# 第五章 雙鏈表
> 原文:[Chapter 5 Doubly-linked list](http://greenteapress.com/thinkdast/html/thinkdast006.html)
> 譯者:[飛龍](https://github.com/wizardforcel)
> 協議:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
> 自豪地采用[谷歌翻譯](https://translate.google.cn/)
本章回顧了上一個練習的結果,并介紹了`List`接口的另一個實現,即雙鏈表。
## 5.1 性能分析結果
在之前的練習中,我們使用了`Profiler.java`,運行`ArrayList`和`LinkedList`的各種操作,它們具有一系列的問題規模。我們將運行時間與問題規模繪制在重對數比例尺上,并估計所得曲線的斜率,它表示運行時間和問題規模之間的關系的主要指數。
例如,當我們使用`add`方法將元素添加到`ArrayList`的末尾,我們發現,執行`n`次添加的總時間正比于`n`。也就是說,估計的斜率接近`1`。我們得出結論,執行`n`次添加是 `O(n)`的,所以平均來說,單個添加的時間是常數時間,或者`O(1)`,基于算法分析,這是我們的預期。
這個練習要求你填充`profileArrayListAddBeginning`的主體,它測試了,在`ArrayList`頭部添加一個新的元素的性能。根據我們的分析,我們預計每個添加都是線性的,因為它必須將其他元素向右移動;所以我們預計,`n`次添加是平方復雜度。
這是一個解決方案,你可以在倉庫的`solution`目錄中找到它。
```java
public static void profileArrayListAddBeginning() {
Timeable timeable = new Timeable() {
List<String> list;
public void setup(int n) {
list = new ArrayList<String>();
}
public void timeMe(int n) {
for (int i=0; i<n; i++) {
list.add(0, "a string");
}
}
};
int startN = 4000;
int endMillis = 10000;
runProfiler("ArrayList add beginning", timeable, startN, endMillis);
}
```
這個方法幾乎和`profileArrayListAddEnd`相同。唯一的區別在于`timeMe`,它使用`add`的雙參數版本,將新元素置于下標`0`處。同樣,我們增加了`endMillis`,來獲取一個額外的數據點。
以下是時間結果(左側是問題規模,右側是運行時間,單位為毫秒):
```
4000, 14
8000, 35
16000, 150
32000, 604
64000, 2518
128000, 11555
```
圖 5.1 展示了運行時間和問題規模的圖形。
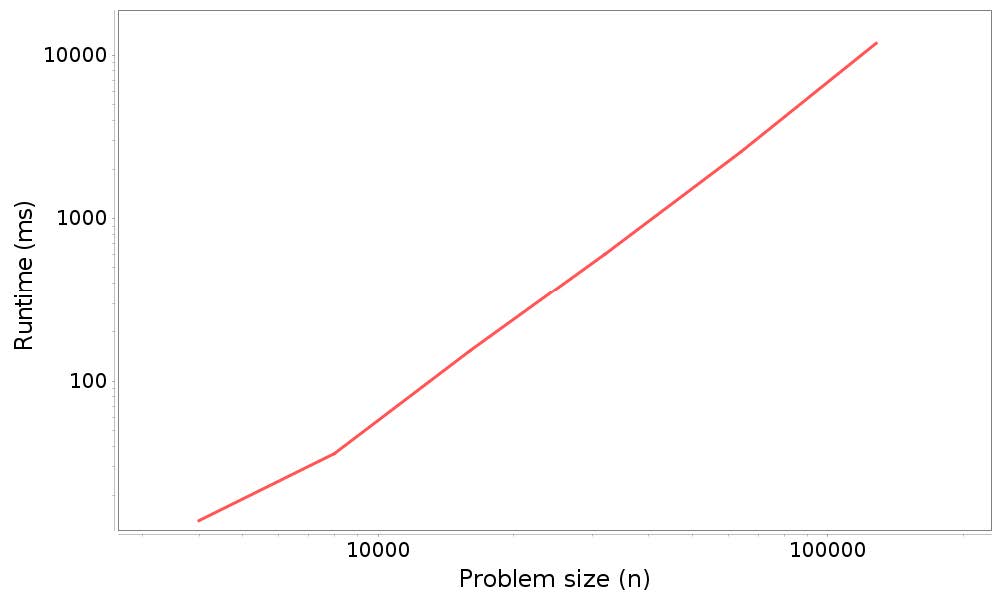
圖 5.1:分析結果:在`ArrayList`開頭添加`n`個元素的運行時間和問題規模
請記住,該圖上的直線并不意味著該算法是線性的。相反,如果對于任何指數`k`,運行時間與`n ** k`成正比,我們預計會看到斜率為`k`的直線。在這種情況下,我們預計,`n`次添加的總時間與`n ** 2`成正比,所以我們預計會有一條斜率為`2`的直線。實際上,估計的斜率是`1.992`,非常接近。恐怕假數據才能做得這么好。
## 5.2 分析`LinkedList`方法的性能
在以前的練習中,你還分析了,在`LinkedList`頭部添加新元素的性能。根據我們的分析,我們預計每個`add`都要花時間,因為在一個鏈表中,我們不必轉移現有元素;我們可以在頭部添加一個新節點。所以我們預計`n`次添加的總時間是線性的。
這是一個解決方案:
```java
public static void profileLinkedListAddBeginning() {
Timeable timeable = new Timeable() {
List<String> list;
public void setup(int n) {
list = new LinkedList<String>();
}
public void timeMe(int n) {
for (int i=0; i<n; i++) {
list.add(0, "a string");
}
}
};
int startN = 128000;
int endMillis = 2000;
runProfiler("LinkedList add beginning", timeable, startN, endMillis);
}
```
我們只做了一些修改,將`ArrayList`替換為`LinkedList`并調整`startN`和`endMillis`,來獲得良好的數據范圍。測量結果比上一批數據更加嘈雜;結果如下:
```
128000, 16
256000, 19
512000, 28
1024000, 77
2048000, 330
4096000, 892
8192000, 1047
16384000, 4755
```
圖 5.2 展示了這些結果的圖形。
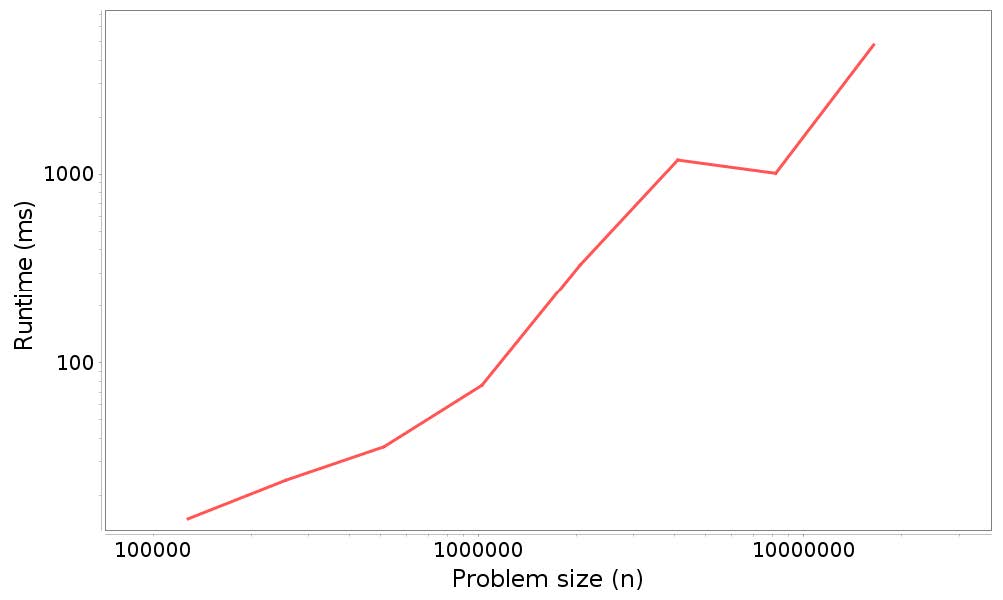
圖 5.2:分析結果:在`LinkedList`開頭添加`n`個元素的運行時間和問題規模
并不是一條很直的線,斜率也不是正好是`1`,最小二乘擬合的斜率是`1.23`。但是結果表示,`n`次添加的總時間至少近似于`O(n)`,所以每次添加都是常數時間。
## 5.3 `LinkedList`的尾部添加
在開頭添加元素是一種操作,我們期望`LinkedList`的速度快于`ArrayList`。但是為了在末尾添加元素,我們預計`LinkedList`會變慢。在我的實現中,我們必須遍歷整個列表來添加一個元素到最后,它是線性的。所以我們預計`n`次添加的總時間是二次的。
但是不是這樣。以下是代碼:
```
public static void profileLinkedListAddEnd() {
Timeable timeable = new Timeable() {
List<String> list;
public void setup(int n) {
list = new LinkedList<String>();
}
public void timeMe(int n) {
for (int i=0; i<n; i++) {
list.add("a string");
}
}
};
int startN = 64000;
int endMillis = 1000;
runProfiler("LinkedList add end", timeable, startN, endMillis);
}
```
這里是結果:
```
64000, 9
128000, 9
256000, 21
512000, 24
1024000, 78
2048000, 235
4096000, 851
8192000, 950
16384000, 6160
```
圖 5.3 展示了這些結果的圖形。
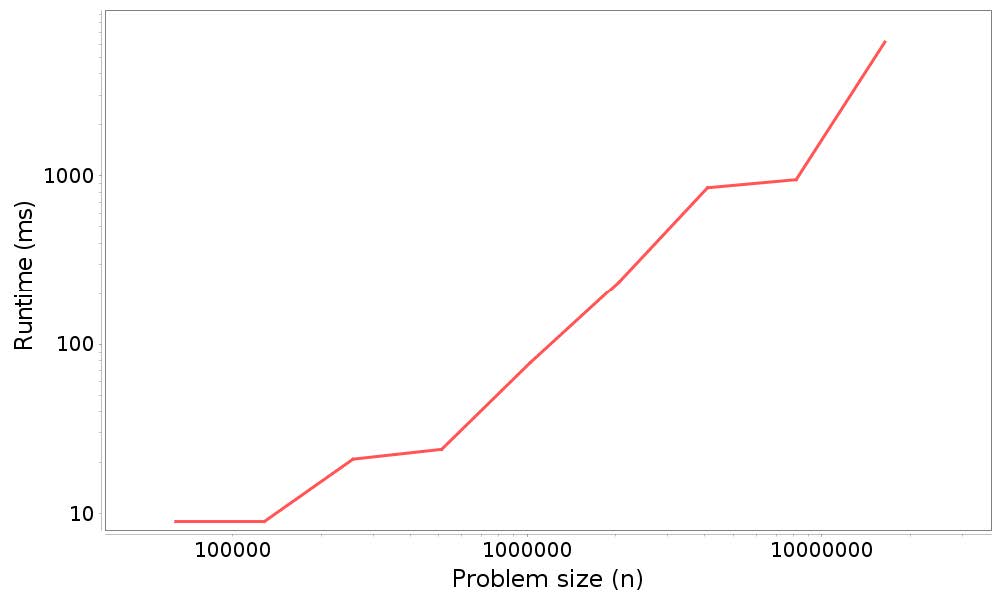
圖 5.2:分析結果:在`LinkedList`末尾添加`n`個元素的運行時間和問題規模
同樣,測量值很嘈雜,線不完全是直的,但估計的斜率為`1.19`,接近于在頭部添加元素,而并不非常接近`2`,這是我們根據分析的預期。事實上,它接近`1`,這表明在尾部添加元素是常數元素。這是怎么回事?
## 5.4 雙鏈表
我的鏈表實現`MyLinkedList`,使用單鏈表;也就是說,每個元素都包含下一個元素的鏈接,并且`MyArrayList`對象本身具有第一個節點的鏈接。
但是,如果你閱讀`LinkedList`的文檔,網址為 <http://thinkdast.com/linked>,它說:
> `List`和`Deque`接口的雙鏈表實現。[...] 所有的操作都能像雙向列表那樣執行。索引該列表中的操作將從頭或者尾遍歷列表,使用更接近指定索引的那個。
如果你不熟悉雙鏈表,你可以在 <http://thinkdast.com/doublelist> 上閱讀更多相關信息,但簡稱為:
+ 每個節點包含下一個節點的鏈接和上一個節點的鏈接。
+ `LinkedList`對象包含指向列表的第一個和最后一個元素的鏈接。
所以我們可以從列表的任意一端開始,并以任意方向遍歷它。因此,我們可以在常數時間內,在列表的頭部和末尾添加和刪除元素!
下表總結了`ArrayList`,`MyLinkedList`(單鏈表)和`LinkedList`(雙鏈表)的預期性能:
| | `MyArrayList` | `MyLinkedList` | `LinkedList` |
| --- | --- | --- | --- |
| `add`(尾部) | 1 | n | 1 |
| `add`(頭部) | n | 1 | 1 |
| `add`(一般) | n | n | n |
| `get`/`set` | 1 | n | n |
| `indexOf`/ `lastIndexOf` | n | n | n |
| `isEmpty`/`size` | 1 | 1 | 1 |
| `remove`(尾部) | 1 | n | 1 |
| `remove`(頭部) | n | 1 | 1 |
| `remove`(一般) | n | n | n |
## 5.5 結構的選擇
對于頭部插入和刪除,雙鏈表的實現優于`ArrayList`。對于尾部插入和刪除,都是一樣好。所以,`ArrayList`唯一優勢是`get`和`set`,鏈表中它需要線性時間,即使是雙鏈表。
如果你知道,你的應用程序的運行時間取決于`get`和`set`元素的所需時間,則`ArrayList`可能是更好的選擇。如果運行時間取決于在開頭或者末尾附加添加和刪除元素,`LinkedList`可能會更好。
但請記住,這些建議是基于大型問題的增長級別。還有其他因素要考慮:
+ 如果這些操作不占用你應用的大部分運行時間 - 也就是說,如果你的應用程序花費大部分時間來執行其他操作 - 那么你對`List`實現的選擇并不重要。
+ 如果你正在處理的列表不是很大,你可能無法獲得期望的性能。對于小型問題,二次算法可能比線性算法更快,或者線性可能比常數時間更快。而對于小型問題,差異可能并不重要。
+ 另外,別忘了空間。到目前為止,我們專注于運行時間,但不同的實現需要不同的空間。在`ArrayList`中,這些元素并排存儲在單個內存塊中,所以浪費的空間很少,并且計算機硬件通常在連續的塊上更快。在鏈表中,每個元素需要一個節點,帶有一個或兩個鏈接。鏈接占用空間(有時甚至超過數據!),并且節點分散在內存中,硬件效率可能不高。
總而言之,算法分析為數據結構的選擇提供了一些指南,但只有:
+ 你的應用的運行時間很重要,
+ 你的應用的運行時間取決于你選擇的數據結構,以及,
+ 問題的規模足夠大,增長級別實際上預測了哪個數據結構更好。
作為一名軟件工程師,在較長的職業生涯中,你幾乎不必考慮這種情況。
