
# 附錄 B 更多關于 IPython 的內容
第2章中,我們學習了IPython shell和Jupyter notebook的基礎。本章中,我們會探索IPython更深層次的功能,可以從控制臺或在jupyter使用。
# B.1 使用命令歷史
Ipython維護了一個位于磁盤的小型數據庫,用于保存執行的每條指令。它的用途有:
- 只用最少的輸入,就能搜索、補全和執行先前運行過的指令;
- 在不同session間保存命令歷史;
- 將日志輸入/輸出歷史到一個文件
這些功能在shell中,要比notebook更為有用,因為notebook從設計上是將輸入和輸出的代碼放到每個代碼格子中。
## 搜索和重復使用命令歷史
Ipython可以讓你搜索和執行之前的代碼或其他命令。這個功能非常有用,因為你可能需要重復執行同樣的命令,例如%run命令,或其它代碼。假設你必須要執行:
```python
In[7]: %run first/second/third/data_script.py
```
運行成功,然后檢查結果,發現計算有錯。解決完問題,然后修改了data_script.py,你就可以輸入一些%run命令,然后按Ctrl+P或上箭頭。這樣就可以搜索歷史命令,匹配輸入字符的命令。多次按Ctrl+P或上箭頭,會繼續搜索命令。如果你要執行你想要執行的命令,不要害怕。你可以按下Ctrl-N或下箭頭,向前移動歷史命令。這樣做了幾次后,你可以不假思索地按下這些鍵!
Ctrl-R可以帶來如同Unix風格shell(比如bash shell)的readline的部分增量搜索功能。在Windows上,readline功能是被IPython模仿的。要使用這個功能,先按Ctrl-R,然后輸入一些包含于輸入行的想要搜索的字符:
```python
In [1]: a_command = foo(x, y, z)
(reverse-i-search)`com': a_command = foo(x, y, z)
```
Ctrl-R會循環歷史,找到匹配字符的每一行。
## 輸入和輸出變量
忘記將函數調用的結果分配給變量是非常煩人的。IPython的一個session會在一個特殊變量,存儲輸入和輸出Python對象的引用。前面兩個輸出會分別存儲在 _(一個下劃線)和 __(兩個下劃線)變量:
```python
In [24]: 2 ** 27
Out[24]: 134217728
In [25]: _
Out[25]: 134217728
```
輸入變量是存儲在名字類似_iX的變量中,X是輸入行的編號。對于每個輸入變量,都有一個對應的輸出變量_X。因此在輸入第27行之后,會有兩個新變量_27 (輸出)和_i27(輸入):
```python
In [26]: foo = 'bar'
In [27]: foo
Out[27]: 'bar'
In [28]: _i27
Out[28]: u'foo'
In [29]: _27
Out[29]: 'bar'
```
因為輸入變量是字符串,它們可以用Python的exec關鍵字再次執行:
```python
In [30]: exec(_i27)
```
這里,_i27是在In [27]輸入的代碼。
有幾個魔術函數可以讓你利用輸入和輸出歷史。%hist可以打印所有或部分的輸入歷史,加上或不加上編號。%reset可以清理交互命名空間,或輸入和輸出緩存。%xdel魔術函數可以去除IPython中對一個特別對象的所有引用。對于關于這些魔術方法的更多內容,請查看文檔。
>警告:當處理非常大的數據集時,要記住IPython的輸入和輸出的歷史會造成被引用的對象不被垃圾回收(釋放內存),即使你使用del關鍵字從交互命名空間刪除變量。在這種情況下,小心使用xdel %和%reset可以幫助你避免陷入內存問題。
# B.2 與操作系統交互
IPython的另一個功能是無縫連接文件系統和操作系統。這意味著,在同時做其它事時,無需退出IPython,就可以像Windows或Unix使用命令行操作,包括shell命令、更改目錄、用Python對象(列表或字符串)存儲結果。它還有簡單的命令別名和目錄書簽功能。
表B-1總結了調用shell命令的魔術函數和語法。我會在下面幾節介紹這些功能。
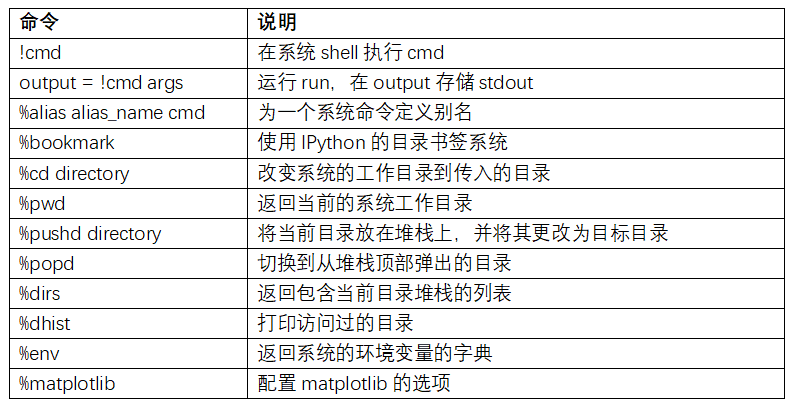
## Shell命令和別名
用嘆號開始一行,是告訴IPython執行嘆號后面的所有內容。這意味著你可以刪除文件(取決于操作系統,用rm或del)、改變目錄或執行任何其他命令。
通過給變量加上嘆號,你可以在一個變量中存儲命令的控制臺輸出。例如,在我聯網的基于Linux的主機上,我可以獲得IP地址為Python變量:
```python
In [1]: ip_info = !ifconfig wlan0 | grep "inet "
In [2]: ip_info[0].strip()
Out[2]: 'inet addr:10.0.0.11 Bcast:10.0.0.255 Mask:255.255.255.0'
```
返回的Python對象ip_info實際上是一個自定義的列表類型,它包含著多種版本的控制臺輸出。
當使用!,IPython還可以替換定義在當前環境的Python值。要這么做,可以在變量名前面加上$符號:
```python
In [3]: foo = 'test*'
In [4]: !ls $foo
test4.py test.py test.xml
```
%alias魔術函數可以自定義shell命令的快捷方式。看一個簡單的例子:
```python
In [1]: %alias ll ls -l
In [2]: ll /usr
total 332
drwxr-xr-x 2 root root 69632 2012-01-29 20:36 bin/
drwxr-xr-x 2 root root 4096 2010-08-23 12:05 games/
drwxr-xr-x 123 root root 20480 2011-12-26 18:08 include/
drwxr-xr-x 265 root root 126976 2012-01-29 20:36 lib/
drwxr-xr-x 44 root root 69632 2011-12-26 18:08 lib32/
lrwxrwxrwx 1 root root 3 2010-08-23 16:02 lib64 -> lib/
drwxr-xr-x 15 root root 4096 2011-10-13 19:03 local/
drwxr-xr-x 2 root root 12288 2012-01-12 09:32 sbin/
drwxr-xr-x 387 root root 12288 2011-11-04 22:53 share/
drwxrwsr-x 24 root src 4096 2011-07-17 18:38 src/
```
你可以執行多個命令,就像在命令行中一樣,只需用分號隔開:
```python
In [558]: %alias test_alias (cd examples; ls; cd ..)
In [559]: test_alias
macrodata.csv spx.csv tips.csv
```
當session結束,你定義的別名就會失效。要創建恒久的別名,需要使用配置。
## 目錄書簽系統
IPython有一個簡單的目錄書簽系統,可以讓你保存常用目錄的別名,這樣在跳來跳去的時候會非常方便。例如,假設你想創建一個書簽,指向本書的補充內容:
```python
In [6]: %bookmark py4da /home/wesm/code/pydata-book
```
這么做之后,當使用%cd魔術命令,就可以使用定義的書簽:
```python
In [7]: cd py4da
(bookmark:py4da) -> /home/wesm/code/pydata-book
/home/wesm/code/pydata-book
```
如果書簽的名字,與當前工作目錄的一個目錄重名,你可以使用-b標志來覆寫,使用書簽的位置。使用%bookmark的-l選項,可以列出所有的書簽:
```python
In [8]: %bookmark -l
Current bookmarks:
py4da -> /home/wesm/code/pydata-book-source
```
書簽,和別名不同,在session之間是保持的。
# B.3 軟件開發工具
除了作為優秀的交互式計算和數據探索環境,IPython也是有效的Python軟件開發工具。在數據分析中,最重要的是要有正確的代碼。幸運的是,IPython緊密集成了和加強了Python內置的pdb調試器。第二,需要快速的代碼。對于這點,IPython有易于使用的代碼計時和分析工具。我會詳細介紹這些工具。
## 交互調試器
IPython的調試器用tab補全、語法增強、逐行異常追蹤增強了pdb。調試代碼的最佳時間就是剛剛發生錯誤。異常發生之后就輸入%debug,就啟動了調試器,進入拋出異常的堆棧框架:
```python
In [2]: run examples/ipython_bug.py
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
/home/wesm/code/pydata-book/examples/ipython_bug.py in <module>()
13 throws_an_exception()
14
---> 15 calling_things()
/home/wesm/code/pydata-book/examples/ipython_bug.py in calling_things()
11 def calling_things():
12 works_fine()
---> 13 throws_an_exception()
14
15 calling_things()
/home/wesm/code/pydata-book/examples/ipython_bug.py in throws_an_exception()
7 a = 5
8 b = 6
----> 9 assert(a + b == 10)
10
11 def calling_things():
AssertionError:
In [3]: %debug
> /home/wesm/code/pydata-book/examples/ipython_bug.py(9)throws_an_exception()
8 b = 6
----> 9 assert(a + b == 10)
10
ipdb>
```
一旦進入調試器,你就可以執行任意的Python代碼,在每個堆棧框架中檢查所有的對象和數據(解釋器會保持它們活躍)。默認是從錯誤發生的最低級開始。通過u(up)和d(down),你可以在不同等級的堆棧蹤跡切換:
```python
ipdb> u
> /home/wesm/code/pydata-book/examples/ipython_bug.py(13)calling_things()
12 works_fine()
---> 13 throws_an_exception()
14
```
執行%pdb命令,可以在發生任何異常時讓IPython自動啟動調試器,許多用戶會發現這個功能非常好用。
用調試器幫助開發代碼也很容易,特別是當你希望設置斷點或在函數和腳本間移動,以檢查每個階段的狀態。有多種方法可以實現。第一種是使用%run和-d,它會在執行傳入腳本的任何代碼之前調用調試器。你必須馬上按s(step)以進入腳本:
```python
In [5]: run -d examples/ipython_bug.py
Breakpoint 1 at /home/wesm/code/pydata-book/examples/ipython_bug.py:1
NOTE: Enter 'c' at the ipdb> prompt to start your script.
> <string>(1)<module>()
ipdb> s
--Call--
> /home/wesm/code/pydata-book/examples/ipython_bug.py(1)<module>()
1---> 1 def works_fine():
2 a = 5
3 b = 6
```
然后,你就可以決定如何工作。例如,在前面的異常,我們可以設置一個斷點,就在調用works_fine之前,然后運行腳本,在遇到斷點時按c(continue):
```python
ipdb> b 12
ipdb> c
> /home/wesm/code/pydata-book/examples/ipython_bug.py(12)calling_things()
11 def calling_things():
2--> 12 works_fine()
13 throws_an_exception()
```
這時,你可以step進入works_fine(),或通過按n(next)執行works_fine(),進入下一行:
```python
ipdb> n
> /home/wesm/code/pydata-book/examples/ipython_bug.py(13)calling_things()
2 12 works_fine()
---> 13 throws_an_exception()
14
```
然后,我們可以進入throws_an_exception,到達發生錯誤的一行,查看變量。注意,調試器的命令是在變量名之前,在變量名前面加嘆號!可以查看內容:
```python
ipdb> s
--Call--
> /home/wesm/code/pydata-book/examples/ipython_bug.py(6)throws_an_exception()
5
----> 6 def throws_an_exception():
7 a = 5
ipdb> n
> /home/wesm/code/pydata-book/examples/ipython_bug.py(7)throws_an_exception()
6 def throws_an_exception():
----> 7 a = 5
8 b = 6
ipdb> n
> /home/wesm/code/pydata-book/examples/ipython_bug.py(8)throws_an_exception()
7 a = 5
----> 8 b = 6
9 assert(a + b == 10)
ipdb> n
> /home/wesm/code/pydata-book/examples/ipython_bug.py(9)throws_an_exception()
8 b = 6
----> 9 assert(a + b == 10)
10
ipdb> !a
5
ipdb> !b
6
```
提高使用交互式調試器的熟練度需要練習和經驗。表B-2,列出了所有調試器命令。如果你習慣了IDE,你可能覺得終端的調試器在一開始會不順手,但會覺得越來越好用。一些Python的IDEs有很好的GUI調試器,選擇順手的就好。
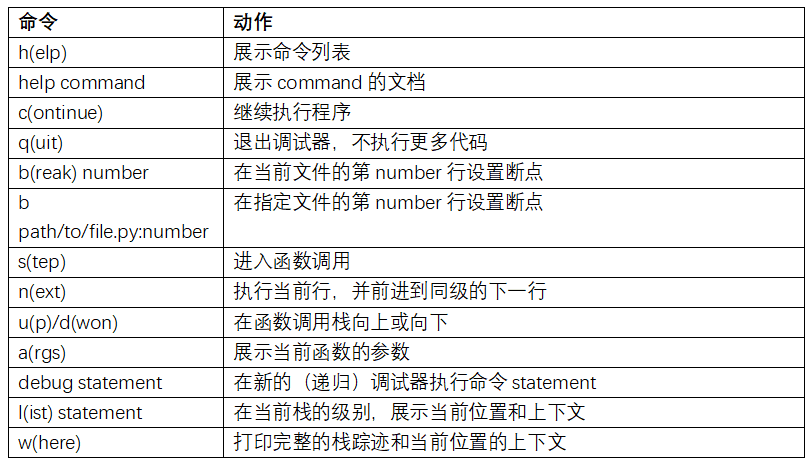
## 使用調試器的其它方式
還有一些其它工作可以用到調試器。第一個是使用特殊的set_trace函數(根據pdb.set_trace命名的),這是一個簡裝的斷點。還有兩種方法是你可能想用的(像我一樣,將其添加到IPython的配置):
```python
from IPython.core.debugger import Pdb
def set_trace():
Pdb(color_scheme='Linux').set_trace(sys._getframe().f_back)
def debug(f, *args, **kwargs):
pdb = Pdb(color_scheme='Linux')
return pdb.runcall(f, *args, **kwargs)
```
第一個函數set_trace非常簡單。如果你想暫時停下來進行仔細檢查(比如發生異常之前),可以在代碼的任何位置使用set_trace:
```python
In [7]: run examples/ipython_bug.py
> /home/wesm/code/pydata-book/examples/ipython_bug.py(16)calling_things()
15 set_trace()
---> 16 throws_an_exception()
17
```
按c(continue)可以讓代碼繼續正常行進。
我們剛看的debug函數,可以讓你方便的在調用任何函數時使用調試器。假設我們寫了一個下面的函數,想逐步分析它的邏輯:
```python
def f(x, y, z=1):
tmp = x + y
return tmp / z
```
普通地使用f,就會像f(1, 2, z=3)。而要想進入f,將f作為第一個參數傳遞給debug,再將位置和關鍵詞參數傳遞給f:
```python
In [6]: debug(f, 1, 2, z=3)
> <ipython-input>(2)f()
1 def f(x, y, z):
----> 2 tmp = x + y
3 return tmp / z
ipdb>
```
這兩個簡單方法節省了我平時的大量時間。
最后,調試器可以和%run一起使用。腳本通過運行%run -d,就可以直接進入調試器,隨意設置斷點并啟動腳本:
```python
In [1]: %run -d examples/ipython_bug.py
Breakpoint 1 at /home/wesm/code/pydata-book/examples/ipython_bug.py:1
NOTE: Enter 'c' at the ipdb> prompt to start your script.
> <string>(1)<module>()
ipdb>
```
加上-b和行號,可以預設一個斷點:
```python
In [2]: %run -d -b2 examples/ipython_bug.py
Breakpoint 1 at /home/wesm/code/pydata-book/examples/ipython_bug.py:2
NOTE: Enter 'c' at the ipdb> prompt to start your script.
> <string>(1)<module>()
ipdb> c
> /home/wesm/code/pydata-book/examples/ipython_bug.py(2)works_fine()
1 def works_fine():
1---> 2 a = 5
3 b = 6
ipdb>
```
## 代碼計時:%time 和 %timeit
對于大型和長時間運行的數據分析應用,你可能希望測量不同組件或單獨函數調用語句的執行時間。你可能想知道哪個函數占用的時間最長。幸運的是,IPython可以讓你開發和測試代碼時,很容易地獲得這些信息。
手動用time模塊和它的函數time.clock和time.time給代碼計時,既單調又重復,因為必須要寫一些無趣的模板化代碼:
```python
import time
start = time.time()
for i in range(iterations):
# some code to run here
elapsed_per = (time.time() - start) / iterations
```
因為這是一個很普通的操作,IPython有兩個魔術函數,%time和%timeit,可以自動化這個過程。
%time會運行一次語句,報告總共的執行時間。假設我們有一個大的字符串列表,我們想比較不同的可以挑選出特定開頭字符串的方法。這里有一個含有600000字符串的列表,和兩個方法,用以選出foo開頭的字符串:
```python
# a very large list of strings
strings = ['foo', 'foobar', 'baz', 'qux',
'python', 'Guido Van Rossum'] * 100000
method1 = [x for x in strings if x.startswith('foo')]
method2 = [x for x in strings if x[:3] == 'foo']
```
看起來它們的性能應該是同級別的,但事實呢?用%time進行一下測量:
```python
In [561]: %time method1 = [x for x in strings if x.startswith('foo')]
CPU times: user 0.19 s, sys: 0.00 s, total: 0.19 s
Wall time: 0.19 s
In [562]: %time method2 = [x for x in strings if x[:3] == 'foo']
CPU times: user 0.09 s, sys: 0.00 s, total: 0.09 s
Wall time: 0.09 s
```
Wall time(wall-clock time的簡寫)是主要關注的。第一個方法是第二個方法的兩倍多,但是這種測量方法并不準確。如果用%time多次測量,你就會發現結果是變化的。要想更準確,可以使用%timeit魔術函數。給出任意一條語句,它能多次運行這條語句以得到一個更為準確的時間:
```python
In [563]: %timeit [x for x in strings if x.startswith('foo')]
10 loops, best of 3: 159 ms per loop
In [564]: %timeit [x for x in strings if x[:3] == 'foo']
10 loops, best of 3: 59.3 ms per loop
```
這個例子說明了解Python標準庫、NumPy、pandas和其它庫的性能是很有價值的。在大型數據分析中,這些毫秒的時間就會累積起來!
%timeit特別適合分析執行時間短的語句和函數,即使是微秒或納秒。這些時間可能看起來毫不重要,但是一個20微秒的函數執行1百萬次就比一個5微秒的函數長15秒。在上一個例子中,我們可以直接比較兩個字符串操作,以了解它們的性能特點:
```python
In [565]: x = 'foobar'
In [566]: y = 'foo'
In [567]: %timeit x.startswith(y)
1000000 loops, best of 3: 267 ns per loop
In [568]: %timeit x[:3] == y
10000000 loops, best of 3: 147 ns per loop
```
## 基礎分析:%prun和%run -p
分析代碼與代碼計時關系很緊密,除了它關注的是“時間花在了哪里”。Python主要的分析工具是cProfile模塊,它并不局限于IPython。cProfile會執行一個程序或任意的代碼塊,并會跟蹤每個函數執行的時間。
使用cProfile的通常方式是在命令行中運行一整段程序,輸出每個函數的累積時間。假設我們有一個簡單的在循環中進行線型代數運算的腳本(計算一系列的100×100矩陣的最大絕對特征值):
```python
import numpy as np
from numpy.linalg import eigvals
def run_experiment(niter=100):
K = 100
results = []
for _ in xrange(niter):
mat = np.random.randn(K, K)
max_eigenvalue = np.abs(eigvals(mat)).max()
results.append(max_eigenvalue)
return results
some_results = run_experiment()
print 'Largest one we saw: %s' % np.max(some_results)
```
你可以用cProfile運行這個腳本,使用下面的命令行:
```
python -m cProfile cprof_example.py
```
運行之后,你會發現輸出是按函數名排序的。這樣要看出誰耗費的時間多有點困難,最好用-s指定排序:
```python
$ python -m cProfile -s cumulative cprof_example.py
Largest one we saw: 11.923204422
15116 function calls (14927 primitive calls) in 0.720 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.001 0.001 0.721 0.721 cprof_example.py:1(<module>)
100 0.003 0.000 0.586 0.006 linalg.py:702(eigvals)
200 0.572 0.003 0.572 0.003 {numpy.linalg.lapack_lite.dgeev}
1 0.002 0.002 0.075 0.075 __init__.py:106(<module>)
100 0.059 0.001 0.059 0.001 {method 'randn')
1 0.000 0.000 0.044 0.044 add_newdocs.py:9(<module>)
2 0.001 0.001 0.037 0.019 __init__.py:1(<module>)
2 0.003 0.002 0.030 0.015 __init__.py:2(<module>)
1 0.000 0.000 0.030 0.030 type_check.py:3(<module>)
1 0.001 0.001 0.021 0.021 __init__.py:15(<module>)
1 0.013 0.013 0.013 0.013 numeric.py:1(<module>)
1 0.000 0.000 0.009 0.009 __init__.py:6(<module>)
1 0.001 0.001 0.008 0.008 __init__.py:45(<module>)
262 0.005 0.000 0.007 0.000 function_base.py:3178(add_newdoc)
100 0.003 0.000 0.005 0.000 linalg.py:162(_assertFinite)
```
只顯示出前15行。掃描cumtime列,可以容易地看出每個函數用了多少時間。如果一個函數調用了其它函數,計時并不會停止。cProfile會記錄每個函數的起始和結束時間,使用它們進行計時。
除了在命令行中使用,cProfile也可以在程序中使用,分析任意代碼塊,而不必運行新進程。Ipython的%prun和%run -p,有便捷的接口實現這個功能。%prun使用類似cProfile的命令行選項,但是可以分析任意Python語句,而不用整個py文件:
```python
In [4]: %prun -l 7 -s cumulative run_experiment()
4203 function calls in 0.643 seconds
Ordered by: cumulative time
List reduced from 32 to 7 due to restriction <7>
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.643 0.643 <string>:1(<module>)
1 0.001 0.001 0.643 0.643 cprof_example.py:4(run_experiment)
100 0.003 0.000 0.583 0.006 linalg.py:702(eigvals)
200 0.569 0.003 0.569 0.003 {numpy.linalg.lapack_lite.dgeev}
100 0.058 0.001 0.058 0.001 {method 'randn'}
100 0.003 0.000 0.005 0.000 linalg.py:162(_assertFinite)
200 0.002 0.000 0.002 0.000 {method 'all' of 'numpy.ndarray'}
```
相似的,調用``%run -p -s cumulative cprof_example.py``有和命令行相似的作用,只是你不用離開Ipython。
在Jupyter notebook中,你可以使用%%prun魔術方法(兩個%)來分析一整段代碼。這會彈出一個帶有分析輸出的獨立窗口。便于快速回答一些問題,比如“為什么這段代碼用了這么長時間”?
使用IPython或Jupyter,還有一些其它工具可以讓分析工作更便于理解。其中之一是SnakeViz(https://github.com/jiffyclub/snakeviz/),它會使用d3.js產生一個分析結果的交互可視化界面。
## 逐行分析函數
有些情況下,用%prun(或其它基于cProfile的分析方法)得到的信息,不能獲得函數執行時間的整個過程,或者結果過于復雜,加上函數名,很難進行解讀。對于這種情況,有一個小庫叫做line_profiler(可以通過PyPI或包管理工具獲得)。它包含IPython插件,可以啟用一個新的魔術函數%lprun,可以對一個函數或多個函數進行逐行分析。你可以通過修改IPython配置(查看IPython文檔或本章后面的配置小節)加入下面這行,啟用這個插件:
```python
# A list of dotted module names of IPython extensions to load.
c.TerminalIPythonApp.extensions = ['line_profiler']
```
你還可以運行命令:
```python
%load_ext line_profiler
```
line_profiler也可以在程序中使用(查看完整文檔),但是在IPython中使用是最為強大的。假設你有一個帶有下面代碼的模塊prof_mod,做一些NumPy數組操作:
```python
from numpy.random import randn
def add_and_sum(x, y):
added = x + y
summed = added.sum(axis=1)
return summed
def call_function():
x = randn(1000, 1000)
y = randn(1000, 1000)
return add_and_sum(x, y)
```
如果想了解add_and_sum函數的性能,%prun可以給出下面內容:
```python
In [569]: %run prof_mod
In [570]: x = randn(3000, 3000)
In [571]: y = randn(3000, 3000)
In [572]: %prun add_and_sum(x, y)
4 function calls in 0.049 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.036 0.036 0.046 0.046 prof_mod.py:3(add_and_sum)
1 0.009 0.009 0.009 0.009 {method 'sum' of 'numpy.ndarray'}
1 0.003 0.003 0.049 0.049 <string>:1(<module>)
```
上面的做法啟發性不大。激活了IPython插件line_profiler,新的命令%lprun就能用了。使用中的不同點是,我們必須告訴%lprun要分析的函數是哪個。語法是:
```python
%lprun -f func1 -f func2 statement_to_profile
```
我們想分析add_and_sum,運行:
```python
In [573]: %lprun -f add_and_sum add_and_sum(x, y)
Timer unit: 1e-06 s
File: prof_mod.py
Function: add_and_sum at line 3
Total time: 0.045936 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
3 def add_and_sum(x, y):
4 1 36510 36510.0 79.5 added = x + y
5 1 9425 9425.0 20.5 summed = added.sum(axis=1)
6 1 1 1.0 0.0 return summed
```
這樣就容易詮釋了。我們分析了和代碼語句中一樣的函數。看之前的模塊代碼,我們可以調用call_function并對它和add_and_sum進行分析,得到一個完整的代碼性能概括:
```python
In [574]: %lprun -f add_and_sum -f call_function call_function()
Timer unit: 1e-06 s
File: prof_mod.py
Function: add_and_sum at line 3
Total time: 0.005526 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
3 def add_and_sum(x, y):
4 1 4375 4375.0 79.2 added = x + y
5 1 1149 1149.0 20.8 summed = added.sum(axis=1)
6 1 2 2.0 0.0 return summed
File: prof_mod.py
Function: call_function at line 8
Total time: 0.121016 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
8 def call_function():
9 1 57169 57169.0 47.2 x = randn(1000, 1000)
10 1 58304 58304.0 48.2 y = randn(1000, 1000)
11 1 5543 5543.0 4.6 return add_and_sum(x, y)
```
我的經驗是用%prun (cProfile)進行宏觀分析,%lprun (line_profiler)做微觀分析。最好對這兩個工具都了解清楚。
>筆記:使用%lprun必須要指明函數名的原因是追蹤每行的執行時間的損耗過多。追蹤無用的函數會顯著地改變結果。
# B.4 使用IPython高效開發的技巧
方便快捷地寫代碼、調試和使用是每個人的目標。除了代碼風格,流程細節(比如代碼重載)也需要一些調整。
因此,這一節的內容更像是門藝術而不是科學,還需要你不斷的試驗,以達成高效。最終,你要能結構優化代碼,并且能省時省力地檢查程序或函數的結果。我發現用IPython設計的軟件比起命令行,要更適合工作。尤其是當發生錯誤時,你需要檢查自己或別人寫的數月或數年前寫的代碼的錯誤。
## 重載模塊依賴
在Python中,當你輸入import some_lib,some_lib中的代碼就會被執行,所有的變量、函數和定義的引入,就會被存入到新創建的some_lib模塊命名空間。當下一次輸入some_lib,就會得到一個已存在的模塊命名空間的引用。潛在的問題是當你%run一個腳本,它依賴于另一個模塊,而這個模塊做過修改,就會產生問題。假設我在test_script.py中有如下代碼:
```python
import some_lib
x = 5
y = [1, 2, 3, 4]
result = some_lib.get_answer(x, y)
```
如果你運行過了%run test_script.py,然后修改了some_lib.py,下一次再執行%run test_script.py,還會得到舊版本的some_lib.py,這是因為Python模塊系統的“一次加載”機制。這一點區分了Python和其它數據分析環境,比如MATLAB,它會自動傳播代碼修改。解決這個問題,有多種方法。第一種是在標準庫importlib模塊中使用reload函數:
```python
import some_lib
import importlib
importlib.reload(some_lib)
```
這可以保證每次運行test_script.py時可以加載最新的some_lib.py。很明顯,如果依賴更深,在各處都使用reload是非常麻煩的。對于這個問題,IPython有一個特殊的dreload函數(它不是魔術函數)重載深層的模塊。如果我運行過some_lib.py,然后輸入dreload(some_lib),就會嘗試重載some_lib和它的依賴。不過,這個方法不適用于所有場景,但比重啟IPython強多了。
## 代碼設計技巧
對于這單,沒有簡單的對策,但是有一些原則,是我在工作中發現很好用的。
## 保持相關對象和數據活躍
為命令行寫一個下面示例中的程序是很少見的:
```python
from my_functions import g
def f(x, y):
return g(x + y)
def main():
x = 6
y = 7.5
result = x + y
if __name__ == '__main__':
main()
```
在IPython中運行這個程序會發生問題,你發現是什么了嗎?運行之后,任何定義在main函數中的結果和對象都不能在IPython中被訪問到。更好的方法是將main中的代碼直接在模塊的命名空間中執行(或者在``__name__ == '__main__':``中,如果你想讓這個模塊可以被引用)。這樣,當你%rundiamante,就可以查看所有定義在main中的變量。這等價于在Jupyter notebook的代碼格中定義一個頂級變量。
## 扁平優于嵌套
深層嵌套的代碼總讓我聯想到洋蔥皮。當測試或調試一個函數時,你需要剝多少層洋蔥皮才能到達目標代碼呢?“扁平優于嵌套”是Python之禪的一部分,它也適用于交互式代碼開發。盡量將函數和類去耦合和模塊化,有利于測試(如果你是在寫單元測試)、調試和交互式使用。
## 克服對大文件的恐懼
如果你之前是寫JAVA(或者其它類似的語言),你可能被告知要讓文件簡短。在多數語言中,這都是合理的建議:太長會讓人感覺是壞代碼,意味著重構和重組是必要的。但是,在用IPython開發時,運行10個相關聯的小文件(小于100行),比起兩個或三個長文件,會讓你更頭疼。更少的文件意味著重載更少的模塊和更少的編輯時在文件中跳轉。我發現維護大模塊,每個模塊都是緊密組織的,會更實用和Pythonic。經過方案迭代,有時會將大文件分解成小文件。
我不建議極端化這條建議,那樣會形成一個單獨的超大文件。找到一個合理和直觀的大型代碼模塊庫和封裝結構往往需要一點工作,但這在團隊工作中非常重要。每個模塊都應該結構緊密,并且應該能直觀地找到負責每個功能領域功能和類。
# B.5 IPython高級功能
要全面地使用IPython系統需要用另一種稍微不同的方式寫代碼,或深入IPython的配置。
## 讓類是對IPython友好的
IPython會盡可能地在控制臺美化展示每個字符串。對于許多對象,比如字典、列表和元組,內置的pprint模塊可以用來美化格式。但是,在用戶定義的類中,你必自己生成字符串。假設有一個下面的簡單的類:
```python
class Message:
def __init__(self, msg):
self.msg = msg
```
如果這么寫,就會發現默認的輸出不夠美觀:
```python
In [576]: x = Message('I have a secret')
In [577]: x
Out[577]: <__main__.Message instance at 0x60ebbd8>
```
IPython會接收__repr__魔術方法返回的字符串(通過output = repr(obj)),并在控制臺打印出來。因此,我們可以添加一個簡單的__repr__方法到前面的類中,以得到一個更有用的輸出:
```python
class Message:
def __init__(self, msg):
self.msg = msg
def __repr__(self):
return 'Message: %s' % self.msg
In [579]: x = Message('I have a secret')
In [580]: x
Out[580]: Message: I have a secret
```
## 文件和配置
通過擴展配置系統,大多數IPython和Jupyter notebook的外觀(顏色、提示符、行間距等等)和動作都是可以配置的。通過配置,你可以做到:
- 改變顏色主題
- 改變輸入和輸出提示符,或刪除輸出之后、輸入之前的空行
- 執行任意Python語句(例如,引入總是要使用的代碼或者每次加載IPython都要運行的內容)
- 啟用IPython總是要運行的插件,比如line_profiler中的%lprun魔術函數
- 啟用Jupyter插件
- 定義自己的魔術函數或系統別名
IPython的配置存儲在特殊的ipython_config.py文件中,它通常是在用戶home目錄的.ipython/文件夾中。配置是通過一個特殊文件。當你啟動IPython,就會默認加載這個存儲在profile_default文件夾中的默認文件。因此,在我的Linux系統,完整的IPython配置文件路徑是:
```python
/home/wesm/.ipython/profile_default/ipython_config.py
```
要啟動這個文件,運行下面的命令:
```python
ipython profile create
```
這個文件中的內容留給讀者自己探索。這個文件有注釋,解釋了每個配置選項的作用。另一點,可以有多個配置文件。假設你想要另一個IPython配置文件,專門是為另一個應用或項目的。創建一個新的配置文件很簡單,如下所示:
```python
ipython profile create secret_project
```
做完之后,在新創建的profile_secret_project目錄便捷配置文件,然后如下啟動IPython:
```python
$ ipython --profile=secret_project
Python 3.5.1 | packaged by conda-forge | (default, May 20 2016, 05:22:56)
Type "copyright", "credits" or "license" for more information.
IPython 5.1.0 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
IPython profile: secret_project
```
和之前一樣,IPython的文檔是一個極好的學習配置文件的資源。
配置Jupyter有些不同,因為你可以使用除了Python的其它語言。要創建一個類似的Jupyter配置文件,運行:
```python
jupyter notebook --generate-config
```
這樣會在home目錄的.jupyter/jupyter_notebook_config.py創建配置文件。編輯完之后,可以將它重命名:
```python
$ mv ~/.jupyter/jupyter_notebook_config.py ~/.jupyter/my_custom_config.py
```
打開Jupyter之后,你可以添加--config參數:
```python
jupyter notebook --config=~/.jupyter/my_custom_config.py
```
# B.6 總結
學習過本書中的代碼案例,你的Python技能得到了一定的提升,我建議你持續學習IPython和Jupyter。因為這兩個項目的設計初衷就是提高生產率的,你可能還會發現一些工具,可以讓你更便捷地使用Python和計算庫。
你可以在nbviewer(https://nbviewer.jupyter.org/)上找到更多有趣的Jupyter notebooks。
- 利用 Python 進行數據分析 · 第 2 版
- 第 1 章 準備工作
- 第 2 章 Python 語法基礎,IPython 和 Jupyter Notebooks
- 第 3 章 Python 的數據結構、函數和文件
- 第 4 章 NumPy 基礎:數組和矢量計算
- 第 5 章 pandas 入門
- 第 6 章 數據加載、存儲與文件格式
- 第 7 章 數據清洗和準備
- 第 8 章 數據規整:聚合、合并和重塑
- 第 9 章 繪圖和可視化
- 第 10 章 數據聚合與分組運算
- 第 11 章 時間序列
- 第 12 章 pandas 高級應用
- 第 13 章 Python 建模庫介紹
- 第 14 章 數據分析案例
- 附錄 A NumPy 高級應用
- 附錄 B 更多關于 IPython 的內容