
# 第 11 章 時間序列
時間序列(time series)數據是一種重要的結構化數據形式,應用于多個領域,包括金融學、經濟學、生態學、神經科學、物理學等。在多個時間點觀察或測量到的任何事物都可以形成一段時間序列。很多時間序列是固定頻率的,也就是說,數據點是根據某種規律定期出現的(比如每15秒、每5分鐘、每月出現一次)。時間序列也可以是不定期的,沒有固定的時間單位或單位之間的偏移量。時間序列數據的意義取決于具體的應用場景,主要有以下幾種:
- 時間戳(timestamp),特定的時刻。
- 固定時期(period),如2007年1月或2010年全年。
- 時間間隔(interval),由起始和結束時間戳表示。時期(period)可以被看做間隔(interval)的特例。
- 實驗或過程時間,每個時間點都是相對于特定起始時間的一個度量。例如,從放入烤箱時起,每秒鐘餅干的直徑。
本章主要講解前3種時間序列。許多技術都可用于處理實驗型時間序列,其索引可能是一個整數或浮點數(表示從實驗開始算起已經過去的時間)。最簡單也最常見的時間序列都是用時間戳進行索引的。
>提示:pandas也支持基于timedeltas的指數,它可以有效代表實驗或經過的時間。這本書不涉及timedelta指數,但你可以學習pandas的文檔(http://pandas.pydata.org/)。
pandas提供了許多內置的時間序列處理工具和數據算法。因此,你可以高效處理非常大的時間序列,輕松地進行切片/切塊、聚合、對定期/不定期的時間序列進行重采樣等。有些工具特別適合金融和經濟應用,你當然也可以用它們來分析服務器日志數據。
# 11.1 日期和時間數據類型及工具
Python標準庫包含用于日期(date)和時間(time)數據的數據類型,而且還有日歷方面的功能。我們主要會用到datetime、time以及calendar模塊。datetime.datetime(也可以簡寫為datetime)是用得最多的數據類型:
```python
In [10]: from datetime import datetime
In [11]: now = datetime.now()
In [12]: now
Out[12]: datetime.datetime(2017, 9, 25, 14, 5, 52, 72973)
In [13]: now.year, now.month, now.day
Out[13]: (2017, 9, 25)
```
datetime以毫秒形式存儲日期和時間。timedelta表示兩個datetime對象之間的時間差:
```python
In [14]: delta = datetime(2011, 1, 7) - datetime(2008, 6, 24, 8, 15)
In [15]: delta
Out[15]: datetime.timedelta(926, 56700)
In [16]: delta.days
Out[16]: 926
In [17]: delta.seconds
Out[17]: 56700
```
可以給datetime對象加上(或減去)一個或多個timedelta,這樣會產生一個新對象:
```python
In [18]: from datetime import timedelta
In [19]: start = datetime(2011, 1, 7)
In [20]: start + timedelta(12)
Out[20]: datetime.datetime(2011, 1, 19, 0, 0)
In [21]: start - 2 * timedelta(12)
Out[21]: datetime.datetime(2010, 12, 14, 0, 0)
```
datetime模塊中的數據類型參見表10-1。雖然本章主要講的是pandas數據類型和高級時間序列處理,但你肯定會在Python的其他地方遇到有關datetime的數據類型。
表11-1 datetime模塊中的數據類型

tzinfo 存儲時區信息的基本類型
## 字符串和datetime的相互轉換
利用str或strftime方法(傳入一個格式化字符串),datetime對象和pandas的Timestamp對象(稍后就會介紹)可以被格式化為字符串:
```python
In [22]: stamp = datetime(2011, 1, 3)
In [23]: str(stamp)
Out[23]: '2011-01-03 00:00:00'
In [24]: stamp.strftime('%Y-%m-%d')
Out[24]: '2011-01-03'
```
表11-2列出了全部的格式化編碼。
表11-2 datetime格式定義(兼容ISO C89)
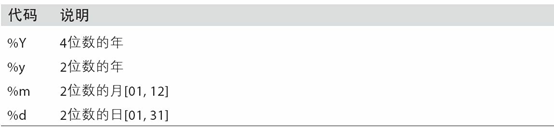

datetime.strptime可以用這些格式化編碼將字符串轉換為日期:
```python
In [25]: value = '2011-01-03'
In [26]: datetime.strptime(value, '%Y-%m-%d')
Out[26]: datetime.datetime(2011, 1, 3, 0, 0)
In [27]: datestrs = ['7/6/2011', '8/6/2011']
In [28]: [datetime.strptime(x, '%m/%d/%Y') for x in datestrs]
Out[28]:
[datetime.datetime(2011, 7, 6, 0, 0),
datetime.datetime(2011, 8, 6, 0, 0)]
```
datetime.strptime是通過已知格式進行日期解析的最佳方式。但是每次都要編寫格式定義是很麻煩的事情,尤其是對于一些常見的日期格式。這種情況下,你可以用dateutil這個第三方包中的parser.parse方法(pandas中已經自動安裝好了):
```python
In [29]: from dateutil.parser import parse
In [30]: parse('2011-01-03')
Out[30]: datetime.datetime(2011, 1, 3, 0, 0)
```
dateutil可以解析幾乎所有人類能夠理解的日期表示形式:
```python
In [31]: parse('Jan 31, 1997 10:45 PM')
Out[31]: datetime.datetime(1997, 1, 31, 22, 45)
```
在國際通用的格式中,日出現在月的前面很普遍,傳入dayfirst=True即可解決這個問題:
```python
In [32]: parse('6/12/2011', dayfirst=True)
Out[32]: datetime.datetime(2011, 12, 6, 0, 0)
```
pandas通常是用于處理成組日期的,不管這些日期是DataFrame的軸索引還是列。to_datetime方法可以解析多種不同的日期表示形式。對標準日期格式(如ISO8601)的解析非常快:
```python
In [33]: datestrs = ['2011-07-06 12:00:00', '2011-08-06 00:00:00']
In [34]: pd.to_datetime(datestrs)
Out[34]: DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00'], dtype='dat
etime64[ns]', freq=None)
```
它還可以處理缺失值(None、空字符串等):
```python
In [35]: idx = pd.to_datetime(datestrs + [None])
In [36]: idx
Out[36]: DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00', 'NaT'], dty
pe='datetime64[ns]', freq=None)
In [37]: idx[2]
Out[37]: NaT
In [38]: pd.isnull(idx)
Out[38]: array([False, False, True], dtype=bool)
```
NaT(Not a Time)是pandas中時間戳數據的null值。
>注意:dateutil.parser是一個實用但不完美的工具。比如說,它會把一些原本不是日期的字符串認作是日期(比如"42"會被解析為2042年的今天)。
datetime對象還有一些特定于當前環境(位于不同國家或使用不同語言的系統)的格式化選項。例如,德語或法語系統所用的月份簡寫就與英語系統所用的不同。表11-3進行了總結。
表11-3 特定于當前環境的日期格式

# 11.2 時間序列基礎
pandas最基本的時間序列類型就是以時間戳(通常以Python字符串或datatime對象表示)為索引的Series:
```python
In [39]: from datetime import datetime
In [40]: dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),
....: datetime(2011, 1, 7), datetime(2011, 1, 8),
....: datetime(2011, 1, 10), datetime(2011, 1, 12)]
In [41]: ts = pd.Series(np.random.randn(6), index=dates)
In [42]: ts
Out[42]:
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
```
這些datetime對象實際上是被放在一個DatetimeIndex中的:
```python
In [43]: ts.index
Out[43]:
DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08',
'2011-01-10', '2011-01-12'],
dtype='datetime64[ns]', freq=None)
```
跟其他Series一樣,不同索引的時間序列之間的算術運算會自動按日期對齊:
```python
In [44]: ts + ts[::2]
Out[44]:
2011-01-02 -0.409415
2011-01-05 NaN
2011-01-07 -1.038877
2011-01-08 NaN
2011-01-10 3.931561
2011-01-12 NaN
dtype: float64
```
ts[::2] 是每隔兩個取一個。
pandas用NumPy的datetime64數據類型以納秒形式存儲時間戳:
```python
In [45]: ts.index.dtype
Out[45]: dtype('<M8[ns]')
```
DatetimeIndex中的各個標量值是pandas的Timestamp對象:
```python
In [46]: stamp = ts.index[0]
In [47]: stamp
Out[47]: Timestamp('2011-01-02 00:00:00')
```
只要有需要,TimeStamp可以隨時自動轉換為datetime對象。此外,它還可以存儲頻率信息(如果有的話),且知道如何執行時區轉換以及其他操作。稍后將對此進行詳細講解。
## 索引、選取、子集構造
當你根據標簽索引選取數據時,時間序列和其它的pandas.Series很像:
```python
In [48]: stamp = ts.index[2]
In [49]: ts[stamp]
Out[49]: -0.51943871505673811
```
還有一種更為方便的用法:傳入一個可以被解釋為日期的字符串:
```python
In [50]: ts['1/10/2011']
Out[50]: 1.9657805725027142
In [51]: ts['20110110']
Out[51]: 1.9657805725027142
```
對于較長的時間序列,只需傳入“年”或“年月”即可輕松選取數據的切片:
```python
In [52]: longer_ts = pd.Series(np.random.randn(1000),
....: index=pd.date_range('1/1/2000', periods=1000))
In [53]: longer_ts
Out[53]:
2000-01-01 0.092908
2000-01-02 0.281746
2000-01-03 0.769023
2000-01-04 1.246435
2000-01-05 1.007189
2000-01-06 -1.296221
2000-01-07 0.274992
2000-01-08 0.228913
2000-01-09 1.352917
2000-01-10 0.886429
...
2002-09-17 -0.139298
2002-09-18 -1.159926
2002-09-19 0.618965
2002-09-20 1.373890
2002-09-21 -0.983505
2002-09-22 0.930944
2002-09-23 -0.811676
2002-09-24 -1.830156
2002-09-25 -0.138730
2002-09-26 0.334088
Freq: D, Length: 1000, dtype: float64
In [54]: longer_ts['2001']
Out[54]:
2001-01-01 1.599534
2001-01-02 0.474071
2001-01-03 0.151326
2001-01-04 -0.542173
2001-01-05 -0.475496
2001-01-06 0.106403
2001-01-07 -1.308228
2001-01-08 2.173185
2001-01-09 0.564561
2001-01-10 -0.190481
...
2001-12-22 0.000369
2001-12-23 0.900885
2001-12-24 -0.454869
2001-12-25 -0.864547
2001-12-26 1.129120
2001-12-27 0.057874
2001-12-28 -0.433739
2001-12-29 0.092698
2001-12-30 -1.397820
2001-12-31 1.457823
Freq: D, Length: 365, dtype: float64
```
這里,字符串“2001”被解釋成年,并根據它選取時間區間。指定月也同樣奏效:
```python
In [55]: longer_ts['2001-05']
Out[55]:
2001-05-01 -0.622547
2001-05-02 0.936289
2001-05-03 0.750018
2001-05-04 -0.056715
2001-05-05 2.300675
2001-05-06 0.569497
2001-05-07 1.489410
2001-05-08 1.264250
2001-05-09 -0.761837
2001-05-10 -0.331617
...
2001-05-22 0.503699
2001-05-23 -1.387874
2001-05-24 0.204851
2001-05-25 0.603705
2001-05-26 0.545680
2001-05-27 0.235477
2001-05-28 0.111835
2001-05-29 -1.251504
2001-05-30 -2.949343
2001-05-31 0.634634
Freq: D, Length: 31, dtype: float64
```
datetime對象也可以進行切片:
```python
In [56]: ts[datetime(2011, 1, 7):]
Out[56]:
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
```
由于大部分時間序列數據都是按照時間先后排序的,因此你也可以用不存在于該時間序列中的時間戳對其進行切片(即范圍查詢):
```python
In [57]: ts
Out[57]:
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
In [58]: ts['1/6/2011':'1/11/2011']
Out[58]:
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
dtype: float64
```
跟之前一樣,你可以傳入字符串日期、datetime或Timestamp。注意,這樣切片所產生的是原時間序列的視圖,跟NumPy數組的切片運算是一樣的。
這意味著,沒有數據被復制,對切片進行修改會反映到原始數據上。
此外,還有一個等價的實例方法也可以截取兩個日期之間TimeSeries:
```python
In [59]: ts.truncate(after='1/9/2011')
Out[59]:
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
dtype: float64
```
面這些操作對DataFrame也有效。例如,對DataFrame的行進行索引:
```python
In [60]: dates = pd.date_range('1/1/2000', periods=100, freq='W-WED')
In [61]: long_df = pd.DataFrame(np.random.randn(100, 4),
....: index=dates,
....: columns=['Colorado', 'Texas',
....: 'New York', 'Ohio'])
In [62]: long_df.loc['5-2001']
Out[62]:
Colorado Texas New York Ohio
2001-05-02 -0.006045 0.490094 -0.277186 -0.707213
2001-05-09 -0.560107 2.735527 0.927335 1.513906
2001-05-16 0.538600 1.273768 0.667876 -0.969206
2001-05-23 1.676091 -0.817649 0.050188 1.951312
2001-05-30 3.260383 0.963301 1.201206 -1.852001
```
## 帶有重復索引的時間序列
在某些應用場景中,可能會存在多個觀測數據落在同一個時間點上的情況。下面就是一個例子:
```python
In [63]: dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000',
....: '1/2/2000', '1/3/2000'])
In [64]: dup_ts = pd.Series(np.arange(5), index=dates)
In [65]: dup_ts
Out[65]:
2000-01-01 0
2000-01-02 1
2000-01-02 2
2000-01-02 3
2000-01-03 4
dtype: int64
```
通過檢查索引的is_unique屬性,我們就可以知道它是不是唯一的:
```python
In [66]: dup_ts.index.is_unique
Out[66]: False
```
對這個時間序列進行索引,要么產生標量值,要么產生切片,具體要看所選的時間點是否重復:
```python
In [67]: dup_ts['1/3/2000'] # not duplicated
Out[67]: 4
In [68]: dup_ts['1/2/2000'] # duplicated
Out[68]:
2000-01-02 1
2000-01-02 2
2000-01-02 3
dtype: int64
```
假設你想要對具有非唯一時間戳的數據進行聚合。一個辦法是使用groupby,并傳入level=0:
```python
In [69]: grouped = dup_ts.groupby(level=0)
In [70]: grouped.mean()
Out[70]:
2000-01-01 0
2000-01-02 2
2000-01-03 4
dtype: int64
In [71]: grouped.count()
Out[71]:
2000-01-01 1
2000-01-02 3
2000-01-03 1
dtype: int64
```
# 11.3 日期的范圍、頻率以及移動
pandas中的原生時間序列一般被認為是不規則的,也就是說,它們沒有固定的頻率。對于大部分應用程序而言,這是無所謂的。但是,它常常需要以某種相對固定的頻率進行分析,比如每日、每月、每15分鐘等(這樣自然會在時間序列中引入缺失值)。幸運的是,pandas有一整套標準時間序列頻率以及用于重采樣、頻率推斷、生成固定頻率日期范圍的工具。例如,我們可以將之前那個時間序列轉換為一個具有固定頻率(每日)的時間序列,只需調用resample即可:
```python
In [72]: ts
Out[72]:
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
In [73]: resampler = ts.resample('D')
```
字符串“D”是每天的意思。
頻率的轉換(或重采樣)是一個比較大的主題,稍后將專門用一節來進行討論(11.6小節)。這里,我將告訴你如何使用基本的頻率和它的倍數。
## 生成日期范圍
雖然我之前用的時候沒有明說,但你可能已經猜到pandas.date_range可用于根據指定的頻率生成指定長度的DatetimeIndex:
```python
In [74]: index = pd.date_range('2012-04-01', '2012-06-01')
In [75]: index
Out[75]:
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20',
'2012-04-21', '2012-04-22', '2012-04-23', '2012-04-24',
'2012-04-25', '2012-04-26', '2012-04-27', '2012-04-28',
'2012-04-29', '2012-04-30', '2012-05-01', '2012-05-02',
'2012-05-03', '2012-05-04', '2012-05-05', '2012-05-06',
'2012-05-07', '2012-05-08', '2012-05-09', '2012-05-10',
'2012-05-11', '2012-05-12', '2012-05-13', '2012-05-14',
'2012-05-15', '2012-05-16', '2012-05-17', '2012-05-18',
'2012-05-19', '2012-05-20', '2012-05-21', '2012-05-22',
'2012-05-23', '2012-05-24', '2012-05-25', '2012-05-26',
'2012-05-27', '2012-05-28', '2012-05-29', '2012-05-30',
'2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
```
默認情況下,date_range會產生按天計算的時間點。如果只傳入起始或結束日期,那就還得傳入一個表示一段時間的數字:
```python
In [76]: pd.date_range(start='2012-04-01', periods=20)
Out[76]:
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20'],
dtype='datetime64[ns]', freq='D')
In [77]: pd.date_range(end='2012-06-01', periods=20)
Out[77]:
DatetimeIndex(['2012-05-13', '2012-05-14', '2012-05-15', '2012-05-16',
'2012-05-17', '2012-05-18', '2012-05-19', '2012-05-20',
'2012-05-21', '2012-05-22', '2012-05-23', '2012-05-24',
'2012-05-25', '2012-05-26', '2012-05-27','2012-05-28',
'2012-05-29', '2012-05-30', '2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
```
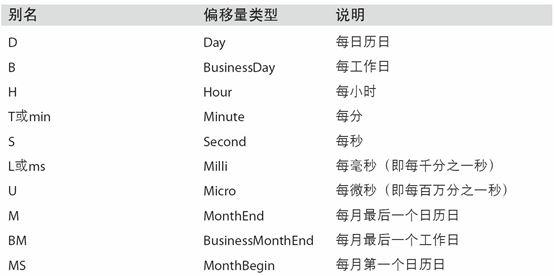
起始和結束日期定義了日期索引的嚴格邊界。例如,如果你想要生成一個由每月最后一個工作日組成的日期索引,可以傳入"BM"頻率(表示business end of month,表11-4是頻率列表),這樣就只會包含時間間隔內(或剛好在邊界上的)符合頻率要求的日期:
```python
In [78]: pd.date_range('2000-01-01', '2000-12-01', freq='BM')
Out[78]:
DatetimeIndex(['2000-01-31', '2000-02-29', '2000-03-31', '2000-04-28',
'2000-05-31', '2000-06-30', '2000-07-31', '2000-08-31',
'2000-09-29', '2000-10-31', '2000-11-30'],
dtype='datetime64[ns]', freq='BM')
```
表11-4 基本的時間序列頻率(不完整)



date_range默認會保留起始和結束時間戳的時間信息(如果有的話):
```python
In [79]: pd.date_range('2012-05-02 12:56:31', periods=5)
Out[79]:
DatetimeIndex(['2012-05-02 12:56:31', '2012-05-03 12:56:31',
'2012-05-04 12:56:31', '2012-05-05 12:56:31',
'2012-05-06 12:56:31'],
dtype='datetime64[ns]', freq='D')
```
有時,雖然起始和結束日期帶有時間信息,但你希望產生一組被規范化(normalize)到午夜的時間戳。normalize選項即可實現該功能:
```python
In [80]: pd.date_range('2012-05-02 12:56:31', periods=5, normalize=True)
Out[80]:
DatetimeIndex(['2012-05-02', '2012-05-03', '2012-05-04', '2012-05-05',
'2012-05-06'],
dtype='datetime64[ns]', freq='D')
```
## 頻率和日期偏移量
pandas中的頻率是由一個基礎頻率(base frequency)和一個乘數組成的。基礎頻率通常以一個字符串別名表示,比如"M"表示每月,"H"表示每小時。對于每個基礎頻率,都有一個被稱為日期偏移量(date offset)的對象與之對應。例如,按小時計算的頻率可以用Hour類表示:
```python
In [81]: from pandas.tseries.offsets import Hour, Minute
In [82]: hour = Hour()
In [83]: hour
Out[83]: <Hour>
```
傳入一個整數即可定義偏移量的倍數:
```python
In [84]: four_hours = Hour(4)
In [85]: four_hours
Out[85]: <4 * Hours>
```
一般來說,無需明確創建這樣的對象,只需使用諸如"H"或"4H"這樣的字符串別名即可。在基礎頻率前面放上一個整數即可創建倍數:
```python
In [86]: pd.date_range('2000-01-01', '2000-01-03 23:59', freq='4h')
Out[86]:
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 04:00:00',
'2000-01-01 08:00:00', '2000-01-01 12:00:00',
'2000-01-01 16:00:00', '2000-01-01 20:00:00',
'2000-01-02 00:00:00', '2000-01-02 04:00:00',
'2000-01-02 08:00:00', '2000-01-02 12:00:00',
'2000-01-02 16:00:00', '2000-01-02 20:00:00',
'2000-01-03 00:00:00', '2000-01-03 04:00:00',
'2000-01-03 08:00:00', '2000-01-03 12:00:00',
'2000-01-03 16:00:00', '2000-01-03 20:00:00'],
dtype='datetime64[ns]', freq='4H')
```
大部分偏移量對象都可通過加法進行連接:
```python
In [87]: Hour(2) + Minute(30)
Out[87]: <150 * Minutes>
```
同理,你也可以傳入頻率字符串(如"2h30min"),這種字符串可以被高效地解析為等效的表達式:
```python
In [88]: pd.date_range('2000-01-01', periods=10, freq='1h30min')
Out[88]:
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 01:30:00',
'2000-01-01 03:00:00', '2000-01-01 04:30:00',
'2000-01-01 06:00:00', '2000-01-01 07:30:00',
'2000-01-01 09:00:00', '2000-01-01 10:30:00',
'2000-01-01 12:00:00', '2000-01-01 13:30:00'],
dtype='datetime64[ns]', freq='90T')
```
有些頻率所描述的時間點并不是均勻分隔的。例如,"M"(日歷月末)和"BM"(每月最后一個工作日)就取決于每月的天數,對于后者,還要考慮月末是不是周末。由于沒有更好的術語,我將這些稱為錨點偏移量(anchored offset)。
表11-4列出了pandas中的頻率代碼和日期偏移量類。
>筆記:用戶可以根據實際需求自定義一些頻率類以便提供pandas所沒有的日期邏輯,但具體的細節超出了本書的范圍。
表11-4 時間序列的基礎頻率


## WOM日期
WOM(Week Of Month)是一種非常實用的頻率類,它以WOM開頭。它使你能獲得諸如“每月第3個星期五”之類的日期:
```python
In [89]: rng = pd.date_range('2012-01-01', '2012-09-01', freq='WOM-3FRI')
In [90]: list(rng)
Out[90]:
[Timestamp('2012-01-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-02-17 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-03-16 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-04-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-05-18 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-06-15 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-07-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-08-17 00:00:00', freq='WOM-3FRI')]
```
## 移動(超前和滯后)數據
移動(shifting)指的是沿著時間軸將數據前移或后移。Series和DataFrame都有一個shift方法用于執行單純的前移或后移操作,保持索引不變:
```python
In [91]: ts = pd.Series(np.random.randn(4),
....: index=pd.date_range('1/1/2000', periods=4, freq='M'))
In [92]: ts
Out[92]:
2000-01-31 -0.066748
2000-02-29 0.838639
2000-03-31 -0.117388
2000-04-30 -0.517795
Freq: M, dtype: float64
In [93]: ts.shift(2)
Out[93]:
2000-01-31 NaN
2000-02-29 NaN
2000-03-31 -0.066748
2000-04-30 0.838639
Freq: M, dtype: float64
In [94]: ts.shift(-2)
Out[94]:
2000-01-31 -0.117388
2000-02-29 -0.517795
2000-03-31 NaN
2000-04-30 NaN
Freq: M, dtype: float64
```
當我們這樣進行移動時,就會在時間序列的前面或后面產生缺失數據。
shift通常用于計算一個時間序列或多個時間序列(如DataFrame的列)中的百分比變化。可以這樣表達:
```python
ts / ts.shift(1) - 1
```
由于單純的移位操作不會修改索引,所以部分數據會被丟棄。因此,如果頻率已知,則可以將其傳給shift以便實現對時間戳進行位移而不是對數據進行簡單位移:
```python
In [95]: ts.shift(2, freq='M')
Out[95]:
2000-03-31 -0.066748
2000-04-30 0.838639
2000-05-31 -0.117388
2000-06-30 -0.517795
Freq: M, dtype: float64
```
這里還可以使用其他頻率,于是你就能非常靈活地對數據進行超前和滯后處理了:
```python
In [96]: ts.shift(3, freq='D')
Out[96]:
2000-02-03 -0.066748
2000-03-03 0.838639
2000-04-03 -0.117388
2000-05-03 -0.517795
dtype: float64
In [97]: ts.shift(1, freq='90T')
Out[97]:
2000-01-31 01:30:00 -0.066748
2000-02-29 01:30:00 0.838639
2000-03-31 01:30:00 -0.117388
2000-04-30 01:30:00 -0.517795
Freq: M, dtype: float64
```
## 通過偏移量對日期進行位移
pandas的日期偏移量還可以用在datetime或Timestamp對象上:
```python
In [98]: from pandas.tseries.offsets import Day, MonthEnd
In [99]: now = datetime(2011, 11, 17)
In [100]: now + 3 * Day()
Out[100]: Timestamp('2011-11-20 00:00:00')
```
如果加的是錨點偏移量(比如MonthEnd),第一次增量會將原日期向前滾動到符合頻率規則的下一個日期:
```python
In [101]: now + MonthEnd()
Out[101]: Timestamp('2011-11-30 00:00:00')
In [102]: now + MonthEnd(2)
Out[102]: Timestamp('2011-12-31 00:00:00')
```
通過錨點偏移量的rollforward和rollback方法,可明確地將日期向前或向后“滾動”:
```python
In [103]: offset = MonthEnd()
In [104]: offset.rollforward(now)
Out[104]: Timestamp('2011-11-30 00:00:00')
In [105]: offset.rollback(now)
Out[105]: Timestamp('2011-10-31 00:00:00')
```
日期偏移量還有一個巧妙的用法,即結合groupby使用這兩個“滾動”方法:
```python
In [106]: ts = pd.Series(np.random.randn(20),
.....: index=pd.date_range('1/15/2000', periods=20, freq='4d'))
In [107]: ts
Out[107]:
2000-01-15 -0.116696
2000-01-19 2.389645
2000-01-23 -0.932454
2000-01-27 -0.229331
2000-01-31 -1.140330
2000-02-04 0.439920
2000-02-08 -0.823758
2000-02-12 -0.520930
2000-02-16 0.350282
2000-02-20 0.204395
2000-02-24 0.133445
2000-02-28 0.327905
2000-03-03 0.072153
2000-03-07 0.131678
2000-03-11 -1.297459
2000-03-15 0.997747
2000-03-19 0.870955
2000-03-23 -0.991253
2000-03-27 0.151699
2000-03-31 1.266151
Freq: 4D, dtype: float64
In [108]: ts.groupby(offset.rollforward).mean()
Out[108]:
2000-01-31 -0.005833
2000-02-29 0.015894
2000-03-31 0.150209
dtype: float64
```
當然,更簡單、更快速地實現該功能的辦法是使用resample(11.6小節將對此進行詳細介紹):
```python
In [109]: ts.resample('M').mean()
Out[109]:
2000-01-31 -0.005833
2000-02-29 0.015894
2000-03-31 0.150209
Freq: M, dtype: float64
```
# 11.4 時區處理
時間序列處理工作中最讓人不爽的就是對時區的處理。許多人都選擇以協調世界時(UTC,它是格林尼治標準時間(Greenwich Mean Time)的接替者,目前已經是國際標準了)來處理時間序列。時區是以UTC偏移量的形式表示的。例如,夏令時期間,紐約比UTC慢4小時,而在全年其他時間則比UTC慢5小時。
在Python中,時區信息來自第三方庫pytz,它使Python可以使用Olson數據庫(匯編了世界時區信息)。這對歷史數據非常重要,這是因為由于各地政府的各種突發奇想,夏令時轉變日期(甚至UTC偏移量)已經發生過多次改變了。就拿美國來說,DST轉變時間自1900年以來就改變過多次!
有關pytz庫的更多信息,請查閱其文檔。就本書而言,由于pandas包裝了pytz的功能,因此你可以不用記憶其API,只要記得時區的名稱即可。時區名可以在shell中看到,也可以通過文檔查看:
```python
In [110]: import pytz
In [111]: pytz.common_timezones[-5:]
Out[111]: ['US/Eastern', 'US/Hawaii', 'US/Mountain', 'US/Pacific', 'UTC']
```
要從pytz中獲取時區對象,使用pytz.timezone即可:
```python
In [112]: tz = pytz.timezone('America/New_York')
In [113]: tz
Out[113]: <DstTzInfo 'America/New_York' LMT-1 day, 19:04:00 STD>
```
pandas中的方法既可以接受時區名也可以接受這些對象。
# 時區本地化和轉換
默認情況下,pandas中的時間序列是單純(naive)的時區。看看下面這個時間序列:
```python
In [114]: rng = pd.date_range('3/9/2012 9:30', periods=6, freq='D')
In [115]: ts = pd.Series(np.random.randn(len(rng)), index=rng)
In [116]: ts
Out[116]:
2012-03-09 09:30:00 -0.202469
2012-03-10 09:30:00 0.050718
2012-03-11 09:30:00 0.639869
2012-03-12 09:30:00 0.597594
2012-03-13 09:30:00 -0.797246
2012-03-14 09:30:00 0.472879
Freq: D, dtype: float64
```
其索引的tz字段為None:
```python
In [117]: print(ts.index.tz)
None
```
可以用時區集生成日期范圍:
```python
In [118]: pd.date_range('3/9/2012 9:30', periods=10, freq='D', tz='UTC')
Out[118]:
DatetimeIndex(['2012-03-09 09:30:00+00:00', '2012-03-10 09:30:00+00:00',
'2012-03-11 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00',
'2012-03-15 09:30:00+00:00', '2012-03-16 09:30:00+00:00',
'2012-03-17 09:30:00+00:00', '2012-03-18 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')
```
從單純到本地化的轉換是通過tz_localize方法處理的:
```python
In [119]: ts
Out[119]:
2012-03-09 09:30:00 -0.202469
2012-03-10 09:30:00 0.050718
2012-03-11 09:30:00 0.639869
2012-03-12 09:30:00 0.597594
2012-03-13 09:30:00 -0.797246
2012-03-14 09:30:00 0.472879
Freq: D, dtype: float64
In [120]: ts_utc = ts.tz_localize('UTC')
In [121]: ts_utc
Out[121]:
2012-03-09 09:30:00+00:00 -0.202469
2012-03-10 09:30:00+00:00 0.050718
2012-03-11 09:30:00+00:00 0.639869
2012-03-12 09:30:00+00:00 0.597594
2012-03-13 09:30:00+00:00 -0.797246
2012-03-14 09:30:00+00:00 0.472879
Freq: D, dtype: float64
In [122]: ts_utc.index
Out[122]:
DatetimeIndex(['2012-03-09 09:30:00+00:00', '2012-03-10 09:30:00+00:00',
'2012-03-11 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')
```
一旦時間序列被本地化到某個特定時區,就可以用tz_convert將其轉換到別的時區了:
```python
In [123]: ts_utc.tz_convert('America/New_York')
Out[123]:
2012-03-09 04:30:00-05:00 -0.202469
2012-03-10 04:30:00-05:00 0.050718
2012-03-11 05:30:00-04:00 0.639869
2012-03-12 05:30:00-04:00 0.597594
2012-03-13 05:30:00-04:00 -0.797246
2012-03-14 05:30:00-04:00 0.472879
Freq: D, dtype: float64
```
對于上面這種時間序列(它跨越了美國東部時區的夏令時轉變期),我們可以將其本地化到EST,然后轉換為UTC或柏林時間:
```python
In [124]: ts_eastern = ts.tz_localize('America/New_York')
In [125]: ts_eastern.tz_convert('UTC')
Out[125]:
2012-03-09 14:30:00+00:00 -0.202469
2012-03-10 14:30:00+00:00 0.050718
2012-03-11 13:30:00+00:00 0.639869
2012-03-12 13:30:00+00:00 0.597594
2012-03-13 13:30:00+00:00 -0.797246
2012-03-14 13:30:00+00:00 0.472879
Freq: D, dtype: float64
In [126]: ts_eastern.tz_convert('Europe/Berlin')
Out[126]:
2012-03-09 15:30:00+01:00 -0.202469
2012-03-10 15:30:00+01:00 0.050718
2012-03-11 14:30:00+01:00 0.639869
2012-03-12 14:30:00+01:00 0.597594
2012-03-13 14:30:00+01:00 -0.797246
2012-03-14 14:30:00+01:00 0.472879
Freq: D, dtype: float64
```
tz_localize和tz_convert也是DatetimeIndex的實例方法:
```python
In [127]: ts.index.tz_localize('Asia/Shanghai')
Out[127]:
DatetimeIndex(['2012-03-09 09:30:00+08:00', '2012-03-10 09:30:00+08:00',
'2012-03-11 09:30:00+08:00', '2012-03-12 09:30:00+08:00',
'2012-03-13 09:30:00+08:00', '2012-03-14 09:30:00+08:00'],
dtype='datetime64[ns, Asia/Shanghai]', freq='D')
```
>注意:對單純時間戳的本地化操作還會檢查夏令時轉變期附近容易混淆或不存在的時間。
## 操作時區意識型Timestamp對象
跟時間序列和日期范圍差不多,獨立的Timestamp對象也能被從單純型(naive)本地化為時區意識型(time zone-aware),并從一個時區轉換到另一個時區:
```python
In [128]: stamp = pd.Timestamp('2011-03-12 04:00')
In [129]: stamp_utc = stamp.tz_localize('utc')
In [130]: stamp_utc.tz_convert('America/New_York')
Out[130]: Timestamp('2011-03-11 23:00:00-0500', tz='America/New_York')
```
在創建Timestamp時,還可以傳入一個時區信息:
```python
In [131]: stamp_moscow = pd.Timestamp('2011-03-12 04:00', tz='Europe/Moscow')
In [132]: stamp_moscow
Out[132]: Timestamp('2011-03-12 04:00:00+0300', tz='Europe/Moscow')
```
時區意識型Timestamp對象在內部保存了一個UTC時間戳值(自UNIX紀元(1970年1月1日)算起的納秒數)。這個UTC值在時區轉換過程中是不會發生變化的:
```python
In [133]: stamp_utc.value
Out[133]: 1299902400000000000
In [134]: stamp_utc.tz_convert('America/New_York').value
Out[134]: 1299902400000000000
```
當使用pandas的DateOffset對象執行時間算術運算時,運算過程會自動關注是否存在夏令時轉變期。這里,我們創建了在DST轉變之前的時間戳。首先,來看夏令時轉變前的30分鐘:
```python
In [135]: from pandas.tseries.offsets import Hour
In [136]: stamp = pd.Timestamp('2012-03-12 01:30', tz='US/Eastern')
In [137]: stamp
Out[137]: Timestamp('2012-03-12 01:30:00-0400', tz='US/Eastern')
In [138]: stamp + Hour()
Out[138]: Timestamp('2012-03-12 02:30:00-0400', tz='US/Eastern')
```
然后,夏令時轉變前90分鐘:
```python
In [139]: stamp = pd.Timestamp('2012-11-04 00:30', tz='US/Eastern')
In [140]: stamp
Out[140]: Timestamp('2012-11-04 00:30:00-0400', tz='US/Eastern')
In [141]: stamp + 2 * Hour()
Out[141]: Timestamp('2012-11-04 01:30:00-0500', tz='US/Eastern')
```
## 不同時區之間的運算
如果兩個時間序列的時區不同,在將它們合并到一起時,最終結果就會是UTC。由于時間戳其實是以UTC存儲的,所以這是一個很簡單的運算,并不需要發生任何轉換:
```python
In [142]: rng = pd.date_range('3/7/2012 9:30', periods=10, freq='B')
In [143]: ts = pd.Series(np.random.randn(len(rng)), index=rng)
In [144]: ts
Out[144]:
2012-03-07 09:30:00 0.522356
2012-03-08 09:30:00 -0.546348
2012-03-09 09:30:00 -0.733537
2012-03-12 09:30:00 1.302736
2012-03-13 09:30:00 0.022199
2012-03-14 09:30:00 0.364287
2012-03-15 09:30:00 -0.922839
2012-03-16 09:30:00 0.312656
2012-03-19 09:30:00 -1.128497
2012-03-20 09:30:00 -0.333488
Freq: B, dtype: float64
In [145]: ts1 = ts[:7].tz_localize('Europe/London')
In [146]: ts2 = ts1[2:].tz_convert('Europe/Moscow')
In [147]: result = ts1 + ts2
In [148]: result.index
Out[148]:
DatetimeIndex(['2012-03-07 09:30:00+00:00', '2012-03-08 09:30:00+00:00',
'2012-03-09 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00',
'2012-03-15 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='B')
```
# 11.5 時期及其算術運算
時期(period)表示的是時間區間,比如數日、數月、數季、數年等。Period類所表示的就是這種數據類型,其構造函數需要用到一個字符串或整數,以及表11-4中的頻率:
```python
In [149]: p = pd.Period(2007, freq='A-DEC')
In [150]: p
Out[150]: Period('2007', 'A-DEC')
```
這里,這個Period對象表示的是從2007年1月1日到2007年12月31日之間的整段時間。只需對Period對象加上或減去一個整數即可達到根據其頻率進行位移的效果:
```python
In [151]: p + 5
Out[151]: Period('2012', 'A-DEC')
In [152]: p - 2
Out[152]: Period('2005', 'A-DEC')
```
如果兩個Period對象擁有相同的頻率,則它們的差就是它們之間的單位數量:
```python
In [153]: pd.Period('2014', freq='A-DEC') - p
Out[153]: 7
```
period_range函數可用于創建規則的時期范圍:
```python
In [154]: rng = pd.period_range('2000-01-01', '2000-06-30', freq='M')
In [155]: rng
Out[155]: PeriodIndex(['2000-01', '2000-02', '2000-03', '2000-04', '2000-05', '20
00-06'], dtype='period[M]', freq='M')
```
PeriodIndex類保存了一組Period,它可以在任何pandas數據結構中被用作軸索引:
```python
In [156]: pd.Series(np.random.randn(6), index=rng)
Out[156]:
2000-01 -0.514551
2000-02 -0.559782
2000-03 -0.783408
2000-04 -1.797685
2000-05 -0.172670
2000-06 0.680215
Freq: M, dtype: float64
```
如果你有一個字符串數組,你也可以使用PeriodIndex類:
```python
In [157]: values = ['2001Q3', '2002Q2', '2003Q1']
In [158]: index = pd.PeriodIndex(values, freq='Q-DEC')
In [159]: index
Out[159]: PeriodIndex(['2001Q3', '2002Q2', '2003Q1'], dtype='period[Q-DEC]', freq
='Q-DEC')
```
## 時期的頻率轉換
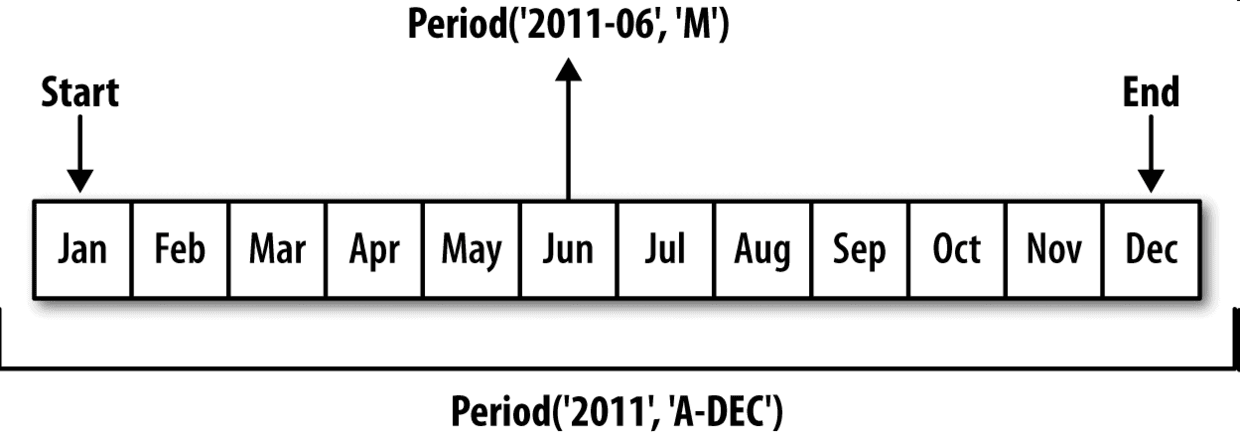
Period和PeriodIndex對象都可以通過其asfreq方法被轉換成別的頻率。假設我們有一個年度時期,希望將其轉換為當年年初或年末的一個月度時期。該任務非常簡單:
```python
In [160]: p = pd.Period('2007', freq='A-DEC')
In [161]: p
Out[161]: Period('2007', 'A-DEC')
In [162]: p.asfreq('M', how='start')
Out[162]: Period('2007-01', 'M')
In [163]: p.asfreq('M', how='end')
Out[163]: Period('2007-12', 'M')
```
你可以將Period('2007','A-DEC')看做一個被劃分為多個月度時期的時間段中的游標。圖11-1對此進行了說明。對于一個不以12月結束的財政年度,月度子時期的歸屬情況就不一樣了:
```python
In [164]: p = pd.Period('2007', freq='A-JUN')
In [165]: p
Out[165]: Period('2007', 'A-JUN')
In [166]: p.asfreq('M', 'start')
Out[166]: Period('2006-07', 'M')
In [167]: p.asfreq('M', 'end')
Out[167]: Period('2007-06', 'M')
```
在將高頻率轉換為低頻率時,超時期(superperiod)是由子時期(subperiod)所屬的位置決定的。例如,在A-JUN頻率中,月份“2007年8月”實際上是屬于周期“2008年”的:
```python
In [168]: p = pd.Period('Aug-2007', 'M')
In [169]: p.asfreq('A-JUN')
Out[169]: Period('2008', 'A-JUN')
```
完整的PeriodIndex或TimeSeries的頻率轉換方式也是如此:
```python
In [170]: rng = pd.period_range('2006', '2009', freq='A-DEC')
In [171]: ts = pd.Series(np.random.randn(len(rng)), index=rng)
In [172]: ts
Out[172]:
2006 1.607578
2007 0.200381
2008 -0.834068
2009 -0.302988
Freq: A-DEC, dtype: float64
In [173]: ts.asfreq('M', how='start')
Out[173]:
2006-01 1.607578
2007-01 0.200381
2008-01 -0.834068
2009-01 -0.302988
Freq: M, dtype: float64
```
這里,根據年度時期的第一個月,每年的時期被取代為每月的時期。如果我們想要每年的最后一個工作日,我們可以使用“B”頻率,并指明想要該時期的末尾:
```python
In [174]: ts.asfreq('B', how='end')
Out[174]:
2006-12-29 1.607578
2007-12-31 0.200381
2008-12-31 -0.834068
2009-12-31 -0.302988
Freq: B, dtype: float64
```
## 按季度計算的時期頻率
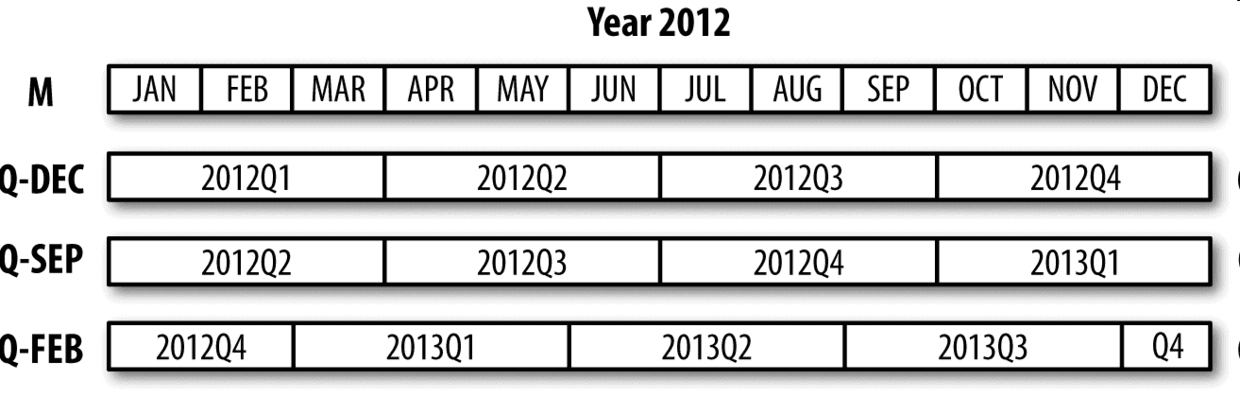
季度型數據在會計、金融等領域中很常見。許多季度型數據都會涉及“財年末”的概念,通常是一年12個月中某月的最后一個日歷日或工作日。就這一點來說,時期"2012Q4"根據財年末的不同會有不同的含義。pandas支持12種可能的季度型頻率,即Q-JAN到Q-DEC:
```python
In [175]: p = pd.Period('2012Q4', freq='Q-JAN')
In [176]: p
Out[176]: Period('2012Q4', 'Q-JAN')
```
在以1月結束的財年中,2012Q4是從11月到1月(將其轉換為日型頻率就明白了)。圖11-2對此進行了說明:
```python
In [177]: p.asfreq('D', 'start')
Out[177]: Period('2011-11-01', 'D')
In [178]: p.asfreq('D', 'end')
Out[178]: Period('2012-01-31', 'D')
```
因此,Period之間的算術運算會非常簡單。例如,要獲取該季度倒數第二個工作日下午4點的時間戳,你可以這樣:
```python
In [179]: p4pm = (p.asfreq('B', 'e') - 1).asfreq('T', 's') + 16 * 60
In [180]: p4pm
Out[180]: Period('2012-01-30 16:00', 'T')
In [181]: p4pm.to_timestamp()
Out[181]: Timestamp('2012-01-30 16:00:00')
```
period_range可用于生成季度型范圍。季度型范圍的算術運算也跟上面是一樣的:
```python
In [182]: rng = pd.period_range('2011Q3', '2012Q4', freq='Q-JAN')
In [183]: ts = pd.Series(np.arange(len(rng)), index=rng)
In [184]: ts
Out[184]:
2011Q3 0
2011Q4 1
2012Q1 2
2012Q2 3
2012Q3 4
2012Q4 5
Freq: Q-JAN, dtype: int64
In [185]: new_rng = (rng.asfreq('B', 'e') - 1).asfreq('T', 's') + 16 * 60
In [186]: ts.index = new_rng.to_timestamp()
In [187]: ts
Out[187]:
2010-10-28 16:00:00 0
2011-01-28 16:00:00 1
2011-04-28 16:00:00 2
2011-07-28 16:00:00 3
2011-10-28 16:00:00 4
2012-01-30 16:00:00 5
dtype: int64
```
## 將Timestamp轉換為Period(及其反向過程)
通過使用to_period方法,可以將由時間戳索引的Series和DataFrame對象轉換為以時期索引:
```python
In [188]: rng = pd.date_range('2000-01-01', periods=3, freq='M')
In [189]: ts = pd.Series(np.random.randn(3), index=rng)
In [190]: ts
Out[190]:
2000-01-31 1.663261
2000-02-29 -0.996206
2000-03-31 1.521760
Freq: M, dtype: float64
In [191]: pts = ts.to_period()
In [192]: pts
Out[192]:
2000-01 1.663261
2000-02 -0.996206
2000-03 1.521760
Freq: M, dtype: float64
```
由于時期指的是非重疊時間區間,因此對于給定的頻率,一個時間戳只能屬于一個時期。新PeriodIndex的頻率默認是從時間戳推斷而來的,你也可以指定任何別的頻率。結果中允許存在重復時期:
```python
In [193]: rng = pd.date_range('1/29/2000', periods=6, freq='D')
In [194]: ts2 = pd.Series(np.random.randn(6), index=rng)
In [195]: ts2
Out[195]:
2000-01-29 0.244175
2000-01-30 0.423331
2000-01-31 -0.654040
2000-02-01 2.089154
2000-02-02 -0.060220
2000-02-03 -0.167933
Freq: D, dtype: float64
In [196]: ts2.to_period('M')
Out[196]:
2000-01 0.244175
2000-01 0.423331
2000-01 -0.654040
2000-02 2.089154
2000-02 -0.060220
2000-02 -0.167933
Freq: M, dtype: float64
```
要轉換回時間戳,使用to_timestamp即可:
```python
In [197]: pts = ts2.to_period()
In [198]: pts
Out[198]:
2000-01-29 0.244175
2000-01-30 0.423331
2000-01-31 -0.654040
2000-02-01 2.089154
2000-02-02 -0.060220
2000-02-03 -0.167933
Freq: D, dtype: float64
In [199]: pts.to_timestamp(how='end')
Out[199]:
2000-01-29 0.244175
2000-01-30 0.423331
2000-01-31 -0.654040
2000-02-01 2.089154
2000-02-02 -0.060220
2000-02-03 -0.167933
Freq: D, dtype: float64
```
## 通過數組創建PeriodIndex
固定頻率的數據集通常會將時間信息分開存放在多個列中。例如,在下面這個宏觀經濟數據集中,年度和季度就分別存放在不同的列中:
```python
In [200]: data = pd.read_csv('examples/macrodata.csv')
In [201]: data.head(5)
Out[201]:
year quarter realgdp realcons realinv realgovt realdpi cpi \
0 1959.0 1.0 2710.349 1707.4 286.898 470.045 1886.9 28.98
1 1959.0 2.0 2778.801 1733.7 310.859 481.301 1919.7 29.15
2 1959.0 3.0 2775.488 1751.8 289.226 491.260 1916.4 29.35
3 1959.0 4.0 2785.204 1753.7 299.356 484.052 1931.3 29.37
4 1960.0 1.0 2847.699 1770.5 331.722 462.199 1955.5 29.54
m1 tbilrate unemp pop infl realint
0 139.7 2.82 5.8 177.146 0.00 0.00
1 141.7 3.08 5.1 177.830 2.34 0.74
2 140.5 3.82 5.3 178.657 2.74 1.09
3 140.0 4.33 5.6 179.386 0.27 4.06
4 139.6 3.50 5.2 180.007 2.31 1.19
In [202]: data.year
Out[202]:
0 1959.0
1 1959.0
2 1959.0
3 1959.0
4 1960.0
5 1960.0
6 1960.0
7 1960.0
8 1961.0
9 1961.0
...
193 2007.0
194 2007.0
195 2007.0
196 2008.0
197 2008.0
198 2008.0
199 2008.0
200 2009.0
201 2009.0
202 2009.0
Name: year, Length: 203, dtype: float64
In [203]: data.quarter
Out[203]:
0 1.0
1 2.0
2 3.0
3 4.0
4 1.0
5 2.0
6 3.0
7 4.0
8 1.0
9 2.0
...
193 2.0
194 3.0
195 4.0
196 1.0
197 2.0
198 3.0
199 4.0
200 1.0
201 2.0
202 3.0
Name: quarter, Length: 203, dtype: float64
```
通過將這些數組以及一個頻率傳入PeriodIndex,就可以將它們合并成DataFrame的一個索引:
```python
In [204]: index = pd.PeriodIndex(year=data.year, quarter=data.quarter,
.....: freq='Q-DEC')
In [205]: index
Out[205]:
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
'1960Q3', '1960Q4', '1961Q1', '1961Q2',
...
'2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
'2008Q4', '2009Q1', '2009Q2', '2009Q3'],
dtype='period[Q-DEC]', length=203, freq='Q-DEC')
In [206]: data.index = index
In [207]: data.infl
Out[207]:
1959Q1 0.00
1959Q2 2.34
1959Q3 2.74
1959Q4 0.27
1960Q1 2.31
1960Q2 0.14
1960Q3 2.70
1960Q4 1.21
1961Q1 -0.40
1961Q2 1.47
...
2007Q2 2.75
2007Q3 3.45
2007Q4 6.38
2008Q1 2.82
2008Q2 8.53
2008Q3 -3.16
2008Q4 -8.79
2009Q1 0.94
2009Q2 3.37
2009Q3 3.56
Freq: Q-DEC, Name: infl, Length: 203, dtype: float64
```
# 11.6 重采樣及頻率轉換
重采樣(resampling)指的是將時間序列從一個頻率轉換到另一個頻率的處理過程。將高頻率數據聚合到低頻率稱為降采樣(downsampling),而將低頻率數據轉換到高頻率則稱為升采樣(upsampling)。并不是所有的重采樣都能被劃分到這兩個大類中。例如,將W-WED(每周三)轉換為W-FRI既不是降采樣也不是升采樣。
pandas對象都帶有一個resample方法,它是各種頻率轉換工作的主力函數。resample有一個類似于groupby的API,調用resample可以分組數據,然后會調用一個聚合函數:
```python
In [208]: rng = pd.date_range('2000-01-01', periods=100, freq='D')
In [209]: ts = pd.Series(np.random.randn(len(rng)), index=rng)
In [210]: ts
Out[210]:
2000-01-01 0.631634
2000-01-02 -1.594313
2000-01-03 -1.519937
2000-01-04 1.108752
2000-01-05 1.255853
2000-01-06 -0.024330
2000-01-07 -2.047939
2000-01-08 -0.272657
2000-01-09 -1.692615
2000-01-10 1.423830
...
2000-03-31 -0.007852
2000-04-01 -1.638806
2000-04-02 1.401227
2000-04-03 1.758539
2000-04-04 0.628932
2000-04-05 -0.423776
2000-04-06 0.789740
2000-04-07 0.937568
2000-04-08 -2.253294
2000-04-09 -1.772919
Freq: D, Length: 100, dtype: float64
In [211]: ts.resample('M').mean()
Out[211]:
2000-01-31 -0.165893
2000-02-29 0.078606
2000-03-31 0.223811
2000-04-30 -0.063643
Freq: M, dtype: float64
In [212]: ts.resample('M', kind='period').mean()
Out[212]:
2000-01 -0.165893
2000-02 0.078606
2000-03 0.223811
2000-04 -0.063643
Freq: M, dtype: float64
```
resample是一個靈活高效的方法,可用于處理非常大的時間序列。我將通過一系列的示例說明其用法。表11-5總結它的一些選項。
表11-5 resample方法的參數
## 降采樣
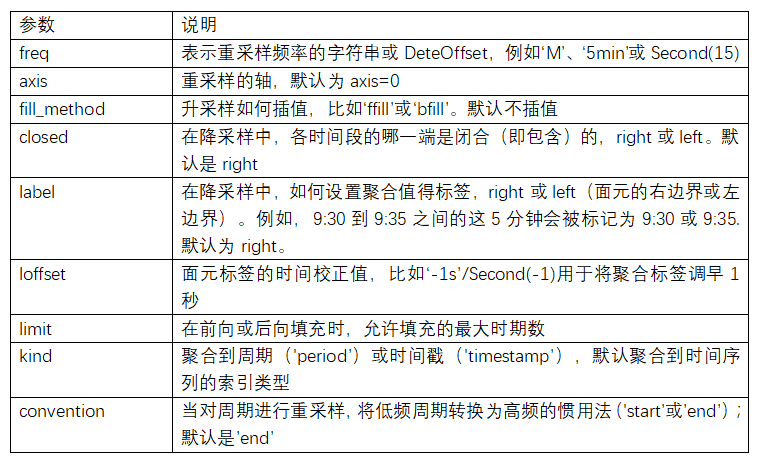
將數據聚合到規律的低頻率是一件非常普通的時間序列處理任務。待聚合的數據不必擁有固定的頻率,期望的頻率會自動定義聚合的面元邊界,這些面元用于將時間序列拆分為多個片段。例如,要轉換到月度頻率('M'或'BM'),數據需要被劃分到多個單月時間段中。各時間段都是半開放的。一個數據點只能屬于一個時間段,所有時間段的并集必須能組成整個時間幀。在用resample對數據進行降采樣時,需要考慮兩樣東西:
- 各區間哪邊是閉合的。
- 如何標記各個聚合面元,用區間的開頭還是末尾。
為了說明,我們來看一些“1分鐘”數據:
```python
In [213]: rng = pd.date_range('2000-01-01', periods=12, freq='T')
In [214]: ts = pd.Series(np.arange(12), index=rng)
In [215]: ts
Out[215]:
2000-01-01 00:00:00 0
2000-01-01 00:01:00 1
2000-01-01 00:02:00 2
2000-01-01 00:03:00 3
2000-01-01 00:04:00 4
2000-01-01 00:05:00 5
2000-01-01 00:06:00 6
2000-01-01 00:07:00 7
2000-01-01 00:08:00 8
2000-01-01 00:09:00 9
2000-01-01 00:10:00 10
2000-01-01 00:11:00 11
Freq: T, dtype: int64
```
假設你想要通過求和的方式將這些數據聚合到“5分鐘”塊中:
```python
In [216]: ts.resample('5min', closed='right').sum()
Out[216]:
1999-12-31 23:55:00 0
2000-01-01 00:00:00 15
2000-01-01 00:05:00 40
2000-01-01 00:10:00 11
Freq: 5T, dtype: int64
```
傳入的頻率將會以“5分鐘”的增量定義面元邊界。默認情況下,面元的右邊界是包含的,因此00:00到00:05的區間中是包含00:05的。傳入closed='left'會讓區間以左邊界閉合:
```python
In [217]: ts.resample('5min', closed='right').sum()
Out[217]:
1999-12-31 23:55:00 0
2000-01-01 00:00:00 15
2000-01-01 00:05:00 40
2000-01-01 00:10:00 11
Freq: 5T, dtype: int64
```
如你所見,最終的時間序列是以各面元右邊界的時間戳進行標記的。傳入label='right'即可用面元的郵編界對其進行標記:
```python
In [218]: ts.resample('5min', closed='right', label='right').sum()
Out[218]:
2000-01-01 00:00:00 0
2000-01-01 00:05:00 15
2000-01-01 00:10:00 40
2000-01-01 00:15:00 11
Freq: 5T, dtype: int64
```
圖11-3說明了“1分鐘”數據被轉換為“5分鐘”數據的處理過程。
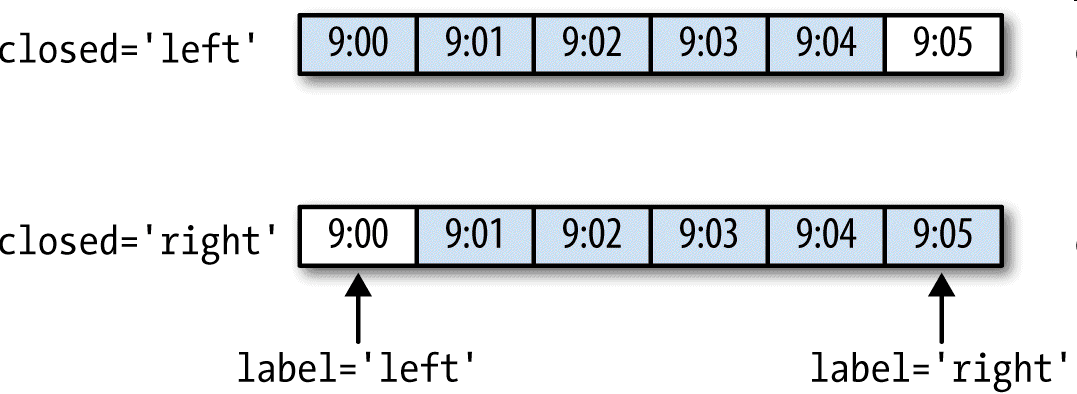
最后,你可能希望對結果索引做一些位移,比如從右邊界減去一秒以便更容易明白該時間戳到底表示的是哪個區間。只需通過loffset設置一個字符串或日期偏移量即可實現這個目的:
```python
In [219]: ts.resample('5min', closed='right',
.....: label='right', loffset='-1s').sum()
Out[219]:
1999-12-31 23:59:59 0
2000-01-01 00:04:59 15
In [219]: ts.resample('5min', closed='right',
.....: label='right', loffset='-1s').sum()
Out[219]:
1999-12-31 23:59:59 0
2000-01-01 00:04:59 15
```
此外,也可以通過調用結果對象的shift方法來實現該目的,這樣就不需要設置loffset了。
##OHLC重采樣
金融領域中有一種無所不在的時間序列聚合方式,即計算各面元的四個值:第一個值(open,開盤)、最后一個值(close,收盤)、最大值(high,最高)以及最小值(low,最低)。傳入how='ohlc'即可得到一個含有這四種聚合值的DataFrame。整個過程很高效,只需一次掃描即可計算出結果:
```python
In [220]: ts.resample('5min').ohlc()
Out[220]:
open high low close
2000-01-01 00:00:00 0 4 0 4
2000-01-01 00:05:00 5 9 5 9
2000-01-01 00:10:00 10 11 10 11
```
##升采樣和插值
在將數據從低頻率轉換到高頻率時,就不需要聚合了。我們來看一個帶有一些周型數據的DataFrame:
```python
In [221]: frame = pd.DataFrame(np.random.randn(2, 4),
.....: index=pd.date_range('1/1/2000', periods=2,
.....: freq='W-WED'),
.....: columns=['Colorado', 'Texas', 'New York', 'Ohio'])
In [222]: frame
Out[222]:
Colorado Texas New York Ohio
2000-01-05 -0.896431 0.677263 0.036503 0.087102
2000-01-12 -0.046662 0.927238 0.482284 -0.867130
```
當你對這個數據進行聚合,每組只有一個值,這樣就會引入缺失值。我們使用asfreq方法轉換成高頻,不經過聚合:
```python
In [223]: df_daily = frame.resample('D').asfreq()
In [224]: df_daily
Out[224]:
Colorado Texas New York Ohio
2000-01-05 -0.896431 0.677263 0.036503 0.087102
2000-01-06 NaN NaN NaN NaN
2000-01-07 NaN NaN NaN NaN
2000-01-08 NaN NaN NaN NaN
2000-01-09 NaN NaN NaN NaN
2000-01-10 NaN NaN NaN NaN
2000-01-11 NaN NaN NaN NaN
2000-01-12 -0.046662 0.927238 0.482284 -0.867130
```
假設你想要用前面的周型值填充“非星期三”。resampling的填充和插值方式跟fillna和reindex的一樣:
```python
In [225]: frame.resample('D').ffill()
Out[225]:
Colorado Texas New York Ohio
2000-01-05 -0.896431 0.677263 0.036503 0.087102
2000-01-06 -0.896431 0.677263 0.036503 0.087102
2000-01-07 -0.896431 0.677263 0.036503 0.087102
2000-01-08 -0.896431 0.677263 0.036503 0.087102
2000-01-09 -0.896431 0.677263 0.036503 0.087102
2000-01-10 -0.896431 0.677263 0.036503 0.087102
2000-01-11 -0.896431 0.677263 0.036503 0.087102
2000-01-12 -0.046662 0.927238 0.482284 -0.867130
```
同樣,這里也可以只填充指定的時期數(目的是限制前面的觀測值的持續使用距離):
```python
In [226]: frame.resample('D').ffill(limit=2)
Out[226]:
Colorado Texas New York Ohio
2000-01-05 -0.896431 0.677263 0.036503 0.087102
2000-01-06 -0.896431 0.677263 0.036503 0.087102
2000-01-07 -0.896431 0.677263 0.036503 0.087102
2000-01-08 NaN NaN NaN NaN
2000-01-09 NaN NaN NaN NaN
2000-01-10 NaN NaN NaN NaN
2000-01-11 NaN NaN NaN NaN
2000-01-12 -0.046662 0.927238 0.482284 -0.867130
```
注意,新的日期索引完全沒必要跟舊的重疊:
```python
In [227]: frame.resample('W-THU').ffill()
Out[227]:
Colorado Texas New York Ohio
2000-01-06 -0.896431 0.677263 0.036503 0.087102
2000-01-13 -0.046662 0.927238 0.482284 -0.867130
```
## 通過時期進行重采樣
對那些使用時期索引的數據進行重采樣與時間戳很像:
```python
In [228]: frame = pd.DataFrame(np.random.randn(24, 4),
.....: index=pd.period_range('1-2000', '12-2001',
.....: freq='M'),
.....: columns=['Colorado', 'Texas', 'New York', 'Ohio'])
In [229]: frame[:5]
Out[229]:
Colorado Texas New York Ohio
2000-01 0.493841 -0.155434 1.397286 1.507055
2000-02 -1.179442 0.443171 1.395676 -0.529658
2000-03 0.787358 0.248845 0.743239 1.267746
2000-04 1.302395 -0.272154 -0.051532 -0.467740
2000-05 -1.040816 0.426419 0.312945 -1.115689
In [230]: annual_frame = frame.resample('A-DEC').mean()
In [231]: annual_frame
Out[231]:
Colorado Texas New York Ohio
2000 0.556703 0.016631 0.111873 -0.027445
2001 0.046303 0.163344 0.251503 -0.157276
```
升采樣要稍微麻煩一些,因為你必須決定在新頻率中各區間的哪端用于放置原來的值,就像asfreq方法那樣。convention參數默認為'start',也可設置為'end':
```python
# Q-DEC: Quarterly, year ending in December
In [232]: annual_frame.resample('Q-DEC').ffill()
Out[232]:
Colorado Texas New York Ohio
2000Q1 0.556703 0.016631 0.111873 -0.027445
2000Q2 0.556703 0.016631 0.111873 -0.027445
2000Q3 0.556703 0.016631 0.111873 -0.027445
2000Q4 0.556703 0.016631 0.111873 -0.027445
2001Q1 0.046303 0.163344 0.251503 -0.157276
2001Q2 0.046303 0.163344 0.251503 -0.157276
2001Q3 0.046303 0.163344 0.251503 -0.157276
2001Q4 0.046303 0.163344 0.251503 -0.157276
In [233]: annual_frame.resample('Q-DEC', convention='end').ffill()
Out[233]:
Colorado Texas New York Ohio
2000Q4 0.556703 0.016631 0.111873 -0.027445
2001Q1 0.556703 0.016631 0.111873 -0.027445
2001Q2 0.556703 0.016631 0.111873 -0.027445
2001Q3 0.556703 0.016631 0.111873 -0.027445
2001Q4 0.046303 0.163344 0.251503 -0.157276
```
由于時期指的是時間區間,所以升采樣和降采樣的規則就比較嚴格:
- 在降采樣中,目標頻率必須是源頻率的子時期(subperiod)。
- 在升采樣中,目標頻率必須是源頻率的超時期(superperiod)。
如果不滿足這些條件,就會引發異常。這主要影響的是按季、年、周計算的頻率。例如,由Q-MAR定義的時間區間只能升采樣為A-MAR、A-JUN、A-SEP、A-DEC等:
```python
In [234]: annual_frame.resample('Q-MAR').ffill()
Out[234]:
Colorado Texas New York Ohio
2000Q4 0.556703 0.016631 0.111873 -0.027445
2001Q1 0.556703 0.016631 0.111873 -0.027445
2001Q2 0.556703 0.016631 0.111873 -0.027445
2001Q3 0.556703 0.016631 0.111873 -0.027445
2001Q4 0.046303 0.163344 0.251503 -0.157276
2002Q1 0.046303 0.163344 0.251503 -0.157276
2002Q2 0.046303 0.163344 0.251503 -0.157276
2002Q3 0.046303 0.163344 0.251503 -0.157276
```
# 11.7 移動窗口函數
在移動窗口(可以帶有指數衰減權數)上計算的各種統計函數也是一類常見于時間序列的數組變換。這樣可以圓滑噪音數據或斷裂數據。我將它們稱為移動窗口函數(moving window function),其中還包括那些窗口不定長的函數(如指數加權移動平均)。跟其他統計函數一樣,移動窗口函數也會自動排除缺失值。
開始之前,我們加載一些時間序列數據,將其重采樣為工作日頻率:
```python
In [235]: close_px_all = pd.read_csv('examples/stock_px_2.csv',
.....: parse_dates=True, index_col=0)
In [236]: close_px = close_px_all[['AAPL', 'MSFT', 'XOM']]
In [237]: close_px = close_px.resample('B').ffill()
```
現在引入rolling運算符,它與resample和groupby很像。可以在TimeSeries或DataFrame以及一個window(表示期數,見圖11-4)上調用它:
```python
In [238]: close_px.AAPL.plot()
Out[238]: <matplotlib.axes._subplots.AxesSubplot at 0x7f2f2570cf98>
In [239]: close_px.AAPL.rolling(250).mean().plot()
```
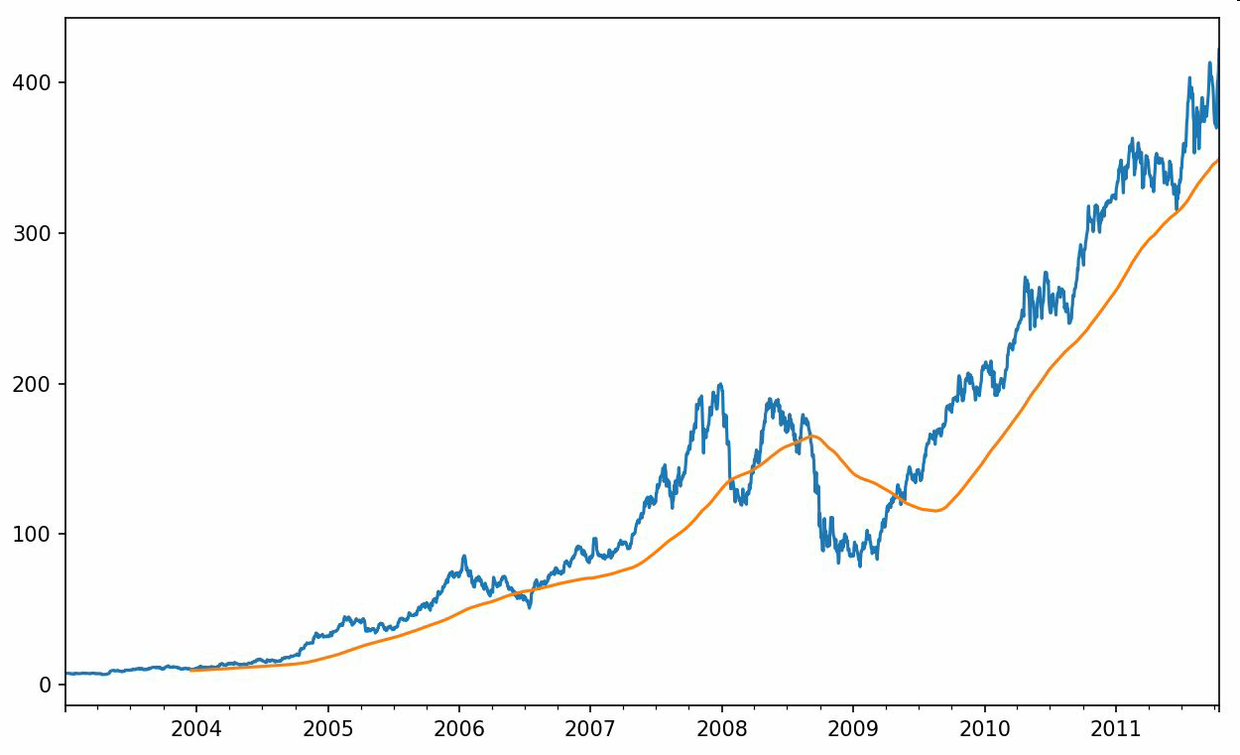
表達式rolling(250)與groupby很像,但不是對其進行分組,而是創建一個按照250天分組的滑動窗口對象。然后,我們就得到了蘋果公司股價的250天的移動窗口。
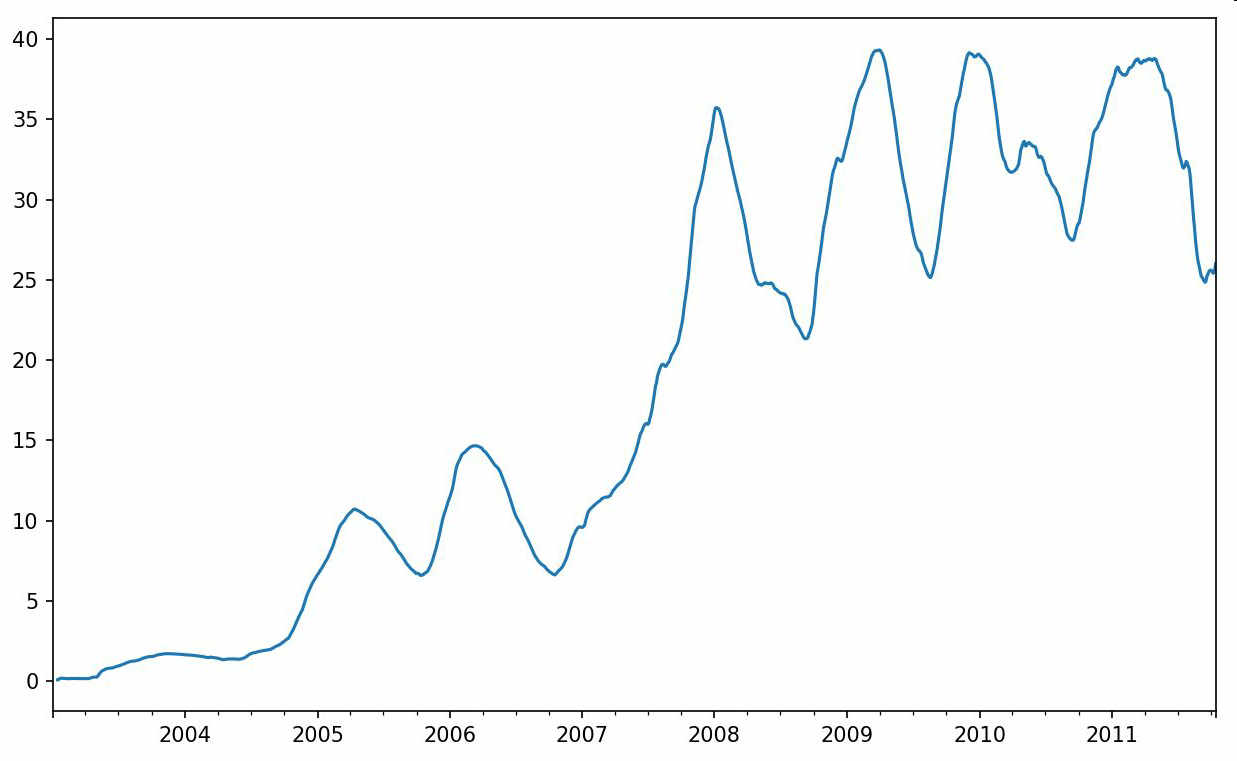
默認情況下,rolling函數需要窗口中所有的值為非NA值。可以修改該行為以解決缺失數據的問題。其實,在時間序列開始處尚不足窗口期的那些數據就是個特例(見圖11-5):
```python
In [241]: appl_std250 = close_px.AAPL.rolling(250, min_periods=10).std()
In [242]: appl_std250[5:12]
Out[242]:
2003-01-09 NaN
2003-01-10 NaN
2003-01-13 NaN
2003-01-14 NaN
2003-01-15 0.077496
2003-01-16 0.074760
2003-01-17 0.112368
Freq: B, Name: AAPL, dtype: float64
In [243]: appl_std250.plot()
```
要計算擴展窗口平均(expanding window mean),可以使用expanding而不是rolling。“擴展”意味著,從時間序列的起始處開始窗口,增加窗口直到它超過所有的序列。apple_std250時間序列的擴展窗口平均如下所示:
```python
In [244]: expanding_mean = appl_std250.expanding().mean()
```
對DataFrame調用rolling_mean(以及與之類似的函數)會將轉換應用到所有的列上(見圖11-6):
```python
In [246]: close_px.rolling(60).mean().plot(logy=True)
```
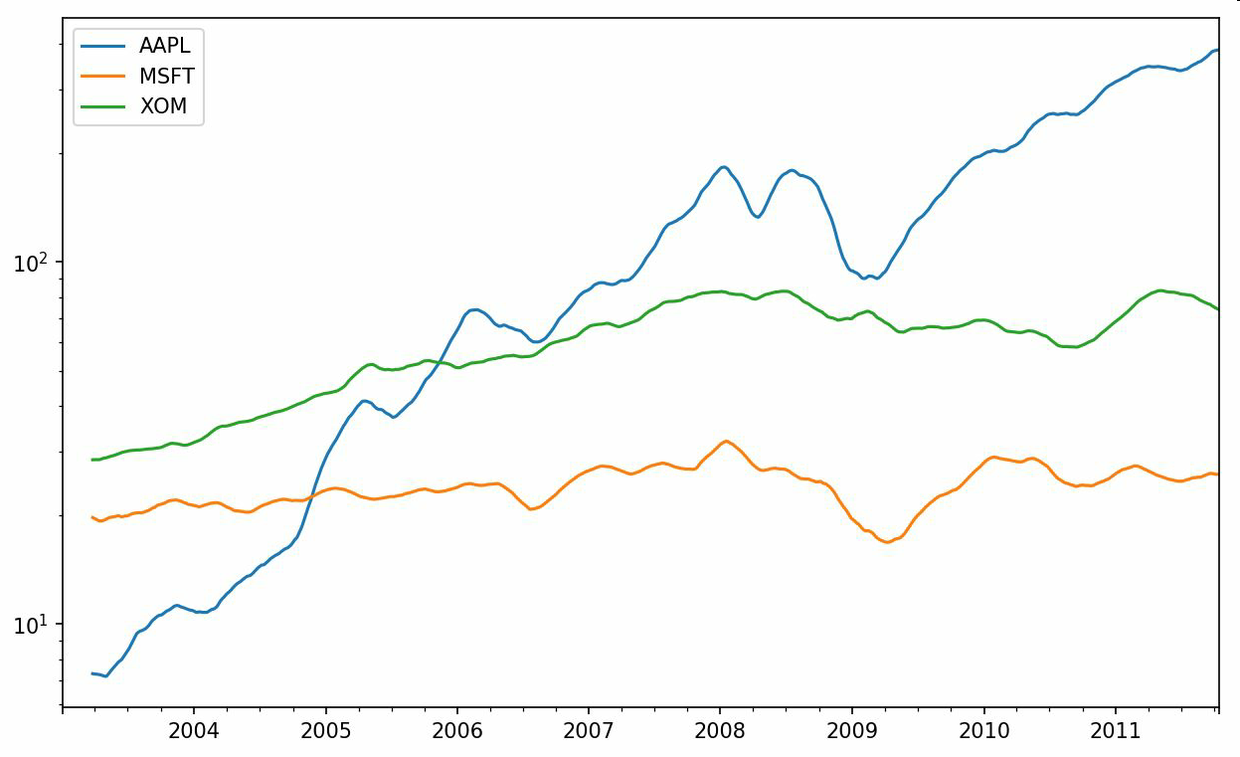
rolling函數也可以接受一個指定固定大小時間補償字符串,而不是一組時期。這樣可以方便處理不規律的時間序列。這些字符串也可以傳遞給resample。例如,我們可以計算20天的滾動均值,如下所示:
```python
In [247]: close_px.rolling('20D').mean()
Out[247]:
AAPL MSFT XOM
2003-01-02 7.400000 21.110000 29.220000
2003-01-03 7.425000 21.125000 29.230000
2003-01-06 7.433333 21.256667 29.473333
2003-01-07 7.432500 21.425000 29.342500
2003-01-08 7.402000 21.402000 29.240000
2003-01-09 7.391667 21.490000 29.273333
2003-01-10 7.387143 21.558571 29.238571
2003-01-13 7.378750 21.633750 29.197500
2003-01-14 7.370000 21.717778 29.194444
2003-01-15 7.355000 21.757000 29.152000
... ... ... ...
2011-10-03 398.002143 25.890714 72.413571
2011-10-04 396.802143 25.807857 72.427143
2011-10-05 395.751429 25.729286 72.422857
2011-10-06 394.099286 25.673571 72.375714
2011-10-07 392.479333 25.712000 72.454667
2011-10-10 389.351429 25.602143 72.527857
2011-10-11 388.505000 25.674286 72.835000
2011-10-12 388.531429 25.810000 73.400714
2011-10-13 388.826429 25.961429 73.905000
2011-10-14 391.038000 26.048667 74.185333
[2292 rows x 3 columns]
```
## 指數加權函數
另一種使用固定大小窗口及相等權數觀測值的辦法是,定義一個衰減因子(decay factor)常量,以便使近期的觀測值擁有更大的權數。衰減因子的定義方式有很多,比較流行的是使用時間間隔(span),它可以使結果兼容于窗口大小等于時間間隔的簡單移動窗口(simple moving window)函數。
由于指數加權統計會賦予近期的觀測值更大的權數,因此相對于等權統計,它能“適應”更快的變化。
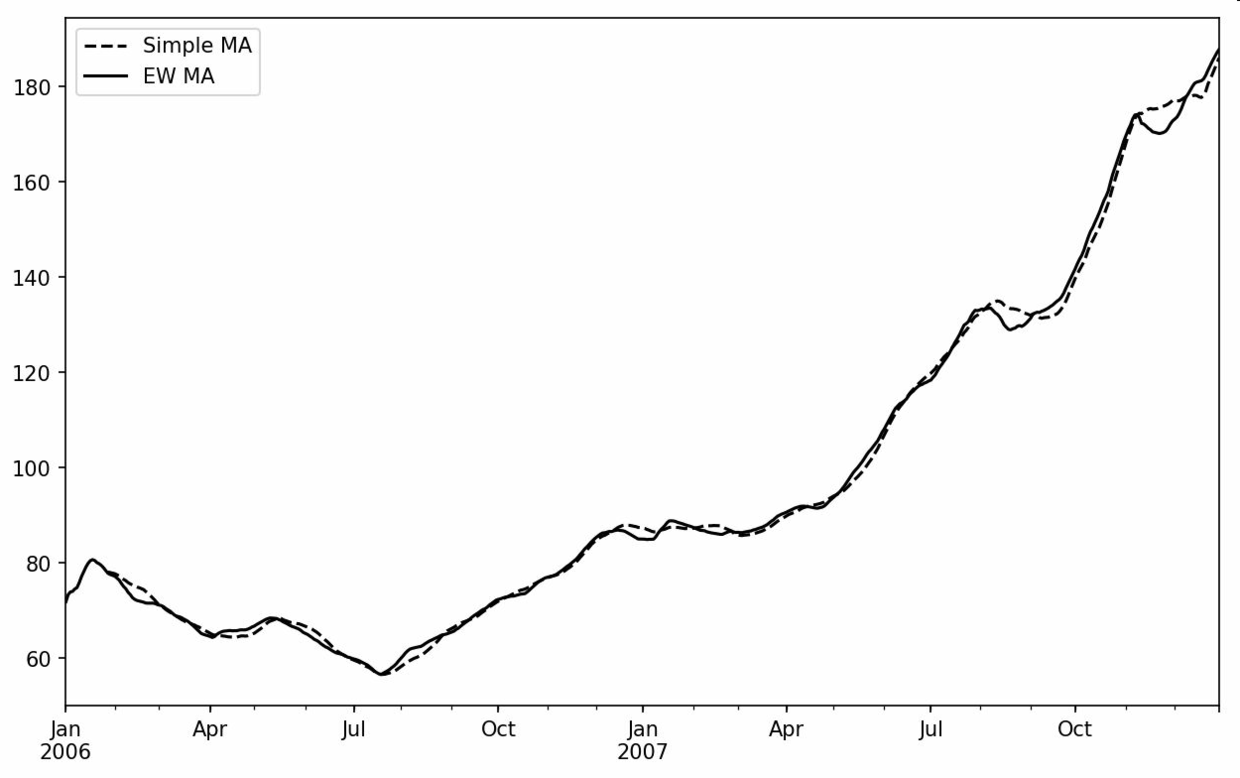
除了rolling和expanding,pandas還有ewm運算符。下面這個例子對比了蘋果公司股價的30日移動平均和span=30的指數加權移動平均(如圖11-7所示):
```python
In [249]: aapl_px = close_px.AAPL['2006':'2007']
In [250]: ma60 = aapl_px.rolling(30, min_periods=20).mean()
In [251]: ewma60 = aapl_px.ewm(span=30).mean()
In [252]: ma60.plot(style='k--', label='Simple MA')
Out[252]: <matplotlib.axes._subplots.AxesSubplot at 0x7f2f252161d0>
In [253]: ewma60.plot(style='k-', label='EW MA')
Out[253]: <matplotlib.axes._subplots.AxesSubplot at 0x7f2f252161d0>
In [254]: plt.legend()
```
## 二元移動窗口函數
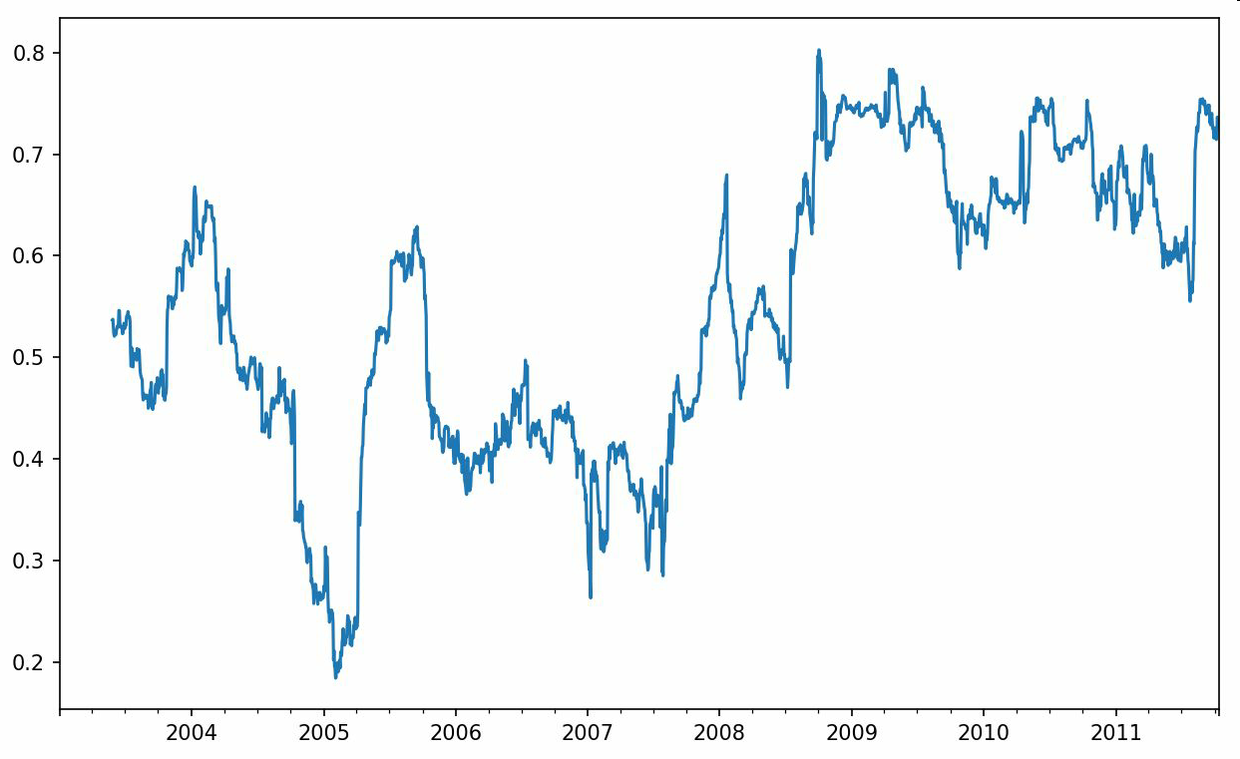
有些統計運算(如相關系數和協方差)需要在兩個時間序列上執行。例如,金融分析師常常對某只股票對某個參考指數(如標準普爾500指數)的相關系數感興趣。要進行說明,我們先計算我們感興趣的時間序列的百分數變化:
```python
In [256]: spx_px = close_px_all['SPX']
In [257]: spx_rets = spx_px.pct_change()
In [258]: returns = close_px.pct_change()
```
調用rolling之后,corr聚合函數開始計算與spx_rets滾動相關系數(結果見圖11-8):
```python
In [259]: corr = returns.AAPL.rolling(125, min_periods=100).corr(spx_rets)
In [260]: corr.plot()
```
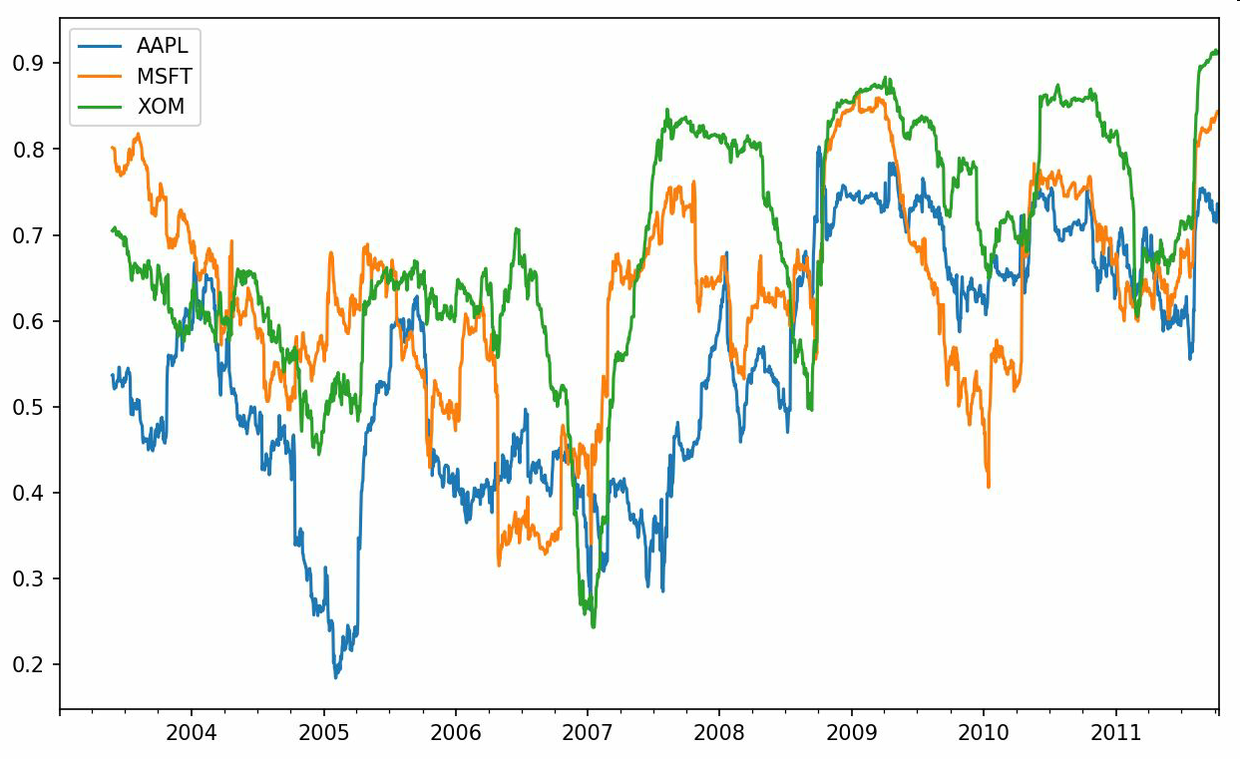
假設你想要一次性計算多只股票與標準普爾500指數的相關系數。雖然編寫一個循環并新建一個DataFrame不是什么難事,但比較啰嗦。其實,只需傳入一個TimeSeries和一個DataFrame,rolling_corr就會自動計算TimeSeries(本例中就是spx_rets)與DataFrame各列的相關系數。結果如圖11-9所示:
```python
In [262]: corr = returns.rolling(125, min_periods=100).corr(spx_rets)
In [263]: corr.plot()
```
## 用戶定義的移動窗口函數
rolling_apply函數使你能夠在移動窗口上應用自己設計的數組函數。唯一要求的就是:該函數要能從數組的各個片段中產生單個值(即約簡)。比如說,當我們用rolling(...).quantile(q)計算樣本分位數時,可能對樣本中特定值的百分等級感興趣。scipy.stats.percentileofscore函數就能達到這個目的(結果見圖11-10):
```python
In [265]: from scipy.stats import percentileofscore
In [266]: score_at_2percent = lambda x: percentileofscore(x, 0.02)
In [267]: result = returns.AAPL.rolling(250).apply(score_at_2percent)
In [268]: result.plot()
```
如果你沒安裝SciPy,可以使用conda或pip安裝。
# 11.8 總結
與前面章節接觸的數據相比,時間序列數據要求不同類型的分析和數據轉換工具。
在接下來的章節中,我們將學習一些高級的pandas方法和如何開始使用建模庫statsmodels和scikit-learn。
- 利用 Python 進行數據分析 · 第 2 版
- 第 1 章 準備工作
- 第 2 章 Python 語法基礎,IPython 和 Jupyter Notebooks
- 第 3 章 Python 的數據結構、函數和文件
- 第 4 章 NumPy 基礎:數組和矢量計算
- 第 5 章 pandas 入門
- 第 6 章 數據加載、存儲與文件格式
- 第 7 章 數據清洗和準備
- 第 8 章 數據規整:聚合、合并和重塑
- 第 9 章 繪圖和可視化
- 第 10 章 數據聚合與分組運算
- 第 11 章 時間序列
- 第 12 章 pandas 高級應用
- 第 13 章 Python 建模庫介紹
- 第 14 章 數據分析案例
- 附錄 A NumPy 高級應用
- 附錄 B 更多關于 IPython 的內容