# 六、可視化
> 原文:[Visualization](https://github.com/data-8/textbook/tree/gh-pages/chapters/06)
> 譯者:[飛龍](https://github.com/wizardforcel)
> 協議:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
> 自豪地采用[谷歌翻譯](https://translate.google.cn/)
表格是一種組織和可視化數據的強大方式。然而,無論數據如何組織,數字的大型表格可能難以解釋。 有時解釋圖片比數字容易得多。
在本章中,我們將開發一些數據分析的基本圖形方法。 我們的數據源是[互聯網電影數據庫](http://www.imdb.com/)(IMDB),這是一個在線數據庫,包含電影,電視節目,和視頻游戲等信息。[Box Office Mojo](http://www.boxofficemojo.com/) 網站提供了許多 IMDB 數據摘要,我們已經采用了其中一些。 我們也使用了 [The Numbers](http://www.the-numbers.com/) 的數據摘要,這個網站的口號是“數據和電影業務的相遇之處”。
## 散點圖和線形圖
`actors`表包含好萊塢的男性和女性演員的數據。 其中的列是:
| 列 | 內容 |
| --- | --- |
| Actor | 演員名稱 |
| Total Gross | 演員所有電影的國內票房總收入(百萬美元) |
| Number of Movies | 演員所演的電影數量 |
| Average per Movie | 總收入除以電影數量 |
| #1 Movie | 演員所演的票房最高的電影 |
| Gross | 演員的 #1 電影的國內票房總收入(百萬美元) |
在總票房的計算中,數據的制表人沒有包括一些電影,其中演員是客串角色或陳述角色,沒有太多的登場時間。
這個表格有 50 行,對應著 50 個最頂級的演員。 這個表已經按照`Total Gross`排序了,所以很容易看出,`Harrison Ford`是最棒的演員。 總的來說,他的電影的國內票房收入比其他演員的電影多。
```py
actors = Table.read_table('actors.csv')
actors
```
| Actor | Total Gross | Number of Movies | Average per Movie | #1 Movie | Gross |
| --- | --- | --- | --- | --- | --- |
| Harrison Ford | 4871.7 | 41 | 118.8 | Star Wars: The Force Awakens | 936.7 |
| Samuel L. Jackson | 4772.8 | 69 | 69.2 | The Avengers | 623.4 |
| Morgan Freeman | 4468.3 | 61 | 73.3 | The Dark Knight | 534.9 |
| Tom Hanks | 4340.8 | 44 | 98.7 | Toy Story 3 | 415 |
| Robert Downey, Jr. | 3947.3 | 53 | 74.5 | The Avengers | 623.4 |
| Eddie Murphy | 3810.4 | 38 | 100.3 | Shrek 2 | 441.2 |
| Tom Cruise | 3587.2 | 36 | 99.6 | War of the Worlds | 234.3 |
| Johnny Depp | 3368.6 | 45 | 74.9 | Dead Man's Chest | 423.3 |
| Michael Caine | 3351.5 | 58 | 57.8 | The Dark Knight | 534.9 |
| Scarlett Johansson | 3341.2 | 37 | 90.3 | The Avengers | 623.4 |
(已省略 40 行)
術語。變量是我們稱之為“特征”的東西的正式名稱,比如`'number of movies'`。 術語“變量”強調了,對于不同的個體,這個特征可以有不同的值 - 演員所演電影的數量因人而異。
擁有數值的變量(如`'number of movies'`或`'average gross receipts per movie'`)的變量稱為定量或數值變量。
### 散點圖
散點圖展示兩個數值變量之間的關系。 在前面的章節中,我們看到了一個散點圖的例子,我們看了兩個經典小說的時間段和角色數量。
`Table`的`scatter`方法繪制一個散點圖,由表格的每一行組成。它的第一個參數是要在橫軸上繪制的列標簽,第二個參數是縱軸上的列標簽。
```py
actors.scatter('Number of Movies', 'Total Gross')
```

散點圖包含 50 個點,表中的每個演員為一個。 一般來說,你可以看到它向上傾斜。 一個演員的電影越多,所有這些電影的總收入就越多。
在形式上,我們說圖表顯示了變量之間的關聯,并且關聯是正的:一個變量的高值往往與另一個變量的高值相關聯,而低值也是一樣,通常情況下。
當然有一些變化。 一些演員有很多電影,但總收入中等。 其他人電影數量中等,但收入很高。正相關只是一個大體趨勢的敘述。
在課程后面,我們將學習如何量化關聯。目前,我們只是定性地思考。
現在我們已經探索了電影的數量與總收入的關系,讓我們把注意力轉向它與每部電影的平均收入的關系。
```py
actors.scatter('Number of Movies', 'Average per Movie')
```

這是一個截然不同的情況,并表現出負相關。 一般來說,演員的電影數量越多,每部電影的平均收入就越少。
另外,有一個點是非常高的,在繪圖的左邊。 它對應于一個電影數量很少,每部電影平均值很高的演員。 這個點是異常的。 它位于數據的一般范圍之外。 事實上,這與繪圖中的其他所有點相差甚遠。
我們將通過查看繪圖的左右兩端的點,來進一步檢查負相關。
對于右端,我們通過查看沒有異常值的部分來放大圖的主體。
```py
no_outlier = actors.where('Number of Movies', are.above(10))
no_outlier.scatter('Number of Movies', 'Average per Movie')
```

負相關仍然清晰可見。 讓我們找出一些演員,對應位于繪圖右側的點,這里電影數量較多:
```py
actors.where('Number of Movies', are.above(60))
```
| Actor | Total Gross | Number of Movies | Average per Movie | #1 Movie | Gross |
| --- | --- | --- | --- | --- | --- |
| Samuel L. Jackson | 4772.8 | 69 | 69.2 | The Avengers | 623.4 |
| Morgan Freeman | 4468.3 | 61 | 73.3 | The Dark Knight | 534.9 |
| Robert DeNiro | 3081.3 | 79 | 39 | Meet the Fockers | 279.3 |
| Liam Neeson | 2942.7 | 63 | 46.7 | The Phantom Menace | 474.5 |
偉大的演員羅伯特·德尼羅(Robert DeNiro)擁有最高的電影數量和最低的每部電影的平均收入。 其他優秀的演員在不遠處的點,但德尼羅在極遠處。
為了理解負相關,請注意,演員所演的電影越多,在風格,流派和票房方片,這些電影變化就越大。 例如,一個演員可能會出現在一些高收入的動作電影或喜劇中(如 Meet Fockers),也可能是優秀但不會吸引大量人群的小眾電影。 因此,演員的每部電影的平均收入值可能相對較低。
為了從不同的角度來看待這個觀點,現在讓我們來看看這個異常點。
```py
actors.where('Number of Movies', are.below(10))
```
| Actor | Total Gross | Number of Movies | Average per Movie | #1 Movie | Gross |
| --- | --- | --- | --- | --- | --- |
| Anthony Daniels | 3162.9 | 7 | 451.8 | Star Wars: The Force Awakens | 936.7 |
作為一名演員,安東尼·丹尼爾斯(Anthony Daniels)可能沒有羅伯特·德尼羅(Robert DeNiro)的身材。 但是他的 7 部電影的平均收入卻高達每部電影近 4.52 億美元。
這些電影是什么? 你可能知道《星球大戰:C-3PO》中的 Droid C-3PO,那是金屬機甲里面的安東尼·丹尼爾斯。 他扮演 C-3PO。

丹尼爾斯先生的全部電影(除了客串)都是由高收入的“星球大戰”系列電影組成的。 這就解釋了他的高平均收入和低電影數量。
類型和制作預算等變量,會影響電影數量與每部電影的平均收入之間的關聯。 這個例子提醒人們,研究兩個變量之間的關聯,往往也涉及到了解其他相關的變量。
## 線形圖
線形圖是最常見的可視化圖形之一,通常用于研究時序型的趨勢和模式。
`movies_by_year`表包含了 1980 年到 2015 年間,美國電影公司制作的電影的數據。這些列是:
| 列 | 內容 |
| --- | --- |
| Year | 年份 |
| Total Gross | 所有發行電影的國內總票房收入(以百萬美元為單位) |
| Number of Movies | 發行的電影數量 |
| #1 Movie | 收入最高的電影 |
```py
movies_by_year = Table.read_table('movies_by_year.csv')
movies_by_year
```
| Year | Total Gross | Number of Movies | #1 Movie |
| --- | --- | --- | --- |
| 2015 | 11128.5 | 702 | Star Wars: The Force Awakens |
| 2014 | 10360.8 | 702 | American Sniper |
| 2013 | 10923.6 | 688 | Catching Fire |
| 2012 | 10837.4 | 667 | The Avengers |
| 2011 | 10174.3 | 602 | Harry Potter / Deathly Hallows (P2) |
| 2010 | 10565.6 | 536 | Toy Story 3 |
| 2009 | 10595.5 | 521 | Avatar |
| 2008 | 9630.7 | 608 | The Dark Knight |
| 2007 | 9663.8 | 631 | Spider-Man 3 |
| 2006 | 9209.5 | 608 | Dead Man's Chest |
(省略了 26 行)
`Table`的`plot`方法產生線形圖。 它的兩個參數與散點圖相同:首先是橫軸上的列,然后是縱軸上的列。 這是 1980 年到 2015 年間每年發行的電影數量的線形圖。
```py
movies_by_year.plot('Year', 'Number of Movies')
```

雖然每年的數字都有明顯的變化,但圖形急劇上升,然后呈現平緩的上升趨勢。 20 世紀 80 年代早期的劇增,部分是由于在上世紀 70 年代,電影制作人推動電影業的幾年后,電影制片廠重新回到電影制作的前沿。
我們的重點將放在最近幾年。 根據電影的主題,對應 2000 年到 2015 年的行,分配給名稱`century_21`。
```py
century_21 = movies_by_year.where('Year', are.above(1999))
century_21.plot('Year', 'Number of Movies')
```

2008 年的全球金融危機有明顯的效果 - 2009 年發行的電影數量急劇下降。
但是,美元數量并沒有太大的變化。
```py
century_21.plot('Year', 'Total Gross')
```

盡管發生了金融危機,電影發行的數量也少得多,但 2009 年的國內總收入仍高于 2008 年。
造成這種矛盾的一個原因是,人們在經濟衰退時往往會去看電影。 “經濟低迷時期,美國人涌向電影”,“紐約時報”于 2009 年 2 月說。文章引用南加州大學的馬丁·卡普蘭(Martin Kaplan)的話說:“人們想要忘記自己的煩惱,想和別人在一起。” 當節假日和昂貴的款待難以負擔,電影提供了受歡迎的娛樂和寬慰。
2009 年的高票房收入的另一個原因是,電影《阿凡達》及其 3D 版本。 阿凡達不僅是 2009 年的第一部電影,它也是有史以來第二高的總票房電影,我們將在后面看到。
```py
century_21.where('Year', are.equal_to(2009))
```
| Year | Total Gross | Number of Movies | #1 Movie |
| --- | --- | --- | --- |
| 2009 | 10595.5 | 521 | Avatar |
## 類別分許
### 可視化類別分布
許多數據不以數字的形式出現。 數據可以是音樂片段,或地圖上的地方。 他們也可以是類別,你可以在里面放置個體。 以下是一些類別變量的例子。
+ 個體是冰淇淋紙盒,變量就是紙盒里的味道。
+ 個體是職業籃球運動員,變量是球員的隊伍。
+ 個體是年,而變量是今年最高票房電影的流派。
+ 個體是調查對象,變量是他們從“完全不滿意”,“有點滿意”和“非常滿意”中選擇的回答。
`icecream `表包含 30 盒冰激凌的數據。
```py
icecream = Table().with_columns(
'Flavor', make_array('Chocolate', 'Strawberry', 'Vanilla'),
'Number of Cartons', make_array(16, 5, 9)
)
icecream
```
| Flavor | Number of Cartons |
| --- | --- |
| Chocolate | 16 |
| Strawberry | 5 |
| Vanilla | 9 |
分類變量“口味”的值是巧克力,草莓和香草。 表格顯示了每種口味的紙盒數量。 我們稱之為分布表。 分布顯示了所有變量的值,以及每個變量的頻率。
### 條形圖
條形圖是可視化類別分布的熟悉方式。 它為每個類別顯示一個條形。 條形的間隔相等,寬度相同。 每個條形的長度與相應類別的頻率成正比。
我們使用橫條繪制條形圖,因為這樣更容易標注條形圖。 所以`Table`的方法稱為`barh`。 它有兩個參數:第一個是類別的列標簽,第二個是頻率的列標簽。
```py
icecream.barh('Flavor', 'Number of Cartons')
```

如果表格只包含一列類別和一列頻率(如冰淇淋),則方法調用甚至更簡單。 你可以指定包含類別的列,`barh`將使用另一列中的值作為頻率。
```py
icecream.barh('Flavor')
```

### 類別分布的特征
除了純粹的視覺差異之外,條形圖和我們在前面章節中看到的兩個圖表之間還有一個重要的區別。 它們是散點圖和線圖,兩者都顯示兩個數值變量 - 兩個軸上的變量都是數值型的。 相比之下,條形圖的一個軸上是類別,在另一個軸上具有數值型頻率。
這對圖表有影響。首先,每個條形的寬度和相鄰條形之間的間隔完全取決于生成圖的人,或者用于生成該圖的程序。 Python 為我們做了這些選擇。 如果你要手動繪制條形圖,則可以做出完全不同的選擇,并且仍然會是完全正確的條形圖,前提是你使用相同寬度繪制了所有條形,并使所有間隔保持相同。
最重要的是,條形可以以任何順序繪制。 “巧克力”,“香草”和“草莓”這些類別沒有普遍的等級順序,不像數字`5, 7`和`10`。
這意味著我們可以繪制一個易于解釋的條形圖,方法是按降序重新排列條形圖。 為了實現它,我們首先按照`Number of Cartons`的降序,重新排列`icecream `的行,然后繪制條形圖。
```py
icecream.sort('Number of Cartons', descending=True).barh('Flavor')
```

這個條形圖包含的信息和以前的完全一樣,但是它更容易閱讀。 雖然在只讀三個條形的情況下,這并不是一個巨大的收益,但是當分類數量很大時,這可能是相當重要的。
## 組合分類數據
為了構造`icecream`表,有人不得不查看 30 個冰淇淋盒子,并計算每種口味的數量。 但是,如果我們的數據還沒有包含頻率,我們必須在繪制條形圖之前計算頻率。 這是一個例子,其中它是必要的。
`top`表由美國歷史上最暢銷的電影組成。 第一列包含電影的標題;《星球大戰:原力覺醒》(Star Wars: The Force Awakens)排名第一,美國票房總額超過 9 億美元。 第二列包含制作電影的工作室的名稱。 第三列包含國內票房收入(美元),第四列包含按 2016 年價格計算的,票面總收入。 第五列包含電影的發行年份。
列表中有 200 部電影。 根據未調整的總收入,這是前十名。
```py
top = Table.read_table('top_movies.csv')
top
```
| Title | Studio | Gross | Gross (Adjusted) | Year |
| --- | --- | --- | --- | --- |
| Star Wars: The Force Awakens | Buena Vista (Disney) | 906723418 | 906723400 | 2015 |
| Avatar | Fox | 760507625 | 846120800 | 2009 |
| Titanic | Paramount | 658672302 | 1178627900 | 1997 |
| Jurassic World | Universal | 652270625 | 687728000 | 2015 |
| Marvel's The Avengers | Buena Vista (Disney) | 623357910 | 668866600 | 2012 |
| The Dark Knight | Warner Bros. | 534858444 | 647761600 | 2008 |
| Star Wars: Episode I - The Phantom Menace | Fox | 474544677 | 785715000 | 1999 |
| Star Wars | Fox | 460998007 | 1549640500 | 1977 |
| Avengers: Age of Ultron | Buena Vista (Disney) | 459005868 | 465684200 | 2015 |
| The Dark Knight Rises | Warner Bros. | 448139099 | 500961700 | 2012 |
(省略了 190 行)
迪斯尼的子公司布埃納維斯塔(Buena Vista)就像福克斯(Fox)和華納兄弟(Warner Brothers)一樣,經常出現在前十名中 如果我們從 200 行中看,哪個工作室最常出現?
為了解決這個問題,首先要注意的是,我們需要的只是一個擁有電影和工作室的表格;其他信息是不必要的。
```py
movies_and_studios = top.select('Title', 'Studio')
```
`Table`的`group`方法組允許我們,通過將每個工作室當做一個類別,并將每一行分配給一個類別,來計算每個工作室出現在表中的頻率。 `group`方法將包含類別的列標簽作為其參數,并返回每個類別中行數量的表格。 數量列始終稱為`count`,但如果你希望的話,則可以使用`relabeled`更改該列。
```py
movies_and_studios.group('Studio')
```
| Studio | count |
| --- | --- |
| AVCO | 1 |
| Buena Vista (Disney) | 29 |
| Columbia | 10 |
| Disney | 11 |
| Dreamworks | 3 |
| Fox | 26 |
| IFC | 1 |
| Lionsgate | 3 |
| MGM | 7 |
| MPC | 1 |
(省略了 14 行)
因此,`group`創建一個分布表,顯示電影在類別(工作室)之間如何分布。
現在我們可以使用這個表格,以及我們上面獲得的圖形技能來繪制條形圖,顯示前 200 個最高收入的電影中,哪個工作室是最常見的。
```py
studio_distribution = movies_and_studios.group('Studio')
studio_distribution.sort('count', descending=True).barh('Studio')
```

華納兄弟(Warner Brothers)和布埃納維斯塔(Buena Vista)是前 200 電影中最常見的工作室。 華納兄弟制作了哈利波特電影,布埃納維斯塔制作了星球大戰。
由于總收入以未經調整的美元來衡量,所以最近幾年的頂級電影比過去幾十年更頻繁,這并不令人驚訝。 以絕對數量來看,現在的電影票價比以前更高,因此總收入也更高。 這是通過條形圖證明的,這些條形圖顯示了 200 部電影的發行年份。
```py
movies_and_years = top.select('Title', 'Year')
movies_and_years.group('Year').sort('count', descending=True).barh('Year')
```

所有最長的條形都對應 2000 年以后的年份。這與我們的觀察一致,即最近幾年應該是最頻繁的。
### 面向數值變量
這張圖有一些未解決的地方。 雖然它確實回答了這個問題,200 部最受歡迎的電影中,最常見的發行年份,但并沒有按時間順序列出所有年份。 它將年作為一個分類變量。
但是,年份是固定的時序單位,確實擁有順序。 他們也有相對于彼此的固定的數值距離。 讓我們看看當我們試圖考慮它的時候會發生什么。
默認情況下,`barh`將類別(年)從最低到最高排序。 所以我們將運行這個代碼,但不按`count`進行排序。
```py
movies_and_years.group('Year').barh('Year')
```

現在年份是升序了。 但是這個條形圖還是有點問題。 1921 年和 1937 年的條形與 1937 年和 1939 年的條形相距甚遠。條形圖并沒有顯示出,200 部電影中沒有一部是在 1922 年到 1936 年間發布的。基于這種可視化,這種不一致和遺漏,使早期年份的分布難以理解。
條形圖用做類別變量的可視化。 當變量是數值,并且我們創建可視化時,必須考慮其值之間的數值關系。 這是下一節的主題。
## 數值分布
### 可視化數值分布
數據科學家研究的許多變量是定量的或數值的。它們的值是你可以做算術的數字。我們所看到的例子包括一本書的章節數量,電影的收入以及美國人的年齡。
類別變量的值可以按照數字編碼,但是這不會使變量成為定量的。在我們研究的,按年齡組分類的人口普查數據的例子中,分類變量`SEX`中,`'Male'`的數字代碼為`1`,`'Female'`的數字代碼為`2`,以及分組`1`和`2`的合計為`0`。 `1`和`2`是數字,在這種情況下,從`2`中減`1`或取`0,1`和`2`的平均值,或對這三個值執行其他算術是沒有意義的。 `SEX`是一個類別變量,即使這些值已經賦予一個數字代碼。
對于我們的主要示例,我們將返回到我們在可視化分類數據時,所研究的數據集。這是一個表格,它由美國歷史上最暢銷的電影中的數據組成。為了方便起見,這里再次描述表格。
第一列包含電影的標題。第二列包含制作電影的工作室的名稱。第三個包含國內票房總值(美元),第四個包含按 2016 年價格計算的票面收入總額。第五個包含電影的發行年份。
列表中有 200 部電影。根據`Gross`列中未調整的總收入,這是前十名。
```py
top = Table.read_table('top_movies.csv')
# Make the numbers in the Gross and Gross (Adjusted) columns look nicer:
top.set_format([2, 3], NumberFormatter)
```
| Title | Studio | Gross | Gross (Adjusted) | Year |
| --- | --- | --- | --- | --- |
| Star Wars: The Force Awakens | Buena Vista (Disney) | 906,723,418 | 906,723,400 | 2015 |
| Avatar | Fox | 760,507,625 | 846,120,800 | 2009 |
| Titanic | Paramount | 658,672,302 | 1,178,627,900 | 1997 |
| Jurassic World | Universal | 652,270,625 | 687,728,000 | 2015 |
| Marvel's The Avengers | Buena Vista (Disney) | 623,357,910 | 668,866,600 | 2012 |
| The Dark Knight | Warner Bros. | 534,858,444 | 647,761,600 | 2008 |
| Star Wars: Episode I - The Phantom Menace | Fox | 474,544,677 | 785,715,000 | 1999 |
| Star Wars | Fox | 460,998,007 | 1,549,640,500 | 1977 |
| Avengers: Age of Ultron | Buena Vista (Disney) | 459,005,868 | 465,684,200 | 2015 |
| The Dark Knight Rises | Warner Bros. | 448,139,099 | 500,961,700 | 2012 |
(省略了 190 行)
### 可視化調整后收入的分布
在本節中,我們將繪制`Gross (Adjusted)`列中數值變量的分布圖。 為了簡單起見,我們創建一個包含我們所需信息的小表。 而且由于三位數字比九位數字更容易處理,我們以百萬美元衡量調整后的總收入。 注意如何使用舍入僅保留兩位小數。
```py
millions = top.select(0).with_column('Adjusted Gross',
np.round(top.column(3)/1e6, 2))
millions
```
| Title | Adjusted Gross |
| --- | --- |
| Star Wars: The Force Awakens | 906.72 |
| Avatar | 846.12 |
| Titanic | 1178.63 |
| Jurassic World | 687.73 |
| Marvel's The Avengers | 668.87 |
| The Dark Knight | 647.76 |
| Star Wars: Episode I - The Phantom Menace | 785.72 |
| Star Wars | 1549.64 |
| Avengers: Age of Ultron | 465.68 |
| The Dark Knight Rises | 500.96 |
### 直方圖
數值數據集的直方圖看起來非常像條形圖,雖然它有一些重要的差異,我們將在本節中討論。 首先,我們只畫出調整后收入的直方圖。
hist方法生成列中值的直方圖。 可選的單位參數用于兩個軸上的標簽。 直方圖顯示調整后的總額分布,以百萬美元為單位。
```py
millions.hist('Adjusted Gross', unit="Million Dollars")
```

### 橫軸
這些金額已被分組為連續的間隔,稱為桶。盡管在這個數據集中,沒有電影正好在兩個桶之間的邊緣上,但是`hist`必須考慮數值可能在邊緣的情況。所以`hist`有一個端點約定:`bin`包含左端點的數據,但不包含右端點的數據。
我們使用符號`[a, b)`表示從`a`開始并在`b`結束但不包括`b`的桶。
有時,必須在第一個或最后一個箱中進行調整,以確保包含變量的最小值和最大值。在前面研究的人口普查數據中,你看到了一個這樣的調整的例子,其中“100”歲的年齡實際上意味著“100 歲以上”。
我們可以看到,有 10 個桶(有些桶很低,難以看到),而且它們的寬度都是一樣的。我們也可以看到,沒有一部電影的收入不到三億美元,那是因為我們只考慮有史以來最暢銷的電影。
準確看到桶的末端在哪里,有點困難。例如,精確地確定值 500 位于橫軸上的位置并不容易。所以很難判斷一個條形的結束位置和下一個條形的開始位置。
可選參數`bins`可以與`hist`一起使用來指定桶的端點。它必須由一系列數字組成,這些數字以第一個桶的左端開始,以最后一個桶的右端結束。我們首先將桶中的數字設置為`300,400,500`等等,以`2000`結尾。
```py
millions.hist('Adjusted Gross', bins=np.arange(300,2001,100), unit="Million Dollars")
```

這個圖的橫軸比較容易閱讀。 標簽`200,400,600`等以對應的值為中心。 最高的條形是對應三億到四億美元之間的電影。
少數電影投入了 8 億美元甚至更多。 這導致這個數字“向右傾斜”,或者更不正式地說,“右側長尾”。 大量人口的收入或租金等變量的分布也經常具有這種形式。
### 桶的數量
可以使用`bin`方法從一個表格中計算出桶中的值的數量,該方法接受列標簽或索引,以及可選的序列或桶的數量。 結果是直方圖的表格形式。 第一列列出了桶的左端點(但請參閱下面關于最終值的注釋)。 第二列包含`Adjusted Gross`列中所有值在相應桶中的數量。 也就是說,它計數所有`Adjusted Gross`的所有值,它們大于或等于`bin`中的值,但小于下一個`bin`中的值。
```py
bin_counts = millions.bin('Adjusted Gross', bins=np.arange(300,2001,100))
bin_counts.show()
```
| bin | Adjusted Gross count |
| --- | --- |
| 300 | 81 |
| 400 | 52 |
| 500 | 28 |
| 600 | 16 |
| 700 | 7 |
| 800 | 5 |
| 900 | 3 |
| 1000 | 1 |
| 1100 | 3 |
| 1200 | 2 |
| 1300 | 0 |
| 1400 | 0 |
| 1500 | 1 |
| 1600 | 0 |
| 1700 | 1 |
| 1800 | 0 |
| 1900 | 0 |
| 2000 | 0 |
注意最后一行的`bin`值 2000。 這不是任何條形的左端點 - 這是最后一個條形的右端點。 按照端點約定,那里的數據不包括在內。 因此,相應的計數記錄為 0,并且即使已經有超過二十億美元的電影也被記錄為 0。 當`bin`或`hist`使用`bin`參數調用時,圖只考慮在指定`bin`中的值。
一旦數值已經分入桶中,所得數量可以用來使用`bin_column`命名參數來生成直方圖,以指定哪個列包含桶的下界。
```py
bin_counts.hist('Adjusted Gross count', bin_column='bin', unit='Million Dollars')
```

### 縱軸:密度刻度
一旦我們已經照顧到細節,如桶的末端,直方圖的橫軸易于閱讀。 縱軸的特征需要更多關注。 我們會一一講解。
我們先來看看如何計算垂直軸上的數字。 如果計算看起來有些奇怪,請耐心等待 - 本節的其余部分將解釋原因。
計算。每個條形的高度是桶中的元素的百分比,除以桶的寬度。
> 譯者注:存在很多種直方圖,比如頻數直方圖、頻率質量直方圖和頻率密度直方圖。它們的縱軸數值不相同,但是圖形形狀是一樣的。這里是最后一種,頻率密度直方圖。
```py
counts = bin_counts.relabeled('Adjusted Gross count', 'Count')
percents = counts.with_column(
'Percent', (counts.column('Count')/200)*100
)
heights = percents.with_column(
'Height', percents.column('Percent')/100
)
heights
```
| bin | Count | Percent | Height |
| --- | --- | --- | --- |
| 300 | 81 | 40.5 | 0.405 |
| 400 | 52 | 26 | 0.26 |
| 500 | 28 | 14 | 0.14 |
| 600 | 16 | 8 | 0.08 |
| 700 | 7 | 3.5 | 0.035 |
| 800 | 5 | 2.5 | 0.025 |
| 900 | 3 | 1.5 | 0.015 |
| 1000 | 1 | 0.5 | 0.005 |
| 1100 | 3 | 1.5 | 0.015 |
| 1200 | 2 | 1 | 0.01 |
(省略了 8 行)
在上面直方圖的縱軸上查看數字,檢查列高度是否正確。
如果我們只查看表格的第一行,計算就會變得清晰。
請記住,數據集中有 200 部電影。這個`[300,400)`的桶包含 81 部電影。這是所有電影的 40.5%: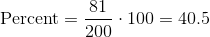。
`[300, 400)`桶的寬度是`400-300 = 100`。所以 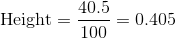。
用于計算高度的代碼使用了總共??有 200 個電影,以及每個箱的寬度是 100 的事實。
單位。條形的高度是 40.5% 除以 1 億美元,因此高度是 0.405% 每百萬美元。
這種繪制直方圖的方法創建了一個垂直軸,它是在密度刻度上的。條形的高度不是桶中條目的百分比;它是桶中的條目除以桶的寬度。這就是為什么高度衡量擁擠度或密度。
讓我們看看為什么這很重要。
### 不等的桶
直方圖相比條形圖的一個優點是,直方圖可以包含不等寬度的桶。 以下將`Millions `中的值分為三個不均勻的類別。
```py
uneven = make_array(300, 400, 600, 1500)
millions.hist('Adjusted Gross', bins=uneven, unit="Million Dollars")
```

這里是三個桶中的數量。
```py
millions.bin('Adjusted Gross', bins=uneven)
```
| bin | Adjusted Gross count |
| --- | --- |
| 300 | 81 |
| 400 | 80 |
| 600 | 37 |
| 1500 | 0 |
雖然范圍`[300,400)`和`[400,600)`具有幾乎相同的計數,但前者的高度是后者的兩倍,因為它只有一半的寬度。 `[300,400)`中的值的密度是`[400,600)`中的密度的兩倍。
直方圖幫助我們可視化數軸上數據最集中的地方,特別是當桶不均勻的時候。
### 僅僅繪制數量的問題
可以使用`hist`方法的`normed=False`選項直接在圖表中顯示數量。 生成的圖表與直方圖具有相同的形狀,但這些桶的寬度均相等,盡管縱軸上的數字不同。
```py
millions.hist('Adjusted Gross', bins=np.arange(300,2001,100), normed=False)
```

雖然數量刻度可能比密度刻度更自然,但當桶寬度不同時,圖表高度的有誤導性。 下面看起來(由于計數)高收入電影相當普遍,事實上我們已經看到它們相對較少。
```py
millions.hist('Adjusted Gross', bins=uneven, normed=False)
```

即使使用的方法被稱為`hist`,上面的圖不是一個直方圖。 誤導性地夸大了至少 6 億美元的電影比例。 每個桶的高度只是按照桶中的電影數量繪制,而不考慮桶寬度的差異。
如果最后兩個桶組合起來,情況就變得更加荒謬了。
```py
very_uneven = make_array(300, 400, 1500)
millions.hist('Adjusted Gross', bins=very_uneven, normed=False)
```

在這個基于數量的圖像中,電影分布完全失去了形狀。
### 直方圖:通用原則和計算
上圖顯示,眼睛將面積視為“較大”的東西,而不是高度。當桶的寬度不同時,這種觀察變得尤為重要。
這就是直方圖具有兩個定義屬性的原因:
+ 桶按比例繪制并且是連續的(盡管有些可能是空的),因為橫軸上的值是數值型的。
+ 每個條形的面積與桶中的條目數成比例。
屬性(2)是繪制直方圖的關鍵,通常實現如下:
```
條形的面積 = 桶中條目的百分比
```
高度的計算僅僅使用了一個事實,條形是長方形的。
```
條形的面積 = 條形的高度 * 桶的寬度
```
因此,
```
條形的高度 = 條形的面積 / 桶的寬度
= 桶中條目的百分比 / 桶的寬度
```
高度的單位是“百分比每橫軸單位”。
當使用這種方法繪制時,直方圖被稱為在密度刻度上繪制。 在這個刻度上:
+ 每個條形的面積等于相應桶中的數據值的百分比。
+ 直方圖中所有條形的總面積為 100%。 從比例的角度來講,我們說直方圖中所有條形的面積“總計為 1”。
### 平頂和細節水平
即使密度刻度使用面積正確表示了百分比,但是通過將值分組到桶中,丟失了一些細節。
再看一下下圖中的`[300,400)`的桶。 值為“0.405% 每百萬美元”的桶的平頂,隱藏了電影在這個桶分布有些不均勻的事實。
```py
millions.hist('Adjusted Gross', bins=uneven, unit="Million Dollars")
```

為了看到它,讓我們將`[300, 400)`劃分為更窄的 10 個桶。每個桶的寬度都是一千萬美元。
```py
some_tiny_bins = make_array(300, 310, 320, 330, 340, 350, 360, 370, 380, 390, 400, 600, 1500)
millions.hist('Adjusted Gross', bins=some_tiny_bins, unit='Million Dollars')
```

### 直方圖 Q&A
讓我們再畫一遍直方圖,這次只有四個桶,檢查我們對概念的理解。
```py
uneven_again = make_array(300, 350, 400, 450, 1500)
millions.hist('Adjusted Gross', bins=uneven_again, unit='Million Dollars')
millions.bin('Adjusted Gross', bins=uneven_again)
```

| bin | Adjusted Gross count |
| --- | --- |
| 300 | 32 |
| 350 | 49 |
| 400 | 25 |
| 450 | 92 |
| 1500 | 0 |
再次查看直方圖,并將`[400,450)`的桶與`[450,1500)`桶進行比較。
問:哪個桶里面有更多的電影?
答:`[450,1500)`的桶。它有 92 部電影,而`[400,450)`桶中有 25 部電影。
問:那么為什么`[450,1500)`的桶比`[400,450)`桶短得多呢?
答:因為高度代表桶里每單位空間的密度,而不是桶里的電影數量。 `[450,1500)`的桶中的電影確實比`[400,450)`的桶多,但它也是一個大桶。 所以它不那么擁擠。 其中的電影密度要低得多。
### 條形圖和直方圖的區別
+ 條形圖為每個類別展示一個數量。 它們通常用于顯示類別變量的分布。 直方圖顯示定量變量的分布。
+ 條形圖中的所有條形都具有相同的寬度,相鄰的條形之間有相等的間距。 直方圖的條形可以具有不同的寬度,并且是連續的。
+ 條形圖中條形的長度(或高度,如果垂直繪制)與每個類別的值成正比。 直方圖中條形的高度是密度的度量;直方圖中的條形的面積與桶中的條目數量成正比。
## 重疊的圖表
在這一章中,我們學習了如何通過繪制圖表來顯示數據。 這種可視化的常見用法是比較兩個數據集。 在本節中,我們將看到如何疊加繪圖,即將它們繪制在單個圖形中,擁有同一對坐標軸
為了使重疊有意義,重疊的圖必須表示相同的變量并以相同的單位進行測量。
為了繪制重疊圖,可以用相同的方法調用`scatter`,`plot`和`barh`方法。 對于`scatter`和`plot`,一列必須作為所有疊加圖的公共橫軸。 對于`barh`,一列必須作為一組類別的公共軸。 一般的調用看起來像這樣:
```py
name_of_table.method(column_label_of_common_axis, array_of_labels_of_variables_to_plot)
```
更常見的是,我們首先僅僅選取圖表所需的列。之后通過指定共同軸上的變量來調用方法。
```py
name_of_table.method(column_label_of_common_axis)
```
### 散點圖
高爾頓(Franics Galton,1822 ~ 1911 年)是一位英國博學家,他是分析數值變量之間關系的先驅。 他對有爭議的優生學領域特別感興趣,實際上,他創造了這個術語 - 這涉及到如何將物理特征從一代傳到下一代。
高爾頓精心收集了大量的數據,其中一些我們將在本課程中分析。 這是高爾頓的,有關父母及其子女身高的數據的子集。 具體來說,數據由 179 名男性組成,他們在家庭中第一個出生。數據是他們自己的高度和父母的高度。所有的高度都是以英寸來測量的。
```py
heights = Table.read_table('galton_subset.csv')
heights
```
| father | mother | son |
| --- | --- | --- |
| 78.5 | 67 | 73.2 |
| 75.5 | 66.5 | 73.5 |
| 75 | 64 | 71 |
| 75 | 64 | 70.5 |
| 75 | 58.5 | 72 |
| 74 | 68 | 76.5 |
| 74 | 62 | 74 |
| 73 | 67 | 71 |
| 73 | 67 | 68 |
| 73 | 66.5 | 71 |
(省略了 169 行)
`scatter`方法使我們能夠可視化,兒子的身高如何與父母的身高有關。 在圖中,兒子的身高將形成公共的橫軸。
```py
heights.scatter('son')
```

注意我們僅僅指定了公共的橫軸上的變量(兒子的身高)。 Python 繪制了兩個散點圖:這個變量和另外兩個之間的關系,每個關系一個。
金色和藍色的散點圖向上傾斜,并顯示出兒子的高度和父母的高度之間的正相關。 藍色(父親)的繪圖一般比金色高,因為父親一般比母親高。
### 線形圖
我們的下一個例子涉及更近的兒童數據。 我們將返回到人口普查數據表`us_pop`,再次在下面創建用于參考。 由此,我們將提取 0 至 18 歲年齡段的所有兒童的數量。
```py
# Read the full Census table
census_url = 'http://www2.census.gov/programs-surveys/popest/datasets/2010-2015/national/asrh/nc-est2015-agesex-res.csv'
full_census_table = Table.read_table(census_url)
# Select columns from the full table and relabel some of them
partial_census_table = full_census_table.select(['SEX', 'AGE', 'POPESTIMATE2010', 'POPESTIMATE2014'])
us_pop = partial_census_table.relabeled('POPESTIMATE2010', '2010').relabeled('POPESTIMATE2014', '2014')
# Access the rows corresponding to all children, ages 0-18
children = us_pop.where('SEX', are.equal_to(0)).where('AGE', are.below(19)).drop('SEX')
children.show()
```
| AGE | 2010 | 2014 |
| --- | --- | --- |
| 0 | 3951330 | 3949775 |
| 1 | 3957888 | 3949776 |
| 2 | 4090862 | 3959664 |
| 3 | 4111920 | 4007079 |
| 4 | 4077551 | 4005716 |
| 5 | 4064653 | 4006900 |
| 6 | 4073013 | 4135930 |
| 7 | 4043046 | 4155326 |
| 8 | 4025604 | 4120903 |
| 9 | 4125415 | 4108349 |
| 10 | 4187062 | 4116942 |
| 11 | 4115511 | 4087402 |
| 12 | 4113279 | 4070682 |
| 13 | 4119666 | 4171030 |
| 14 | 4145614 | 4233839 |
| 15 | 4231002 | 4164796 |
| 16 | 4313252 | 4168559 |
| 17 | 4376367 | 4186513 |
| 18 | 4491005 | 4227920 |
現在我們可以繪制兩個疊加的線形圖,顯示 2010 年和 2014 年的不同年齡的兒童人數。方法調用類似于前面例子中的`scatter`調用。
```py
children.plot('AGE')
```

在這個刻度上,重要的是要記住我們只有`0,1,2`歲等等的數據。 兩個圖形的點相互“交織”。
這些圖表在一些地方相互交叉:例如,2010 年的 4 歲人數比 2014 年多,2014 年的 14 歲人數比 2010 年多。
當然,2014 年的 14 歲兒童大部分都是 2010 年的 10 歲兒童。為了看到這一點,請查看 14 歲的金色圖表和 10 歲的藍色圖表。事實上,你會注意到,整個金色圖表(2014 年)看起來像藍色圖表(2010 年)向右滑了 4 年。 由于 2010 年至 2014 年間進入該國的兒童的凈效應,這個下滑幅度還是有所上升, 幸運的是,在這些年代,沒有太多的生命損失。
### 條形圖
對于本節的最后一個例子,我們看看加利福尼亞州以及整個美國的成人和兒童的種族分布情況。
凱撒家庭基金會根據人口普查數據,編制了美國人口種族分布情況。基金會的網站提供了 2014 年整個美國人口以及當年 18 歲以下的美國兒童的數據匯總。
這里是一個表格,采用了美國和加利福尼亞州的數據。 這些列代表美國和加利福尼亞州的每個人,美國和加州的兒童。 表格的主體包含不同類別的比例。 每一列顯示了,該列對應的人群的種族分布。 所以在每一列中,條目總計為 1。
```py
usa_ca = Table.read_table('usa_ca_2014.csv')
usa_ca
```
| Ethnicity | USA All | CA All | USA Children | CA Children |
| --- | --- | --- | --- | --- |
| Black | 0.12 | 0.05 | 0.14 | 0.05 |
| Hispanic | 0.18 | 0.38 | 0.24 | 0.5 |
| White | 0.62 | 0.39 | 0.52 | 0.29 |
| Other | 0.08 | 0.18 | 0.1 | 0.16 |
我們自然想要比較這些分布。 直接比較列是有意義的,因為所有條目都是比例,因此在相同刻度上。
`barh`方法允許我們通過在相同軸域上繪制多個條形圖,將比較可視化。這個調用類似于`scatter`和`plot`:我們必須指定類別的公共軸。
> 譯者注:軸域(Axes)是橫軸和縱軸圍城的區域。
```py
usa_ca.barh('Ethnicity')
```

雖然繪制疊加的條形圖非常簡單,但是我們可以在這個圖表上找到太多的信息,以便能夠理清種群之間的相似性和差異性。 似乎很清楚的是,美國所有人和美國兒童的種族分布比任何其他列都更相似,但是一次比較一對要容易得多。
首先比較美國和加利福尼亞的整個人口。
```py
usa_ca.select('Ethnicity', 'USA All', 'CA All').barh('Ethnicity')
```

這兩個分布是完全不同的。 加利福尼亞州的拉美裔和其他類別比例較高,黑人和白人比例相應較低。 這種差異主要是由于,加利福尼亞州的地理位置和移民模式,無論是歷史上還是近幾十年來。 例如,加利福尼亞的“其他”類別包括相當一部分亞洲人和太平洋島民。
從圖中可以看出,2014 年加州近 40% 的人口是拉美裔。 與該州兒童人口的比較表明,未來幾年拉美裔人口的比例可能會更高。 在加州兒童中,50% 屬于拉美裔。
```py
usa_ca.select('Ethnicity', 'CA All', 'CA Children').barh('Ethnicity')
```

更復雜的數據集自然會產生各種有趣的可視化效果,包括不同種類的重疊圖形。 為了分析這些數據,獲得更多的數據操作技能的有幫助的,這樣我們就可以將數據轉化為一種形式,使我們能夠使用本節中的方法。 在下一章中,我們將介紹其中的一些技巧。
