
# 3.11 模型選擇、欠擬合和過擬合
在前幾節基于Fashion-MNIST數據集的實驗中,我們評價了機器學習模型在訓練數據集和測試數據集上的表現。如果你改變過實驗中的模型結構或者超參數,你也許發現了:當模型在訓練數據集上更準確時,它在測試數據集上卻不一定更準確。這是為什么呢?
## 3.11.1 訓練誤差和泛化誤差
在解釋上述現象之前,我們需要區分訓練誤差(training error)和泛化誤差(generalization error)。通俗來講,前者指模型在訓練數據集上表現出的誤差,后者指模型在任意一個測試數據樣本上表現出的誤差的期望,并常常通過測試數據集上的誤差來近似。計算訓練誤差和泛化誤差可以使用之前介紹過的損失函數,例如線性回歸用到的平方損失函數和softmax回歸用到的交叉熵損失函數。
讓我們以高考為例來直觀地解釋訓練誤差和泛化誤差這兩個概念。訓練誤差可以認為是做往年高考試題(訓練題)時的錯誤率,泛化誤差則可以通過真正參加高考(測試題)時的答題錯誤率來近似。假設訓練題和測試題都隨機采樣于一個未知的依照相同考綱的巨大試題庫。如果讓一名未學習中學知識的小學生去答題,那么測試題和訓練題的答題錯誤率可能很相近。但如果換成一名反復練習訓練題的高三備考生答題,即使在訓練題上做到了錯誤率為0,也不代表真實的高考成績會如此。
在機器學習里,我們通常假設訓練數據集(訓練題)和測試數據集(測試題)里的每一個樣本都是從同一個概率分布中相互獨立地生成的。基于該獨立同分布假設,給定任意一個機器學習模型(含參數),它的訓練誤差的期望和泛化誤差都是一樣的。例如,如果我們將模型參數設成隨機值(小學生),那么訓練誤差和泛化誤差會非常相近。但我們從前面幾節中已經了解到,模型的參數是通過在訓練數據集上訓練模型而學習出的,參數的選擇依據了最小化訓練誤差(高三備考生)。所以,訓練誤差的期望小于或等于泛化誤差。也就是說,一般情況下,由訓練數據集學到的模型參數會使模型在訓練數據集上的表現優于或等于在測試數據集上的表現。由于無法從訓練誤差估計泛化誤差,一味地降低訓練誤差并不意味著泛化誤差一定會降低。
機器學習模型應關注降低泛化誤差。
## 3.11.2 模型選擇
在機器學習中,通常需要評估若干候選模型的表現并從中選擇模型。這一過程稱為模型選擇(model selection)。可供選擇的候選模型可以是有著不同超參數的同類模型。以多層感知機為例,我們可以選擇隱藏層的個數,以及每個隱藏層中隱藏單元個數和激活函數。為了得到有效的模型,我們通常要在模型選擇上下一番功夫。下面,我們來描述模型選擇中經常使用的驗證數據集(validation data set)。
### 3.11.2.1 驗證數據集
從嚴格意義上講,測試集只能在所有超參數和模型參數選定后使用一次。不可以使用測試數據選擇模型,如調參。由于無法從訓練誤差估計泛化誤差,因此也不應只依賴訓練數據選擇模型。鑒于此,我們可以預留一部分在訓練數據集和測試數據集以外的數據來進行模型選擇。這部分數據被稱為驗證數據集,簡稱驗證集(validation set)。例如,我們可以從給定的訓練集中隨機選取一小部分作為驗證集,而將剩余部分作為真正的訓練集。
然而在實際應用中,由于數據不容易獲取,測試數據極少只使用一次就丟棄。因此,實踐中驗證數據集和測試數據集的界限可能比較模糊。從嚴格意義上講,除非明確說明,否則本書中實驗所使用的測試集應為驗證集,實驗報告的測試結果(如測試準確率)應為驗證結果(如驗證準確率)。
### 3.11.2.3 $K$折交叉驗證
由于驗證數據集不參與模型訓練,當訓練數據不夠用時,預留大量的驗證數據顯得太奢侈。一種改善的方法是`$ K $`折交叉驗證(`$ K $`-fold cross-validation)。在`$ K $`折交叉驗證中,我們把原始訓練數據集分割成`$ K $`個不重合的子數據集,然后我們做`$ K $`次模型訓練和驗證。每一次,我們使用一個子數據集驗證模型,并使用其他`$ K-1 $`個子數據集來訓練模型。在這`$ K $`次訓練和驗證中,每次用來驗證模型的子數據集都不同。最后,我們對這`$ K $`次訓練誤差和驗證誤差分別求平均。
## 3.11.3 欠擬合和過擬合
接下來,我們將探究模型訓練中經常出現的兩類典型問題:一類是模型無法得到較低的訓練誤差,我們將這一現象稱作欠擬合(underfitting);另一類是模型的訓練誤差遠小于它在測試數據集上的誤差,我們稱該現象為過擬合(overfitting)。在實踐中,我們要盡可能同時應對欠擬合和過擬合。雖然有很多因素可能導致這兩種擬合問題,在這里我們重點討論兩個因素:模型復雜度和訓練數據集大小。
> 關于模型復雜度和訓練集大小對學習的影響的詳細理論分析可參見我寫的[這篇博客](https://tangshusen.me/2018/12/09/vc-dimension/)。
### 3.11.3.1 模型復雜度
為了解釋模型復雜度,我們以多項式函數擬合為例。給定一個由標量數據特征`$ x $`和對應的標量標簽`$ y $`組成的訓練數據集,多項式函數擬合的目標是找一個`$ K $`階多項式函數
```[tex]
\hat{y} = b + \sum_{k=1}^K x^k w_k
```
來近似 `$ y $`。在上式中,`$ w_k $`是模型的權重參數,`$ b $`是偏差參數。與線性回歸相同,多項式函數擬合也使用平方損失函數。特別地,一階多項式函數擬合又叫線性函數擬合。
因為高階多項式函數模型參數更多,模型函數的選擇空間更大,所以高階多項式函數比低階多項式函數的復雜度更高。因此,高階多項式函數比低階多項式函數更容易在相同的訓練數據集上得到更低的訓練誤差。給定訓練數據集,模型復雜度和誤差之間的關系通常如圖3.4所示。給定訓練數據集,如果模型的復雜度過低,很容易出現欠擬合;如果模型復雜度過高,很容易出現過擬合。應對欠擬合和過擬合的一個辦法是針對數據集選擇合適復雜度的模型。
:-: 
<div align=center>圖3.4 模型復雜度對欠擬合和過擬合的影響</div>
### 3.11.3.2 訓練數據集大小
影響欠擬合和過擬合的另一個重要因素是訓練數據集的大小。一般來說,如果訓練數據集中樣本數過少,特別是比模型參數數量(按元素計)更少時,過擬合更容易發生。此外,泛化誤差不會隨訓練數據集里樣本數量增加而增大。因此,在計算資源允許的范圍之內,我們通常希望訓練數據集大一些,特別是在模型復雜度較高時,例如層數較多的深度學習模型。
## 3.11.4 多項式函數擬合實驗
為了理解模型復雜度和訓練數據集大小對欠擬合和過擬合的影響,下面我們以多項式函數擬合為例來實驗。首先導入實驗需要的包或模塊。
``` python
%matplotlib inline
import torch
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
```
### 3.11.4.1 生成數據集
我們將生成一個人工數據集。在訓練數據集和測試數據集中,給定樣本特征$x$,我們使用如下的三階多項式函數來生成該樣本的標簽:
```[tex]
y = 1.2x - 3.4x^2 + 5.6x^3 + 5 + \epsilon,
```
其中噪聲項`$ \epsilon $`服從均值為0、標準差為0.01的正態分布。訓練數據集和測試數據集的樣本數都設為100。
``` python
n_train, n_test, true_w, true_b = 100, 100, [1.2, -3.4, 5.6], 5
features = torch.randn((n_train + n_test, 1))
poly_features = torch.cat((features, torch.pow(features, 2), torch.pow(features, 3)), 1)
labels = (true_w[0] * poly_features[:, 0] + true_w[1] * poly_features[:, 1]
+ true_w[2] * poly_features[:, 2] + true_b)
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float)
```
看一看生成的數據集的前兩個樣本。
``` python
features[:2], poly_features[:2], labels[:2]
```
輸出:
```
(tensor([[-1.0613],
[-0.8386]]), tensor([[-1.0613, 1.1264, -1.1954],
[-0.8386, 0.7032, -0.5897]]), tensor([-6.8037, -1.7054]))
```
### 3.11.4.2 定義、訓練和測試模型
我們先定義作圖函數`semilogy`,其中 `$ y $` 軸使用了對數尺度。
``` python
# 本函數已保存在d2lzh_pytorch包中方便以后使用
def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None, y2_vals=None,
legend=None, figsize=(3.5, 2.5)):
d2l.set_figsize(figsize)
d2l.plt.xlabel(x_label)
d2l.plt.ylabel(y_label)
d2l.plt.semilogy(x_vals, y_vals)
if x2_vals and y2_vals:
d2l.plt.semilogy(x2_vals, y2_vals, linestyle=':')
d2l.plt.legend(legend)
```
和線性回歸一樣,多項式函數擬合也使用平方損失函數。因為我們將嘗試使用不同復雜度的模型來擬合生成的數據集,所以我們把模型定義部分放在`fit_and_plot`函數中。多項式函數擬合的訓練和測試步驟與3.6節(softmax回歸的從零開始實現)介紹的softmax回歸中的相關步驟類似。
``` python
num_epochs, loss = 100, torch.nn.MSELoss()
def fit_and_plot(train_features, test_features, train_labels, test_labels):
net = torch.nn.Linear(train_features.shape[-1], 1)
# 通過Linear文檔可知,pytorch已經將參數初始化了,所以我們這里就不手動初始化了
batch_size = min(10, train_labels.shape[0])
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y.view(-1, 1))
optimizer.zero_grad()
l.backward()
optimizer.step()
train_labels = train_labels.view(-1, 1)
test_labels = test_labels.view(-1, 1)
train_ls.append(loss(net(train_features), train_labels).item())
test_ls.append(loss(net(test_features), test_labels).item())
print('final epoch: train loss', train_ls[-1], 'test loss', test_ls[-1])
semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('weight:', net.weight.data,
'\nbias:', net.bias.data)
```
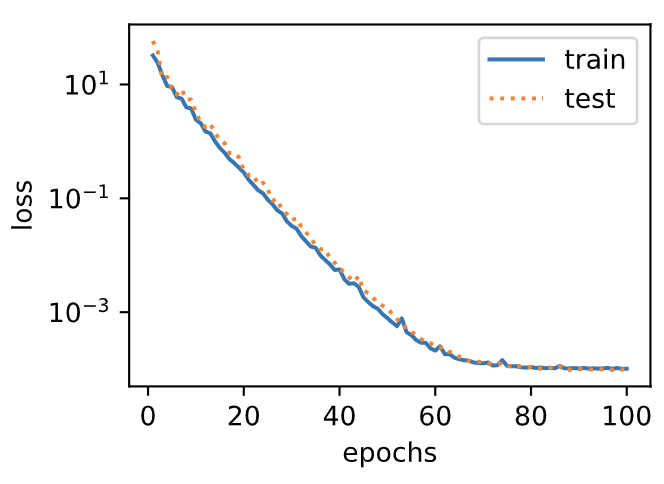
### 3.11.4.3 三階多項式函數擬合(正常)
我們先使用與數據生成函數同階的三階多項式函數擬合。實驗表明,這個模型的訓練誤差和在測試數據集的誤差都較低。訓練出的模型參數也接近真實值:`$ w_1 = 1.2, w_2=-3.4, w_3=5.6, b = 5 $`。
``` python
fit_and_plot(poly_features[:n_train, :], poly_features[n_train:, :],
labels[:n_train], labels[n_train:])
```
輸出:
```
final epoch: train loss 0.00010175639908993617 test loss 9.790256444830447e-05
weight: tensor([[ 1.1982, -3.3992, 5.6002]])
bias: tensor([5.0014])
```
:-: 
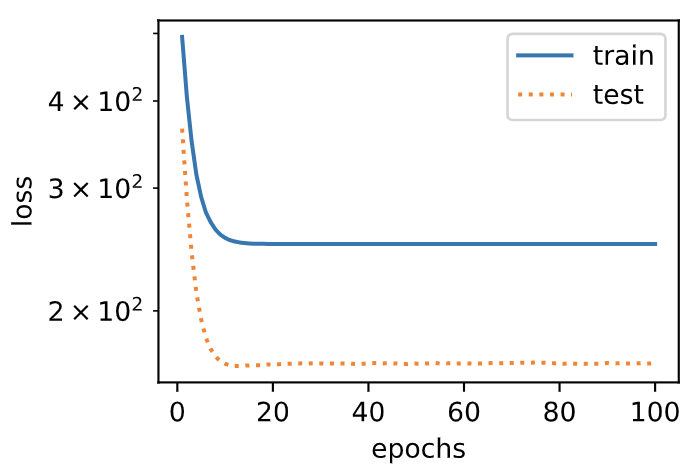
### 3.11.4.4 線性函數擬合(欠擬合)
我們再試試線性函數擬合。很明顯,該模型的訓練誤差在迭代早期下降后便很難繼續降低。在完成最后一次迭代周期后,訓練誤差依舊很高。線性模型在非線性模型(如三階多項式函數)生成的數據集上容易欠擬合。
``` python
fit_and_plot(features[:n_train, :], features[n_train:, :], labels[:n_train],
labels[n_train:])
```
輸出:
```
final epoch: train loss 249.35157775878906 test loss 168.37705993652344
weight: tensor([[19.4123]])
bias: tensor([0.5805])
```
:-: 
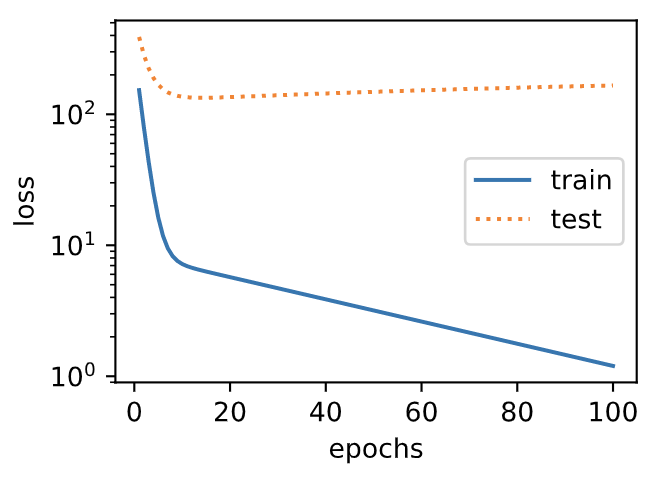
### 3.11.4.5 訓練樣本不足(過擬合)
事實上,即便使用與數據生成模型同階的三階多項式函數模型,如果訓練樣本不足,該模型依然容易過擬合。讓我們只使用兩個樣本來訓練模型。顯然,訓練樣本過少了,甚至少于模型參數的數量。這使模型顯得過于復雜,以至于容易被訓練數據中的噪聲影響。在迭代過程中,盡管訓練誤差較低,但是測試數據集上的誤差卻很高。這是典型的過擬合現象。
```python
fit_and_plot(poly_features[0:2, :], poly_features[n_train:, :], labels[0:2],
labels[n_train:])
```
輸出:
```
final epoch: train loss 1.198514699935913 test loss 166.037109375
weight: tensor([[1.4741, 2.1198, 2.5674]])
bias: tensor([3.1207])
```
:-: 
我們將在接下來的兩個小節繼續討論過擬合問題以及應對過擬合的方法。
## 小結
* 由于無法從訓練誤差估計泛化誤差,一味地降低訓練誤差并不意味著泛化誤差一定會降低。機器學習模型應關注降低泛化誤差。
* 可以使用驗證數據集來進行模型選擇。
* 欠擬合指模型無法得到較低的訓練誤差,過擬合指模型的訓練誤差遠小于它在測試數據集上的誤差。
* 應選擇復雜度合適的模型并避免使用過少的訓練樣本。
-----------
> 注:本節除了代碼之外與原書基本相同,[原書傳送門](https://zh.d2l.ai/chapter_deep-learning-basics/underfit-overfit.html)
- Home
- Introduce
- 1.深度學習簡介
- 深度學習簡介
- 2.預備知識
- 2.1環境配置
- 2.2數據操作
- 2.3自動求梯度
- 3.深度學習基礎
- 3.1 線性回歸
- 3.2 線性回歸的從零開始實現
- 3.3 線性回歸的簡潔實現
- 3.4 softmax回歸
- 3.5 圖像分類數據集(Fashion-MINST)
- 3.6 softmax回歸的從零開始實現
- 3.7 softmax回歸的簡潔實現
- 3.8 多層感知機
- 3.9 多層感知機的從零開始實現
- 3.10 多層感知機的簡潔實現
- 3.11 模型選擇、反向傳播和計算圖
- 3.12 權重衰減
- 3.13 丟棄法
- 3.14 正向傳播、反向傳播和計算圖
- 3.15 數值穩定性和模型初始化
- 3.16 實戰kaggle比賽:房價預測
- 4 深度學習計算
- 4.1 模型構造
- 4.2 模型參數的訪問、初始化和共享
- 4.3 模型參數的延后初始化
- 4.4 自定義層
- 4.5 讀取和存儲
- 4.6 GPU計算
- 5 卷積神經網絡
- 5.1 二維卷積層
- 5.2 填充和步幅
- 5.3 多輸入通道和多輸出通道
- 5.4 池化層
- 5.5 卷積神經網絡(LeNet)
- 5.6 深度卷積神經網絡(AlexNet)
- 5.7 使用重復元素的網絡(VGG)
- 5.8 網絡中的網絡(NiN)
- 5.9 含并行連結的網絡(GoogLeNet)
- 5.10 批量歸一化
- 5.11 殘差網絡(ResNet)
- 5.12 稠密連接網絡(DenseNet)
- 6 循環神經網絡
- 6.1 語言模型
- 6.2 循環神經網絡
- 6.3 語言模型數據集(周杰倫專輯歌詞)
- 6.4 循環神經網絡的從零開始實現
- 6.5 循環神經網絡的簡單實現
- 6.6 通過時間反向傳播
- 6.7 門控循環單元(GRU)
- 6.8 長短期記憶(LSTM)
- 6.9 深度循環神經網絡
- 6.10 雙向循環神經網絡
- 7 優化算法
- 7.1 優化與深度學習
- 7.2 梯度下降和隨機梯度下降
- 7.3 小批量隨機梯度下降
- 7.4 動量法
- 7.5 AdaGrad算法
- 7.6 RMSProp算法
- 7.7 AdaDelta
- 7.8 Adam算法
- 8 計算性能
- 8.1 命令式和符號式混合編程
- 8.2 異步計算
- 8.3 自動并行計算
- 8.4 多GPU計算
- 9 計算機視覺
- 9.1 圖像增廣
- 9.2 微調
- 9.3 目標檢測和邊界框
- 9.4 錨框
- 10 自然語言處理
- 10.1 詞嵌入(word2vec)
- 10.2 近似訓練
- 10.3 word2vec實現
- 10.4 子詞嵌入(fastText)
- 10.5 全局向量的詞嵌入(Glove)
- 10.6 求近義詞和類比詞
- 10.7 文本情感分類:使用循環神經網絡
- 10.8 文本情感分類:使用卷積網絡
- 10.9 編碼器--解碼器(seq2seq)
- 10.10 束搜索
- 10.11 注意力機制
- 10.12 機器翻譯