# 第十一章 `HashMap`
> 原文:[Chapter 11 HashMap](http://greenteapress.com/thinkdast/html/thinkdast012.html)
> 譯者:[飛龍](https://github.com/wizardforcel)
> 協議:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
> 自豪地采用[谷歌翻譯](https://translate.google.cn/)
上一章中,我們寫了一個使用哈希的`Map`接口的實現。我們期望這個版本更快,因為它搜索的列表較短,但增長順序仍然是線性的。
如果存在`n`個條目和`k`個子映射,則子映射的大小平均為`n/k`,這仍然與`n`成正比。但是,如果我們與`n`一起增加`k`,我們可以限制`n/k`的大小。
例如,假設每次`n`超過`k`的時候,我們都使`k`加倍;在這種情況下,每個映射的條目的平均數量將小于`1`,并且幾乎總是小于`10`,只要散列函數能夠很好地展開鍵。
如果每個子映射的條目數是不變的,我們可以在常數時間內搜索一個子映射。并且計算散列函數通常是常數時間(它可能取決于鍵的大小,但不取決于鍵的數量)。這使得`Map`的核心方法, `put`和`get`時間不變。
在下一個練習中,你將看到細節。
## 11.1 練習 9
在`MyHashMap.java`中,我提供了哈希表的大綱,它會按需增長。這里是定義的起始:
```java
public class MyHashMap<K, V> extends MyBetterMap<K, V> implements Map<K, V> {
// average number of entries per sub-map before we rehash
private static final double FACTOR = 1.0;
@Override
public V put(K key, V value) {
V oldValue = super.put(key, value);
// check if the number of elements per sub-map exceeds the threshold
if (size() > maps.size() * FACTOR) {
rehash();
}
return oldValue;
}
}
```
`MyHashMap`擴展了`MyBetterMap`,所以它繼承了那里定義的方法。它覆蓋的唯一方法是`put`,它調用了超類中的`put` -- 也就是說,它調用了`MyBetterMap `中的`put`版本 -- 然后它檢查它是否必須`rehash`。調用`size`返回總數量`n`。調用`maps.size`返回內嵌映射的數量`k`。
常數`FACTOR`(稱為負載因子)確定每個子映射的平均最大條目數。如果`n > k * FACTOR`,這意味著`n/k > FACTOR`,意味著每個子映射的條目數超過閾值,所以我們調用`rehash`。
運行`ant build`來編譯源文件。然后運行`ant MyHashMapTest`。它應該失敗,因為執行`rehash`會拋出異常。你的工作是填充它。
填充`rehash`的主體,來收集表中的條目,調整表的大小,然后重新放入條目。我提供了兩種可能會派上用場的方法:`MyBetterMap.makeMaps`和`MyLinearMap.getEntries`。每次調用它時,你的解決方案應該使映射數量加倍。
## 11.2 分析`MyHashMap`
如果最大子映射中的條目數與`n/k`成正比,并且`k`與`n`成正比,那么多個核心方法就是常數時間的:
```java
public boolean containsKey(Object target){
MyLinearMap <K,V> map = chooseMap(target);
return map.containsKey(target);
}
public V get(Object key){
MyLinearMap <K,V> map = chooseMap(key); return map.get(key);
}
public V remove(Object key){
MyLinearMap <K,V> map = chooseMap(key);
return map.remove(key);
}
```
每個方法都計算鍵的哈希,這是常數時間,然后在一個子映射上調用一個方法,這個方法是常數時間的。
到現在為止還挺好。但另一個核心方法,`put`有點難分析。當我們不需要`rehash`時,它是不變的時間,但是當我們這樣做時,它是線性的。這樣,它與 3.2 節中我們分析的`ArrayList.add`類似。
出于同樣的原因,如果我們平攤一系列的調用,結果是常數時間。同樣,論證基于攤銷分析(見 3.2 節)。
假設子映射的初始數量`k`為`2`,負載因子為`1`。現在我們來看看`put`一系列的鍵需要多少工作量。作為基本的“工作單位”,我們將計算對密鑰哈希,并將其添加到子映射中的次數。
我們第一次調用`put`時,它需要`1`個工作單位。第二次也需要`1`個單位。第三次我們需要`rehash`,所以需要`2`個單位重新填充現有的鍵,和`1`個單位來對新鍵哈希。
> 譯者注:可以單獨計算`rehash`中轉移元素的數量,然后將元素轉移的復雜度和計算哈希的復雜度相加。
現在哈希表的大小是`4`,所以下次調用`put`時 ,需要`1`個工作單位。但是下一次我們必須`rehash`,需要`4`個單位來`rehash`現有的鍵,和`1`個單位來對新鍵哈希。
圖 11.1 展示了規律,對新鍵哈希的正常工作量在底部展示,額外工作量展示為塔樓。
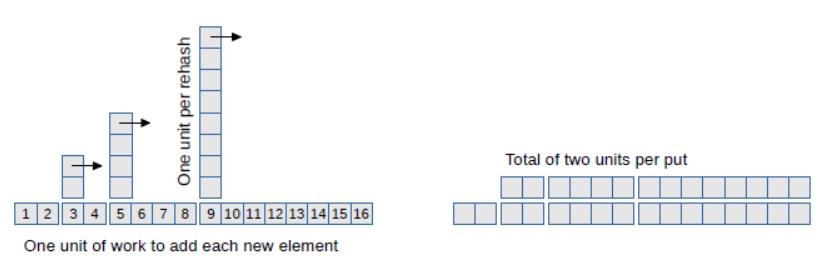
圖 11.1:向哈希表添加元素的工作量展示
如箭頭所示,如果我們把塔樓推倒,每個積木都會在下一個塔樓之前填滿空間。結果似乎`2`個單位的均勻高度,這表明`put`的平均工作量約為`2`個單位。這意味著`put`平均是常數時間。
這個圖還顯示了,當我們`rehash`的時候,為什么加倍子映射數量`k`很重要。如果我們只是加上`k`而不是加倍,那么這些塔樓會靠的太近,他們會開始堆積。這樣就不會是常數時間了。
## 11.3 權衡
我們已經表明,`containsKey`,`get`和`remove`是常數時間,`put`平均為常數時間。我們應該花一點時間來欣賞它有多么出色。無論哈希表有多大,這些操作的性能幾乎相同。算是這樣吧。
記住,我們的分析基于一個簡單的計算模型,其中每個“工作單位”花費相同的時間量。真正的電腦比這更復雜。特別是,當處理足夠小,適應高速緩存的數據結構時,它們通常最快;如果結構不適合高速緩存但仍適合內存,則稍慢一點;如果結構不適合在內存中,則非常慢。
這個實現的另一個限制是,如果我們得到了一個值而不是一個鍵時,那么散列是不會有幫助的:`containsValue`是線性的,因為它必須搜索所有的子映射。查找一個值并找到相應的鍵(或可能的鍵),沒有特別有效的方式。
還有一個限制:`MyLinearMap`的一些常數時間的方法變成了線性的。例如:
```java
public void clear() {
for (int i=0; i<maps.size(); i++) {
maps.get(i).clear();
}
}
```
`clear`必須清除所有的子映射,子映射的數量與`n`成正比,所以它是線性的。幸運的是,這個操作并不常用,所以在大多數應用中,這種權衡是可以接受的。
## 11.4 分析`MyHashMap`
在我們繼續之前,我們應該檢查一下,`MyHashMap.put`是否真的是常數時間。
運行`ant build`來編譯源文件。然后運行`ant ProfileMapPut`。它使用一系列問題規模,測量 `HashMap.put`(由 Java 提供)的運行時間,并在重對數比例尺上繪制運行時間與問題規模。如果這個操作是常數時間,`n`個操作的總時間應該是線性的,所以結果應該是斜率為`1`的直線。當我運行這個代碼時,估計的斜率接近`1`,這與我們的分析一致。你應該得到類似的東西。
修改`ProfileMapPut.java`,來測量你的`MyHashMap`實現,而不是 Java 的`HashMap`。再次運行分析器,查看斜率是否接近`1`。你可能需要調整`startN`和`endMillis`,來找到一系列問題規模,其中運行時間多于幾毫秒,但不超過幾秒。
當我運行這個代碼時,我感到驚訝:斜率大約為`1.7`,這表明這個實現不是一直都是常數的。它包含一個“性能錯誤”。
在閱讀下一節之前,你應該跟蹤錯誤,修復錯誤,并確認現在`put`是常數時間,符合預期。
## 11.5 修復`MyHashMap`
`MyHashMap`的問題是`size`,它繼承自`MyBetterMap`:
```java
public int size() {
int total = 0;
for (MyLinearMap<K, V> map: maps) {
total += map.size();
}
return total;
}
```
為了累計整個大小,它必須迭代子映射。由于我們增加了子映射的數量`k`,隨著條目數`n`增加,所以`k`與`n`成正比,所以`size`是線性的。
`put`也是線性的,因為它使用`size`:
```java
public V put(K key, V value) {
V oldValue = super.put(key, value);
if (size() > maps.size() * FACTOR) {
rehash();
}
return oldValue;
}
```
如果`size`是線性的,我們做的一切都浪費了。
幸運的是,有一個簡單的解決方案,我們以前看過:我們必須維護實例變量中的條目數,并且每當我們調用一個改變它的方法時更新它。
你會在這本書的倉庫中找到我的解決方案`MyFixedHashMap.java`。這是類定義的起始:
```java
public class MyFixedHashMap<K, V> extends MyHashMap<K, V> implements Map<K, V> {
private int size = 0;
public void clear() {
super.clear();
size = 0;
}
```
我們不修改`MyHashMap`,我定義一個擴展它的新類。它添加一個新的實例變量`size`,它被初始化為零。
更新`clear`很簡單; 我們在超類中調用`clear`(清除子映射),然后更新`size`。
更新`remove`和`put`有點困難,因為當我們調用超類的該方法,我們不能得知子映射的大小是否改變。這是我的解決方式:
```java
public V remove(Object key) {
MyLinearMap<K, V> map = chooseMap(key);
size -= map.size();
V oldValue = map.remove(key);
size += map.size();
return oldValue;
}
```
`remove`使用`chooseMap`找到正確的子映射,然后減去子映射的大小。它會在子映射上調用`remove`,根據是否找到了鍵,它可以改變子映射的大小,也可能不會改變它的大小。但是無論哪種方式,我們將子映射的新大小加到`size`,所以最終的`size`值是正確的。
重寫的`put`版本是類似的:
```java
public V put(K key, V value) {
MyLinearMap<K, V> map = chooseMap(key);
size -= map.size();
V oldValue = map.put(key, value);
size += map.size();
if (size() > maps.size() * FACTOR) {
size = 0;
rehash();
}
return oldValue;
}
```
我們在這里也有同樣的問題:當我們在子地圖上調用`put`時,我們不知道是否添加了一個新的條目。所以我們使用相同的解決方案,減去舊的大小,然后加上新的大小。
現在`size`方法的實現很簡單了:
```java
public int size() {
return size;
}
```
并且正好是常數時間。
當我測量這個解決方案時,我發現放入`n`個鍵的總時間正比于`n`,也就是說,每個`put`是常數時間的,符合預期。
## 11.6 UML 類圖
在本章中使用代碼的一個挑戰是,我們有幾個互相依賴的類。以下是類之間的一些關系:
+ `MyLinearMap`包含一個`LinkedList`并實現了`Map`。
+ `MyBetterMap`包含許多`MyLinearMap`對象并實現了`Map`。
+ `MyHashMap`擴展了`MyBetterMap`,所以它也包含`MyLinearMap對象`,并實現了`Map`。
+ `MyFixedHashMap`擴展了`MyHashMap`并實現了`Map`。
為了有助于跟蹤這些關系,軟件工程師經常使用 UML 類圖。UML 代表統一建模語言(見 <http://thinkdast.com/uml> )。“類圖”是由 UML 定義的幾種圖形標準之一。
在類圖中,每個類由一個框表示,類之間的關系由箭頭表示。圖 11.2 顯示了使用在線工具 yUML(<http://yuml.me/>)生成的,上一個練習的 UML 類圖。

圖11.2:本章中的 UML 類圖
不同的關系由不同的箭頭表示:
+ 實心箭頭表示 HAS-A 關系。例如,每個`MyBetterMap`實例包含多個`MyLinearMap`實例,因此它們通過實線箭頭連接。
+ 空心和實線箭頭表示 IS-A 關系。例如,`MyHashMap`擴展 了`MyBetterMap`,因此它們通過 IS-A 箭頭連接。
+ 空心和虛線箭頭表示一個類實現了一個接口;在這個圖中,每個類都實現 `Map`。
UML 類圖提供了一種簡潔的方式,來表示大量類集合的信息。在設計階段中,它們用于交流備選設計,在實施階段中,用于維護項目的共享思維導圖,并在部署過程中記錄設計。
