
由于上一課時篇幅比較多,我們在這一課時重點講解上一課時中提到的 CMS 垃圾回收器,讓你可以更好的理解垃圾回收的過程。
在這里首先給你介紹幾個概念:
* Minor GC:發生在年輕代的 GC。
* Major GC:發生在老年代的 GC。
* Full GC:全堆垃圾回收。比如 Metaspace 區引起年輕代和老年代的回收。
理解了這三個概念,我們再往下看。
CMS 的全稱是 Mostly Concurrent Mark and Sweep Garbage Collector(主要并發-標記-清除-垃圾收集器),它在年輕代使用復制算法,而對老年代使用標記-清除算法。你可以看到,在老年代階段,比起 Mark-Sweep,它多了一個并發字樣。
CMS 的設計目標,是避免在老年代 GC 時出現長時間的卡頓(但它并不是一個老年代回收器)。如果你不希望有長時間的停頓,同時你的 CPU 資源也比較豐富,使用 CMS 是比較合適的。
CMS 使用的是 Sweep 而不是 Compact,所以它的主要問題是碎片化。隨著 JVM 的長時間運行,碎片化會越來越嚴重,只有通過 Full GC 才能完成整理。
為什么 CMS 能夠獲得更小的停頓時間呢?主要是因為它把最耗時的一些操作,做成了和應用線程并行。接下來我們簡要看一下這個過程。
#### CMS 回收過程
#### 初始標記(Initial Mark)
初始標記階段,只標記直接關聯 GC root 的對象,不用向下追溯。因為最耗時的就在 tracing 階段,這樣就極大地縮短了初始標記時間。
這個過程是 STW 的,但由于只是標記第一層,所以速度是很快的。
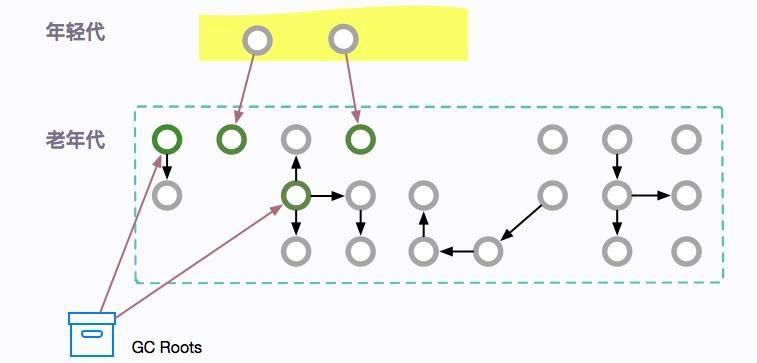
注意,這里除了要標記相關的 GC Roots 之外,還要標記年輕代中對象的引用,這也是 CMS 老年代回收,依然要掃描新生代的原因。
#### 并發標記(Concurrent Mark)
在初始標記的基礎上,進行并發標記。這一步驟主要是 tracinng 的過程,用于標記所有可達的對象。
這個過程會持續比較長的時間,但卻可以和用戶線程并行。在這個階段的執行過程中,可能會產生很多變化:
* 有些對象,從新生代晉升到了老年代;
* 有些對象,直接分配到了老年代;
* 老年代或者新生代的對象引用發生了變化。
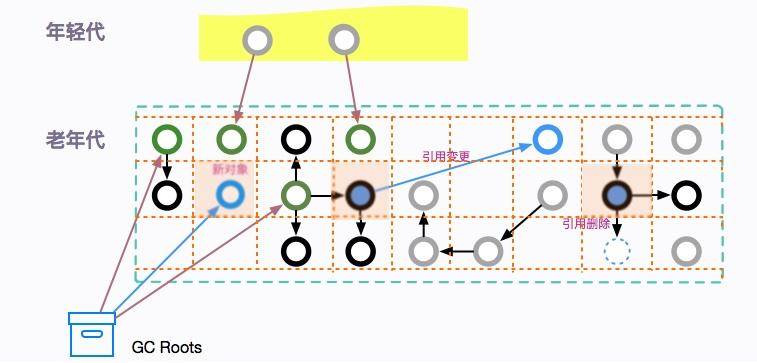
還記得我們在上一課時提到的卡片標記么?在這個階段受到影響的老年代對象所對應的卡頁,會被標記為 dirty,用于后續重新標記階段的掃描。
#### 并發預清理(Concurrent Preclean)
并發預清理也是不需要 STW 的,目的是為了讓重新標記階段的 STW 盡可能短。這個時候,老年代中被標記為 dirty 的卡頁中的對象,就會被重新標記,然后清除掉 dirty 的狀態。
由于這個階段也是可以并發的,在執行過程中引用關系依然會發生一些變化。我們可以假定這個清理動作是第一次清理。
所以重新標記階段,有可能還會有處于 dirty 狀態的卡頁。
#### 并發可取消的預清理(Concurrent Abortable Preclean)
因為重新標記是需要 STW 的,所以會有很多次預清理動作。并發可取消的預清理,顧名思義,在滿足某些條件的時候,可以終止,比如迭代次數、有用工作量、消耗的系統時間等。
這個階段是可選的。換句話說,這個階段是“并發預清理”階段的一種優化。
這個階段的第一個意圖,是避免回掃年輕代的大量對象;另外一個意圖,就是當滿足最終標記的條件時,自動退出。
我們在前面說過,標記動作是需要掃描年輕代的。如果年輕代的對象太多,肯定會嚴重影響標記的時間。如果在此之前能夠進行一次 Minor GC,情況會不會變得好了許多?
CMS 提供了參數 CMSScavengeBeforeRemark,可以在進入重新標記之前強制進行一次 Minor GC。
但請你記住一件事情,GC 的停頓是不分什么年輕代老年代的。設置了上面的參數,可能會在一個比較長的 Minor GC 之后,緊跟著一個 CMS 的 Remark,它們都是 STW 的。
這部分有非常多的配置參數。但是一般都不會去改動。
#### 最終標記(Final Remark)
通常 CMS 會嘗試在年輕代盡可能空的情況下運行 Final Remark 階段,以免接連多次發生 STW 事件。
這是 CMS 垃圾回收階段的第二次 STW 階段,目標是完成老年代中所有存活對象的標記。我們前面多輪的 preclean 階段,一直在和應用線程玩追趕游戲,有可能跟不上引用的變化速度。本輪的標記動作就需要 STW 來處理這些情況。
如果預處理階段做的不夠好,會顯著增加本階段的 STW 時間。你可以看到,CMS 垃圾回收器把回收過程分了多個部分,而影響最大的不是 STW 階段本身,而是它之前的預處理動作。
#### 并發清除(Concurrent Sweep)
此階段用戶線程被重新激活,目標是刪掉不可達的對象,并回收它們的空間。
由于 CMS 并發清理階段用戶線程還在運行中,伴隨程序運行自然就還會有新的垃圾不斷產生,這一部分垃圾出現在標記過程之后,CMS 無法在當次 GC 中處理掉它們,只好留待下一次 GC 時再清理掉。這一部分垃圾就稱為“浮動垃圾”。
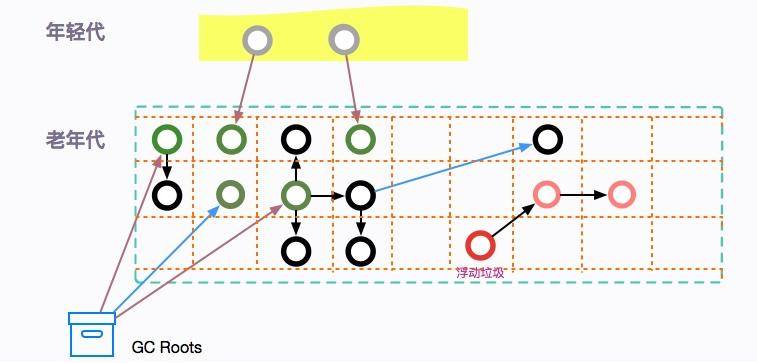
#### 并發重置(Concurrent Reset)
此階段與應用程序并發執行,重置 CMS 算法相關的內部數據,為下一次 GC 循環做準備。
### 內存碎片
由于 CMS 在執行過程中,用戶線程還需要運行,那就需要保證有充足的內存空間供用戶使用。如果等到老年代空間快滿了,再開啟這個回收過程,用戶線程可能會產生“Concurrent Mode Failure”的錯誤,這時會臨時啟用 Serial Old 收集器來重新進行老年代的垃圾收集,這樣停頓時間就很長了(STW)。
這部分空間預留,一般在 30% 左右即可,那么能用的大概只有 70%。參數 -XX:CMSInitiatingOccupancyFraction 用來配置這個比例(記得要首先開啟參數UseCMSInitiatingOccupancyOnly)。也就是說,當老年代的使用率達到 70%,就會觸發 GC 了。如果你的系統老年代增長不是太快,可以調高這個參數,降低內存回收的次數。
其實,這個比率非常不好設置。一般在堆大小小于 2GB 的時候,都不會考慮 CMS 垃圾回收器。
另外,CMS 對老年代回收的時候,并沒有內存的整理階段。這就造成程序在長時間運行之后,碎片太多。如果你申請一個稍大的對象,就會引起分配失敗。
CMS 提供了兩個參數來解決這個問題:
* (1) UseCMSCompactAtFullCollection(默認開啟),表示在要進行 Full GC 的時候,進行內存碎片整理。內存整理的過程是無法并發的,所以停頓時間會變長。
* (2)CMSFullGCsBeforeCompaction,每隔多少次不壓縮的 Full GC 后,執行一次帶壓縮的 Full GC。默認值為 0,表示每次進入 Full GC 時都進行碎片整理。
所以,預留空間加上內存的碎片,使用 CMS 垃圾回收器的老年代,留給我們的空間就不是太多,這也是 CMS 的一個弱點。

### 小結
一般的,我們將 CMS 垃圾回收器分為四個階段:
1. 初始標記
2. 并發標記
3. 重新標記
4. 并發清理
我們總結一下 CMS 中都會有哪些停頓(STW):
1. 初始標記,這部分的停頓時間較短;
2. Minor GC(可選),在預處理階段對年輕代的回收,停頓由年輕代決定;
3. 重新標記,由于 preclaen 階段的介入,這部分停頓也較短;
4. Serial-Old 收集老年代的停頓,主要發生在預留空間不足的情況下,時間會持續很長;
5. Full GC,永久代空間耗盡時的操作,由于會有整理階段,持續時間較長。
在發生 GC 問題時,你一定要明確發生在哪個階段,然后對癥下藥。gclog 通常能夠非常詳細的表現這個過程。
我們再來看一下 CMS 的 trade-off。
**優勢:**
低延遲,尤其對于大堆來說。大部分垃圾回收過程并發執行。
**劣勢:**
1. 內存碎片問題。Full GC 的整理階段,會造成較長時間的停頓。
2. 需要預留空間,用來分配收集階段產生的“浮動垃圾”。
3. 使用更多的 CPU 資源,在應用運行的同時進行堆掃描。
CMS 是一種高度可配置的復雜算法,因此給 JDK 中的 GC 代碼庫帶來了很多復雜性。由于 G1 和 ZGC 的產生,CMS 已經在被廢棄的路上。但是,目前仍然有大部分應用是運行在 Java8 及以下的版本之上,針對它的優化,還是要持續很長一段時間。
### 課后問答
* 1、第06講(上)中 老年代垃圾收集器 的第三種是CMS,而該講(06下)卻說CMS【但它并不是一個老年代回收器】。那究竟是 or 不是?
答案:初步印象是,但實際上不是。根據CMS的各個收集過程,它其實是一個涉及年輕代和老年代的綜合性垃圾回收器。不過它主要是作用在老年代的,所以一般交流說是,較真起來并不是。
* 2、在其他課程里邊,有個老師說major gc就是full gc,所以他講課直接就說的是full gc發生在老年代,但是本文中把major gc和full gc分開了,我又迷惑了,這兩個到底有沒有區別呀?
答案:當然有區別。full gc > major gc。比如,full gc=major gc + metaspace的回收。
* 3、不同的垃圾收集器中的GC都是一樣的的嗎。比如CMS的FullGC 和 其他組合的垃圾收器的FullGC 是同一個概念嗎?
答案:基于分代的垃圾回收器都有三個概念:MinorGC、MajorGC、FullGC,三個概念都是相同的。
* 4、CMS 回收過程初始標記(Initial Mark)這里是標記gc roots直接可達的老年代對象、新生代引用的老年代對象?
答案:是的。
- 前言
- 開篇詞
- 基礎原理
- 第01講:一探究竟:為什么需要 JVM?它處在什么位置?
- 第02講:大廠面試題:你不得不掌握的 JVM 內存管理
- 第03講:大廠面試題:從覆蓋 JDK 的類開始掌握類的加載機制
- 第04講:動手實踐:從棧幀看字節碼是如何在 JVM 中進行流轉的
- 垃圾回收
- 第05講:大廠面試題:得心應手應對 OOM 的疑難雜癥
- 第06講:深入剖析:垃圾回收你真的了解嗎?(上)
- 第06講:深入剖析:垃圾回收你真的了解嗎?(下)
- 第07講:大廠面試題:有了 G1 還需要其他垃圾回收器嗎?
- 第08講:案例實戰:億級流量高并發下如何進行估算和調優
- 實戰部分
- 第09講:案例實戰:面對突如其來的 GC 問題如何下手解決
- 第10講:動手實踐:自己模擬 JVM 內存溢出場景
- 第11講:動手實踐:遇到問題不要慌,輕松搞定內存泄漏
- 第12講:工具進階:如何利用 MAT 找到問題發生的根本原因
- 第13講:動手實踐:讓面試官刮目相看的堆外內存排查
- 第14講:預警與解決:深入淺出 GC 監控與調優
- 第15講:案例分析:一個高死亡率的報表系統的優化之路
- 第16講:案例分析:分庫分表后,我的應用崩潰了
- 進階部分
- 第17講:動手實踐:從字節碼看方法調用的底層實現
- 第18講:大廠面試題:不要搞混 JMM 與 JVM
- 第19講:動手實踐:從字節碼看并發編程的底層實現
- 第20講:動手實踐:不為人熟知的字節碼指令
- 第21講:深入剖析:如何使用 Java Agent 技術對字節碼進行修改
- 第22講:動手實踐:JIT 參數配置如何影響程序運行?
- 第23講:案例分析:大型項目如何進行性能瓶頸調優?
- 彩蛋
- 第24講:未來:JVM 的歷史與展望
- 第25講:福利:常見 JVM 面試題補充