
# 第 7 章 數據清洗和準備
在數據分析和建模的過程中,相當多的時間要用在數據準備上:加載、清理、轉換以及重塑。這些工作會占到分析師時間的80%或更多。有時,存儲在文件和數據庫中的數據的格式不適合某個特定的任務。許多研究者都選擇使用通用編程語言(如Python、Perl、R或Java)或UNIX文本處理工具(如sed或awk)對數據格式進行專門處理。幸運的是,pandas和內置的Python標準庫提供了一組高級的、靈活的、快速的工具,可以讓你輕松地將數據規整為想要的格式。
如果你發現了一種本書或pandas庫中沒有的數據操作方式,請在郵件列表或GitHub網站上提出。實際上,pandas的許多設計和實現都是由真實應用的需求所驅動的。
在本章中,我會討論處理缺失數據、重復數據、字符串操作和其它分析數據轉換的工具。下一章,我會關注于用多種方法合并、重塑數據集。
# 7.1 處理缺失數據
在許多數據分析工作中,缺失數據是經常發生的。pandas的目標之一就是盡量輕松地處理缺失數據。例如,pandas對象的所有描述性統計默認都不包括缺失數據。
缺失數據在pandas中呈現的方式有些不完美,但對于大多數用戶可以保證功能正常。對于數值數據,pandas使用浮點值NaN(Not a Number)表示缺失數據。我們稱其為哨兵值,可以方便的檢測出來:
```python
In [10]: string_data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado'])
In [11]: string_data
Out[11]:
0 aardvark
1 artichoke
2 NaN
3 avocado
dtype: object
In [12]: string_data.isnull()
Out[12]:
0 False
1 False
2 True
3 False
dtype: bool
```
在pandas中,我們采用了R語言中的慣用法,即將缺失值表示為NA,它表示不可用not available。在統計應用中,NA數據可能是不存在的數據或者雖然存在,但是沒有觀察到(例如,數據采集中發生了問題)。當進行數據清洗以進行分析時,最好直接對缺失數據進行分析,以判斷數據采集的問題或缺失數據可能導致的偏差。
Python內置的None值在對象數組中也可以作為NA:
```python
In [13]: string_data[0] = None
In [14]: string_data.isnull()
Out[14]:
0 True
1 False
2 True
3 False
dtype: bool
```
pandas項目中還在不斷優化內部細節以更好處理缺失數據,像用戶API功能,例如pandas.isnull,去除了許多惱人的細節。表7-1列出了一些關于缺失數據處理的函數。

## 濾除缺失數據
過濾掉缺失數據的辦法有很多種。你可以通過pandas.isnull或布爾索引的手工方法,但dropna可能會更實用一些。對于一個Series,dropna返回一個僅含非空數據和索引值的Series:
```python
In [15]: from numpy import nan as NA
In [16]: data = pd.Series([1, NA, 3.5, NA, 7])
In [17]: data.dropna()
Out[17]:
0 1.0
2 3.5
4 7.0
dtype: float64
```
這等價于:
```python
In [18]: data[data.notnull()]
Out[18]:
0 1.0
2 3.5
4 7.0
dtype: float64
```
而對于DataFrame對象,事情就有點復雜了。你可能希望丟棄全NA或含有NA的行或列。dropna默認丟棄任何含有缺失值的行:
```python
In [19]: data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA],
....: [NA, NA, NA], [NA, 6.5, 3.]])
In [20]: cleaned = data.dropna()
In [21]: data
Out[21]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
In [22]: cleaned
Out[22]:
0 1 2
0 1.0 6.5 3.0
```
傳入how='all'將只丟棄全為NA的那些行:
```python
In [23]: data.dropna(how='all')
Out[23]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
3 NaN 6.5 3.0
```
用這種方式丟棄列,只需傳入axis=1即可:
```python
In [24]: data[4] = NA
In [25]: data
Out[25]:
0 1 2 4
0 1.0 6.5 3.0 NaN
1 1.0 NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN 6.5 3.0 NaN
In [26]: data.dropna(axis=1, how='all')
Out[26]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
```
另一個濾除DataFrame行的問題涉及時間序列數據。假設你只想留下一部分觀測數據,可以用thresh參數實現此目的:
```python
In [27]: df = pd.DataFrame(np.random.randn(7, 3))
In [28]: df.iloc[:4, 1] = NA
In [29]: df.iloc[:2, 2] = NA
In [30]: df
Out[30]:
0 1 2
0 -0.204708 NaN NaN
1 -0.555730 NaN NaN
2 0.092908 NaN 0.769023
3 1.246435 NaN -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
In [31]: df.dropna()
Out[31]:
0 1 2
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
In [32]: df.dropna(thresh=2)
Out[32]:
0 1 2
2 0.092908 NaN 0.769023
3 1.246435 NaN -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
```
## 填充缺失數據
你可能不想濾除缺失數據(有可能會丟棄跟它有關的其他數據),而是希望通過其他方式填補那些“空洞”。對于大多數情況而言,fillna方法是最主要的函數。通過一個常數調用fillna就會將缺失值替換為那個常數值:
```python
In [33]: df.fillna(0)
Out[33]:
0 1 2
0 -0.204708 0.000000 0.000000
1 -0.555730 0.000000 0.000000
2 0.092908 0.000000 0.769023
3 1.246435 0.000000 -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
```
若是通過一個字典調用fillna,就可以實現對不同的列填充不同的值:
```python
In [34]: df.fillna({1: 0.5, 2: 0})
Out[34]:
0 1 2
0 -0.204708 0.500000 0.000000
1 -0.555730 0.500000 0.000000
2 0.092908 0.500000 0.769023
3 1.246435 0.500000 -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
```
fillna默認會返回新對象,但也可以對現有對象進行就地修改:
```python
In [35]: _ = df.fillna(0, inplace=True)
In [36]: df
Out[36]:
0 1 2
0 -0.204708 0.000000 0.000000
1 -0.555730 0.000000 0.000000
2 0.092908 0.000000 0.769023
3 1.246435 0.000000 -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
```
對reindexing有效的那些插值方法也可用于fillna:
```python
In [37]: df = pd.DataFrame(np.random.randn(6, 3))
In [38]: df.iloc[2:, 1] = NA
In [39]: df.iloc[4:, 2] = NA
In [40]: df
Out[40]:
0 1 2
0 0.476985 3.248944 -1.021228
1 -0.577087 0.124121 0.302614
2 0.523772 NaN 1.343810
3 -0.713544 NaN -2.370232
4 -1.860761 NaN NaN
5 -1.265934 NaN NaN
In [41]: df.fillna(method='ffill')
Out[41]:
0 1 2
0 0.476985 3.248944 -1.021228
1 -0.577087 0.124121 0.302614
2 0.523772 0.124121 1.343810
3 -0.713544 0.124121 -2.370232
4 -1.860761 0.124121 -2.370232
5 -1.265934 0.124121 -2.370232
In [42]: df.fillna(method='ffill', limit=2)
Out[42]:
0 1 2
0 0.476985 3.248944 -1.021228
1 -0.577087 0.124121 0.302614
2 0.523772 0.124121 1.343810
3 -0.713544 0.124121 -2.370232
4 -1.860761 NaN -2.370232
5 -1.265934 NaN -2.370232
```
只要有些創新,你就可以利用fillna實現許多別的功能。比如說,你可以傳入Series的平均值或中位數:
```python
In [43]: data = pd.Series([1., NA, 3.5, NA, 7])
In [44]: data.fillna(data.mean())
Out[44]:
0 1.000000
1 3.833333
2 3.500000
3 3.833333
4 7.000000
dtype: float64
```
表7-2列出了fillna的參考。


# 7.2 數據轉換
本章到目前為止介紹的都是數據的重排。另一類重要操作則是過濾、清理以及其他的轉換工作。
## 移除重復數據
DataFrame中出現重復行有多種原因。下面就是一個例子:
```python
In [45]: data = pd.DataFrame({'k1': ['one', 'two'] * 3 + ['two'],
....: 'k2': [1, 1, 2, 3, 3, 4, 4]})
In [46]: data
Out[46]:
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
6 two 4
```
DataFrame的duplicated方法返回一個布爾型Series,表示各行是否是重復行(前面出現過的行):
```python
In [47]: data.duplicated()
Out[47]:
0 False
1 False
2 False
3 False
4 False
5 False
6 True
dtype: bool
```
還有一個與此相關的drop_duplicates方法,它會返回一個DataFrame,重復的數組會標為False:
```python
In [48]: data.drop_duplicates()
Out[48]:
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
```
這兩個方法默認會判斷全部列,你也可以指定部分列進行重復項判斷。假設我們還有一列值,且只希望根據k1列過濾重復項:
```python
In [49]: data['v1'] = range(7)
In [50]: data.drop_duplicates(['k1'])
Out[50]:
k1 k2 v1
0 one 1 0
1 two 1 1
```
duplicated和drop_duplicates默認保留的是第一個出現的值組合。傳入keep='last'則保留最后一個:
```python
In [51]: data.drop_duplicates(['k1', 'k2'], keep='last')
Out[51]:
k1 k2 v1
0 one 1 0
1 two 1 1
2 one 2 2
3 two 3 3
4 one 3 4
6 two 4 6
```
## 利用函數或映射進行數據轉換
對于許多數據集,你可能希望根據數組、Series或DataFrame列中的值來實現轉換工作。我們來看看下面這組有關肉類的數據:
```python
In [52]: data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon',
....: 'Pastrami', 'corned beef', 'Bacon',
....: 'pastrami', 'honey ham', 'nova lox'],
....: 'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
In [53]: data
Out[53]:
food ounces
0 bacon 4.0
1 pulled pork 3.0
2 bacon 12.0
3 Pastrami 6.0
4 corned beef 7.5
5 Bacon 8.0
6 pastrami 3.0
7 honey ham 5.0
8 nova lox 6.0
```
假設你想要添加一列表示該肉類食物來源的動物類型。我們先編寫一個不同肉類到動物的映射:
```python
meat_to_animal = {
'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'
}
```
Series的map方法可以接受一個函數或含有映射關系的字典型對象,但是這里有一個小問題,即有些肉類的首字母大寫了,而另一些則沒有。因此,我們還需要使用Series的str.lower方法,將各個值轉換為小寫:
```python
In [55]: lowercased = data['food'].str.lower()
In [56]: lowercased
Out[56]:
0 bacon
1 pulled pork
2 bacon
3 pastrami
4 corned beef
5 bacon
6 pastrami
7 honey ham
8 nova lox
Name: food, dtype: object
In [57]: data['animal'] = lowercased.map(meat_to_animal)
In [58]: data
Out[58]:
food ounces animal
0 bacon 4.0 pig
1 pulled pork 3.0 pig
2 bacon 12.0 pig
3 Pastrami 6.0 cow
4 corned beef 7.5 cow
5 Bacon 8.0 pig
6 pastrami 3.0 cow
7 honey ham 5.0 pig
8 nova lox 6.0 salmon
```
我們也可以傳入一個能夠完成全部這些工作的函數:
```python
In [59]: data['food'].map(lambda x: meat_to_animal[x.lower()])
Out[59]:
0 pig
1 pig
2 pig
3 cow
4 cow
5 pig
6 cow
7 pig
8 salmon
Name: food, dtype: object
```
使用map是一種實現元素級轉換以及其他數據清理工作的便捷方式。
## 替換值
利用fillna方法填充缺失數據可以看做值替換的一種特殊情況。前面已經看到,map可用于修改對象的數據子集,而replace則提供了一種實現該功能的更簡單、更靈活的方式。我們來看看下面這個Series:
```python
In [60]: data = pd.Series([1., -999., 2., -999., -1000., 3.])
In [61]: data
Out[61]:
0 1.0
1 -999.0
2 2.0
3 -999.0
4 -1000.0
5 3.0
```
-999這個值可能是一個表示缺失數據的標記值。要將其替換為pandas能夠理解的NA值,我們可以利用replace來產生一個新的Series(除非傳入inplace=True):
```python
In [62]: data.replace(-999, np.nan)
Out[62]:
0 1.0
1 NaN
2 2.0
3 NaN
4 -1000.0
5 3.0
dtype: float64
```
如果你希望一次性替換多個值,可以傳入一個由待替換值組成的列表以及一個替換值::
```python
In [63]: data.replace([-999, -1000], np.nan)
Out[63]:
0 1.0
1 NaN
2 2.0
3 NaN
4 NaN
5 3.0
dtype: float64
```
要讓每個值有不同的替換值,可以傳遞一個替換列表:
```python
In [64]: data.replace([-999, -1000], [np.nan, 0])
Out[64]:
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
```
傳入的參數也可以是字典:
```python
In [65]: data.replace({-999: np.nan, -1000: 0})
Out[65]:
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
```
>筆記:data.replace方法與data.str.replace不同,后者做的是字符串的元素級替換。我們會在后面學習Series的字符串方法。
## 重命名軸索引
跟Series中的值一樣,軸標簽也可以通過函數或映射進行轉換,從而得到一個新的不同標簽的對象。軸還可以被就地修改,而無需新建一個數據結構。接下來看看下面這個簡單的例子:
```python
In [66]: data = pd.DataFrame(np.arange(12).reshape((3, 4)),
....: index=['Ohio', 'Colorado', 'New York'],
....: columns=['one', 'two', 'three', 'four'])
```
跟Series一樣,軸索引也有一個map方法:
```python
In [67]: transform = lambda x: x[:4].upper()
In [68]: data.index.map(transform)
Out[68]: Index(['OHIO', 'COLO', 'NEW '], dtype='object')
```
你可以將其賦值給index,這樣就可以對DataFrame進行就地修改:
```python
In [69]: data.index = data.index.map(transform)
In [70]: data
Out[70]:
one two three four
OHIO 0 1 2 3
COLO 4 5 6 7
NEW 8 9 10 11
```
如果想要創建數據集的轉換版(而不是修改原始數據),比較實用的方法是rename:
```python
In [71]: data.rename(index=str.title, columns=str.upper)
Out[71]:
ONE TWO THREE FOUR
Ohio 0 1 2 3
Colo 4 5 6 7
New 8 9 10 11
```
特別說明一下,rename可以結合字典型對象實現對部分軸標簽的更新:
```python
In [72]: data.rename(index={'OHIO': 'INDIANA'},
....: columns={'three': 'peekaboo'})
Out[72]:
one two peekaboo four
INDIANA 0 1 2 3
COLO 4 5 6 7
NEW 8 9 10 11
```
rename可以實現復制DataFrame并對其索引和列標簽進行賦值。如果希望就地修改某個數據集,傳入inplace=True即可:
```python
In [73]: data.rename(index={'OHIO': 'INDIANA'}, inplace=True)
In [74]: data
Out[74]:
one two three four
INDIANA 0 1 2 3
COLO 4 5 6 7
NEW 8 9 10 11
```
## 離散化和面元劃分
為了便于分析,連續數據常常被離散化或拆分為“面元”(bin)。假設有一組人員數據,而你希望將它們劃分為不同的年齡組:
```python
In [75]: ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
```
接下來將這些數據劃分為“18到25”、“26到35”、“35到60”以及“60以上”幾個面元。要實現該功能,你需要使用pandas的cut函數:
```python
In [76]: bins = [18, 25, 35, 60, 100]
In [77]: cats = pd.cut(ages, bins)
In [78]: cats
Out[78]:
[(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (25, 35], (60, 100], (35,60], (35, 60], (25, 35]]
Length: 12
Categories (4, interval[int64]): [(18, 25] < (25, 35] < (35, 60] < (60, 100]]
```
pandas返回的是一個特殊的Categorical對象。結果展示了pandas.cut劃分的面元。你可以將其看做一組表示面元名稱的字符串。它的底層含有一個表示不同分類名稱的類型數組,以及一個codes屬性中的年齡數據的標簽:
```python
In [79]: cats.codes
Out[79]: array([0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 1], dtype=int8)
In [80]: cats.categories
Out[80]:
IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]]
closed='right',
dtype='interval[int64]')
In [81]: pd.value_counts(cats)
Out[81]:
(18, 25] 5
(35, 60] 3
(25, 35] 3
(60, 100] 1
dtype: int64
```
pd.value_counts(cats)是pandas.cut結果的面元計數。
跟“區間”的數學符號一樣,圓括號表示開端,而方括號則表示閉端(包括)。哪邊是閉端可以通過right=False進行修改:
```python
In [82]: pd.cut(ages, [18, 26, 36, 61, 100], right=False)
Out[82]:
[[18, 26), [18, 26), [18, 26), [26, 36), [18, 26), ..., [26, 36), [61, 100), [36,
61), [36, 61), [26, 36)]
Length: 12
Categories (4, interval[int64]): [[18, 26) < [26, 36) < [36, 61) < [61, 100)]
```
你可 以通過傳遞一個列表或數組到labels,設置自己的面元名稱:
```python
In [83]: group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
In [84]: pd.cut(ages, bins, labels=group_names)
Out[84]:
[Youth, Youth, Youth, YoungAdult, Youth, ..., YoungAdult, Senior, MiddleAged, Mid
dleAged, YoungAdult]
Length: 12
Categories (4, object): [Youth < YoungAdult < MiddleAged < Senior]
```
如果向cut傳入的是面元的數量而不是確切的面元邊界,則它會根據數據的最小值和最大值計算等長面元。下面這個例子中,我們將一些均勻分布的數據分成四組:
```python
In [85]: data = np.random.rand(20)
In [86]: pd.cut(data, 4, precision=2)
Out[86]:
[(0.34, 0.55], (0.34, 0.55], (0.76, 0.97], (0.76, 0.97], (0.34, 0.55], ..., (0.34
, 0.55], (0.34, 0.55], (0.55, 0.76], (0.34, 0.55], (0.12, 0.34]]
Length: 20
Categories (4, interval[float64]): [(0.12, 0.34] < (0.34, 0.55] < (0.55, 0.76] <
(0.76, 0.97]]
```
選項precision=2,限定小數只有兩位。
qcut是一個非常類似于cut的函數,它可以根據樣本分位數對數據進行面元劃分。根據數據的分布情況,cut可能無法使各個面元中含有相同數量的數據點。而qcut由于使用的是樣本分位數,因此可以得到大小基本相等的面元:
```python
In [87]: data = np.random.randn(1000) # Normally distributed
In [88]: cats = pd.qcut(data, 4) # Cut into quartiles
In [89]: cats
Out[89]:
[(-0.0265, 0.62], (0.62, 3.928], (-0.68, -0.0265], (0.62, 3.928], (-0.0265, 0.62]
, ..., (-0.68, -0.0265], (-0.68, -0.0265], (-2.95, -0.68], (0.62, 3.928], (-0.68,
-0.0265]]
Length: 1000
Categories (4, interval[float64]): [(-2.95, -0.68] < (-0.68, -0.0265] < (-0.0265,
0.62] <
(0.62, 3.928]]
In [90]: pd.value_counts(cats)
Out[90]:
(0.62, 3.928] 250
(-0.0265, 0.62] 250
(-0.68, -0.0265] 250
(-2.95, -0.68] 250
dtype: int64
```
與cut類似,你也可以傳遞自定義的分位數(0到1之間的數值,包含端點):
```python
In [91]: pd.qcut(data, [0, 0.1, 0.5, 0.9, 1.])
Out[91]:
[(-0.0265, 1.286], (-0.0265, 1.286], (-1.187, -0.0265], (-0.0265, 1.286], (-0.026
5, 1.286], ..., (-1.187, -0.0265], (-1.187, -0.0265], (-2.95, -1.187], (-0.0265,
1.286], (-1.187, -0.0265]]
Length: 1000
Categories (4, interval[float64]): [(-2.95, -1.187] < (-1.187, -0.0265] < (-0.026
5, 1.286] <
(1.286, 3.928]]
```
本章稍后在講解聚合和分組運算時會再次用到cut和qcut,因為這兩個離散化函數對分位和分組分析非常重要。
## 檢測和過濾異常值
過濾或變換異常值(outlier)在很大程度上就是運用數組運算。來看一個含有正態分布數據的DataFrame:
```python
In [92]: data = pd.DataFrame(np.random.randn(1000, 4))
In [93]: data.describe()
Out[93]:
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 0.049091 0.026112 -0.002544 -0.051827
std 0.996947 1.007458 0.995232 0.998311
min -3.645860 -3.184377 -3.745356 -3.428254
25% -0.599807 -0.612162 -0.687373 -0.747478
50% 0.047101 -0.013609 -0.022158 -0.088274
75% 0.756646 0.695298 0.699046 0.623331
max 2.653656 3.525865 2.735527 3.366626
```
假設你想要找出某列中絕對值大小超過3的值:
```python
In [94]: col = data[2]
In [95]: col[np.abs(col) > 3]
Out[95]:
41 -3.399312
136 -3.745356
Name: 2, dtype: float64
```
要選出全部含有“超過3或-3的值”的行,你可以在布爾型DataFrame中使用any方法:
```python
In [96]: data[(np.abs(data) > 3).any(1)]
Out[96]:
0 1 2 3
41 0.457246 -0.025907 -3.399312 -0.974657
60 1.951312 3.260383 0.963301 1.201206
136 0.508391 -0.196713 -3.745356 -1.520113
235 -0.242459 -3.056990 1.918403 -0.578828
258 0.682841 0.326045 0.425384 -3.428254
322 1.179227 -3.184377 1.369891 -1.074833
544 -3.548824 1.553205 -2.186301 1.277104
635 -0.578093 0.193299 1.397822 3.366626
782 -0.207434 3.525865 0.283070 0.544635
803 -3.645860 0.255475 -0.549574 -1.907459
```
根據這些條件,就可以對值進行設置。下面的代碼可以將值限制在區間-3到3以內:
```python
In [97]: data[np.abs(data) > 3] = np.sign(data) * 3
In [98]: data.describe()
Out[98]:
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 0.050286 0.025567 -0.001399 -0.051765
std 0.992920 1.004214 0.991414 0.995761
min -3.000000 -3.000000 -3.000000 -3.000000
25% -0.599807 -0.612162 -0.687373 -0.747478
50% 0.047101 -0.013609 -0.022158 -0.088274
75% 0.756646 0.695298 0.699046 0.623331
max 2.653656 3.000000 2.735527 3.000000
```
根據數據的值是正還是負,np.sign(data)可以生成1和-1:
```python
In [99]: np.sign(data).head()
Out[99]:
0 1 2 3
0 -1.0 1.0 -1.0 1.0
1 1.0 -1.0 1.0 -1.0
2 1.0 1.0 1.0 -1.0
3 -1.0 -1.0 1.0 -1.0
4 -1.0 1.0 -1.0 -1.0
```
## 排列和隨機采樣
利用numpy.random.permutation函數可以輕松實現對Series或DataFrame的列的排列工作(permuting,隨機重排序)。通過需要排列的軸的長度調用permutation,可產生一個表示新順序的整數數組:
```python
In [100]: df = pd.DataFrame(np.arange(5 * 4).reshape((5, 4)))
In [101]: sampler = np.random.permutation(5)
In [102]: sampler
Out[102]: array([3, 1, 4, 2, 0])
```
然后就可以在基于iloc的索引操作或take函數中使用該數組了:
```python
In [103]: df
Out[103]:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
In [104]: df.take(sampler)
Out[104]:
0 1 2 3
3 12 13 14 15
1 4 5 6 7
4 16 17 18 19
2 8 9 10 11
0 0 1 2 3
```
如果不想用替換的方式選取隨機子集,可以在Series和DataFrame上使用sample方法:
```python
In [105]: df.sample(n=3)
Out[105]:
0 1 2 3
3 12 13 14 15
4 16 17 18 19
2 8 9 10 11
```
要通過替換的方式產生樣本(允許重復選擇),可以傳遞replace=True到sample:
```python
In [106]: choices = pd.Series([5, 7, -1, 6, 4])
In [107]: draws = choices.sample(n=10, replace=True)
In [108]: draws
Out[108]:
4 4
1 7
4 4
2 -1
0 5
3 6
1 7
4 4
0 5
4 4
dtype: int64
```
## 計算指標/啞變量
另一種常用于統計建模或機器學習的轉換方式是:將分類變量(categorical variable)轉換為“啞變量”或“指標矩陣”。
如果DataFrame的某一列中含有k個不同的值,則可以派生出一個k列矩陣或DataFrame(其值全為1和0)。pandas有一個get_dummies函數可以實現該功能(其實自己動手做一個也不難)。使用之前的一個DataFrame例子:
```python
In [109]: df = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'],
.....: 'data1': range(6)})
In [110]: pd.get_dummies(df['key'])
Out[110]:
a b c
0 0 1 0
1 0 1 0
2 1 0 0
3 0 0 1
4 1 0 0
5 0 1 0
```
有時候,你可能想給指標DataFrame的列加上一個前綴,以便能夠跟其他數據進行合并。get_dummies的prefix參數可以實現該功能:
```python
In [111]: dummies = pd.get_dummies(df['key'], prefix='key')
In [112]: df_with_dummy = df[['data1']].join(dummies)
In [113]: df_with_dummy
Out[113]:
data1 key_a key_b key_c
0 0 0 1 0
1 1 0 1 0
2 2 1 0 0
3 3 0 0 1
4 4 1 0 0
5 5 0 1 0
```
如果DataFrame中的某行同屬于多個分類,則事情就會有點復雜。看一下MovieLens 1M數據集,14章會更深入地研究它:
```python
In [114]: mnames = ['movie_id', 'title', 'genres']
In [115]: movies = pd.read_table('datasets/movielens/movies.dat', sep='::',
.....: header=None, names=mnames)
In [116]: movies[:10]
Out[116]:
movie_id title genres
0 1 Toy Story (1995) Animation|Children's|Comedy
1 2 Jumanji (1995) Adventure|Children's|Fantasy
2 3 Grumpier Old Men (1995) Comedy|Romance
3 4 Waiting to Exhale (1995) Comedy|Drama
4 5 Father of the Bride Part II (1995) Comedy
5 6 Heat (1995) Action|Crime|Thriller
6 7 Sabrina (1995) Comedy|Romance
7 8 Tom and Huck (1995) Adventure|Children's
8 9 Sudden Death (1995)
Action
9 10 GoldenEye (1995) Action|Adventure|Thriller
```
要為每個genre添加指標變量就需要做一些數據規整操作。首先,我們從數據集中抽取出不同的genre值:
```python
In [117]: all_genres = []
In [118]: for x in movies.genres:
.....: all_genres.extend(x.split('|'))
In [119]: genres = pd.unique(all_genres)
```
現在有:
```python
In [120]: genres
Out[120]:
array(['Animation', "Children's", 'Comedy', 'Adventure', 'Fantasy',
'Romance', 'Drama', 'Action', 'Crime', 'Thriller','Horror',
'Sci-Fi', 'Documentary', 'War', 'Musical', 'Mystery', 'Film-Noir',
'Western'], dtype=object)
```
構建指標DataFrame的方法之一是從一個全零DataFrame開始:
```python
In [121]: zero_matrix = np.zeros((len(movies), len(genres)))
In [122]: dummies = pd.DataFrame(zero_matrix, columns=genres)
```
現在,迭代每一部電影,并將dummies各行的條目設為1。要這么做,我們使用dummies.columns來計算每個類型的列索引:
```python
In [123]: gen = movies.genres[0]
In [124]: gen.split('|')
Out[124]: ['Animation', "Children's", 'Comedy']
In [125]: dummies.columns.get_indexer(gen.split('|'))
Out[125]: array([0, 1, 2])
```
然后,根據索引,使用.iloc設定值:
```python
In [126]: for i, gen in enumerate(movies.genres):
.....: indices = dummies.columns.get_indexer(gen.split('|'))
.....: dummies.iloc[i, indices] = 1
.....:
```
然后,和以前一樣,再將其與movies合并起來:
```python
In [127]: movies_windic = movies.join(dummies.add_prefix('Genre_'))
In [128]: movies_windic.iloc[0]
Out[128]:
movie_id 1
title Toy Story (1995)
genres Animation|Children's|Comedy
Genre_Animation 1
Genre_Children's 1
Genre_Comedy 1
Genre_Adventure 0
Genre_Fantasy 0
Genre_Romance 0
Genre_Drama 0
...
Genre_Crime 0
Genre_Thriller 0
Genre_Horror 0
Genre_Sci-Fi 0
Genre_Documentary 0
Genre_War 0
Genre_Musical 0
Genre_Mystery 0
Genre_Film-Noir 0
Genre_Western 0
Name: 0, Length: 21, dtype: object
```
>筆記:對于很大的數據,用這種方式構建多成員指標變量就會變得非常慢。最好使用更低級的函數,將其寫入NumPy數組,然后結果包裝在DataFrame中。
一個對統計應用有用的秘訣是:結合get_dummies和諸如cut之類的離散化函數:
```python
In [129]: np.random.seed(12345)
In [130]: values = np.random.rand(10)
In [131]: values
Out[131]:
array([ 0.9296, 0.3164, 0.1839, 0.2046, 0.5677, 0.5955, 0.9645,
0.6532, 0.7489, 0.6536])
In [132]: bins = [0, 0.2, 0.4, 0.6, 0.8, 1]
In [133]: pd.get_dummies(pd.cut(values, bins))
Out[133]:
(0.0, 0.2] (0.2, 0.4] (0.4, 0.6] (0.6, 0.8] (0.8, 1.0]
0 0 0 0 0 1
1 0 1 0 0 0
2 1 0 0 0 0
3 0 1 0 0 0
4 0 0 1 0 0
5 0 0 1 0 0
6 0 0 0 0 1
7 0 0 0 1 0
8 0 0 0 1 0
9 0 0 0 1 0
```
我們用numpy.random.seed,使這個例子具有確定性。本書后面會介紹pandas.get_dummies。
# 7.3 字符串操作
Python能夠成為流行的數據處理語言,部分原因是其簡單易用的字符串和文本處理功能。大部分文本運算都直接做成了字符串對象的內置方法。對于更為復雜的模式匹配和文本操作,則可能需要用到正則表達式。pandas對此進行了加強,它使你能夠對整組數據應用字符串表達式和正則表達式,而且能處理煩人的缺失數據。
## 字符串對象方法
對于許多字符串處理和腳本應用,內置的字符串方法已經能夠滿足要求了。例如,以逗號分隔的字符串可以用split拆分成數段:
```python
In [134]: val = 'a,b, guido'
In [135]: val.split(',')
Out[135]: ['a', 'b', ' guido']
```
split常常與strip一起使用,以去除空白符(包括換行符):
```python
In [136]: pieces = [x.strip() for x in val.split(',')]
In [137]: pieces
Out[137]: ['a', 'b', 'guido']
```
利用加法,可以將這些子字符串以雙冒號分隔符的形式連接起來:
```python
In [138]: first, second, third = pieces
In [139]: first + '::' + second + '::' + third
Out[139]: 'a::b::guido'
```
但這種方式并不是很實用。一種更快更符合Python風格的方式是,向字符串"::"的join方法傳入一個列表或元組:
```python
In [140]: '::'.join(pieces)
Out[140]: 'a::b::guido'
```
其它方法關注的是子串定位。檢測子串的最佳方式是利用Python的in關鍵字,還可以使用index和find:
```python
In [141]: 'guido' in val
Out[141]: True
In [142]: val.index(',')
Out[142]: 1
In [143]: val.find(':')
Out[143]: -1
```
注意find和index的區別:如果找不到字符串,index將會引發一個異常(而不是返回-1):
```python
In [144]: val.index(':')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-144-280f8b2856ce> in <module>()
----> 1 val.index(':')
ValueError: substring not found
```
與此相關,count可以返回指定子串的出現次數:
```python
In [145]: val.count(',')
Out[145]: 2
```
replace用于將指定模式替換為另一個模式。通過傳入空字符串,它也常常用于刪除模式:
```python
In [146]: val.replace(',', '::')
Out[146]: 'a::b:: guido'
In [147]: val.replace(',', '')
Out[147]: 'ab guido'
```
表7-3列出了Python內置的字符串方法。
這些運算大部分都能使用正則表達式實現(馬上就會看到)。


casefold 將字符轉換為小寫,并將任何特定區域的變量字符組合轉換成一個通用的可比較形式。
## 正則表達式
正則表達式提供了一種靈活的在文本中搜索或匹配(通常比前者復雜)字符串模式的方式。正則表達式,常稱作regex,是根據正則表達式語言編寫的字符串。Python內置的re模塊負責對字符串應用正則表達式。我將通過一些例子說明其使用方法。
>筆記:正則表達式的編寫技巧可以自成一章,超出了本書的范圍。從網上和其它書可以找到許多非常不錯的教程和參考資料。
re模塊的函數可以分為三個大類:模式匹配、替換以及拆分。當然,它們之間是相輔相成的。一個regex描述了需要在文本中定位的一個模式,它可以用于許多目的。我們先來看一個簡單的例子:假設我想要拆分一個字符串,分隔符為數量不定的一組空白符(制表符、空格、換行符等)。描述一個或多個空白符的regex是\s+:
```python
In [148]: import re
In [149]: text = "foo bar\t baz \tqux"
In [150]: re.split('\s+', text)
Out[150]: ['foo', 'bar', 'baz', 'qux']
```
調用re.split('\s+',text)時,正則表達式會先被編譯,然后再在text上調用其split方法。你可以用re.compile自己編譯regex以得到一個可重用的regex對象:
```python
In [151]: regex = re.compile('\s+')
In [152]: regex.split(text)
Out[152]: ['foo', 'bar', 'baz', 'qux']
```
如果只希望得到匹配regex的所有模式,則可以使用findall方法:
```python
In [153]: regex.findall(text)
Out[153]: [' ', '\t ', ' \t']
```
>筆記:如果想避免正則表達式中不需要的轉義(\),則可以使用原始字符串字面量如r'C:\x'(也可以編寫其等價式'C:\\x')。
如果打算對許多字符串應用同一條正則表達式,強烈建議通過re.compile創建regex對象。這樣將可以節省大量的CPU時間。
match和search跟findall功能類似。findall返回的是字符串中所有的匹配項,而search則只返回第一個匹配項。match更加嚴格,它只匹配字符串的首部。來看一個小例子,假設我們有一段文本以及一條能夠識別大部分電子郵件地址的正則表達式:
```python
text = """Dave dave@google.com
Steve steve@gmail.com
Rob rob@gmail.com
Ryan ryan@yahoo.com
"""
pattern = r'[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}'
# re.IGNORECASE makes the regex case-insensitive
regex = re.compile(pattern, flags=re.IGNORECASE)
```
對text使用findall將得到一組電子郵件地址:
```python
In [155]: regex.findall(text)
Out[155]:
['dave@google.com',
'steve@gmail.com',
'rob@gmail.com',
'ryan@yahoo.com']
```
search返回的是文本中第一個電子郵件地址(以特殊的匹配項對象形式返回)。對于上面那個regex,匹配項對象只能告訴我們模式在原字符串中的起始和結束位置:
```python
In [156]: m = regex.search(text)
In [157]: m
Out[157]: <_sre.SRE_Match object; span=(5, 20), match='dave@google.com'>
In [158]: text[m.start():m.end()]
Out[158]: 'dave@google.com'
```
regex.match則將返回None,因為它只匹配出現在字符串開頭的模式:
```python
In [159]: print(regex.match(text))
None
```
相關的,sub方法可以將匹配到的模式替換為指定字符串,并返回所得到的新字符串:
```python
In [160]: print(regex.sub('REDACTED', text))
Dave REDACTED
Steve REDACTED
Rob REDACTED
Ryan REDACTED
```
假設你不僅想要找出電子郵件地址,還想將各個地址分成3個部分:用戶名、域名以及域后綴。要實現此功能,只需將待分段的模式的各部分用圓括號包起來即可:
```python
In [161]: pattern = r'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\.([A-Z]{2,4})'
In [162]: regex = re.compile(pattern, flags=re.IGNORECASE)
```
由這種修改過的正則表達式所產生的匹配項對象,可以通過其groups方法返回一個由模式各段組成的元組:
```python
In [163]: m = regex.match('wesm@bright.net')
In [164]: m.groups()
Out[164]: ('wesm', 'bright', 'net')
```
對于帶有分組功能的模式,findall會返回一個元組列表:
```python
In [165]: regex.findall(text)
Out[165]:
[('dave', 'google', 'com'),
('steve', 'gmail', 'com'),
('rob', 'gmail', 'com'),
('ryan', 'yahoo', 'com')]
```
sub還能通過諸如\1、\2之類的特殊符號訪問各匹配項中的分組。符號\1對應第一個匹配的組,\2對應第二個匹配的組,以此類推:
```python
In [166]: print(regex.sub(r'Username: \1, Domain: \2, Suffix: \3', text))
Dave Username: dave, Domain: google, Suffix: com
Steve Username: steve, Domain: gmail, Suffix: com
Rob Username: rob, Domain: gmail, Suffix: com
Ryan Username: ryan, Domain: yahoo, Suffix: com
```
Python中還有許多的正則表達式,但大部分都超出了本書的范圍。表7-4是一個簡要概括。

## pandas的矢量化字符串函數
清理待分析的散亂數據時,常常需要做一些字符串規整化工作。更為復雜的情況是,含有字符串的列有時還含有缺失數據:
```python
In [167]: data = {'Dave': 'dave@google.com', 'Steve': 'steve@gmail.com',
.....: 'Rob': 'rob@gmail.com', 'Wes': np.nan}
In [168]: data = pd.Series(data)
In [169]: data
Out[169]:
Dave dave@google.com
Rob rob@gmail.com
Steve steve@gmail.com
Wes NaN
dtype: object
In [170]: data.isnull()
Out[170]:
Dave False
Rob False
Steve False
Wes True
dtype: bool
```
通過data.map,所有字符串和正則表達式方法都能被應用于(傳入lambda表達式或其他函數)各個值,但是如果存在NA(null)就會報錯。為了解決這個問題,Series有一些能夠跳過NA值的面向數組方法,進行字符串操作。通過Series的str屬性即可訪問這些方法。例如,我們可以通過str.contains檢查各個電子郵件地址是否含有"gmail":
```python
In [171]: data.str.contains('gmail')
Out[171]:
Dave False
Rob True
Steve True
Wes NaN
dtype: object
```
也可以使用正則表達式,還可以加上任意re選項(如IGNORECASE):
```python
In [172]: pattern
Out[172]: '([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\\.([A-Z]{2,4})'
In [173]: data.str.findall(pattern, flags=re.IGNORECASE)
Out[173]:
Dave [(dave, google, com)]
Rob [(rob, gmail, com)]
Steve [(steve, gmail, com)]
Wes NaN
dtype: object
```
有兩個辦法可以實現矢量化的元素獲取操作:要么使用str.get,要么在str屬性上使用索引:
```python
In [174]: matches = data.str.match(pattern, flags=re.IGNORECASE)
In [175]: matches
Out[175]:
Dave True
Rob True
Steve True
Wes NaN
dtype: object
```
要訪問嵌入列表中的元素,我們可以傳遞索引到這兩個函數中:
```python
In [176]: matches.str.get(1)
Out[176]:
Dave NaN
Rob NaN
Steve NaN
Wes NaN
dtype: float64
In [177]: matches.str[0]
Out[177]:
Dave NaN
Rob NaN
Steve NaN
Wes NaN
dtype: float64
```
你可以利用這種方法對字符串進行截取:
```python
In [178]: data.str[:5]
Out[178]:
Dave dave@
Rob rob@g
Steve steve
Wes NaN
dtype: object
```
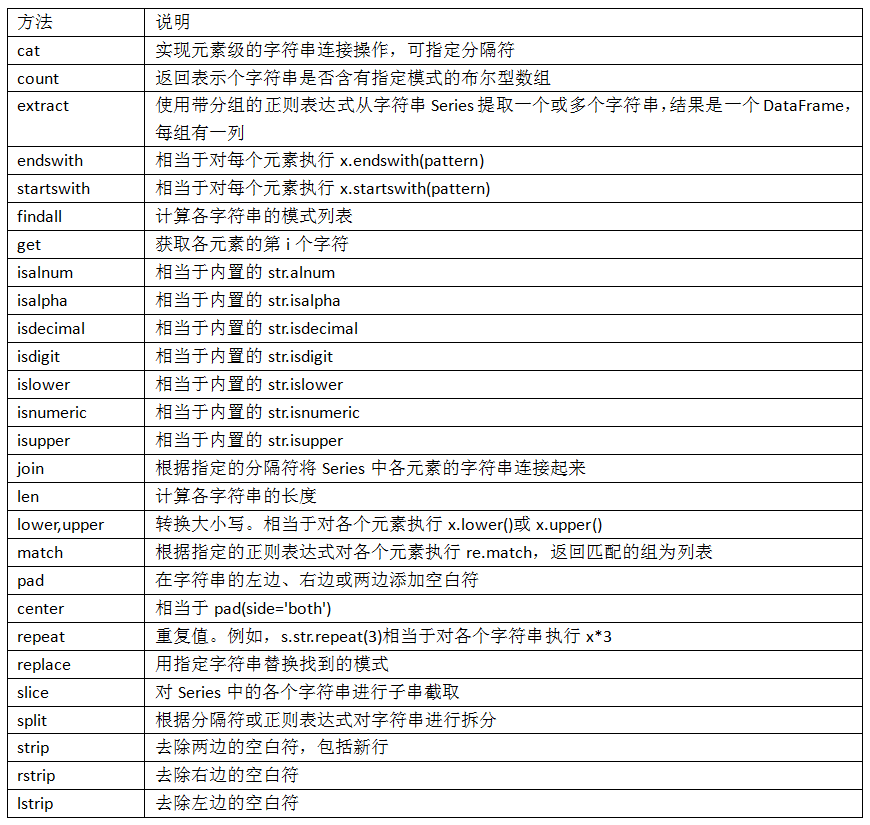
表7-5介紹了更多的pandas字符串方法。
# 7.4 總結
高效的數據準備可以讓你將更多的時間用于數據分析,花較少的時間用于準備工作,這樣就可以極大地提高生產力。我們在本章中學習了許多工具,但覆蓋并不全面。下一章,我們會學習pandas的聚合與分組。
- 利用 Python 進行數據分析 · 第 2 版
- 第 1 章 準備工作
- 第 2 章 Python 語法基礎,IPython 和 Jupyter Notebooks
- 第 3 章 Python 的數據結構、函數和文件
- 第 4 章 NumPy 基礎:數組和矢量計算
- 第 5 章 pandas 入門
- 第 6 章 數據加載、存儲與文件格式
- 第 7 章 數據清洗和準備
- 第 8 章 數據規整:聚合、合并和重塑
- 第 9 章 繪圖和可視化
- 第 10 章 數據聚合與分組運算
- 第 11 章 時間序列
- 第 12 章 pandas 高級應用
- 第 13 章 Python 建模庫介紹
- 第 14 章 數據分析案例
- 附錄 A NumPy 高級應用
- 附錄 B 更多關于 IPython 的內容