 有些不同的地方。Card Table 是一種 points-out(我引用了誰的對象)的結構。而 RSet 記錄了其他 Region 中的對象引用本 Region 中對象的關系,屬于 points-into 結構(誰引用了我的對象),有點倒排索引的味道。
你可以把 RSet 理解成一個 Hash,key 是引用的 Region 地址,value 是引用它的對象的卡頁集合。
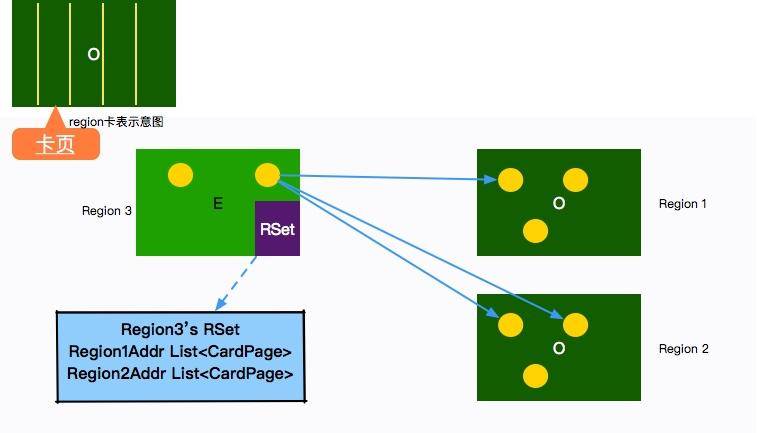
有了這個數據結構,在回收某個 Region 的時候,就不必對整個堆內存的對象進行掃描了。它使得部分收集成為了可能。
對于年輕代的 Region,它的 RSet 只保存了來自老年代的引用,這是因為年輕代的回收是針對所有年輕代 Region 的,沒必要畫蛇添足。所以說年輕代 Region 的 RSet 有可能是空的。
而對于老年代的 Region 來說,它的 RSet 也只會保存老年代對它的引用。這是因為老年代回收之前,會先對年輕代進行回收。這時,Eden 區變空了,而在回收過程中會掃描 Survivor 分區,所以也沒必要保存來自年輕代的引用。
RSet 通常會占用很大的空間,大約 5% 或者更高。不僅僅是空間方面,很多計算開銷也是比較大的。
事實上,為了維護 RSet,程序運行的過程中,寫入某個字段就會產生一個 post-write barrier 。為了減少這個開銷,將內容放入 RSet 的過程是異步的,而且經過了很多的優化:Write Barrier 把臟卡信息存放到本地緩沖區(local buffer),有專門的 GC 線程負責收集,并將相關信息傳給被引用 Region 的 RSet。
參數` -XX:G1ConcRefinementThreads` 或者 `-XX:ParallelGCThreads` 可以控制這個異步的過程。如果并發優化線程跟不上緩沖區的速度,就會在用戶進程上完成。
#### 具體回收過程
G1 還有一個 CSet 的概念。這個就比較好理解了,它的全稱是 Collection Set,即收集集合,保存一次 GC 中將執行垃圾回收的區間(Region)。GC 是在 CSet 中的所有存活數據(Live Data)都會被轉移。
了解了上面的數據結構,我們再來簡要看一下回收過程。
#### 年輕代回收
年輕代回收是一個 STW 的過程,它的跨代引用使用 RSet 數據結構來追溯,會一次性回收掉年輕代的所有 Region。
JVM 啟動時,G1 會先準備好 Eden 區,程序在運行過程中不斷創建對象到 Eden 區,當所有的 Eden 區都滿了,G1 會啟動一次年輕代垃圾回收過程。
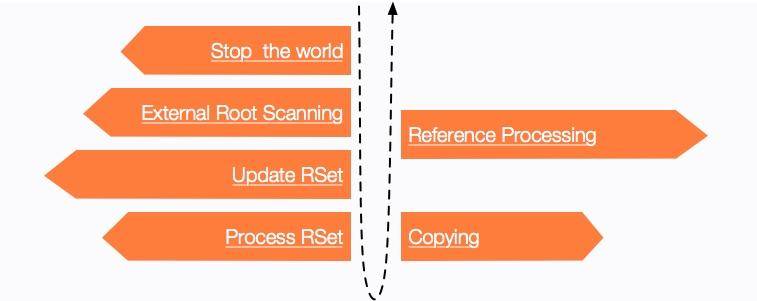
年輕代的收集包括下面的回收階段:
(1)掃描根
根,可以看作是我們前面介紹的 GC Roots,加上 RSet 記錄的其他 Region 的外部引用。
(2)更新 RS
處理 dirty card queue 中的卡頁,更新 RSet。此階段完成后,RSet 可以準確的反映老年代對所在的內存分段中對象的引用。可以看作是第一步的補充。
(3)處理 RS
識別被老年代對象指向的 Eden 中的對象,這些被指向的 Eden 中的對象被認為是存活的對象。
(4)復制對象
沒錯,收集算法依然使用的是 Copy 算法。
在這個階段,對象樹被遍歷,Eden 區內存段中存活的對象會被復制到 Survivor 區中空的 Region。這個過程和其他垃圾回收算法一樣,包括對象的年齡和晉升,無需做過多介紹。
(5)處理引用
處理 Soft、Weak、Phantom、Final、JNI Weak 等引用。結束收集。
它的大體示意圖如下所示。
#### 并發標記(Concurrent Marking)
當整個堆內存使用達到一定比例(默認是 45%),并發標記階段就會被啟動。這個比例也是可以調整的,通過參數 -XX:InitiatingHeapOccupancyPercent 進行配置。
Concurrent Marking 是為 Mixed GC 提供標記服務的,并不是一次 GC 過程的一個必須環節。這個過程和 CMS 垃圾回收器的回收過程非常類似,你可以類比 CMS 的回收過程看一下。具體標記過程如下:
(1)初始標記(Initial Mark)
這個過程共用了 Minor GC 的暫停,這是因為它們可以復用 root scan 操作。雖然是 STW 的,但是時間通常非常短。
(2)Root 區掃描(Root Region Scan)
(3)并發標記( Concurrent Mark)
這個階段從 GC Roots 開始對 heap 中的對象標記,標記線程與應用程序線程并行執行,并且收集各個 Region 的存活對象信息。
(4)重新標記(Remaking)
和 CMS 類似,也是 STW 的。標記那些在并發標記階段發生變化的對象。
(5)清理階段(Cleanup)
這個過程不需要 STW。如果發現 Region 里全是垃圾,在這個階段會立馬被清除掉。不全是垃圾的 Region,并不會被立馬處理,它會在 Mixed GC 階段,進行收集。
了解 CMS 垃圾回收器后,上面這個過程就比較好理解。但是還有一個疑問需要稍微提一下。
如果在并發標記階段,又有新的對象變化,該怎么辦?
這是由算法 SATB 保證的。SATB 的全稱是 Snapshot At The Beginning,它作用是保證在并發標記階段的正確性。
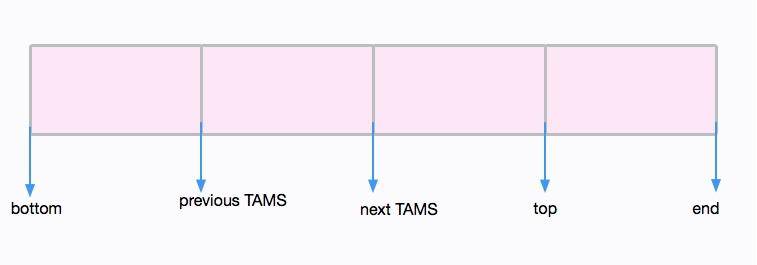
這個快照是邏輯上的,主要是有幾個指針,將 Region 分成個多個區段。如圖所示,并發標記期間分配的對象,都會在 next TAMS 和 top 之間。
#### 混合回收(Mixed GC)
能并發清理老年代中的整個整個的小堆區是一種最優情形。混合收集過程,不只清理年輕代,還會將一部分老年代區域也加入到 CSet 中。
通過 Concurrent Marking 階段,我們已經統計了老年代的垃圾占比。在 Minor GC 之后,如果判斷這個占比達到了某個閾值,下次就會觸發 Mixed GC。這個閾值,由 -XX:G1HeapWastePercent 參數進行設置(默認是堆大小的 5%)。因為這種情況下, GC 會花費很多的時間但是回收到的內存卻很少。所以這個參數也是可以調整 Mixed GC 的頻率的。
還有參數 G1MixedGCCountTarget,用于控制一次并發標記之后,最多執行 Mixed GC 的次數。
#### ZGC
你有沒有感覺,在系統切換到 G1 垃圾回收器之后,線上發生的嚴重 GC 問題已經非常少了?
這歸功于 G1 的預測模型和它創新的分區模式。但預測模型也會有失效的時候,它并不是總如我們期望的那樣運行,尤其是你給它定下一個苛刻的目標之后。
另外,如果應用的內存非常吃緊,對內存進行部分回收根本不夠,始終要進行整個 Heap 的回收,那么 G1 要做的工作量就一點也不會比其他垃圾回收器少,而且因為本身算法復雜了,還可能比其他回收器要差。
所以垃圾回收器本身的優化和升級,從來都沒有停止過。最新的 ZGC 垃圾回收器,就有 3 個令人振奮的 Flag:
1. 停頓時間不會超過 10ms;
2. 停頓時間不會隨著堆的增大而增大(不管多大的堆都能保持在 10ms 以下);
3. 可支持幾百 M,甚至幾 T 的堆大小(最大支持 4T)。
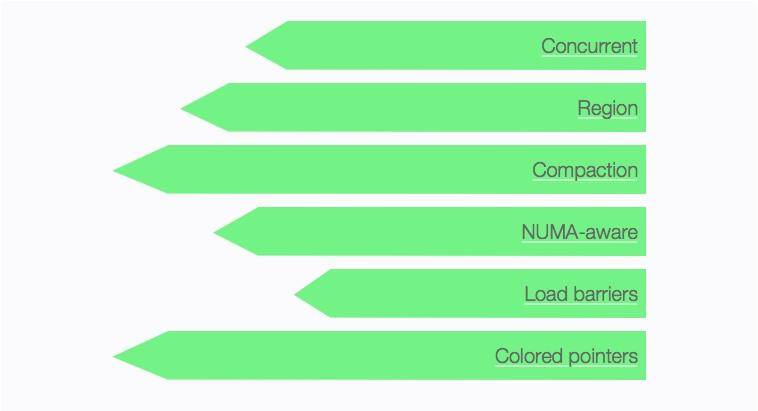
在 ZGC 中,連邏輯上的年輕代和老年代也去掉了,只分為一塊塊的 page,每次進行 GC 時,都會對 page 進行壓縮操作,所以沒有碎片問題。ZGC 還能感知 NUMA 架構,提高內存的訪問速度。與傳統的收集算法相比,ZGC 直接在對象的引用指針上做文章,用來標識對象的狀態,所以它只能用在 64 位的機器上。
現在在線上使用 ZGC 的還非常少。即使是用,也只能在 Linux 平臺上使用。等待它的普及,還需要一段時間。
#### 小結
本課時,我們簡要看了下 G1 垃圾回收器的回收過程,并著重看了一下底層的數據結構 RSet。基本思想很簡單,但實現細節卻特別多。這不是我們的重點,對 G1 詳細過程感興趣的,可以參考紙質書籍。我也會通過其他途徑分享一些細節,你也可以關注拉勾教育公眾號后進學習群與大家一起多多交流。
相對于 CMS,G1 有了更可靠的駕馭度。而且有 RSet 和 SATB 等算法的支撐,Remark 階段更加高效。
G1 最重要的概念,其實就是 Region。它采用分而治之,部分收集的思想,盡力達到我們給它設定的停頓目標。
G1 的垃圾回收過程分為三種,其中,并發標記階段,為更加復雜的 Mixed GC 階段做足了準備。
以下是一個線上運行系統的 JVM 參數樣例。這些參數,現在你都能看懂么?如果有問題可以在評論區討論。
```
JAVA_OPTS="$JAVA_OPTS?-XX:NewRatio=2?-XX:G1HeapRegionSize=8m?-XX:MetaspaceSize
=256m?-XX:MaxMetaspaceSize=256m?-XX:MaxTenuringThreshold=10?-XX:+UseG1GC
?-XX:InitiatingHeapOccupancyPercent=45?-XX:MaxGCPauseMillis=200?-verbose:gc
??-XX:+PrintGCDetails?-XX:+PrintGCTimeStamps?-XX:+PrintReferenceGC
???-XX:+PrintAdaptiveSizePolicy?-XX:+UseGCLogFileRotation?-XX:NumberOfGCLogFiles=6
????-XX:GCLogFileSize=32m?-Xloggc:./var/run/gc.log.$(date?+%Y%m%d%H%M)
?????-XX:+HeapDumpOnOutOfMemoryError?-XX:HeapDumpPath=./var/run/heap-dump.hprof
??????-Dfile.encoding=UTF-8?-Dcom.sun.management.jmxremote?-Dcom.sun.management.
??????jmxremote.port=${JMX_PORT:-0}?-Dcom.sun.management.jmxremote.ssl=false
???????-Dcom.sun.management.jmxremote.authenticate=false"
```
#### 課后問答
* 1、有個疑惑,就是“每一塊 Region,大小都是一致的,但是后面又介紹了Humongous region,這個是不是比那些eden、survivor、old的region大呀”那到底是不是都大小一致的呀,我有點搞不懂。
答案:這個不沖突,小堆區是最小單元。Humongous是虛擬概念,包含了多個連續的小堆區。
- 前言
- 開篇詞
- 基礎原理
- 第01講:一探究竟:為什么需要 JVM?它處在什么位置?
- 第02講:大廠面試題:你不得不掌握的 JVM 內存管理
- 第03講:大廠面試題:從覆蓋 JDK 的類開始掌握類的加載機制
- 第04講:動手實踐:從棧幀看字節碼是如何在 JVM 中進行流轉的
- 垃圾回收
- 第05講:大廠面試題:得心應手應對 OOM 的疑難雜癥
- 第06講:深入剖析:垃圾回收你真的了解嗎?(上)
- 第06講:深入剖析:垃圾回收你真的了解嗎?(下)
- 第07講:大廠面試題:有了 G1 還需要其他垃圾回收器嗎?
- 第08講:案例實戰:億級流量高并發下如何進行估算和調優
- 實戰部分
- 第09講:案例實戰:面對突如其來的 GC 問題如何下手解決
- 第10講:動手實踐:自己模擬 JVM 內存溢出場景
- 第11講:動手實踐:遇到問題不要慌,輕松搞定內存泄漏
- 第12講:工具進階:如何利用 MAT 找到問題發生的根本原因
- 第13講:動手實踐:讓面試官刮目相看的堆外內存排查
- 第14講:預警與解決:深入淺出 GC 監控與調優
- 第15講:案例分析:一個高死亡率的報表系統的優化之路
- 第16講:案例分析:分庫分表后,我的應用崩潰了
- 進階部分
- 第17講:動手實踐:從字節碼看方法調用的底層實現
- 第18講:大廠面試題:不要搞混 JMM 與 JVM
- 第19講:動手實踐:從字節碼看并發編程的底層實現
- 第20講:動手實踐:不為人熟知的字節碼指令
- 第21講:深入剖析:如何使用 Java Agent 技術對字節碼進行修改
- 第22講:動手實踐:JIT 參數配置如何影響程序運行?
- 第23講:案例分析:大型項目如何進行性能瓶頸調優?
- 彩蛋
- 第24講:未來:JVM 的歷史與展望
- 第25講:福利:常見 JVM 面試題補充