
本課時我們主要分享一個實踐案例:從字節碼看并發編程的底層實現。
我們在上一課時中簡單學習了 JMM 的概念,知道了 Java 語言中一些默認的 happens-before 規則,是靠內存屏障完成的。其中的 lock 和 unlock 兩個 Action,就屬于粒度最大的兩個操作。
如下圖所示,Java 中的多線程,第一類是 Thread 類。它有三種實現方式:第 1 種是通過繼承 Thread 覆蓋它的 run 方法;第 2 種是通過 Runnable 接口,實現它的 run 方法;而第 3 種是通過創建線程,就是通過線程池的方法去創建。
多線程除了增加任務的執行速度,同樣也有共享變量的同步問題。傳統的線程同步方式,是使用 synchronized 關鍵字,或者 wait、notify 方法等,比如我們在第 15 課時中所介紹的,使用 jstack 命令可以觀測到各種線程的狀態。在目前的并發編程中,使用 concurrent 包里的工具更多一些。
#### 線程模型
我們首先來看一下 JVM 的線程模型,以及它和操作系統進程之間的關系。
如下圖所示,對于 Hotspot 來說,每一個 Java 線程,都會映射到一條輕量級進程中(LWP,Light Weight Process)。輕量級進程是用戶進程調用系統內核所提供的一套接口,實際上它還需要調用更加底層的內核線程(KLT,Kernel-Level Thread)。而具體的功能,比如創建、同步等,則需要進行系統調用。
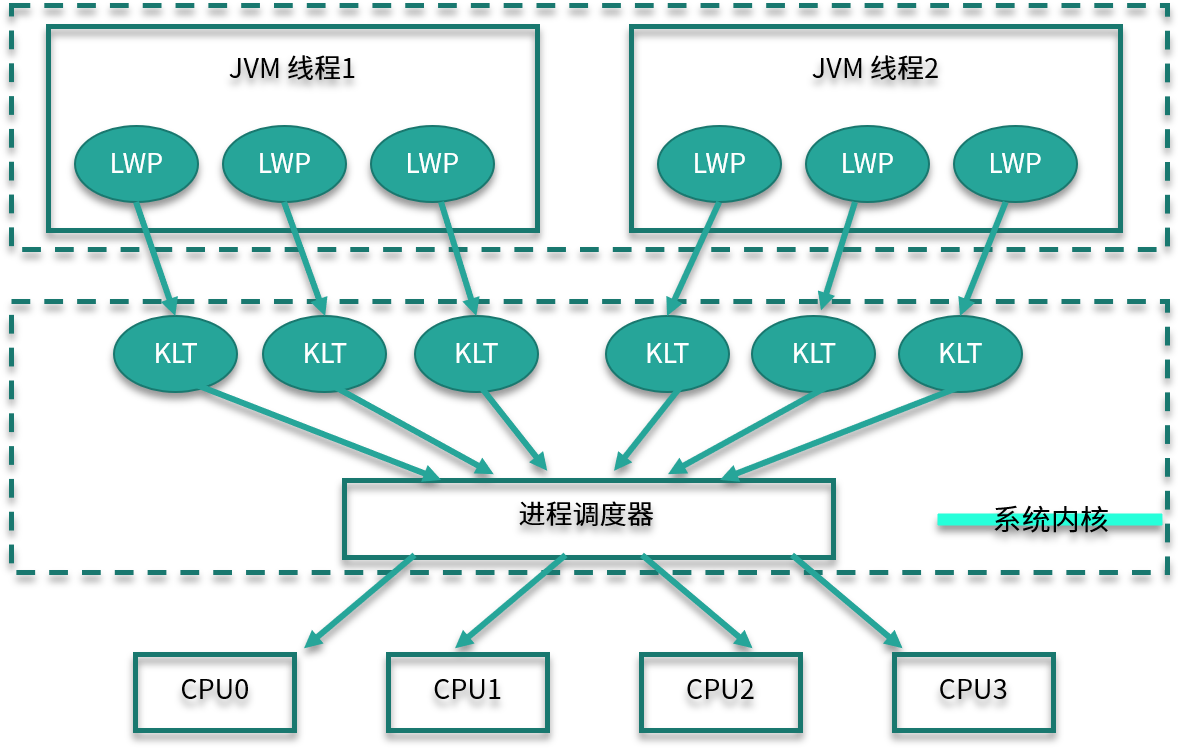
這些系統調用的操作,代價都比較高,需要在用戶態(User Mode)和內核態(Kernel Mode)中來回切換,也就是我們常說的線程上下文切換( CS,Context Switch)。
使用 vmstat 命令能夠方便地觀測到這個數值。
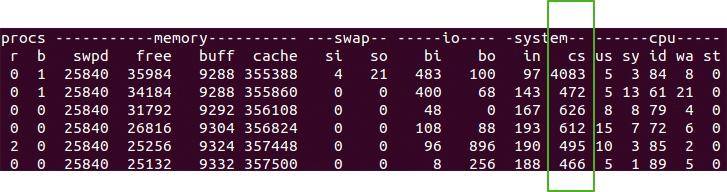
Java 在保證正確的前提下,要想高效并發,就要盡量減少上下文的切換。
一般有下面幾種做法來減少上下文的切換:
* CAS 算法,比如 Java 的 Atomic 類,如果使用 CAS 來更新數據,則不需要加鎖;
* 減少鎖粒度,多線程競爭會引起上下文的頻繁切換,如果在處理數據的時候,能夠將數據分段,即可減少競爭,Java 的 ConcurrentHashMap、LongAddr 等就是這樣的思路;
* 協程,在單線程里實現多任務調度,并在單線程里支持多個任務之間的切換;
* 對加鎖的對象進行智能判斷,讓操作更加輕量級。
CAS 和無鎖并發一般是建立在 concurrent 包里面的 AQS 模型之上,大多數屬于 Java 語言層面上的知識點。本課時在對其進行簡單的描述后,會把重點放在普通鎖的優化上。
#### CAS
CAS(Compare And Swap,比較并替換)機制中使用了 3 個基本操作數:內存地址 V、舊的預期值 A 和要修改的新值 B。更新一個變量時,只有當變量的預期值 A 和內存地址 V 當中的實際值相同時,才會將內存地址 V 對應的值修改為 B。
如果修改不成功,CAS 將不斷重試。
拿 AtomicInteger 類來說,相關的代碼如下:
```
public?final?boolean?compareAndSet(int?expectedValue,?int?newValue)?{
????????return?U.compareAndSetInt(this,?VALUE,?expectedValue,?newValue);
????}
```
可以看到,這個操作,是由 jdk.internal.misc.Unsafe 類進行操作的,而這是一個 native 方法:
```
@HotSpotIntrinsicCandidate
????public?final?native?boolean?compareAndSetInt(Object?o,?long?offset,
?????????????????????????????????????????????????int?expected,
?????????????????????????????????????????????????int?x);
```
我們繼續向下跟蹤,在 Linux 機器上參照 os_cpu/linux_x86/atomic_linux_x86.hpp:
```
template<>
template<typename?T>
inline?T?Atomic::PlatformCmpxchg<4>::operator()(T?exchange_value,
????????????????????????????????????????????????T?volatile*?dest,
????????????????????????????????????????????????T?compare_value,
????????????????????????????????????????????????atomic_memory_order?/*?order?*/)?const?{
??STATIC_ASSERT(4?==?sizeof(T));
??__asm__?volatile?("lock?cmpxchgl?%1,(%3)"
????????????????????:?"=a"?(exchange_value)
????????????????????:?"r"?(exchange_value),?"a"?(compare_value),?"r"?(dest)
????????????????????:?"cc",?"memory");
??return?exchange_value;
}
```
可以看到,最底層的調用是匯編語言,而最重要的就是 cmpxchgl 指令,到這里沒法再往下找代碼了,也就是說 CAS 的原子性實際上是硬件 CPU 直接實現的。
#### synchronized
* [ ] 字節碼
synchronized 可以在是多線程中使用的最多的關鍵字了。在開始介紹之前,請思考一個問題:在執行速度方面,是基于 CAS 的 Lock 效率高一些,還是同步關鍵字效率高一些?
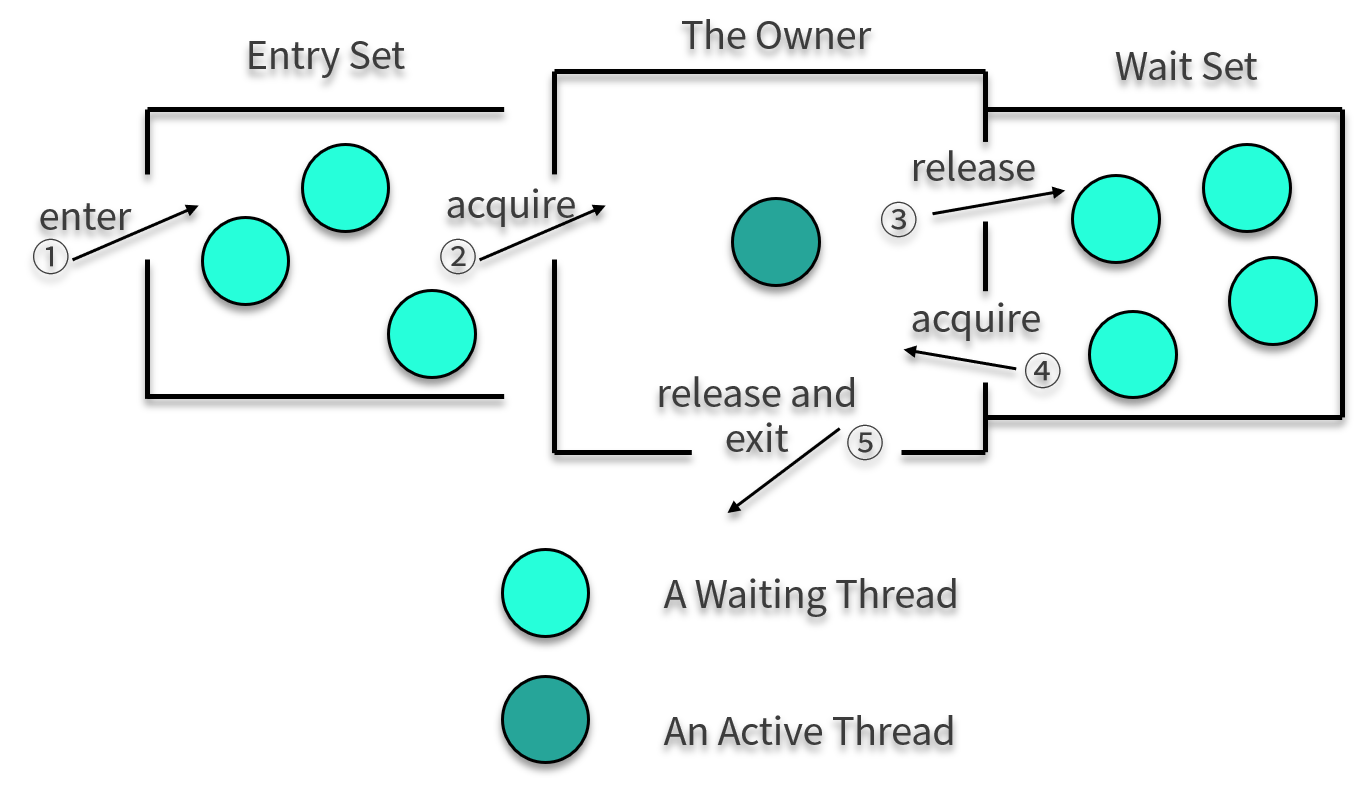
synchronized 關鍵字給代碼或者方法上鎖時,會有顯示或者隱藏的上鎖對象。當一個線程試圖訪問同步代碼塊時,它必須先得到鎖,而在退出或拋出異常時必須釋放鎖。
* 給普通方法加鎖時,上鎖的對象是 this,如代碼中的方法 m1 。
* 給靜態方法加鎖時,鎖的是 class 對象,如代碼中的方法 m2 。
* 給代碼塊加鎖時,可以指定一個具體的對象。
關于對象對鎖的爭奪,我們依然拿前面講的一張圖來看一下這個過程。
下面我們來看一段簡單的代碼,并觀測一下它的字節碼。
```
public?class?SynchronizedDemo?{
synchronized?void?m1()?{
System.out.println("m1");
}
????static?synchronized?void??m2()?{
System.out.println("m2");
}
final?Object?lock?=?new?Object();
void?doLock()?{
synchronized?(lock)?{
System.out.println("lock");
}
}
}
```
下面是普通方法 m1 的字節碼。
```
synchronized?void?m1();
????descriptor:?()V
????flags:?ACC_SYNCHRONIZED
????Code:
??????stack=2,?locals=1,?args_size=1
?????????0:?getstatic?????#4?????????????????
?????????3:?ldc???????????#5?????????????????????????
?????????5:?invokevirtual?#6???????????
?????????8:?return
```
可以看到,在字節碼的體現上,它只給方法加了一個 flag:ACC_SYNCHRONIZED。
靜態方法 m2 和 m1 區別不大,只不過 flags 上多了一個參數:ACC_STATIC。
相比較起來,doLock 方法就麻煩了一些,其中出現了 monitorenter 和 monitorexit 等字節碼指令。
```
void?doLock();
????descriptor:?()V
????flags:
????Code:
??????stack=2,?locals=3,?args_size=1
?????????0:?aload_0
?????????1:?getfield??????#3??????????????????//?Field?lock:Ljava/lang/Object;
?????????4:?dup
?????????5:?astore_1
?????????6:?monitorenter
?????????7:?getstatic?????#4??????????????????//?Field?java/lang/System.out:Ljava/io/PrintStream;
????????10:?ldc???????????#8??????????????????//?String?lock
????????12:?invokevirtual?#6??????????????????//?Method?java/io/PrintStream.println:(Ljava/lang/String;)V
????????15:?aload_1
????????16:?monitorexit
????????17:?goto??????????25
????????20:?astore_2
????????21:?aload_1
????????22:?monitorexit
????????23:?aload_2
????????24:?athrow
????????25:?return
??????Exception?table:
?????????from????to??target?type
?????????????7????17????20???any
????????????20????23????20???any
```
很多人都認為,synchronized 是一種悲觀鎖、一種重量級鎖;而基于 CAS 的 AQS 是一種樂觀鎖,這種理解并不全對。JDK1.6 之后,JVM 對同步關鍵字進行了很多的優化,這把鎖有了不同的狀態,大多數情況下的效率,已經和 concurrent 包下的 Lock 不相上下了,甚至更高。
#### 對象內存布局
說到 synchronized 加鎖原理,就不得不先說 Java 對象在內存中的布局,Java 對象內存布局如下圖所示。

我來分別解釋一下各個部分的含義。
* Mark Word:用來存儲 hashCode、GC 分代年齡、鎖類型標記、偏向鎖線程 ID、CAS 鎖指向線程 LockRecord 的指針等,synconized 鎖的機制與這里密切相關,這有點像 TCP/IP 中的協議頭。
* Class Pointer:用來存儲對象指向它的類元數據指針、JVM 就是通過它來確定是哪個 Class 的實例。
* Instance Data:存儲的是對象真正有效的信息,比如對象中所有字段的內容。
* Padding:HostSpot 規定對象的起始地址必須是 8 字節的整數倍,這是為了高效讀取對象而做的一種“對齊”操作。
#### 可重入鎖
synchronized 是一把可重入鎖。因此,在一個線程使用 synchronized 方法時可以調用該對象的另一個 synchronized 方法,即一個線程得到一個對象鎖后再次請求該對象鎖,是可以永遠拿到鎖的。
Java 中線程獲得對象鎖的操作是以線程而不是以調用為單位的。synchronized 鎖的對象頭的 Mark Work 中會記錄該鎖的線程持有者和計數器。當一個線程請求成功后,JVM 會記下持有鎖的線程,并將計數器計為 1 。此時如果有其他線程請求該鎖,則必須等待。而該持有鎖的線程如果再次請求這個鎖,就可以再次拿到這個鎖,同時計數器會遞增。當線程退出一個 ?synchronized 方法/塊時,計數器會遞減,如果計數器為 0 則釋放該鎖。
#### 鎖升級
根據使用情況,鎖升級大體可以按照下面的路徑:偏向鎖→輕量級鎖→重量級鎖,鎖只能升級不能降級,所以一旦鎖升級為重量級鎖,就只能依靠操作系統進行調度。
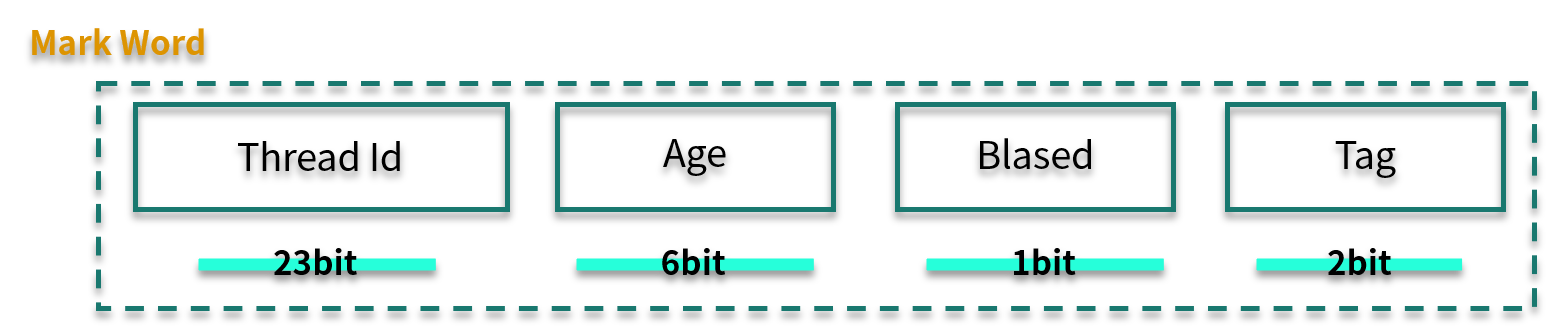
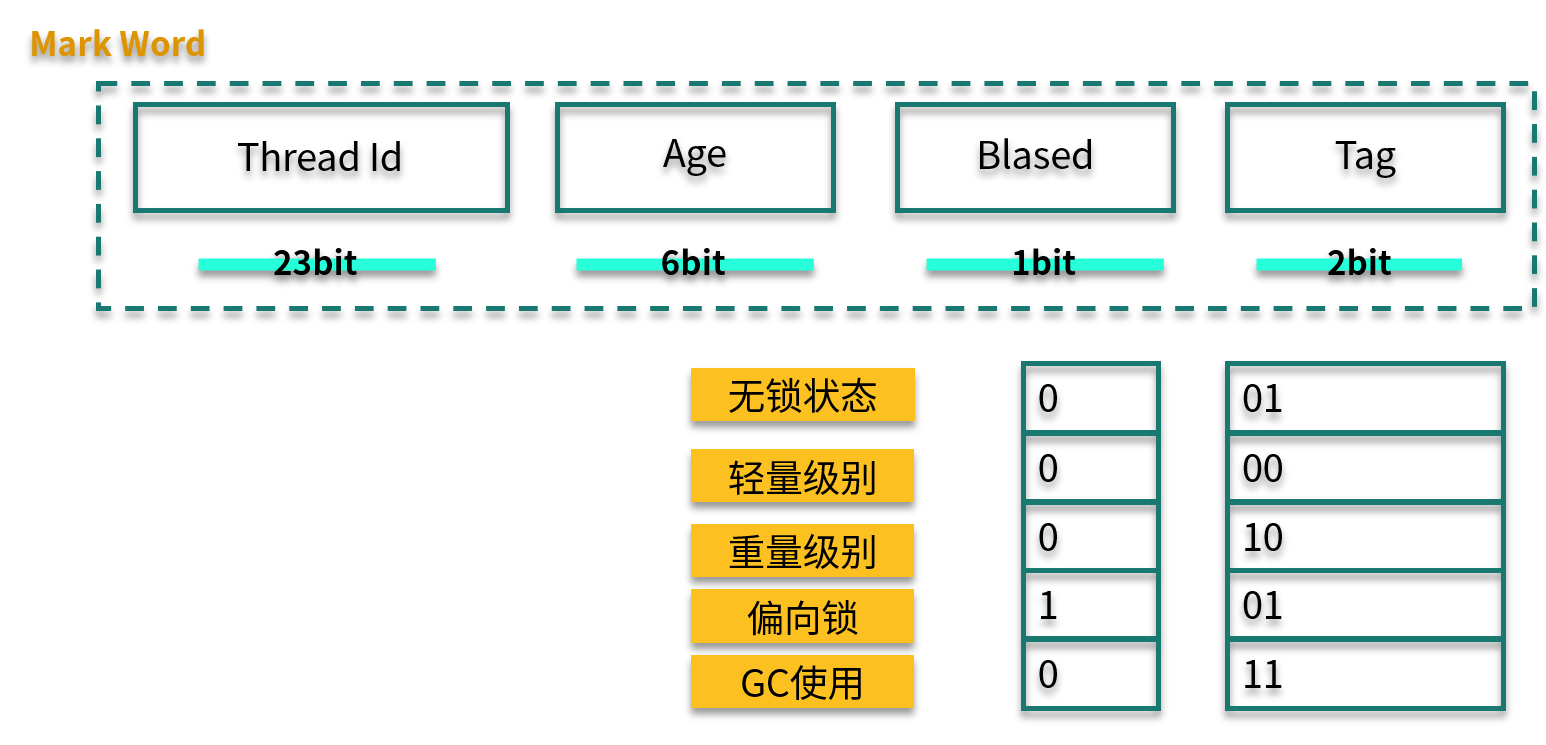
我們再看一下 Mark Word 的結構。其中,Biased 有 1 bit 大小,Tag 有 2 bit 大小,鎖升級就是通過 Thread Id、Biased、Tag 這三個變量值來判斷的。
#### 偏向鎖
偏向鎖,其實是一把偏心鎖(一般不這么描述)。在 JVM 中,當只有一個線程使用了鎖的情況下,偏向鎖才能夠保證更高的效率。
當第 1 個線程第一次訪問同步塊時,會先檢測對象頭 Mark Word 中的標志位(Tag)是否為 01,以此來判斷此時對象鎖是否處于無鎖狀態或者偏向鎖狀態(匿名偏向鎖)。
這也是鎖默認的狀態,線程一旦獲取了這把鎖,就會把自己的線程 ID 寫到 Mark Word 中,在其他線程來獲取這把鎖之前,該線程都處于偏向鎖狀態。
#### 輕量級鎖
當下一個線程參與到偏向鎖競爭時,會先判斷 Mark Word 中保存的線程 ID 是否與這個線程 ID 相等,如果不相等,則會立即撤銷偏向鎖,升級為輕量級鎖。
輕量級鎖的獲取是怎么進行的呢?它們使用的是自旋方式。
參與競爭的每個線程,會在自己的線程棧中生成一個 LockRecord ( LR ),然后每個線程通過 CAS(自旋)的操作將鎖對象頭中的 Mark Work 設置為指向自己的 LR 指針,哪個線程設置成功,就意味著哪個線程獲得鎖。在這種情況下,JVM 不會依賴內核進行線程調度。
當鎖處于輕量級鎖的狀態時,就不能夠再通過簡單的對比 Tag 值進行判斷了,每次對鎖的獲取,都需要通過自旋的操作。
當然,自旋也是面向不存在鎖競爭的場景,比如一個線程運行完了,另外一個線程去獲取這把鎖。但如果自旋失敗達到一定的次數(JVM 自動管理)時,就會膨脹為重量級鎖。
#### 重量級鎖
重量級鎖即為我們對 synchronized 的直觀認識,在這種情況下,線程會掛起,進入到操作系統內核態,等待操作系統的調度,然后再映射回用戶態。系統調用是昂貴的,重量級鎖的名稱也由此而來。
如果系統的共享變量競爭非常激烈,那么鎖會迅速膨脹到重量級鎖,這些優化也就名存實亡了。如果并發非常嚴重,則可以通過參數 -XX:-UseBiasedLocking 禁用偏向鎖。這種方法在理論上會有一些性能提升,但實際上并不確定。
因為,synchronized 在 JDK,包括一些框架代碼中的應用是非常廣泛的。在一些不需要同步的場景中,即使加上了 synchronized 關鍵字,由于鎖升級的原因,效率也不會太差。
下面這張圖展示了三種鎖的狀態和 Mark Word 值的變化。
#### 小結
在本課時中,我們首先介紹了多線程的一些特點,然后熟悉了 Java 中的線程和它在操作系統中的一些表現形式;還了解了,線程上下文切換會嚴重影響系統的性能,所以 Java 的鎖有基于硬件 CAS 自旋,也有基于比較輕量級的“輕量級鎖”和“偏向鎖”。
它們的目標是,在不改變編程模型的基礎上,盡量提高系統的性能,進行更加高效的并發。
- 前言
- 開篇詞
- 基礎原理
- 第01講:一探究竟:為什么需要 JVM?它處在什么位置?
- 第02講:大廠面試題:你不得不掌握的 JVM 內存管理
- 第03講:大廠面試題:從覆蓋 JDK 的類開始掌握類的加載機制
- 第04講:動手實踐:從棧幀看字節碼是如何在 JVM 中進行流轉的
- 垃圾回收
- 第05講:大廠面試題:得心應手應對 OOM 的疑難雜癥
- 第06講:深入剖析:垃圾回收你真的了解嗎?(上)
- 第06講:深入剖析:垃圾回收你真的了解嗎?(下)
- 第07講:大廠面試題:有了 G1 還需要其他垃圾回收器嗎?
- 第08講:案例實戰:億級流量高并發下如何進行估算和調優
- 實戰部分
- 第09講:案例實戰:面對突如其來的 GC 問題如何下手解決
- 第10講:動手實踐:自己模擬 JVM 內存溢出場景
- 第11講:動手實踐:遇到問題不要慌,輕松搞定內存泄漏
- 第12講:工具進階:如何利用 MAT 找到問題發生的根本原因
- 第13講:動手實踐:讓面試官刮目相看的堆外內存排查
- 第14講:預警與解決:深入淺出 GC 監控與調優
- 第15講:案例分析:一個高死亡率的報表系統的優化之路
- 第16講:案例分析:分庫分表后,我的應用崩潰了
- 進階部分
- 第17講:動手實踐:從字節碼看方法調用的底層實現
- 第18講:大廠面試題:不要搞混 JMM 與 JVM
- 第19講:動手實踐:從字節碼看并發編程的底層實現
- 第20講:動手實踐:不為人熟知的字節碼指令
- 第21講:深入剖析:如何使用 Java Agent 技術對字節碼進行修改
- 第22講:動手實踐:JIT 參數配置如何影響程序運行?
- 第23講:案例分析:大型項目如何進行性能瓶頸調優?
- 彩蛋
- 第24講:未來:JVM 的歷史與展望
- 第25講:福利:常見 JVM 面試題補充