
本課時我們主要分析一個大廠面試題:不要搞混 JMM 與 JVM。
在面試的時候,有一個問題經常被問到,那就是 Java 的內存模型,它已經成為了面試中的標配,是非常具有原理性的一個知識點。但是,有不少人把它和 JVM 的內存布局搞混了,以至于答非所問。這個現象在一些工作多年的程序員中非常普遍,主要是因為 JMM 與多線程有關,而且相對于底層而言,很多人平常的工作就是 CRUD,很難接觸到這方面的知識。
預警:本課時假設你已經熟悉 Java 并發編程的 API,且有實際的編程經驗。如果不是很了解,那么本課時和下一課時的一些內容,可能會比較晦澀。
#### JMM 概念
在第 02 課時,就已經了解了 JVM 的內存布局,你可以認為這是 JVM 的數據存儲模型;但對于 JVM 的運行時模型,還有一個和多線程相關的,且非常容易搞混的概念——Java 的內存模型(JMM,Java Memory Model)。
我們在 Java 的內存布局課時(第02課時)中,還了解了 Java 的虛擬機棧,它和線程相關,也就是我們的字節碼指令其實是靠操作棧來完成的。現在,用一小段代碼,來看一下這個執行引擎的一些特點。
```
import?java.util.stream.IntStream;
public?class?JMMDemo?{
????int?value?=?0;
????void?add()?{
????????value++;
????}
????public?static?void?main(String[]?args)?throws?Exception?{
????????final?int?count?=?100000;
????????final?JMMDemo?demo?=?new?JMMDemo();
????????Thread?t1?=?new?Thread(()?->?IntStream.range(0,?count).forEach((i)?->?demo.add()));
????????Thread?t2?=?new?Thread(()?->?IntStream.range(0,?count).forEach((i)?->?demo.add()));
????????t1.start();
????????t2.start();
????????t1.join();
????????t2.join();
????????System.out.println(demo.value);
```
上面的代碼沒有任何同步塊,每個線程單獨運行后,都會對 value 加 10 萬,但執行之后,大概率不會輸出 20 萬。深層次的原因,我們將使用 javap 命令從字節碼層面找一下。
```
void?add();
????descriptor:?()V
????flags:
????Code:
??????stack=3,?locals=1,?args_size=1
?????????0:?aload_0
?????????1:?dup
?????????2:?getfield??????#2??????????????????//?Field?value:I
?????????5:?iconst_1
?????????6:?iadd
?????????7:?putfield??????#2??????????????????//?Field?value:I
????????10:?return
??????LineNumberTable:
????????line?7:?0
????????line?8:?10
??????LocalVariableTable:
????????Start??Length??Slot??Name???Signature
????????????0??????11?????0??this???LJMMDemo;
```
著重看一下?add?方法,可以看到一個簡單的?i++?操作,竟然有這么多的字節碼,而它們都是傻乎乎按照“順序執行”的。當它自己執行的時候不會有什么問題,但是如果放在多線程環境中,執行順序就變得不可預料了。
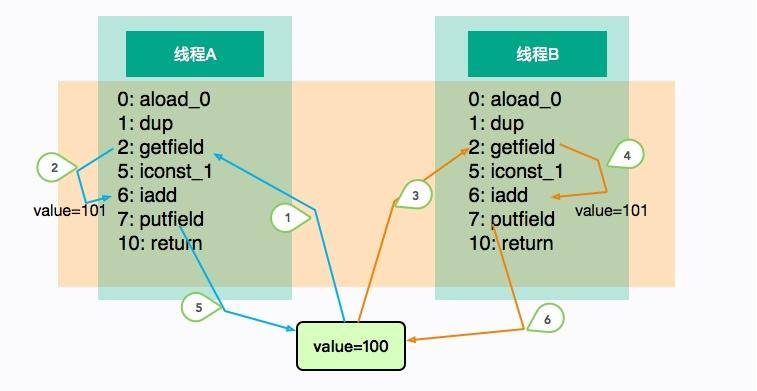
上圖展示了這個亂序的過程。線程 A 和線程 B“并發”執行相同的代碼塊 add,執行的順序如圖中的標號,它們在線程中是有序的(1、2、5 或者 3、4、6),但整體順序是不可預測的。
線程 A 和 B 各自執行了一次加 1 操作,但在這種場景中,線程 B 的 putfield 指令直接覆蓋了線程 A 的值,最終 value 的結果是 101。
上面的示例僅僅是字節碼層面上的,更加復雜的是,CPU 和內存之間同樣存在一致性問題。很多人認為 CPU 是一個計算組件,并沒有數據一致性的問題。但事實上,由于內存的發展速度跟不上 CPU 的更新,在 CPU 和內存之間,存在著多層的高速緩存。
原因就是由于多核所引起的,這些高速緩存,往往會有多層。如果一個線程的時間片跨越了多個 CPU,那么同樣存在同步的問題。
另外,在執行過程中,CPU 可能也會對輸入的代碼進行亂序執行優化,Java 虛擬機的即時編譯器也有類似的指令重排序優化。整個函數的執行步驟就分的更加細致,看起來非常的碎片化(比字節碼指令要細很多)。

**不管是字節碼的原因,還是硬件的原因,在粗粒度上簡化來看,比較淺顯且明顯的因素,那就是線程 add 方法的操作并不是原子性的**。
為了解決這個問題,我們可以在 add 方法上添加 synchronized 關鍵字,它不僅保證了內存上的同步,而且還保證了 CPU 的同步。這個時候,各個線程只能排隊進入 add 方法,我們也能夠得到期望的結果 102。
```
synchronized?void?add()?{
????value++;
}
```
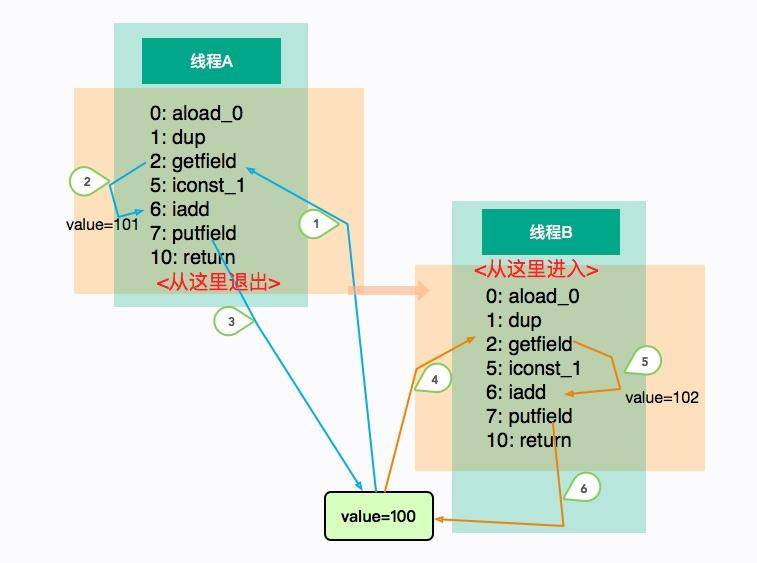
講到這里,Java 的內存模型就呼之欲出了。JMM 是一個抽象的概念,它描述了一系列的規則或者規范,用來解決多線程的共享變量問題,比如 volatile、synchronized 等關鍵字就是圍繞 JMM 的語法。這里所說的變量,包括實例字段、靜態字段,但不包括局部變量和方法參數,因為后者是線程私有的,不存在競爭問題。
JVM 試圖定義一種統一的內存模型,能將各種底層硬件,以及操作系統的內存訪問差異進行封裝,使 Java 程序在不同硬件及操作系統上都能達到相同的并發效果。
#### JMM 的結構
JMM 分為主存儲器(Main Memory)和工作存儲器(Working Memory)兩種。
* 主存儲器是實例位置所在的區域,所有的實例都存在于主存儲器內。比如,實例所擁有的字段即位于主存儲器內,主存儲器是所有的線程所共享的。
* 工作存儲器是線程所擁有的作業區,每個線程都有其專用的工作存儲器。工作存儲器存有主存儲器中必要部分的拷貝,稱之為工作拷貝(Working Copy)。
在這個模型中,線程無法對主存儲器直接進行操作。如下圖,線程 A 想要和線程 B 通信,只能通過主存進行交換。
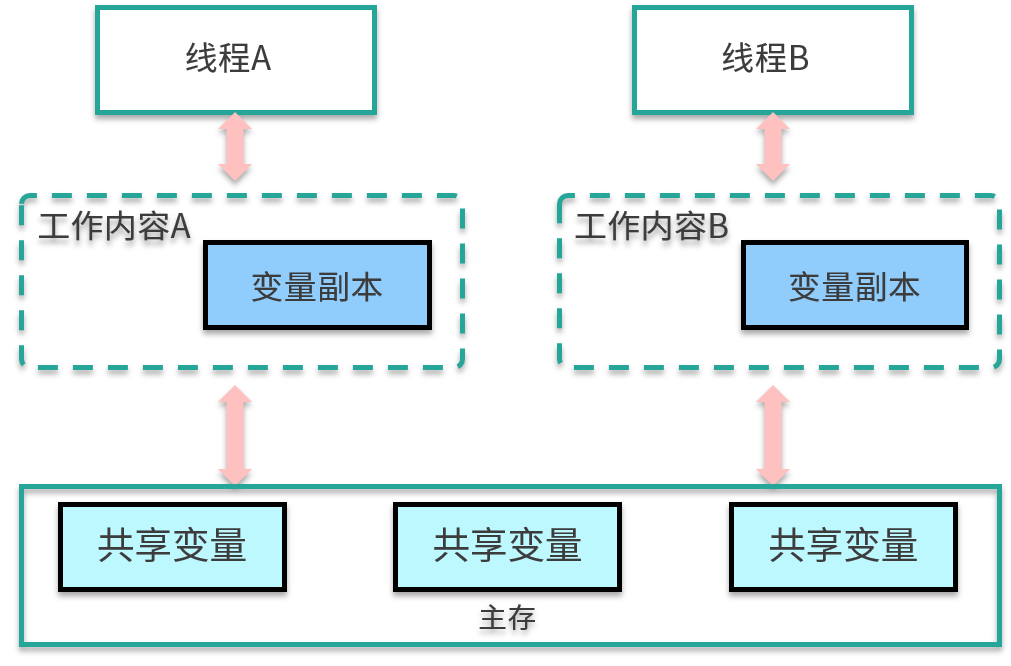
那這些內存區域都是在哪存儲的呢?如果非要有個對應的話,你可以認為主存中的內容是 Java 堆中的對象,而工作內存對應的是虛擬機棧中的內容。但實際上,主內存也可能存在于高速緩存,或者 CPU 的寄存器上;工作內存也可能存在于硬件內存中,我們不用太糾結具體的存儲位置。
#### 8 個 Action
操作類型
為了支持 JMM,Java 定義了 8 種原子操作(Action),用來控制主存與工作內存之間的交互。
* (1)read(讀取)作用于主內存,它把變量從主內存傳動到線程的工作內存中,供后面的 load 動作使用。
* (2)load(載入)作用于工作內存,它把 read 操作的值放入到工作內存中的變量副本中。
* (3)store(存儲)作用于工作內存,它把工作內存中的一個變量傳送給主內存中,以備隨后的 write 操作使用。
* (4)write?(寫入)作用于主內存,它把 store 傳送值放到主內存中的變量中。
* (5)use(使用)作用于工作內存,它把工作內存中的值傳遞給執行引擎,每當虛擬機遇到一個需要使用這個變量的指令時,將會執行這個動作。
* (6)assign(賦值)作用于工作內存,它把從執行引擎獲取的值賦值給工作內存中的變量,每當虛擬機遇到一個給變量賦值的指令時,執行該操作。
* (7)lock(鎖定)作用于主內存,把變量標記為線程獨占狀態。
* (8)unlock(解鎖)作用于主內存,它將釋放獨占狀態。
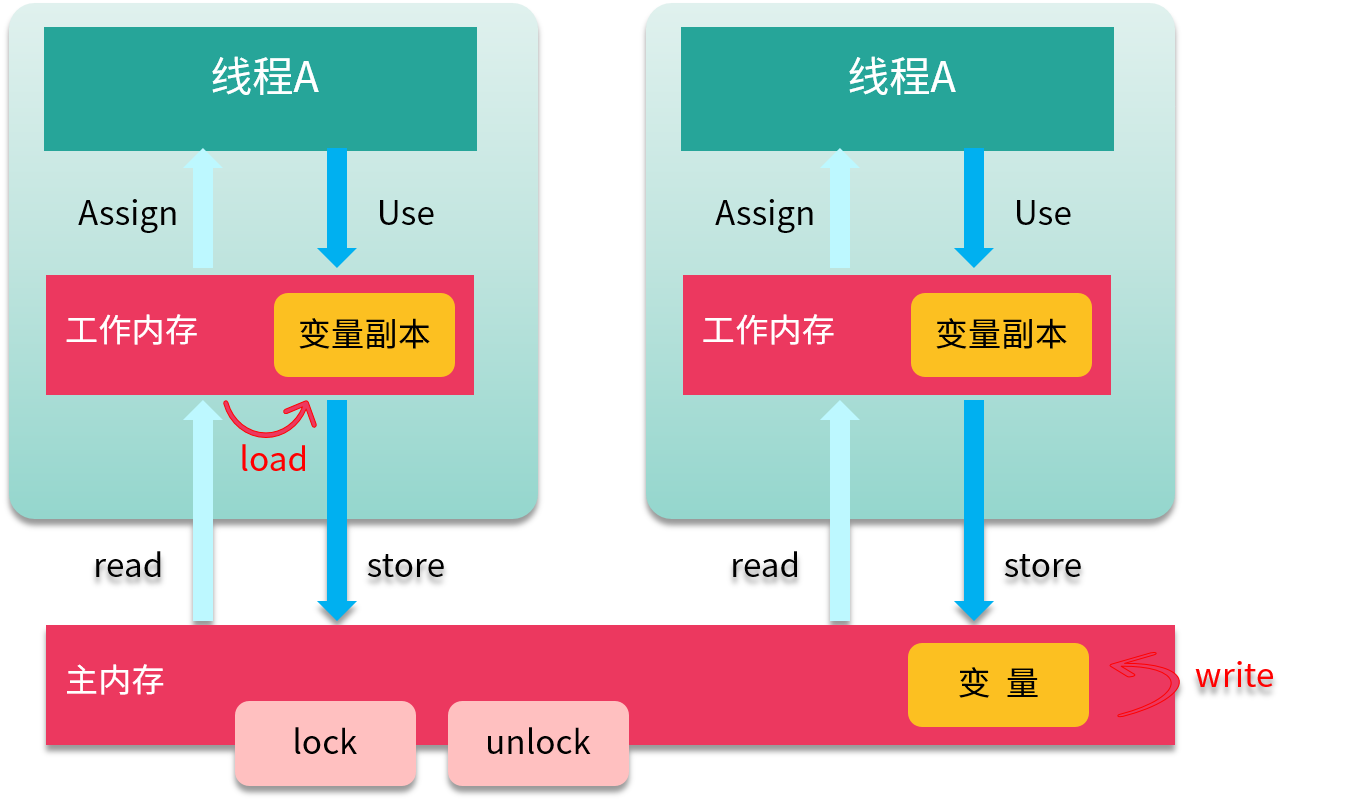
如上圖所示,把一個變量從主內存復制到工作內存,就要順序執行 read 和 load;而把變量從工作內存同步回主內存,就要順序執行 store 和 write 操作。
#### 三大特征
* (1)原子性
JMM 保證了 read、load、assign、use、store 和 write 六個操作具有原子性,可以認為除了 long 和 double 類型以外,對其他基本數據類型所對應的內存單元的訪問讀寫都是原子的。
如果想要一個顆粒度更大的原子性保證,就可以使用 lock 和 unlock 這兩個操作。
* (2)可見性
可見性是指當一個線程修改了共享變量的值,其他線程也能立即感知到這種變化。
我們從前面的圖中可以看到,要保證這種效果,需要經歷多次操作。一個線程對變量的修改,需要先同步給主內存,趕在另外一個線程的讀取之前刷新變量值。
volatile、synchronized、final 和鎖,都是保證可見性的方式。
這里要著重提一下 volatile,因為它的特點最顯著。使用了 volatile 關鍵字的變量,每當變量的值有變動時,都會把更改立即同步到主內存中;而如果某個線程想要使用這個變量,則先要從主存中刷新到工作內存上,這樣就確保了變量的可見性。
而鎖和同步關鍵字就比較好理解一些,它是把更多個操作強制轉化為原子化的過程。由于只有一把鎖,變量的可見性就更容易保證。
(3)有序性
Java 程序很有意思,從上面的 add 操作可以看出,如果在線程中觀察,則所有的操作都是有序的;而如果在另一個線程中觀察,則所有的操作都是無序的。
除了多線程這種無序性的觀測,無序的產生還來源于指令重排。
指令重排序是 JVM 為了優化指令,來提高程序運行效率的,在不影響單線程程序執行結果的前提下,按照一定的規則進行指令優化。在某些情況下,這種優化會帶來一些執行的邏輯問題,在并發執行的情況下,按照不同的邏輯會得到不同的結果。
我們可以看一下 Java 語言中默認的一些“有序”行為,也就是先行發生(happens-before)原則,這些可能在寫代碼的時候沒有感知,因為它是一種默認行為。
先行發生是一個非常重要的概念,如果操作 A 先行發生于操作 B,那么操作 A 產生的影響能夠被操作 B 感知到。
下面的原則是《Java 并發編程實踐》這本書中對一些法則的描述。
* 程序次序:一個線程內,按照代碼順序,寫在前面的操作先行發生于寫在后面的操作。
* 監視器鎖定:unLock 操作先行發生于后面對同一個鎖的 lock 操作。
* volatile:對一個變量的寫操作先行發生于后面對這個變量的讀操作。
* 傳遞規則:如果操作 A 先行發生于操作 B,而操作 B 又先行發生于操作 C,則可以得出操作 A 先行發生于操作 C。
* 線程啟動:對線程 start() 的操作先行發生于線程內的任何操作。
* 線程中斷:對線程 interrupt() 的調用先行發生于線程代碼中檢測到中斷事件的發生,可以通過 Thread.interrupted() 方法檢測是否發生中斷。
* 線程終結規則:線程中的所有操作先行發生于檢測到線程終止,可以通過 Thread.join()、Thread.isAlive() 的返回值檢測線程是否已經終止。
* 對象終結規則:一個對象的初始化完成先行發生于它的 finalize() 方法的開始。
#### 內存屏障
那我們上面提到這么多規則和特性,是靠什么保證的呢?
內存屏障(Memory Barrier)用于控制在特定條件下的重排序和內存可見性問題。JMM 內存屏障可分為讀屏障和寫屏障,Java 的內存屏障實際上也是上述兩種的組合,完成一系列的屏障和數據同步功能。Java 編譯器在生成字節碼時,會在執行指令序列的適當位置插入內存屏障來限制處理器的重排序。
下面介紹一下這些組合。
* Load-Load Barriers
保證 load1 數據的裝載優先于 load2 以及所有后續裝載指令的裝載。對于 Load Barrier 來說,在指令前插入 Load Barrier,可以讓高速緩存中的數據失效,強制重新從主內存加載數據。
```
load1
LoadLoad
load2
```
* Load-Store Barriers
保證 load1 數據裝載優先于 store2 以及后續的存儲指令刷新到內存。
```
load1
LoadStore
store2
```
* Store-Store Barriers
保證 store1 數據對其他處理器可見,優先于 store2 以及所有后續存儲指令的存儲。對于 Store Barrier 來說,在指令后插入 Store Barrier,能讓寫入緩存中的最新數據更新寫入主內存,讓其他線程可見。
```
store1
StoreStore
store
```
* Store-Load Barriers
```
在 Load2 及后續所有讀取操作執行前,保證 Store1 的寫入對所有處理器可見。這條內存屏障指令是一個全能型的屏障,它同時具有其他 3 條屏障的效果,而且它的開銷也是四種屏障中最大的一個。
store1
StoreLoad
load2
```
#### 小結
好了,到這里我們已經簡要地介紹完了 JMM 相關的知識點。前面提到過,“請談一下 Java 的內存模型”這個面試題非常容易被誤解,甚至很多面試官自己也不清楚這個概念。其實,如果我們把 JMM 叫作“Java 的并發內存模型”,會更容易理解。
這個時候,可以和面試官確認一下,問的是 Java 內存布局,還是和多線程相關的 JMM,如果不是 JMM,你就需要回答一下第 02 課時的相關知識了。
JMM 可以說是 Java 并發的基礎,它的定義將直接影響多線程實現的機制,如果你想要深入了解多線程并發中的相關問題現象,對 JMM 的深入研究是必不可少的。
想要深入了解這方面知識的,請點擊這里。
#### 課后問答
* 1、JMM 保證了 read、load、assign、use、store 和 write 六個操作具有原子性,可以認為除了 long 和 double 類型以外,對其他基本數據類型所對應的內存單元的訪問讀寫都是原子的。long和double沒有原子性?
答案:目前大多數機器是64位的,你可以認為是原子的。這是因為,在32位操作系統上對64位的數據的讀寫要分兩步完成,每一步取32位數據。隨著時間推移,這種知識點會越來越冷。
- 前言
- 開篇詞
- 基礎原理
- 第01講:一探究竟:為什么需要 JVM?它處在什么位置?
- 第02講:大廠面試題:你不得不掌握的 JVM 內存管理
- 第03講:大廠面試題:從覆蓋 JDK 的類開始掌握類的加載機制
- 第04講:動手實踐:從棧幀看字節碼是如何在 JVM 中進行流轉的
- 垃圾回收
- 第05講:大廠面試題:得心應手應對 OOM 的疑難雜癥
- 第06講:深入剖析:垃圾回收你真的了解嗎?(上)
- 第06講:深入剖析:垃圾回收你真的了解嗎?(下)
- 第07講:大廠面試題:有了 G1 還需要其他垃圾回收器嗎?
- 第08講:案例實戰:億級流量高并發下如何進行估算和調優
- 實戰部分
- 第09講:案例實戰:面對突如其來的 GC 問題如何下手解決
- 第10講:動手實踐:自己模擬 JVM 內存溢出場景
- 第11講:動手實踐:遇到問題不要慌,輕松搞定內存泄漏
- 第12講:工具進階:如何利用 MAT 找到問題發生的根本原因
- 第13講:動手實踐:讓面試官刮目相看的堆外內存排查
- 第14講:預警與解決:深入淺出 GC 監控與調優
- 第15講:案例分析:一個高死亡率的報表系統的優化之路
- 第16講:案例分析:分庫分表后,我的應用崩潰了
- 進階部分
- 第17講:動手實踐:從字節碼看方法調用的底層實現
- 第18講:大廠面試題:不要搞混 JMM 與 JVM
- 第19講:動手實踐:從字節碼看并發編程的底層實現
- 第20講:動手實踐:不為人熟知的字節碼指令
- 第21講:深入剖析:如何使用 Java Agent 技術對字節碼進行修改
- 第22講:動手實踐:JIT 參數配置如何影響程序運行?
- 第23講:案例分析:大型項目如何進行性能瓶頸調優?
- 彩蛋
- 第24講:未來:JVM 的歷史與展望
- 第25講:福利:常見 JVM 面試題補充