
# 第 2 章 Python 語法基礎,IPython 和 Jupyter Notebooks
當我在2011年和2012年寫作本書的第一版時,可用的學習Python數據分析的資源很少。這部分上是一個雞和蛋的問題:我們現在使用的庫,比如pandas、scikit-learn和statsmodels,那時相對來說并不成熟。2017年,數據科學、數據分析和機器學習的資源已經很多,原來通用的科學計算拓展到了計算機科學家、物理學家和其它研究領域的工作人員。學習Python和成為軟件工程師的優秀書籍也有了。
因為這本書是專注于Python數據處理的,對于一些Python的數據結構和庫的特性難免不足。因此,本章和第3章的內容只夠你能學習本書后面的內容。
在我來看,沒有必要為了數據分析而去精通Python。我鼓勵你使用IPython shell和Jupyter試驗示例代碼,并學習不同類型、函數和方法的文檔。雖然我已盡力讓本書內容循序漸進,但讀者偶爾仍會碰到沒有之前介紹過的內容。
本書大部分內容關注的是基于表格的分析和處理大規模數據集的數據準備工具。為了使用這些工具,必須首先將混亂的數據規整為整潔的表格(或結構化)形式。幸好,Python是一個理想的語言,可以快速整理數據。Python使用得越熟練,越容易準備新數據集以進行分析。
最好在IPython和Jupyter中親自嘗試本書中使用的工具。當你學會了如何啟動Ipython和Jupyter,我建議你跟隨示例代碼進行練習。與任何鍵盤驅動的操作環境一樣,記住常見的命令也是學習曲線的一部分。
> 筆記:本章沒有介紹Python的某些概念,如類和面向對象編程,你可能會發現它們在Python數據分析中很有用。 為了加強Python知識,我建議你學習官方Python教程,[https://docs.python.org/3/,或是通用的Python教程書籍,比如:](https://docs.python.org/3/,或是通用的Python教程書籍,比如:)
>
> * Python Cookbook,第3版,David Beazley和Brian K. Jones著(O’Reilly)
> * 流暢的Python,Luciano Ramalho著 \(O’Reilly\)
> * 高效的Python,Brett Slatkin著 \(Pearson\)
## 2.1 Python解釋器
Python是解釋性語言。Python解釋器同一時間只能運行一個程序的一條語句。標準的交互Python解釋器可以在命令行中通過鍵入`python`命令打開:
```text
$ python
Python 3.6.0 | packaged by conda-forge | (default, Jan 13 2017, 23:17:12)
[GCC 4.8.2 20140120 (Red Hat 4.8.2-15)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> a = 5
>>> print(a)
5
```
`>>>`提示輸入代碼。要退出Python解釋器返回終端,可以輸入`exit()`或按Ctrl-D。
運行Python程序只需調用Python的同時,使用一個`.py`文件作為它的第一個參數。假設創建了一個`hello_world.py`文件,它的內容是:
```python
print('Hello world')
```
你可以用下面的命令運行它(`hello_world.py`文件必須位于終端的工作目錄):
```python
$ python hello_world.py
Hello world
```
一些Python程序員總是這樣執行Python代碼的,從事數據分析和科學計算的人卻會使用IPython,一個強化的Python解釋器,或Jupyter notebooks,一個網頁代碼筆記本,它原先是IPython的一個子項目。在本章中,我介紹了如何使用IPython和Jupyter,在附錄A中有更深入的介紹。當你使用`%run`命令,IPython會同樣執行指定文件中的代碼,結束之后,還可以與結果交互:
```text
$ ipython
Python 3.6.0 | packaged by conda-forge | (default, Jan 13 2017, 23:17:12)
Type "copyright", "credits" or "license" for more information.
IPython 5.1.0 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]: %run hello_world.py
Hello world
In [2]:
```
IPython默認采用序號的格式`In [2]:`,與標準的`>>>`提示符不同。
## 2.2 IPython基礎
在本節中,我們會教你打開運行IPython shell和jupyter notebook,并介紹一些基本概念。
### 運行IPython Shell
你可以用`ipython`在命令行打開IPython Shell,就像打開普通的Python解釋器:
```text
$ ipython
Python 3.6.0 | packaged by conda-forge | (default, Jan 13 2017, 23:17:12)
Type "copyright", "credits" or "license" for more information.
IPython 5.1.0 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]: a = 5
In [2]: a
Out[2]: 5
```
你可以通過輸入代碼并按Return(或Enter),運行任意Python語句。當你只輸入一個變量,它會顯示代表的對象:
```python
In [5]: import numpy as np
In [6]: data = {i : np.random.randn() for i in range(7)}
In [7]: data
Out[7]:
{0: -0.20470765948471295,
1: 0.47894333805754824,
2: -0.5194387150567381,
3: -0.55573030434749,
4: 1.9657805725027142,
5: 1.3934058329729904,
6: 0.09290787674371767}
```
前兩行是Python代碼語句;第二條語句創建一個名為`data`的變量,它引用一個新創建的Python字典。最后一行打印`data`的值。
許多Python對象被格式化為更易讀的形式,或稱作`pretty-printed`,它與普通的`print`不同。如果在標準Python解釋器中打印上述`data`變量,則可讀性要降低:
```text
>>> from numpy.random import randn
>>> data = {i : randn() for i in range(7)}
>>> print(data)
{0: -1.5948255432744511, 1: 0.10569006472787983, 2: 1.972367135977295,
3: 0.15455217573074576, 4: -0.24058577449429575, 5: -1.2904897053651216,
6: 0.3308507317325902}
```
IPython還支持執行任意代碼塊(通過一個華麗的復制-粘貼方法)和整段Python腳本的功能。你也可以使用Jupyter notebook運行大代碼塊,接下來就會看到。
### 運行Jupyter Notebook
notebook是Jupyter項目的重要組件之一,它是一個代碼、文本(有標記或無標記)、數據可視化或其它輸出的交互式文檔。Jupyter Notebook需要與內核互動,內核是Jupyter與其它編程語言的交互編程協議。Python的Jupyter內核是使用IPython。要啟動Jupyter,在命令行中輸入`jupyter notebook`:
```text
$ jupyter notebook
[I 15:20:52.739 NotebookApp] Serving notebooks from local directory:
/home/wesm/code/pydata-book
[I 15:20:52.739 NotebookApp] 0 active kernels
[I 15:20:52.739 NotebookApp] The Jupyter Notebook is running at:
http://localhost:8888/
[I 15:20:52.740 NotebookApp] Use Control-C to stop this server and shut down
all kernels (twice to skip confirmation).
Created new window in existing browser session.
```
在多數平臺上,Jupyter會自動打開默認的瀏覽器(除非指定了`--no-browser`)。或者,可以在啟動notebook之后,手動打開網頁`http://localhost:8888/`。圖2-1展示了Google Chrome中的notebook。
> 筆記:許多人使用Jupyter作為本地的計算環境,但它也可以部署到服務器上遠程訪問。這里不做介紹,如果需要的話,鼓勵讀者自行到網上學習。
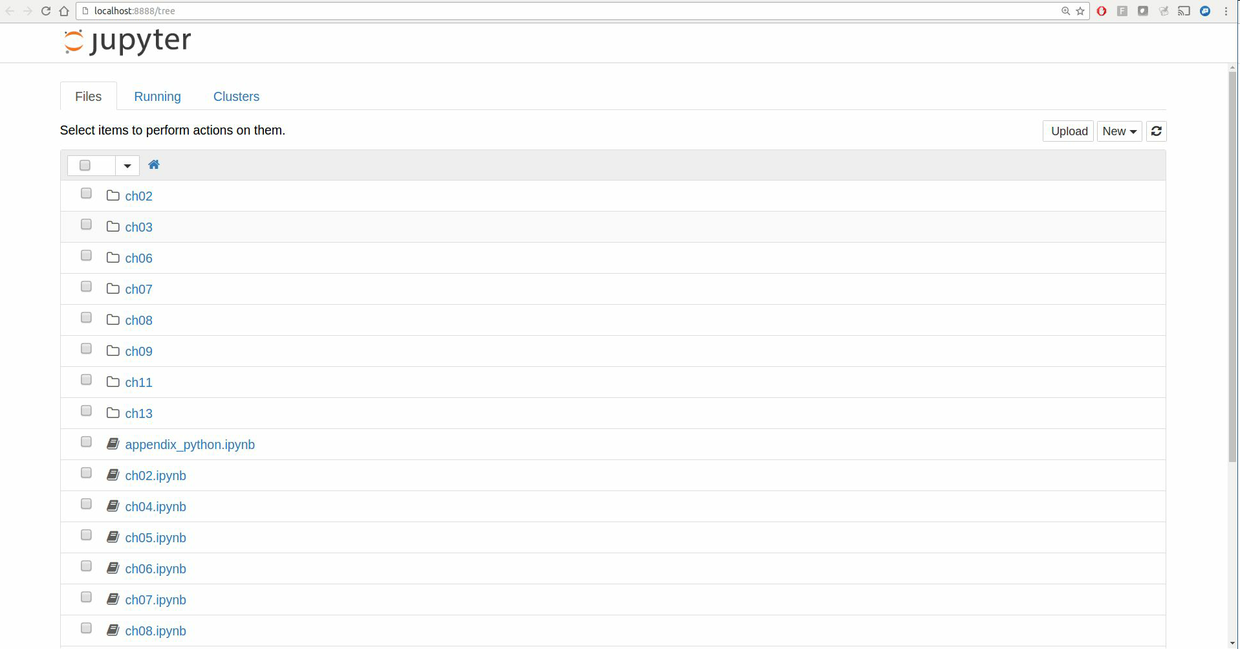
要新建一個notebook,點擊按鈕New,選擇“Python3”或“conda\[默認項\]”。如果是第一次,點擊空格,輸入一行Python代碼。然后按Shift-Enter執行。
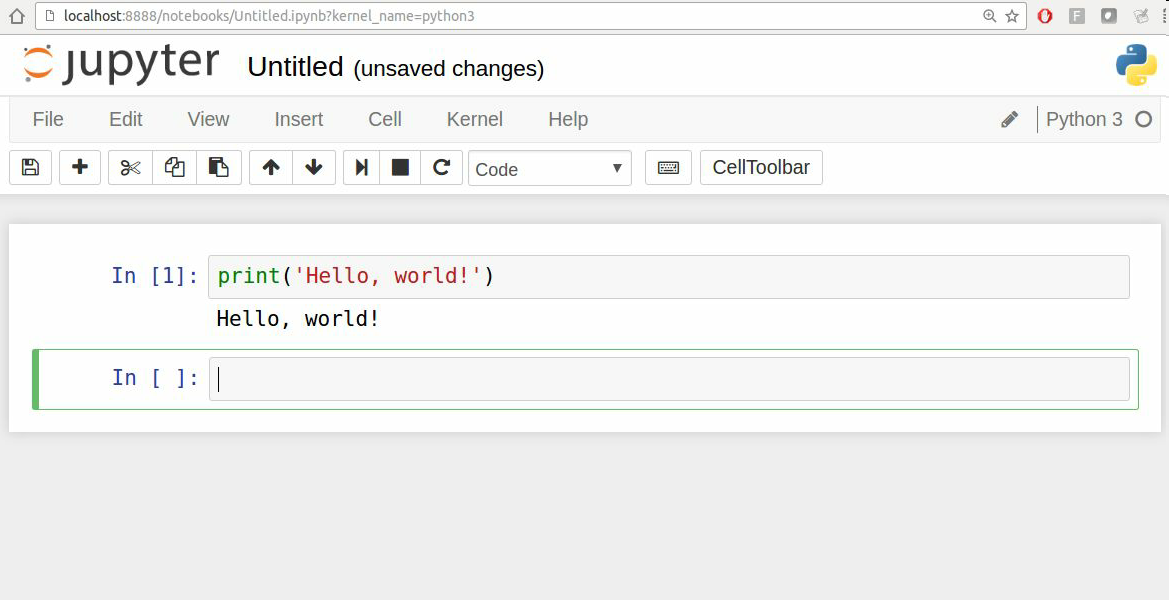
當保存notebook時(File目錄下的Save and Checkpoint),會創建一個后綴名為`.ipynb`的文件。這是一個自包含文件格式,包含當前筆記本中的所有內容(包括所有已評估的代碼輸出)。可以被其它Jupyter用戶加載和編輯。要加載存在的notebook,把它放到啟動notebook進程的相同目錄內。你可以用本書的示例代碼練習,見圖2-3。
雖然Jupyter notebook和IPython shell使用起來不同,本章中幾乎所有的命令和工具都可以通用。
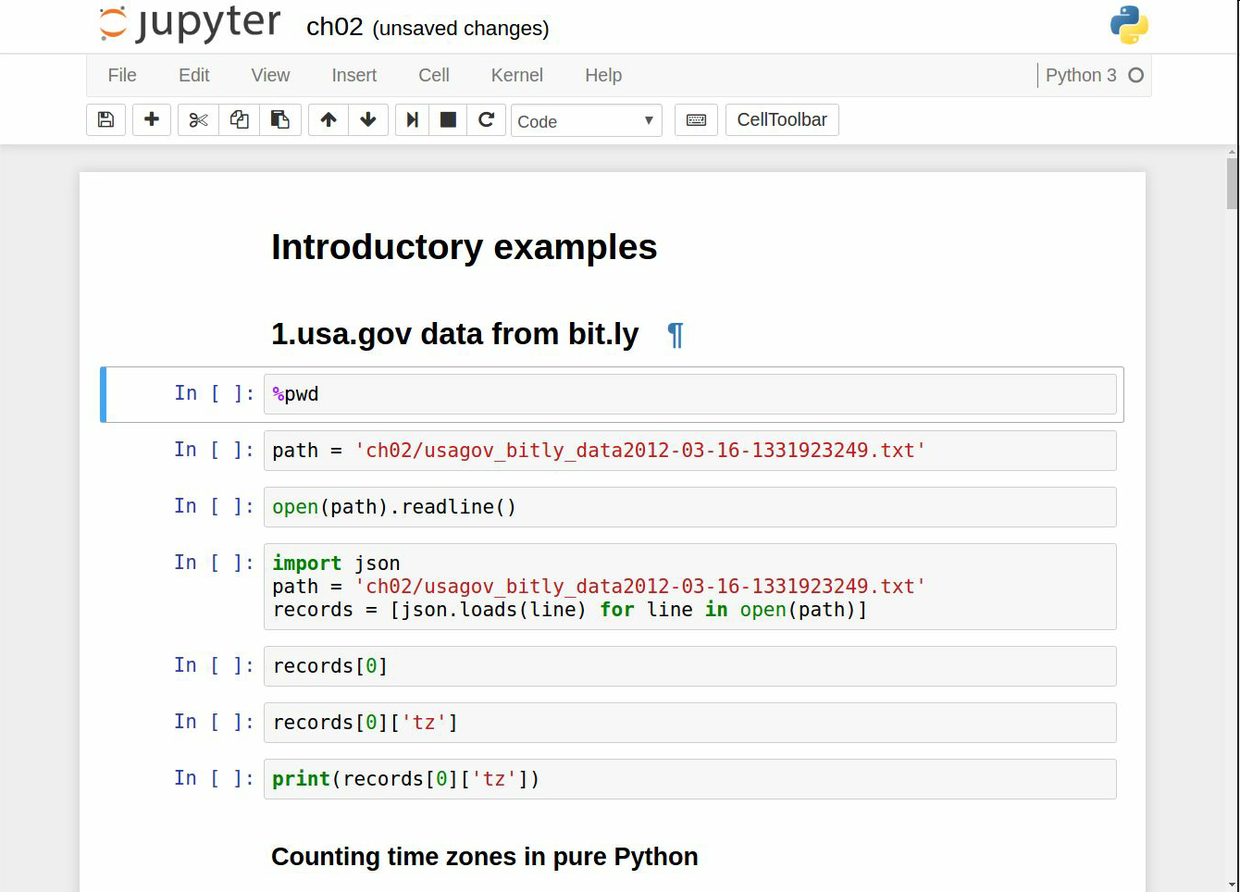
### Tab補全
從外觀上,IPython shell和標準的Python解釋器只是看起來不同。IPython shell的進步之一是具備其它IDE和交互計算分析環境都有的tab補全功能。在shell中輸入表達式,按下Tab,會搜索已輸入變量(對象、函數等等)的命名空間:
```text
In [1]: an_apple = 27
In [2]: an_example = 42
In [3]: an<Tab>
an_apple and an_example any
```
在這個例子中,IPython呈現出了之前兩個定義的變量和Python的關鍵字和內建的函數`any`。當然,你也可以補全任何對象的方法和屬性:
```text
In [3]: b = [1, 2, 3]
In [4]: b.<Tab>
b.append b.count b.insert b.reverse
b.clear b.extend b.pop b.sort
b.copy b.index b.remove
```
同樣也適用于模塊:
```text
In [1]: import datetime
In [2]: datetime.<Tab>
datetime.date datetime.MAXYEAR datetime.timedelta
datetime.datetime datetime.MINYEAR datetime.timezone
datetime.datetime_CAPI datetime.time datetime.tzinfo
```
在Jupyter notebook和新版的IPython(5.0及以上),自動補全功能是下拉框的形式。
> 筆記:注意,默認情況下,IPython會隱藏下劃線開頭的方法和屬性,比如魔術方法和內部的“私有”方法和屬性,以避免混亂的顯示(和讓新手迷惑!)這些也可以tab補全,但是你必須首先鍵入一個下劃線才能看到它們。如果你喜歡總是在tab補全中看到這樣的方法,你可以IPython配置中進行設置。可以在IPython文檔中查找方法。
除了補全命名、對象和模塊屬性,Tab還可以補全其它的。當輸入看似文件路徑時(即使是Python字符串),按下Tab也可以補全電腦上對應的文件信息:
```text
In [7]: datasets/movielens/<Tab>
datasets/movielens/movies.dat datasets/movielens/README
datasets/movielens/ratings.dat datasets/movielens/users.dat
In [7]: path = 'datasets/movielens/<Tab>
datasets/movielens/movies.dat datasets/movielens/README
datasets/movielens/ratings.dat datasets/movielens/users.dat
```
結合`%run`,tab補全可以節省許多鍵盤操作。
另外,tab補全可以補全函數的關鍵詞參數(包括等于號=)。見圖2-4。
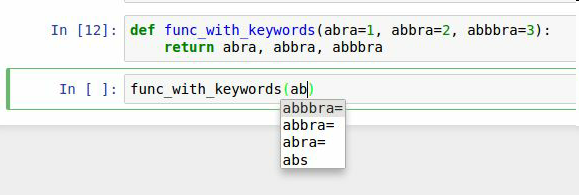
后面會仔細地學習函數。
### 自省
在變量前后使用問號?,可以顯示對象的信息:
```python
In [8]: b = [1, 2, 3]
In [9]: b?
Type: list
String Form:[1, 2, 3]
Length: 3
Docstring:
list() -> new empty list
list(iterable) -> new list initialized from iterable's items
In [10]: print?
Docstring:
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
Type: builtin_function_or_method
```
這可以作為對象的自省。如果對象是一個函數或實例方法,定義過的文檔字符串,也會顯示出信息。假設我們寫了一個如下的函數:
```python
def add_numbers(a, b):
"""
Add two numbers together
Returns
-------
the_sum : type of arguments
"""
return a + b
```
然后使用?符號,就可以顯示如下的文檔字符串:
```python
In [11]: add_numbers?
Signature: add_numbers(a, b)
Docstring:
Add two numbers together
Returns
-------
the_sum : type of arguments
File: <ipython-input-9-6a548a216e27>
Type: function
```
使用??會顯示函數的源碼:
```python
In [12]: add_numbers??
Signature: add_numbers(a, b)
Source:
def add_numbers(a, b):
"""
Add two numbers together
Returns
-------
the_sum : type of arguments
"""
return a + b
File: <ipython-input-9-6a548a216e27>
Type: function
```
?還有一個用途,就是像Unix或Windows命令行一樣搜索IPython的命名空間。字符與通配符結合可以匹配所有的名字。例如,我們可以獲得所有包含load的頂級NumPy命名空間:
```python
In [13]: np.*load*?
np.__loader__
np.load
np.loads
np.loadtxt
np.pkgload
```
### %run命令
你可以用`%run`命令運行所有的Python程序。假設有一個文件`ipython_script_test.py`:
```python
def f(x, y, z):
return (x + y) / z
a = 5
b = 6
c = 7.5
result = f(a, b, c)
```
可以如下運行:
```python
In [14]: %run ipython_script_test.py
```
這段腳本運行在空的命名空間(沒有import和其它定義的變量),因此結果和普通的運行方式`python script.py`相同。文件中所有定義的變量(import、函數和全局變量,除非拋出異常),都可以在IPython shell中隨后訪問:
```python
In [15]: c
Out [15]: 7.5
In [16]: result
Out[16]: 1.4666666666666666
```
如果一個Python腳本需要命令行參數(在`sys.argv`中查找),可以在文件路徑之后傳遞,就像在命令行上運行一樣。
> 筆記:如果想讓一個腳本訪問IPython已經定義過的變量,可以使用`%run -i`。
在Jupyter notebook中,你也可以使用`%load`,它將腳本導入到一個代碼格中:
```text
>>> %load ipython_script_test.py
def f(x, y, z):
return (x + y) / z
a = 5
b = 6
c = 7.5
result = f(a, b, c)
```
### 中斷運行的代碼
代碼運行時按Ctrl-C,無論是%run或長時間運行命令,都會導致`KeyboardInterrupt`。這會導致幾乎所有Python程序立即停止,除非一些特殊情況。
> 警告:當Python代碼調用了一些編譯的擴展模塊,按Ctrl-C不一定將執行的程序立即停止。在這種情況下,你必須等待,直到控制返回Python解釋器,或者在更糟糕的情況下強制終止Python進程。
### 從剪貼板執行程序
如果使用Jupyter notebook,你可以將代碼復制粘貼到任意代碼格執行。在IPython shell中也可以從剪貼板執行。假設在其它應用中復制了如下代碼:
```python
x = 5
y = 7
if x > 5:
x += 1
y = 8
```
最簡單的方法是使用`%paste`和`%cpaste`函數。`%paste`可以直接運行剪貼板中的代碼:
```python
In [17]: %paste
x = 5
y = 7
if x > 5:
x += 1
y = 8
## -- End pasted text --
```
`%cpaste`功能類似,但會給出一條提示:
```python
In [18]: %cpaste
Pasting code; enter '--' alone on the line to stop or use Ctrl-D.
:x = 5
:y = 7
:if x > 5:
: x += 1
:
: y = 8
:--
```
使用`%cpaste`,你可以粘貼任意多的代碼再運行。你可能想在運行前,先看看代碼。如果粘貼了錯誤的代碼,可以用Ctrl-C中斷。
### 鍵盤快捷鍵
IPython有許多鍵盤快捷鍵進行導航提示(類似Emacs文本編輯器或UNIX bash Shell)和交互shell的歷史命令。表2-1總結了常見的快捷鍵。圖2-5展示了一部分,如移動光標。
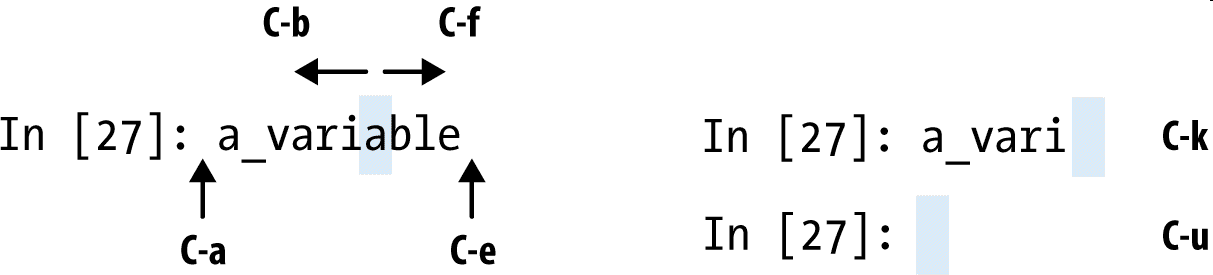

Jupyter notebooks有另外一套龐大的快捷鍵。因為它的快捷鍵比IPython的變化快,建議你參閱Jupyter notebook的幫助文檔。
### 魔術命令
IPython中特殊的命令(Python中沒有)被稱作“魔術”命令。這些命令可以使普通任務更便捷,更容易控制IPython系統。魔術命令是在指令前添加百分號%前綴。例如,可以用`%timeit`(這個命令后面會詳談)測量任何Python語句,例如矩陣乘法,的執行時間:
```python
In [20]: a = np.random.randn(100, 100)
In [20]: %timeit np.dot(a, a)
10000 loops, best of 3: 20.9 μs per loop
```
魔術命令可以被看做IPython中運行的命令行。許多魔術命令有“命令行”選項,可以通過?查看:
```text
In [21]: %debug?
Docstring:
::
%debug [--breakpoint FILE:LINE] [statement [statement ...]]
Activate the interactive debugger.
This magic command support two ways of activating debugger.
One is to activate debugger before executing code. This way, you
can set a break point, to step through the code from the point.
You can use this mode by giving statements to execute and optionally
a breakpoint.
The other one is to activate debugger in post-mortem mode. You can
activate this mode simply running %debug without any argument.
If an exception has just occurred, this lets you inspect its stack
frames interactively. Note that this will always work only on the last
traceback that occurred, so you must call this quickly after an
exception that you wish to inspect has fired, because if another one
occurs, it clobbers the previous one.
If you want IPython to automatically do this on every exception, see
the %pdb magic for more details.
positional arguments:
statement Code to run in debugger. You can omit this in cell
magic mode.
optional arguments:
--breakpoint <FILE:LINE>, -b <FILE:LINE>
Set break point at LINE in FILE.
```
魔術函數默認可以不用百分號,只要沒有變量和函數名相同。這個特點被稱為“自動魔術”,可以用`%automagic`打開或關閉。
一些魔術函數與Python函數很像,它的結果可以賦值給一個變量:
```text
In [22]: %pwd
Out[22]: '/home/wesm/code/pydata-book
In [23]: foo = %pwd
In [24]: foo
Out[24]: '/home/wesm/code/pydata-book'
```
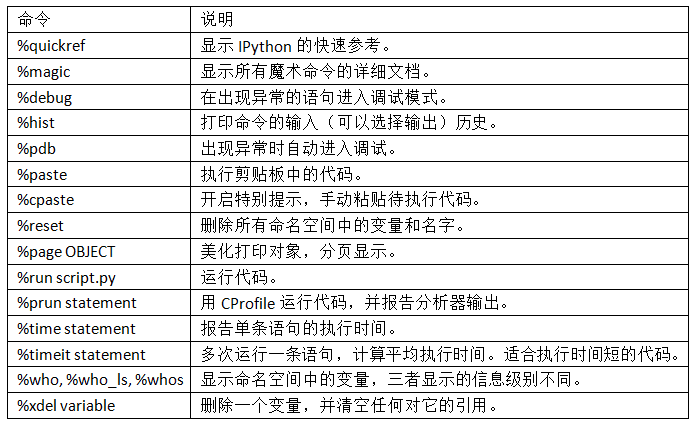
IPython的文檔可以在shell中打開,我建議你用`%quickref`或`%magic`學習下所有特殊命令。表2-2列出了一些可以提高生產率的交互計算和Python開發的IPython指令。
### 集成Matplotlib
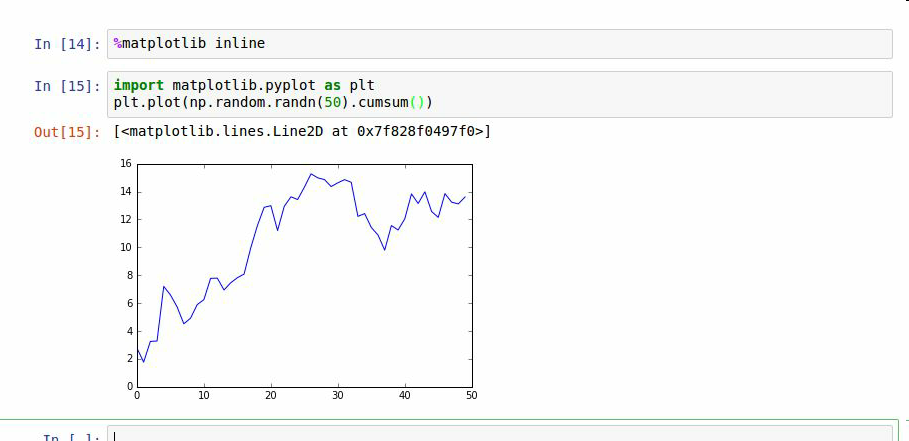
IPython在分析計算領域能夠流行的原因之一是它非常好的集成了數據可視化和其它用戶界面庫,比如matplotlib。不用擔心以前沒用過matplotlib,本書后面會詳細介紹。`%matplotlib`魔術函數配置了IPython shell和Jupyter notebook中的matplotlib。這點很重要,其它創建的圖不會出現(notebook)或獲取session的控制,直到結束(shell)。
在IPython shell中,運行`%matplotlib`可以進行設置,可以創建多個繪圖窗口,而不會干擾控制臺session:
```text
In [26]: %matplotlib
Using matplotlib backend: Qt4Agg
```
在JUpyter中,命令有所不同(圖2-6):
```text
In [26]: %matplotlib inline
```
## 2.3 Python語法基礎
在本節中,我將概述基本的Python概念和語言機制。在下一章,我將詳細介紹Python的數據結構、函數和其它內建工具。
### 語言的語義
Python的語言設計強調的是可讀性、簡潔和清晰。有些人稱Python為“可執行的偽代碼”。
### 使用縮進,而不是括號
Python使用空白字符(tab和空格)來組織代碼,而不是像其它語言,比如R、C++、JAVA和Perl那樣使用括號。看一個排序算法的`for`循環:
```python
for x in array:
if x < pivot:
less.append(x)
else:
greater.append(x)
```
冒號標志著縮進代碼塊的開始,冒號之后的所有代碼的縮進量必須相同,直到代碼塊結束。不管是否喜歡這種形式,使用空白符是Python程序員開發的一部分,在我看來,這可以讓python的代碼可讀性大大優于其它語言。雖然期初看起來很奇怪,經過一段時間,你就能適應了。
> 筆記:我強烈建議你使用四個空格作為默認的縮進,可以使用tab代替四個空格。許多文本編輯器的設置是使用制表位替代空格。某些人使用tabs或不同數目的空格數,常見的是使用兩個空格。大多數情況下,四個空格是大多數人采用的方法,因此建議你也這樣做。
你應該已經看到,Python的語句不需要用分號結尾。但是,分號卻可以用來給同在一行的語句切分:
```python
a = 5; b = 6; c = 7
```
Python不建議將多條語句放到一行,這會降低代碼的可讀性。
### 萬物皆對象
Python語言的一個重要特性就是它的對象模型的一致性。每個數字、字符串、數據結構、函數、類、模塊等等,都是在Python解釋器的自有“盒子”內,它被認為是Python對象。每個對象都有類型(例如,字符串或函數)和內部數據。在實際中,這可以讓語言非常靈活,因為函數也可以被當做對象使用。
### 注釋
任何前面帶有井號\#的文本都會被Python解釋器忽略。這通常被用來添加注釋。有時,你會想排除一段代碼,但并不刪除。簡便的方法就是將其注釋掉:
```python
results = []
for line in file_handle:
# keep the empty lines for now
# if len(line) == 0:
# continue
results.append(line.replace('foo', 'bar'))
```
也可以在執行過的代碼后面添加注釋。一些人習慣在代碼之前添加注釋,前者這種方法有時也是有用的:
```python
print("Reached this line") # Simple status report
```
### 函數和對象方法調用
你可以用圓括號調用函數,傳遞零個或幾個參數,或者將返回值給一個變量:
```python
result = f(x, y, z)
g()
```
幾乎Python中的每個對象都有附加的函數,稱作方法,可以用來訪問對象的內容。可以用下面的語句調用:
```python
obj.some_method(x, y, z)
```
函數可以使用位置和關鍵詞參數:
```python
result = f(a, b, c, d=5, e='foo')
```
后面會有更多介紹。
### 變量和參數傳遞
當在Python中創建變量(或名字),你就在等號右邊創建了一個對這個變量的引用。考慮一個整數列表:
```python
In [8]: a = [1, 2, 3]
```
假設將a賦值給一個新變量b:
```python
In [9]: b = a
```
在有些方法中,這個賦值會將數據\[1, 2, 3\]也復制。在Python中,a和b實際上是同一個對象,即原有列表\[1, 2, 3\](見圖2-7)。你可以在a中添加一個元素,然后檢查b:
```python
In [10]: a.append(4)
In [11]: b
Out[11]: [1, 2, 3, 4]
```

理解Python的引用的含義,數據是何時、如何、為何復制的,是非常重要的。尤其是當你用Python處理大的數據集時。
> 筆記:賦值也被稱作綁定,我們是把一個名字綁定給一個對象。變量名有時可能被稱為綁定變量。
當你將對象作為參數傳遞給函數時,新的局域變量創建了對原始對象的引用,而不是復制。如果在函數里綁定一個新對象到一個變量,這個變動不會反映到上一層。因此可以改變可變參數的內容。假設有以下函數:
```python
def append_element(some_list, element):
some_list.append(element)
```
然后有:
```python
In [27]: data = [1, 2, 3]
In [28]: append_element(data, 4)
In [29]: data
Out[29]: [1, 2, 3, 4]
```
### 動態引用,強類型
與許多編譯語言(如JAVA和C++)對比,Python中的對象引用不包含附屬的類型。下面的代碼是沒有問題的:
```python
In [12]: a = 5
In [13]: type(a)
Out[13]: int
In [14]: a = 'foo'
In [15]: type(a)
Out[15]: str
```
變量是在特殊命名空間中的對象的名字,類型信息保存在對象自身中。一些人可能會說Python不是“類型化語言”。這是不正確的,看下面的例子:
```text
In [16]: '5' + 5
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-16-f9dbf5f0b234> in <module>()
----> 1 '5' + 5
TypeError: must be str, not int
```
在某些語言中,例如Visual Basic,字符串‘5’可能被默許轉換(或投射)為整數,因此會產生10。但在其它語言中,例如JavaScript,整數5會被投射成字符串,結果是聯結字符串‘55’。在這個方面,Python被認為是強類型化語言,意味著每個對象都有明確的類型(或類),默許轉換只會發生在特定的情況下,例如:
```text
In [17]: a = 4.5
In [18]: b = 2
# String formatting, to be visited later
In [19]: print('a is {0}, b is {1}'.format(type(a), type(b)))
a is <class 'float'>, b is <class 'int'>
In [20]: a / b
Out[20]: 2.25
```
知道對象的類型很重要,最好能讓函數可以處理多種類型的輸入。你可以用`isinstance`函數檢查對象是某個類型的實例:
```text
In [21]: a = 5
In [22]: isinstance(a, int)
Out[22]: True
```
`isinstance`可以用類型元組,檢查對象的類型是否在元組中:
```text
In [23]: a = 5; b = 4.5
In [24]: isinstance(a, (int, float))
Out[24]: True
In [25]: isinstance(b, (int, float))
Out[25]: True
```
### 屬性和方法
Python的對象通常都有屬性(其它存儲在對象內部的Python對象)和方法(對象的附屬函數可以訪問對象的內部數據)。可以用`obj.attribute_name`訪問屬性和方法:
```text
In [1]: a = 'foo'
In [2]: a.<Press Tab>
a.capitalize a.format a.isupper a.rindex a.strip
a.center a.index a.join a.rjust a.swapcase
a.count a.isalnum a.ljust a.rpartition a.title
a.decode a.isalpha a.lower a.rsplit a.translate
a.encode a.isdigit a.lstrip a.rstrip a.upper
a.endswith a.islower a.partition a.split a.zfill
a.expandtabs a.isspace a.replace a.splitlines
a.find a.istitle a.rfind a.startswith
```
也可以用`getattr`函數,通過名字訪問屬性和方法:
```text
In [27]: getattr(a, 'split')
Out[27]: <function str.split>
```
在其它語言中,訪問對象的名字通常稱作“反射”。本書不會大量使用`getattr`函數和相關的`hasattr`和`setattr`函數,使用這些函數可以高效編寫原生的、可重復使用的代碼。
### 鴨子類型
經常地,你可能不關心對象的類型,只關心對象是否有某些方法或用途。這通常被稱為“鴨子類型”,來自“走起來像鴨子、叫起來像鴨子,那么它就是鴨子”的說法。例如,你可以通過驗證一個對象是否遵循迭代協議,判斷它是可迭代的。對于許多對象,這意味著它有一個`__iter__`魔術方法,其它更好的判斷方法是使用`iter`函數:
```python
def isiterable(obj):
try:
iter(obj)
return True
except TypeError: # not iterable
return False
```
這個函數會返回字符串以及大多數Python集合類型為`True`:
```text
In [29]: isiterable('a string')
Out[29]: True
In [30]: isiterable([1, 2, 3])
Out[30]: True
In [31]: isiterable(5)
Out[31]: False
```
我總是用這個功能編寫可以接受多種輸入類型的函數。常見的例子是編寫一個函數可以接受任意類型的序列(list、tuple、ndarray)或是迭代器。你可先檢驗對象是否是列表(或是NUmPy數組),如果不是的話,將其轉變成列表:
```python
if not isinstance(x, list) and isiterable(x):
x = list(x)
```
### 引入
在Python中,模塊就是一個有`.py`擴展名、包含Python代碼的文件。假設有以下模塊:
```python
# some_module.py
PI = 3.14159
def f(x):
return x + 2
def g(a, b):
return a + b
```
如果想從同目錄下的另一個文件訪問`some_module.py`中定義的變量和函數,可以:
```python
import some_module
result = some_module.f(5)
pi = some_module.PI
```
或者:
```python
from some_module import f, g, PI
result = g(5, PI)
```
使用`as`關鍵詞,你可以給引入起不同的變量名:
```python
import some_module as sm
from some_module import PI as pi, g as gf
r1 = sm.f(pi)
r2 = gf(6, pi)
```
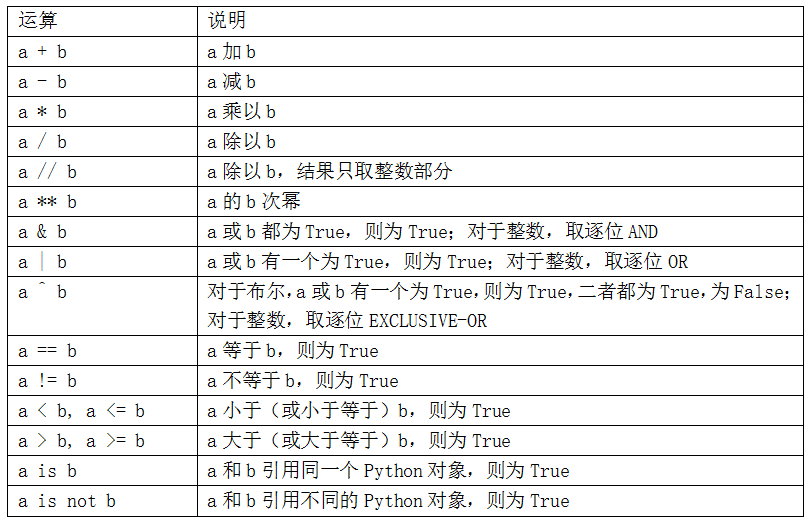
### 二元運算符和比較運算符
大多數二元數學運算和比較都不難想到:
```python
In [32]: 5 - 7
Out[32]: -2
In [33]: 12 + 21.5
Out[33]: 33.5
In [34]: 5 <= 2
Out[34]: False
```
表2-3列出了所有的二元運算符。
要判斷兩個引用是否指向同一個對象,可以使用`is`方法。`is not`可以判斷兩個對象是不同的:
```python
In [35]: a = [1, 2, 3]
In [36]: b = a
In [37]: c = list(a)
In [38]: a is b
Out[38]: True
In [39]: a is not c
Out[39]: True
```
因為`list`總是創建一個新的Python列表(即復制),我們可以斷定c是不同于a的。使用`is`比較與`==`運算符不同,如下:
```python
In [40]: a == c
Out[40]: True
```
`is`和`is not`常用來判斷一個變量是否為`None`,因為只有一個`None`的實例:
```python
In [41]: a = None
In [42]: a is None
Out[42]: True
```
### 可變與不可變對象
Python中的大多數對象,比如列表、字典、NumPy數組,和用戶定義的類型(類),都是可變的。意味著這些對象或包含的值可以被修改:
```python
In [43]: a_list = ['foo', 2, [4, 5]]
In [44]: a_list[2] = (3, 4)
In [45]: a_list
Out[45]: ['foo', 2, (3, 4)]
```
其它的,例如字符串和元組,是不可變的:
```python
In [46]: a_tuple = (3, 5, (4, 5))
In [47]: a_tuple[1] = 'four'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-47-b7966a9ae0f1> in <module>()
----> 1 a_tuple[1] = 'four'
TypeError: 'tuple' object does not support item assignment
```
記住,可以修改一個對象并不意味就要修改它。這被稱為副作用。例如,當寫一個函數,任何副作用都要在文檔或注釋中寫明。如果可能的話,我推薦避免副作用,采用不可變的方式,即使要用到可變對象。
### 標量類型
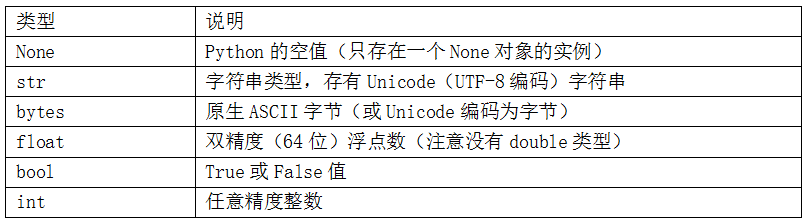
Python的標準庫中有一些內建的類型,用于處理數值數據、字符串、布爾值,和日期時間。這些單值類型被稱為標量類型,本書中稱其為標量。表2-4列出了主要的標量。日期和時間處理會另外討論,因為它們是標準庫的`datetime`模塊提供的。
### 數值類型
Python的主要數值類型是`int`和`float`。`int`可以存儲任意大的數:
```python
In [48]: ival = 17239871
In [49]: ival ** 6
Out[49]: 26254519291092456596965462913230729701102721
```
浮點數使用Python的`float`類型。每個數都是雙精度(64位)的值。也可以用科學計數法表示:
```python
In [50]: fval = 7.243
In [51]: fval2 = 6.78e-5
```
不能得到整數的除法會得到浮點數:
```python
In [52]: 3 / 2
Out[52]: 1.5
```
要獲得C-風格的整除(去掉小數部分),可以使用底除運算符//:
```python
In [53]: 3 // 2
Out[53]: 1
```
### 字符串
許多人是因為Python強大而靈活的字符串處理而使用Python的。你可以用單引號或雙引號來寫字符串:
```python
a = 'one way of writing a string'
b = "another way"
```
對于有換行符的字符串,可以使用三引號,'''或"""都行:
```python
c = """
This is a longer string that
spans multiple lines
"""
```
字符串`c`實際包含四行文本,"""后面和lines后面的換行符。可以用`count`方法計算`c`中的新的行:
```python
In [55]: c.count('\n')
Out[55]: 3
```
Python的字符串是不可變的,不能修改字符串:
```python
In [56]: a = 'this is a string'
In [57]: a[10] = 'f'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-57-5ca625d1e504> in <module>()
----> 1 a[10] = 'f'
TypeError: 'str' object does not support item assignment
In [58]: b = a.replace('string', 'longer string')
In [59]: b
Out[59]: 'this is a longer string'
```
經過以上的操作,變量`a`并沒有被修改:
```python
In [60]: a
Out[60]: 'this is a string'
```
許多Python對象使用`str`函數可以被轉化為字符串:
```python
In [61]: a = 5.6
In [62]: s = str(a)
In [63]: print(s)
5.6
```
字符串是一個序列的Unicode字符,因此可以像其它序列,比如列表和元組(下一章會詳細介紹兩者)一樣處理:
```python
In [64]: s = 'python'
In [65]: list(s)
Out[65]: ['p', 'y', 't', 'h', 'o', 'n']
In [66]: s[:3]
Out[66]: 'pyt'
```
語法`s[:3]`被稱作切片,適用于許多Python序列。后面會更詳細的介紹,本書中用到很多切片。
反斜杠是轉義字符,意思是它備用來表示特殊字符,比如換行符\n或Unicode字符。要寫一個包含反斜杠的字符串,需要進行轉義:
```python
In [67]: s = '12\\34'
In [68]: print(s)
12\34
```
如果字符串中包含許多反斜杠,但沒有特殊字符,這樣做就很麻煩。幸好,可以在字符串前面加一個r,表明字符就是它自身:
```python
In [69]: s = r'this\has\no\special\characters'
In [70]: s
Out[70]: 'this\\has\\no\\special\\characters'
```
r表示raw。
將兩個字符串合并,會產生一個新的字符串:
```python
In [71]: a = 'this is the first half '
In [72]: b = 'and this is the second half'
In [73]: a + b
Out[73]: 'this is the first half and this is the second half'
```
字符串的模板化或格式化,是另一個重要的主題。Python 3拓展了此類的方法,這里只介紹一些。字符串對象有`format`方法,可以替換格式化的參數為字符串,產生一個新的字符串:
```python
In [74]: template = '{0:.2f} {1:s} are worth US${2:d}'
```
在這個字符串中,
* `{0:.2f}`表示格式化第一個參數為帶有兩位小數的浮點數。
* `{1:s}`表示格式化第二個參數為字符串。
* `{2:d}`表示格式化第三個參數為一個整數。
要替換參數為這些格式化的參數,我們傳遞`format`方法一個序列:
```python
In [75]: template.format(4.5560, 'Argentine Pesos', 1)
Out[75]: '4.56 Argentine Pesos are worth US$1'
```
字符串格式化是一個很深的主題,有多種方法和大量的選項,可以控制字符串中的值是如何格式化的。推薦參閱Python官方文檔。
這里概括介紹字符串處理,第8章的數據分析會詳細介紹。
### 字節和Unicode
在Python 3及以上版本中,Unicode是一級的字符串類型,這樣可以更一致的處理ASCII和Non-ASCII文本。在老的Python版本中,字符串都是字節,不使用Unicode編碼。假如知道字符編碼,可以將其轉化為Unicode。看一個例子:
```python
In [76]: val = "espa?ol"
In [77]: val
Out[77]: 'espa?ol'
```
可以用`encode`將這個Unicode字符串編碼為UTF-8:
```python
In [78]: val_utf8 = val.encode('utf-8')
In [79]: val_utf8
Out[79]: b'espa\xc3\xb1ol'
In [80]: type(val_utf8)
Out[80]: bytes
```
如果你知道一個字節對象的Unicode編碼,用`decode`方法可以解碼:
```python
In [81]: val_utf8.decode('utf-8')
Out[81]: 'espa?ol'
```
雖然UTF-8編碼已經變成主流,但因為歷史的原因,你仍然可能碰到其它編碼的數據:
```python
In [82]: val.encode('latin1')
Out[82]: b'espa\xf1ol'
In [83]: val.encode('utf-16')
Out[83]: b'\xff\xfee\x00s\x00p\x00a\x00\xf1\x00o\x00l\x00'
In [84]: val.encode('utf-16le')
Out[84]: b'e\x00s\x00p\x00a\x00\xf1\x00o\x00l\x00'
```
工作中碰到的文件很多都是字節對象,盲目地將所有數據編碼為Unicode是不可取的。
雖然用的不多,你可以在字節文本的前面加上一個b:
```python
In [85]: bytes_val = b'this is bytes'
In [86]: bytes_val
Out[86]: b'this is bytes'
In [87]: decoded = bytes_val.decode('utf8')
In [88]: decoded # this is str (Unicode) now
Out[88]: 'this is bytes'
```
### 布爾值
Python中的布爾值有兩個,True和False。比較和其它條件表達式可以用True和False判斷。布爾值可以與and和or結合使用:
```python
In [89]: True and True
Out[89]: True
In [90]: False or True
Out[90]: True
```
### 類型轉換
str、bool、int和float也是函數,可以用來轉換類型:
```python
In [91]: s = '3.14159'
In [92]: fval = float(s)
In [93]: type(fval)
Out[93]: float
In [94]: int(fval)
Out[94]: 3
In [95]: bool(fval)
Out[95]: True
In [96]: bool(0)
Out[96]: False
```
### None
None是Python的空值類型。如果一個函數沒有明確的返回值,就會默認返回None:
```python
In [97]: a = None
In [98]: a is None
Out[98]: True
In [99]: b = 5
In [100]: b is not None
Out[100]: True
```
None也常常作為函數的默認參數:
```python
def add_and_maybe_multiply(a, b, c=None):
result = a + b
if c is not None:
result = result * c
return result
```
另外,None不僅是一個保留字,還是唯一的NoneType的實例:
```python
In [101]: type(None)
Out[101]: NoneType
```
### 日期和時間
Python內建的`datetime`模塊提供了`datetime`、`date`和`time`類型。`datetime`類型結合了`date`和`time`,是最常使用的:
```python
In [102]: from datetime import datetime, date, time
In [103]: dt = datetime(2011, 10, 29, 20, 30, 21)
In [104]: dt.day
Out[104]: 29
In [105]: dt.minute
Out[105]: 30
```
根據`datetime`實例,你可以用`date`和`time`提取出各自的對象:
```python
In [106]: dt.date()
Out[106]: datetime.date(2011, 10, 29)
In [107]: dt.time()
Out[107]: datetime.time(20, 30, 21)
```
`strftime`方法可以將datetime格式化為字符串:
```python
In [108]: dt.strftime('%m/%d/%Y %H:%M')
Out[108]: '10/29/2011 20:30'
```
`strptime`可以將字符串轉換成`datetime`對象:
```python
In [109]: datetime.strptime('20091031', '%Y%m%d')
Out[109]: datetime.datetime(2009, 10, 31, 0, 0)
```
表2-5列出了所有的格式化命令。

當你聚類或對時間序列進行分組,替換datetimes的time字段有時會很有用。例如,用0替換分和秒:
```python
In [110]: dt.replace(minute=0, second=0)
Out[110]: datetime.datetime(2011, 10, 29, 20, 0)
```
因為`datetime.datetime`是不可變類型,上面的方法會產生新的對象。
兩個datetime對象的差會產生一個`datetime.timedelta`類型:
```python
In [111]: dt2 = datetime(2011, 11, 15, 22, 30)
In [112]: delta = dt2 - dt
In [113]: delta
Out[113]: datetime.timedelta(17, 7179)
In [114]: type(delta)
Out[114]: datetime.timedelta
```
結果`timedelta(17, 7179)`指明了`timedelta`將17天、7179秒的編碼方式。
將`timedelta`添加到`datetime`,會產生一個新的偏移`datetime`:
```python
In [115]: dt
Out[115]: datetime.datetime(2011, 10, 29, 20, 30, 21)
In [116]: dt + delta
Out[116]: datetime.datetime(2011, 11, 15, 22, 30)
```
### 控制流
Python有若干內建的關鍵字進行條件邏輯、循環和其它控制流操作。
### if、elif和else
if是最廣為人知的控制流語句。它檢查一個條件,如果為True,就執行后面的語句:
```python
if x < 0:
print('It's negative')
```
`if`后面可以跟一個或多個`elif`,所有條件都是False時,還可以添加一個`else`:
```python
if x < 0:
print('It's negative')
elif x == 0:
print('Equal to zero')
elif 0 < x < 5:
print('Positive but smaller than 5')
else:
print('Positive and larger than or equal to 5')
```
如果某個條件為True,后面的`elif`就不會被執行。當使用and和or時,復合條件語句是從左到右執行:
```python
In [117]: a = 5; b = 7
In [118]: c = 8; d = 4
In [119]: if a < b or c > d:
.....: print('Made it')
Made it
```
在這個例子中,`c > d`不會被執行,因為第一個比較是True:
也可以把比較式串在一起:
```python
In [120]: 4 > 3 > 2 > 1
Out[120]: True
```
### for循環
for循環是在一個集合(列表或元組)中進行迭代,或者就是一個迭代器。for循環的標準語法是:
```python
for value in collection:
# do something with value
```
你可以用continue使for循環提前,跳過剩下的部分。看下面這個例子,將一個列表中的整數相加,跳過None:
```python
sequence = [1, 2, None, 4, None, 5]
total = 0
for value in sequence:
if value is None:
continue
total += value
```
可以用`break`跳出for循環。下面的代碼將各元素相加,直到遇到5:
```python
sequence = [1, 2, 0, 4, 6, 5, 2, 1]
total_until_5 = 0
for value in sequence:
if value == 5:
break
total_until_5 += value
```
break只中斷for循環的最內層,其余的for循環仍會運行:
```python
In [121]: for i in range(4):
.....: for j in range(4):
.....: if j > i:
.....: break
.....: print((i, j))
.....:
(0, 0)
(1, 0)
(1, 1)
(2, 0)
(2, 1)
(2, 2)
(3, 0)
(3, 1)
(3, 2)
(3, 3)
```
如果集合或迭代器中的元素序列(元組或列表),可以用for循環將其方便地拆分成變量:
```python
for a, b, c in iterator:
# do something
```
### While循環
while循環指定了條件和代碼,當條件為False或用break退出循環,代碼才會退出:
```python
x = 256
total = 0
while x > 0:
if total > 500:
break
total += x
x = x // 2
```
### pass
pass是Python中的非操作語句。代碼塊不需要任何動作時可以使用(作為未執行代碼的占位符);因為Python需要使用空白字符劃定代碼塊,所以需要pass:
```python
if x < 0:
print('negative!')
elif x == 0:
# TODO: put something smart here
pass
else:
print('positive!')
```
### range
range函數返回一個迭代器,它產生一個均勻分布的整數序列:
```python
In [122]: range(10)
Out[122]: range(0, 10)
In [123]: list(range(10))
Out[123]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
```
range的三個參數是(起點,終點,步進):
```python
In [124]: list(range(0, 20, 2))
Out[124]: [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
In [125]: list(range(5, 0, -1))
Out[125]: [5, 4, 3, 2, 1]
```
可以看到,range產生的整數不包括終點。range的常見用法是用序號迭代序列:
```python
seq = [1, 2, 3, 4]
for i in range(len(seq)):
val = seq[i]
```
可以使用list來存儲range在其他數據結構中生成的所有整數,默認的迭代器形式通常是你想要的。下面的代碼對0到99999中3或5的倍數求和:
```python
sum = 0
for i in range(100000):
# % is the modulo operator
if i % 3 == 0 or i % 5 == 0:
sum += i
```
雖然range可以產生任意大的數,但任意時刻耗用的內存卻很小。
### 三元表達式
Python中的三元表達式可以將if-else語句放到一行里。語法如下:
```python
value = true-expr if condition else false-expr
```
`true-expr`或`false-expr`可以是任何Python代碼。它和下面的代碼效果相同:
```python
if condition:
value = true-expr
else:
value = false-expr
```
下面是一個更具體的例子:
```python
In [126]: x = 5
In [127]: 'Non-negative' if x >= 0 else 'Negative'
Out[127]: 'Non-negative'
```
和if-else一樣,只有一個表達式會被執行。因此,三元表達式中的if和else可以包含大量的計算,但只有True的分支會被執行。因此,三元表達式中的if和else可以包含大量的計算,但只有True的分支會被執行。
雖然使用三元表達式可以壓縮代碼,但會降低代碼可讀性。
- 利用 Python 進行數據分析 · 第 2 版
- 第 1 章 準備工作
- 第 2 章 Python 語法基礎,IPython 和 Jupyter Notebooks
- 第 3 章 Python 的數據結構、函數和文件
- 第 4 章 NumPy 基礎:數組和矢量計算
- 第 5 章 pandas 入門
- 第 6 章 數據加載、存儲與文件格式
- 第 7 章 數據清洗和準備
- 第 8 章 數據規整:聚合、合并和重塑
- 第 9 章 繪圖和可視化
- 第 10 章 數據聚合與分組運算
- 第 11 章 時間序列
- 第 12 章 pandas 高級應用
- 第 13 章 Python 建模庫介紹
- 第 14 章 數據分析案例
- 附錄 A NumPy 高級應用
- 附錄 B 更多關于 IPython 的內容