# 七、非線性特征提取和模型堆疊
> 譯者:[@friedhelm739](https://github.com/friedhelm739)
當在數據一個線性子空間像扁平餅時 PCA 是非常有用的。但是如果數據形成更復雜的形狀呢?一個平面(線性子空間)可以推廣到一個 *流形* (非線性子空間),它可以被認為是一個被各種拉伸和滾動的表面。
如果線性子空間是平的紙張,那么卷起的紙張就是非線性流形的例子。你也可以叫它瑞士卷。(見圖 7-1),一旦滾動,二維平面就會變為三維的。然而,它本質上仍是一個二維物體。換句話說,它具有低的內在維度,這是我們在“直覺”中已經接觸到的一個概念。如果我們能以某種方式展開瑞士卷,我們就可以恢復到二維平面。這是非線性降維的目標,它假定流形比它所占據的全維更簡單,并試圖展開它。
關鍵是,即使當大流形看起來復雜,每個點周圍的局部鄰域通常可以很好地近似于一片平坦的表面。換句話說,他們學習使用局部結構對全局結構進行編碼。非線性降維也被稱為非線性嵌入,或流形學習。非線性嵌入可有效地將高維數據壓縮成低維數據。它們通常用于 2-D 或 3-D 的可視化。
然而,特征工程的目的并不是要使特征維數盡可能低,而是要達到任務的正確特征。在這一章中,正確的特征是代表數據空間特征的特征。
聚類算法通常不是局部結構化學習的技術。但事實上也可以用他們這么做。彼此接近的點(由數據科學家使用某些度量可以定義的“接近度”)屬于同一個簇。給定聚類,數據點可以由其聚類成員向量來表示。如果簇的數量小于原始的特征數,則新的表示將比原始的具有更小的維度;原始數據被壓縮成較低的維度。
與非線性嵌入技術相比,聚類可以產生更多的特征。但是如果最終目標是特征工程而不是可視化,那這不是問題。
我們將提出一個使用 k 均值聚類算法來進行結構化學習的思想。它簡單易懂,易于實踐。與非線性流體降維相反,k 均值執行非線性流形特征提取更容易解釋。如果正確使用它,它可以是特征工程的一個強大的工具。
## k 均值聚類
k 均值是一種聚類算法。聚類算法根據數據在空間中的排列方式來分組數據。它們是無監督的,因為它們不需要任何類型的標簽,使用算法僅基于數據本身的幾何形狀來推斷聚類標簽。
聚類算法依賴于 *度量* ,它是度量數據點之間的緊密度的測量。最流行的度量是歐幾里德距離或歐幾里得度量。它來自歐幾里得幾何學并測量兩點之間的直線距離。我們對它很熟悉,因為這是我們在日常現實中看到的距離。
兩個向量`X`和`Y`之間的歐幾里得距離是`X-Y`的 L2 范數。(見 L2 范數的“L2 標準化”),在數學語言中,它通常被寫成`‖ x - y ‖`。
k 均值建立一個硬聚類,意味著每個數據點被分配給一個且只分配一個集群。該算法學習定位聚類中心,使得每個數據點和它的聚類中心之間的歐幾里德距離的總和最小化。對于那些喜歡閱讀公式而非語言的人來說,目標函數是:
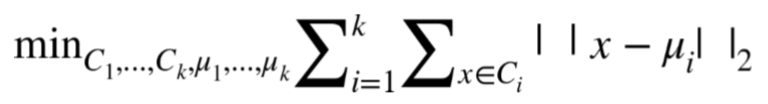
每個簇  包含數據點的子集。簇`i`的中心等于簇中所有數據點的平均值:,其中  表示簇`i`中的數據點的數目。
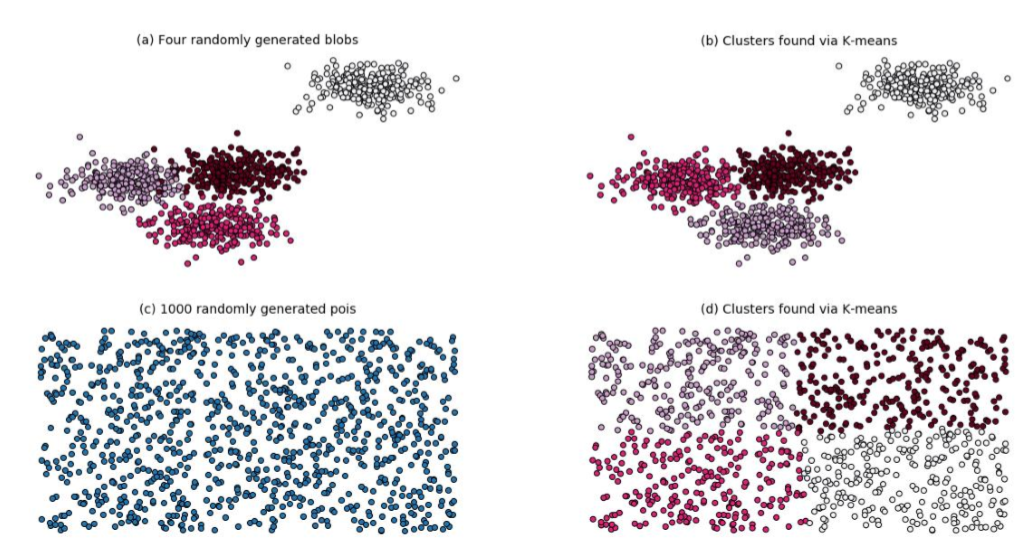
圖 7-2 顯示了 k 均值在兩個不同的隨機生成數據集上的工作。(a)中的數據是由具有相同方差但不同均值的隨機高斯分布生成的。(c)中的數據是隨機產生的。這些問題很容易解決,k 均值做得很好。(結果可能對簇的數目敏感,數目必須給算法)。這個例子的代碼如例 7-1 所示。
例 7-1
```python
import numpy as np
from sklearn.cluster
import KMeans from sklearn.datasets
import make_blobs
import matplotlib.pyplot as plt %matplotlib notebook
n_data = 1000
seed = 1
n_clusters = 4
# 產生高斯隨機數,運行K-均值
blobs, blob_labels = make_blobs(n_samples=n_data, n_features=2,centers=n_centers, random_state=seed)
clusters_blob = KMeans(n_clusters=n_centers, random_state=seed).fit_predict(blobs)
# 產生隨機數,運行K-均值
uniform = np.random.rand(n_data, 2)
clusters_uniform = KMeans(n_clusters=n_clusters, random_state=seed).fit_predict(uniform)
# 使用Matplotlib進行結果可視化
figure = plt.figure()
plt.subplot(221)
plt.scatter(blobs[:, 0], blobs[:, 1], c=blob_labels, cmap='gist_rainbow')
plt.title("(a) Four randomly generated blobs", fontsize=14)
plt.axis('off')
plt.subplot(222)
plt.scatter(blobs[:, 0], blobs[:, 1], c=clusters_blob, cmap='gist_rainbow')
plt.title("(b) Clusters found via K-means", fontsize=14)
plt.axis('off')
plt.subplot(223)
plt.scatter(uniform[:, 0], uniform[:, 1])
plt.title("(c) 1000 randomly generated points", fontsize=14)
plt.axis('off')
plt.subplot(224)
plt.scatter(uniform[:, 0], uniform[:, 1], c=clusters_uniform, cmap='gist_rainbow')
plt.title("(d) Clusters found via K-means", fontsize=14) plt.axis('off')
```

## 曲面拼接聚類
應用聚類一般假定存在自然簇,即在其他空的空間中存在密集的數據區域。在這些情況下,有一個正確的聚類數的概念,人們已經發明了聚類指數用于測量數據分組的質量,以便選擇k。
然而,當數據像如圖 7-2(c)那樣均勻分布時,不再有正確的簇數。在這種情況下,聚類算法的作用是矢量量化,即將數據劃分成有限數量的塊。當使用量化矢量而不是原始矢量時,可以基于可接受的近似誤差來選擇簇的數目。
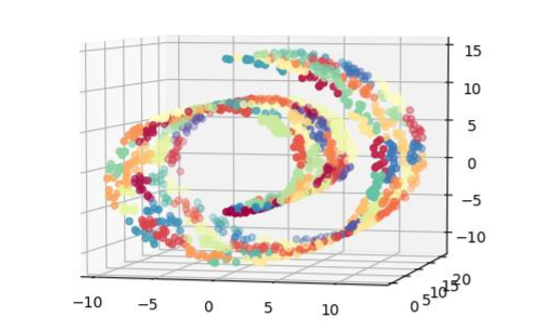
從視覺上看,k 均值的這種用法可以被認為是如圖 7-3 那樣用補丁覆蓋數據表面。如果在瑞士卷數據集上運行 k 均值,這確實是我們所得到的。例 7-2 使用`sklearn`生成瑞士卷上的嘈雜數據集,將其用 k 均值聚類,并使用 Matplotlib 可視化聚類結果。數據點根據它們的簇 ID 著色。

例 7-2
```python
from mpl_toolkits.mplot3d import Axes3D
from sklearn import manifold, datasets
# 在瑞士卷訓練集上產生噪聲
X, color = datasets.samples_generator.make_swiss_roll(n_samples=1500)
# 用100 K-均值聚類估計數據集
clusters_swiss_roll = KMeans(n_clusters=100, random_state=1).fit_predict(X)
# 展示用數據集,其中顏色是K-均值聚類的id
fig2 = plt.figure() ax = fig2.add_subplot(111, projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=clusters_swiss_roll, cmap='Spectral')
```
在這個例子中,我們在瑞士卷表面上隨機生成 1500 個點,并要求 k 均值用 100 個簇來近似它。我們提出 100 這個數字,因為它看起來相當大,使每一簇覆蓋了相當小的空間。結果看起來不錯;簇群確實是很小的的,并且流體的不同部分被映射到不同的簇。不錯!但我們完成了嗎?
問題是,如果我們選擇一個太小的`K`,那么從多元學習的角度來看,結果不會那么好。圖 7-5 顯示了 k 均值用 10 個簇在瑞士卷的輸出。我們可以清楚地看流體的完全的部分都被映射到相同的簇(例如黃色、紫色、綠色和品紅簇)的數據。
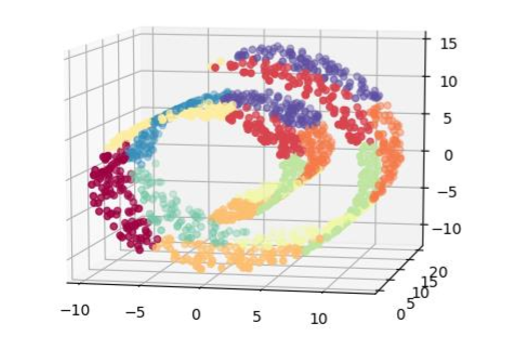
如果數據在空間中均勻分布,則選擇正確的`k`就被歸結為球填充問題。在`D`維中,可以擬合半徑約為`R`的`1/r`的`D`次冪的球。每個 k 均值聚類是一個球面,半徑是用質心表示球面中的點的最大誤差。因此,如果我們愿意容忍每個數據點`R`的最大逼近誤差,那么簇的數目是`O((1/R)^D)`,其中`D`是數據的原始特征空間的維數。
對于 k 均值來說,均勻分布是最壞的情況。如果數據密度不均勻,那么我們將能夠用更少的簇來表示更多的數據。一般來說,很難知道數據在高維空間中是如何分布的。我們可以保守的選擇更大的 K。但是它不能太大,因為`K`將成為下一步建模步驟的特征數量。
## 用于分類的 k 均值特征化
當使用 k 均值作為特征化過程時,數據點可以由它的簇成員(分類變量群組成員的稀疏獨熱編碼)來表示,我們現在來說明。
如果目標變量也是可用的,那么我們可以選擇將該信息作為對聚類過程的提示。一種合并目標信息的方法是簡單地將目標變量作為 k 均值算法的附加輸入特征。由于目標是最小化在所有輸入維度上的總歐氏距離,所以聚類過程將試圖平衡目標值和原始特征空間中的相似性。可以在聚類算法中對目標值進行縮放以獲得更多或更少的關注。目標的較大差異將產生更多關注分類邊界的聚類。
## k 均值特征化
聚類算法分析數據的空間分布。因此,k 均值特征化創建了一個壓縮的空間索引,該數據可以在下一階段被饋送到模型中。這是模型堆疊(stacking)的一個例子。
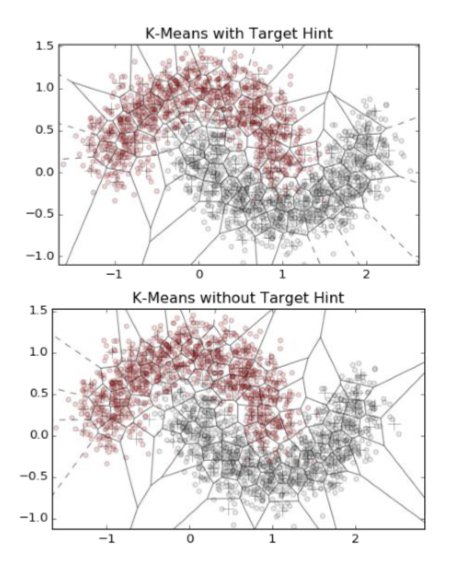
例 7-3 顯示了一個簡單的 k 均值特征。它被定義為可以訓練數據和變換任何新數據的類對象。為了說明在聚類時使用和不使用目標信息之間的差異,我們將特征化器應用到使用`sklearn`的 *make——moons* 函數(例 7-4)生成的合成數據集。然后我們繪制簇邊界的 Voronoi 圖。圖 7-6 展示出了結果的比較。底部面板顯示沒有目標信息訓練的集群。注意,許多簇跨越兩個類之間的空空間。頂部面板表明,當聚類算法被給定目標信息時,聚類邊界可以沿著類邊界更好地對齊。
例 7-3
```python
import numpy as np
from sklearn.cluster import KMeans
class KMeansFeaturizer:
"""將數字型數據輸入k-均值聚類.
在輸入數據上運行k-均值并且把每個數據點設定為它的簇id. 如果存在目標變量,則將其縮放并包含為k-均值的輸入,以導出服從分類邊界以及組相似點的簇。
"""
def __init__(self, k=100, target_scale=5.0, random_state=None):
self.k = k
self.target_scale = target_scale
self.random_state = random_state
def fit(self, X, y=None):
"""在輸入數據上運行k-均值,并找到中心."""
if y is None:
# 沒有目標變量運行k-均值
km_model = KMeans(n_clusters=self.k,n_init=20,random_state=self.random_state)
km_model.fit(X)
self.km_model_ = km_model
self.cluster_centers_ = km_model.cluster_centers_
return self
# 有目標信息,使用合適的縮減并把輸入數據輸入k-均值
data_with_target = np.hstack((X, y[:,np.newaxis]*self.target_scale))
# 在數據和目標上簡歷預訓練k-均值模型
km_model_pretrain = KMeans(n_clusters=self.k,n_init=20,random_state=self.random_state)
km_model_pretrain.fit(data_with_target)
#運行k-均值第二次獲得簇在原始空間沒有目標信息。使用預先訓練中發現的質心進行初始化。
#通過一個迭代的集群分配和質心重新計算。
km_model = KMeans(n_clusters=self.k,init=km_model_pretrain.cluster_centers_[:,:2],n_init=1,max_iter=1)
km_model.fit(X)
self.km_model = km_model
self.cluster_centers_ = km_model.cluster_centers_
return self
def transform(self, X, y=None):
"""為每個輸入數據點輸出最接近的簇id。"""
clusters = self.km_model.predict(X)
return clusters[:,np.newaxis]
def fit_transform(self, X, y=None):
self.fit(X, y)
return self.transform(X, y)
```
例 7-4
```python
from scipy.spatial import Voronoi, voronoi_plot_2d
from sklearn.datasets import make_moons
training_data, training_labels = make_moons(n_samples=2000, noise=0.2)
kmf_hint = KMeansFeaturizer(k=100, target_scale=10).fit(training_data, training_labels)
kmf_no_hint = KMeansFeaturizer(k=100, target_scale=0).fit(training_data, training_labels)
def kmeans_voronoi_plot(X, y, cluster_centers, ax):
"""繪制與數據疊加的k-均值聚類的Voronoi圖"""
ax.scatter(X[:, 0], X[:, 1], c=y, cmap='Set1', alpha=0.2)
vor = Voronoi(cluster_centers)
voronoi_plot_2d(vor, ax=ax, show_vertices=False, alpha=0.5)
```
讓我們測試 k 均值特征分類的有效性。例 7-5 對 k 均值簇特征增強的輸入數據應用 Logistic 回歸。比較了與使用徑向基核的支持向量機(RBF SVM)、K 近鄰(KNN)、隨機森林(RF)和梯度提升樹(GBT)的結果。隨機森林和梯度提升樹是最流行的非線性分類器,具有最先進的性能。RBF 支持向量機是歐氏空間的一種合理的非線性分類器。KNN 根據其 K 近鄰的平均值對數據進行分類。(請參閱“分類器概述”來概述每個分類器。)
分類器的默認輸入數據是數據的 2D 坐標。Logistic 回歸也給出了簇成員特征(在圖 7-7 中標注為“k 均值的 LR”)。作為基線,我們也嘗試在二維坐標(標記為“LR”)上進行邏輯回歸。
例 7-4
```python
from sklearn.linear_model
import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier
#生成與訓練數據相同分布的測試數據
test_data, test_labels = make_moons(n_samples=2000, noise=0.3)
# 使用k-均值特技器生成簇特征
training_cluster_features = kmf_hint.transform(training_data) test_cluster_features = kmf_hint.transform(test_data)
# 將新的輸入特征和聚類特征整合
training_with_cluster = scipy.sparse.hstack((training_data, training_cluster_features)) test_with_cluster = scipy.sparse.hstack((test_data, test_cluster_features))
# 建立分類器
lr_cluster = LogisticRegression(random_state=seed).fit(training_with_cluster, training_labels)
classifier_names = ['LR','kNN','RBF SVM','Random Forest','Boosted Trees']
classifiers = [LogisticRegression(random_state=seed),KNeighborsClassifier(5),SVC(gamma=2, C=1),RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1),GradientBoostingClassifier(n_estimators=10, learning_rate=1.0, max_depth=5)]
for model in classifiers:
model.fit(training_data, training_labels)
# 輔助函數使用ROC評估分類器性能
def test_roc(model, data, labels):
if hasattr(model, "decision_function"):
predictions = model.decision_function(data)
else:
predictions = model.predict_proba(data)[:,1]
fpr, tpr, _ = sklearn.metrics.roc_curve(labels, predictions)
return fpr, tpr
# 顯示結果
import matplotlib.pyplot as plt plt.figure()
fpr_cluster, tpr_cluster = test_roc(lr_cluster, test_with_cluster, test_labels) plt.plot(fpr_cluster, tpr_cluster, 'r-', label='LR with k-means')
for i, model in enumerate(classifiers):
fpr, tpr = test_roc(model, test_data, test_labels) plt.plot(fpr, tpr, label=classifier_names[i])
plt.plot([0, 1], [0, 1], 'k--')
plt.legend()
```
## 可選擇的密集化
與獨熱簇相反,數據點也可以由其逆距離的密集向量表示到每個聚類中心。這比簡單的二值化簇保留了更多的信息,但是現在表達是密集的。這里有一個折衷方案。一個熱集群成員導致一個非常輕量級的稀疏表示,但是一個可能需要較大的`K`來表示復雜形狀的數據。反向距離表示是密集的,這對于建模步驟可能花費更昂貴,但是這可以需要較小的`K`。
稀疏和密集之間的折衷是只保留最接近的簇的`p`的逆距離。但是現在`P`是一個額外的超參數需要去調整。(現在你能理解為什么特征工程需要這么多的步驟嗎?),天下沒有免費的午餐。
## 總結
使用 k 均值將空間數據轉換為模型堆疊的一個例子,其中一個模型的輸入是另一個模型的輸出。堆疊的另一個例子是使用決策樹類型模型(隨機森林或梯度提升樹)的輸出作為線性分類器的輸入。堆疊已成為近年來越來越流行的技術。非線性分類器訓練和維護是昂貴的。堆疊的關鍵一點是將非線性引入特征,并且使用非常簡單的、通常是線性的模型作為最后一層。該特征可以離線訓練,這意味著可以使用昂貴的模型,這需要更多的計算能力或內存,但產生有用的特征。頂層的簡單模型可以很快地適應在線數據的變化分布。這是精度和速度之間的一個很好的折衷,這經常被應用于需要快速適應改變數據分布的應用,比如目標廣告。
## 模型堆疊的關鍵點
復雜的基礎層(通常是昂貴的模型)產生良好的(通常是非線性的)特征,隨后結合簡單并且快速的頂層模型。這常常在模型精度和速度之間達到正確的平衡。
與使用非線性分類器相比,采用 logistic 回歸的 k 均值更容易進行訓練和存儲。表 7-1 是多個機器學習模型的計算和記憶的訓練和預測復雜性的圖表。`n`表示數據點的數量,`D`(原始)特征的數量。
對于 k 均值,訓練時間是`O(nkd)`,因為每次迭代涉及計算每個數據點和每個質心(`k`)之間的`d`維距離。我們樂觀地假設迭代次數不是`n`的函數,盡管并不普遍適用。預測需要計算新的數據點與質心(`k`)之間的距離,即`O(kd)`。存儲空間需求是`O(kd)`,對于`K`質心的坐標。
logistic 訓練和預測在數據點的數量和特征維度上都是線性的。RBF SVM 訓練是昂貴的,因為它涉及計算每一對輸入數據的核矩陣。RBF SVM 預測比訓練成本低,在支持向量`S`和特征維數`D`的數目上是線性的。改進的樹模型訓練和預測在數據大小和模型的大小上線性的(`t`個樹,每個最多 2 的`m`次冪子葉,其中`m`是樹的最大深度)。KNN 的實現根本不需要訓練時間,因為訓練數據本身本質上是模型。花費全都在預測時間,輸入必須對每個原始訓練點進行評估,并部分排序以檢索 K 近鄰。
總體而言,k 均值 +LR 是在訓練和預測時間上唯一的線性組合(相對于訓練數據`O(nd)`的大小和模型大小`O(kd)`)。復雜度最類似于提升樹,其成本在數據點的數量、特征維度和模型的大小(`O(2^m*t)`)中是線性的。很難說 k 均值 +LR 或提升樹是否會產生更小的模型,這取決于數據的空間特征。

## 數據泄露的潛力
那些記得我們對數據泄露的謹慎(參見“防止數據泄露(桶計數:未來的日子)”)可能會問 k 均值特化步驟中的目標變量是否也會導致這樣的問題。答案是“是的”,但并不像桶計數(Bin-counting)計算的那么多。如果我們使用相同的數據集來學習聚類和建立分類模型,那么關于目標的信息將泄漏到輸入變量中。因此,對訓練數據的精度評估可能過于樂觀,但是當在保持驗證集或測試集上進行評估時,偏差會消失。此外,泄漏不會像桶計數那么糟糕(參見“桶計數”),因為聚類算法的有損壓縮將抽象掉一些信息。要格外小心防止泄漏,人們可以始終保留一個單獨的數據集來導出簇,就像在桶計數下一樣。
k 均值特化對有實數、有界的數字特征是有用的,這些特征構成空間中密集區域的團塊。團塊可以是任何形狀,因為我們可以增加簇的數量來近似它們。(與經典的類別聚類不同,我們不關心真正的簇數;我們只需要覆蓋它們。)
k 均值不能處理歐幾里得距離沒有意義的特征空間,也就是說,奇怪的分布式數字變量或類別變量。如果特征集包含這些變量,那么有幾種處理它們的方法:
1. 僅在實值的有界數字特征上應用 k 均值特征。
2. 定義自定義度量(參見第?章以處理多個數據類型并使用 k 中心點算法。(k 中心點類似于 k 均值,但允許任意距離度量。)
3. 類別變量可以轉換為裝箱統計(見“桶計數”),然后使用 K 均值進行特征化。
結合處理分類變量和時間序列的技術,k 均值特化可以自適應的處理經常出現在客戶營銷和銷售分析中的豐富數據。所得到的聚類可以被認為是用戶段,這對于下一個建模步驟是非常有用的特征。
我們將在下一章中討論的深度學習,是通過將神經網絡層疊在一起,將模型堆疊提升到一個全新的水平。ImageNet 挑戰的兩個贏家使用了 13 層和 22 層神經網絡。就像 K 均值一樣,較低層次的深度學習模型是無監督的。它們利用大量可用的未標記的訓練圖像,并尋找產生良好圖像特征的像素組合。
