
# 2.1 環境配置
本節簡單介紹一些必要的軟件的安裝與配置,由于不同機器軟硬件配置不同,所以不詳述,遇到問題請擅用Google。
## 2.1.1 Anaconda
Anaconda是Python的一個開源發行版本,主要面向科學計算。我們可以簡單理解為,Anaconda是一個預裝了很多我們用的到或用不到的第三方庫的Python。而且相比于大家熟悉的pip install命令,Anaconda中增加了conda install命令。當你熟悉了Anaconda以后會發現,conda install會比pip install更方便一些。 強烈建議先去看看[最省心的Python版本和第三方庫管理——初探Anaconda](https://zhuanlan.zhihu.com/p/25198543)和[初學 Python 者自學 Anaconda 的正確姿勢-猴子的回答](https://www.zhihu.com/question/58033789/answer/254673663)。
總的來說,我們應該完成以下幾步:
* 根據操作系統下載并安裝Anaconda(或者mini版本Miniconda)并學會常用的幾個conda命令,例如如何管理python環境、如何安裝卸載包等;
* Anaconda安裝成功之后,我們需要修改其包管理鏡像為國內源,這樣以后安裝包時就會快一些。
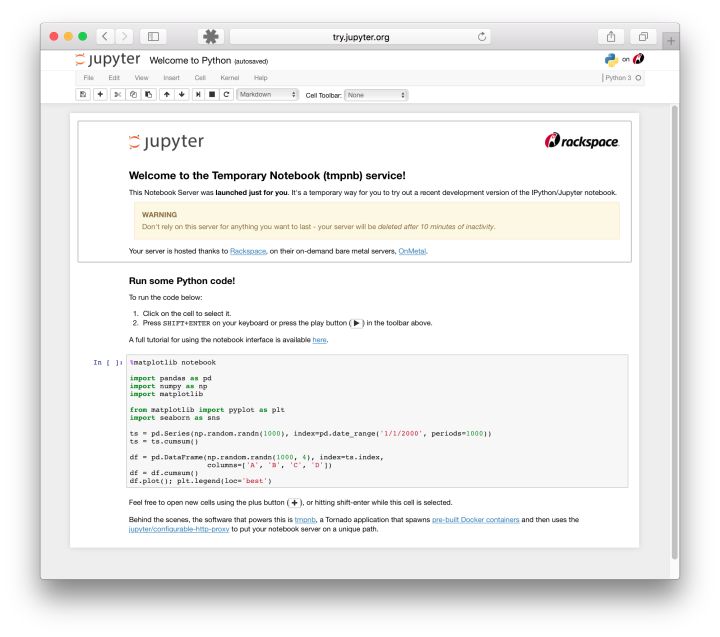
## 2.1.2 Jupyter
在沒有notebook之前,在IT領域是這樣工作的:在普通的 Python shell 或者在IDE(集成開發環境)如Pycharm中寫代碼,然后在word中寫文檔來說明你的項目。這個過程很反鎖,通常是寫完代碼,再寫文檔的時候我還的重頭回顧一遍代碼。最蛋疼的地方在于,有些數據分析的中間結果,還得重新跑代碼,然后把結果弄到文檔里給客戶看。有了notebook之后,世界突然美好了許多,因為notebook可以直接在代碼旁寫出敘述性文檔,而不是另外編寫單獨的文檔。也就是它可以能將代碼、文檔等這一切集中到一處,讓用戶一目了然。如下圖所示。
?
?
Jupyter Notebook 已迅速成為數據分析,機器學習的必備工具。因為它可以讓數據分析師集中精力向用戶解釋整個分析過程。
我們參考[jupyter notebook-猴子的回答](https://www.zhihu.com/question/46309360/answer/254638807)進行jupyter notebook及常用包(例如環境自動關聯包nb\_conda)的安裝。
安裝好后,我們使用以下命令打開一個jupyter notebook:
~~~
?jupyter notebook
~~~
這時在瀏覽器打開 [http://localhost:8888](http://localhost:8888) (通常會自動打開)位于當前目錄的jupyter服務。
## 2.1.3 PyTorch
由于本文需要用到PyTorch框架,所以還需要安裝PyTorch(后期必不可少地會使用GPU,所以安裝GPU版本的)。直接去[PyTorch官網](https://pytorch.org/)找到自己的軟硬件對應的安裝命令即可(這里不得不吹一下[PyTorch的官方文檔](https://pytorch.org/tutorials/),從安裝到入門,深入淺出,比tensorflow不知道高到哪里去了)。安裝好后使用以下命令可查看安裝的PyTorch及版本號。
~~~
?conda list | grep torch
~~~
## 2.1.4 其他
此外還可以安裝python最好用的IDE [PyCharm](https://www.jetbrains.com/pycharm/),專業版的應該是需要收費的,但學生用戶可以申請免費使用([傳送門](https://www.jetbrains.com/zh/student/)),或者直接用免費的社區版。
如果不喜歡用IDE也可以選擇編輯器,例如VSCode等。
本節與原文有很大不同,[原文傳送門](https://zh.d2l.ai/chapter_prerequisite/install.html)
- Home
- Introduce
- 1.深度學習簡介
- 深度學習簡介
- 2.預備知識
- 2.1環境配置
- 2.2數據操作
- 2.3自動求梯度
- 3.深度學習基礎
- 3.1 線性回歸
- 3.2 線性回歸的從零開始實現
- 3.3 線性回歸的簡潔實現
- 3.4 softmax回歸
- 3.5 圖像分類數據集(Fashion-MINST)
- 3.6 softmax回歸的從零開始實現
- 3.7 softmax回歸的簡潔實現
- 3.8 多層感知機
- 3.9 多層感知機的從零開始實現
- 3.10 多層感知機的簡潔實現
- 3.11 模型選擇、反向傳播和計算圖
- 3.12 權重衰減
- 3.13 丟棄法
- 3.14 正向傳播、反向傳播和計算圖
- 3.15 數值穩定性和模型初始化
- 3.16 實戰kaggle比賽:房價預測
- 4 深度學習計算
- 4.1 模型構造
- 4.2 模型參數的訪問、初始化和共享
- 4.3 模型參數的延后初始化
- 4.4 自定義層
- 4.5 讀取和存儲
- 4.6 GPU計算
- 5 卷積神經網絡
- 5.1 二維卷積層
- 5.2 填充和步幅
- 5.3 多輸入通道和多輸出通道
- 5.4 池化層
- 5.5 卷積神經網絡(LeNet)
- 5.6 深度卷積神經網絡(AlexNet)
- 5.7 使用重復元素的網絡(VGG)
- 5.8 網絡中的網絡(NiN)
- 5.9 含并行連結的網絡(GoogLeNet)
- 5.10 批量歸一化
- 5.11 殘差網絡(ResNet)
- 5.12 稠密連接網絡(DenseNet)
- 6 循環神經網絡
- 6.1 語言模型
- 6.2 循環神經網絡
- 6.3 語言模型數據集(周杰倫專輯歌詞)
- 6.4 循環神經網絡的從零開始實現
- 6.5 循環神經網絡的簡單實現
- 6.6 通過時間反向傳播
- 6.7 門控循環單元(GRU)
- 6.8 長短期記憶(LSTM)
- 6.9 深度循環神經網絡
- 6.10 雙向循環神經網絡
- 7 優化算法
- 7.1 優化與深度學習
- 7.2 梯度下降和隨機梯度下降
- 7.3 小批量隨機梯度下降
- 7.4 動量法
- 7.5 AdaGrad算法
- 7.6 RMSProp算法
- 7.7 AdaDelta
- 7.8 Adam算法
- 8 計算性能
- 8.1 命令式和符號式混合編程
- 8.2 異步計算
- 8.3 自動并行計算
- 8.4 多GPU計算
- 9 計算機視覺
- 9.1 圖像增廣
- 9.2 微調
- 9.3 目標檢測和邊界框
- 9.4 錨框
- 10 自然語言處理
- 10.1 詞嵌入(word2vec)
- 10.2 近似訓練
- 10.3 word2vec實現
- 10.4 子詞嵌入(fastText)
- 10.5 全局向量的詞嵌入(Glove)
- 10.6 求近義詞和類比詞
- 10.7 文本情感分類:使用循環神經網絡
- 10.8 文本情感分類:使用卷積網絡
- 10.9 編碼器--解碼器(seq2seq)
- 10.10 束搜索
- 10.11 注意力機制
- 10.12 機器翻譯