# 第八章 索引器
> 原文:[Chapter 8 Indexer](http://greenteapress.com/thinkdast/html/thinkdast009.html)
> 譯者:[飛龍](https://github.com/wizardforcel)
> 協議:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
> 自豪地采用[谷歌翻譯](https://translate.google.cn/)
目前,我們構建了一個基本的 Web 爬蟲;我們下一步將是索引。在網頁搜索的上下文中,索引是一種數據結構,可以查找檢索詞并找到該詞出現的頁面。此外,我們想知道每個頁面上顯示檢索詞的次數,這將有助于確定與該詞最相關的頁面。
例如,如果用戶提交檢索詞“Java”和“編程”,我們將查找兩個檢索詞并獲得兩組頁面。帶有“Java”的頁面將包括 Java 島嶼,咖啡昵稱以及編程語言的網頁。具有“編程”一詞的頁面將包括不同編程語言的頁面,以及該單詞的其他用途。通過選擇具有兩個檢索詞的頁面,我們希望消除不相關的頁面,并找到 Java 編程的頁面。
現在我們了解索引是什么,它執行什么操作,我們可以設計一個數據結構來表示它。
## 8.1 數據結構選取
索引的基本操作是查找;具體來說,我們需要能夠查找檢索詞并找到包含它的所有頁面。最簡單的實現將是頁面的集合。給定一個檢索詞,我們可以遍歷頁面的內容,并選擇包含檢索詞的內容。但運行時間與所有頁面上的總字數成正比,這太慢了。
一個更好的選擇是一個映射(字典),它是一個數據結構,表示鍵值對的集合,并提供了一種方法,快速查找鍵以及相應值。例如,我們將要構建的第一個映射是`TermCounter`,它將每個檢索詞映射為頁面中出現的次數。鍵是檢索詞,值是計數(也稱為“頻率”)。
Java 提供了`Map`的調用接口,它指定映射應該提供的方法;最重要的是:
+ `get(key)`:此方法查找一個鍵并返回相應的值。
+ `put(key, value)`:該方法向`Map`添加一個新的鍵值對,或者如果該鍵已經在映射中,它將替換與`key`關聯的值。
Java 提供了幾個`Map`實現,包括我們將關注的兩個,`HashMap`以及`TreeMap`。在即將到來的章節中,我們將介紹這些實現并分析其性能。
除了檢索詞到計數的映射`TermCounter`之外,我們將定義一個被稱為`Index`的類,它將檢索詞映射為出現的頁面的集合。而這又引發了下一個問題,即如何表示頁面集合。同樣,如果我們考慮我們想要執行的操作,它們就指導了我們的決定。
在這種情況下,我們需要組合兩個或多個集合,并找到所有這些集合中顯示的頁面。你可以將此操作看做集合的交集:兩個集合的交集是出現在兩者中的一組元素。
你可能猜到了,Java 提供了一個`Set`接口,來定義集合應該執行的操作。它實際上并不提供設置交集,但它提供了方法,使我們能夠有??效地實現交集和其他結合操作。核心的`Set`方法是:
+ `add(element)`:該方法將一個元素添加到集合中;如果元素已經在集合中,則它不起作用。
+ `contains(element)`:該方法檢查給定元素是否在集合中。
Java 提供了幾個`Set`實現,包括`HashSet`和`TreeSet`。
現在我們自頂向下設計了我們的數據結構,我們將從內到外實現它們,從`TermCounter`開始。
## 8.2 `TermCounter`
`TermCounter`是一個類,表示檢索詞到頁面中出現次數的映射。這是類定義的第一部分:
```java
public class TermCounter {
private Map<String, Integer> map;
private String label;
public TermCounter(String label) {
this.label = label;
this.map = new HashMap<String, Integer>();
}
}
```
實例變量`map`包含檢索詞到計數的映射,并且`label`標識檢索詞的來源文檔;我們將使用它來存儲 URL。
為了實現映射,我選擇了`HashMap`,它是最常用的`Map`。在幾章中,你將看到它是如何工作的,以及為什么它是一個常見的選擇。
`TermCounter`提供`put`和`get`,定義如下:
```java
public void put(String term, int count) {
map.put(term, count);
}
public Integer get(String term) {
Integer count = map.get(term);
return count == null ? 0 : count;
}
```
`put`只是一個包裝方法;當你調用`TermCounter`的`put`時,它會調用內嵌映射的`put`。
另一方面,`get`做了一些實際工作。當你調用`TermCounter`的`get`時,它會在映射上調用`get`,然后檢查結果。如果該檢索詞沒有出現在映射中,則`TermCount.get`返回`0`。`get`的這種定義方式使`incrementTermCount`的寫入更容易,它需要一個檢索詞,并增加關聯該檢索詞的計數器。
```java
public void incrementTermCount(String term) {
put(term, get(term) + 1);
}
```
如果這個檢索詞未見過,則`get`返回`0`;我們設為`1`,然后使用`put`向映射添加一個新的鍵值對。如果該檢索詞已經在映射中,我們得到舊的計數,增加`1`,然后存儲新的計數,替換舊的值。
此外,`TermCounter`還提供了這些其他方法,來幫助索引網頁:
```java
public void processElements(Elements paragraphs) {
for (Node node: paragraphs) {
processTree(node);
}
}
public void processTree(Node root) {
for (Node node: new WikiNodeIterable(root)) {
if (node instanceof TextNode) {
processText(((TextNode) node).text());
}
}
}
public void processText(String text) {
String[] array = text.replaceAll("\\pP", " ").
toLowerCase().
split("\\s+");
for (int i=0; i<array.length; i++) {
String term = array[i];
incrementTermCount(term);
}
}
```
最后,這里是一個例子,展示了如何使用`TermCounter`:
```java
String url = "http://en.wikipedia.org/wiki/Java_(programming_language)";
WikiFetcher wf = new WikiFetcher();
Elements paragraphs = wf.fetchWikipedia(url);
TermCounter counter = new TermCounter(url);
counter.processElements(paragraphs);
counter.printCounts();
```
這個示例使用了`WikiFetcher`從維基百科下載頁面,并解析正文。之后它創建了`TermCounter`并使用它來計數頁面上的單詞。
下一節中,你會擁有一個挑戰,來運行這個代碼,并通過填充缺失的方法來測試你的理解。
## 8.3 練習 6
在本書的存儲庫中,你將找到此練習的源文件:
+ `TermCounter.java`包含上一節中的代碼。
+ `TermCounterTest.java`包含測試代碼`TermCounter.java`。
+ `Index.java`包含本練習下一部分的類定義。
+ `WikiFetcher.java`包含我們在上一個練習中使用的,用于下載和解析網頁的類。
+ `WikiNodeIterable.java`包含我們用于遍歷 DOM 樹中的節點的類。
你還會發現 Ant 構建文件`build.xml`。
運行`ant build`來編譯源文件。然后運行`ant TermCounter`;它應該運行上一節中的代碼,并打印一個檢索詞列表及其計數。輸出應該是這樣的:
```
genericservlet, 2
configurations, 1
claimed, 1
servletresponse, 2
occur, 2
Total of all counts = -1
```
運行它時,檢索詞的順序可能不同。
最后一行應該打印檢索詞計數的總和,但是由于方法`size`不完整而返回`-1`。填充此方法并`ant TermCounter`重新運行。結果應該是`4798`。
運行`ant TermCounterTest`來確認這部分練習是否完整和正確。
對于練習的第二部分,我將介紹`Index`對象的實現,你將填充一個缺失的方法。這是類定義的開始:
```java
public class Index {
private Map<String, Set<TermCounter>> index =
new HashMap<String, Set<TermCounter>>();
public void add(String term, TermCounter tc) {
Set<TermCounter> set = get(term);
// if we're seeing a term for the first time, make a new Set
if (set == null) {
set = new HashSet<TermCounter>();
index.put(term, set);
}
// otherwise we can modify an existing Set
set.add(tc);
}
public Set<TermCounter> get(String term) {
return index.get(term);
}
```
實例變量`index`是每個檢索詞到一組`TermCounter`對象的映射。每個`TermCounter`表示檢索詞出現的頁面。
`add`方法向集合添加新的`TermCounter`,它與檢索詞關聯。當我們索引一個尚未出現的檢索詞時,我們必須創建一個新的集合。否則我們可以添加一個新的元素到一個現有的集合。在這種情況下,`set.add`修改位于`index`里面的集合,但不會修改`index`本身。我們唯一修改`index`的時候是添加一個新的檢索詞。
最后,`get`方法接受檢索詞并返回相應的`TermCounter`對象集。
這種數據結構比較復雜。回顧一下,`Index`包含`Map`,將每個檢索詞映射到`TermCounter`對象的`Set`,每個`TermCounter`包含一個`Map`,將檢索詞映射到計數。
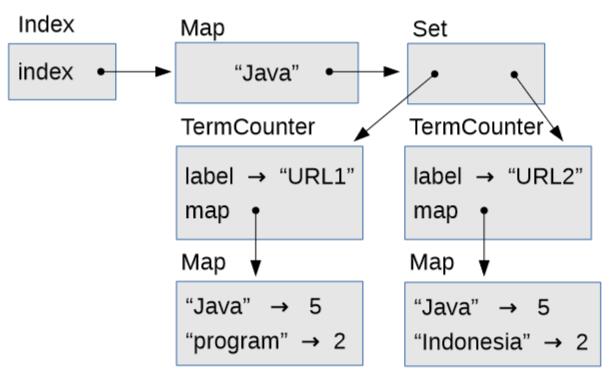
圖 8.1 `Index`的對象圖
圖 8.1 是展示這些對象的對象圖。`Index`對象具有一個名為`index` 的`Map`實例變量。在這個例子中,`Map`只包含一個字符串,`"Java"`,它映射到一個`Set`,包含兩個`TermCounter`對象的,代表每個出現單詞“Java”的頁面。
每個`TermCounter`包含`label`,它是頁面的 URL,以及`map`,它是`Map`,包含頁面上的單詞和每個單詞出現的次數。
`printIndex`方法展示了如何解壓縮此數據結構:
```java
public void printIndex() {
// loop through the search terms
for (String term: keySet()) {
System.out.println(term);
// for each term, print pages where it appears and frequencies
Set<TermCounter> tcs = get(term);
for (TermCounter tc: tcs) {
Integer count = tc.get(term);
System.out.println(" " + tc.getLabel() + " " + count);
}
}
}
```
外層循環遍歷檢索詞。內層循環迭代`TermCounter`對象。
運行`ant build`來確保你的源代碼已編譯,然后運行`ant Index`。它下載兩個維基百科頁面,對它們進行索引,并打印結果;但是當你運行它時,你將看不到任何輸出,因為我們已經將其中一個方法留空。
你的工作是填寫`indexPage`,它需要一個 URL(一個`String`)和一個`Elements`對象,并更新索引。下面的注釋描述了應該做什么:
```java
public void indexPage(String url, Elements paragraphs) {
// 生成一個 TermCounter 并統計段落中的檢索詞
// 對于 TermCounter 中的每個檢索詞,將 TermCounter 添加到索引
}
```
它能工作之后,再次運行`ant Index`,你應該看到如下輸出:
```java
...
configurations
http://en.wikipedia.org/wiki/Programming_language 1
http://en.wikipedia.org/wiki/Java_(programming_language) 1
claimed
http://en.wikipedia.org/wiki/Java_(programming_language) 1
servletresponse
http://en.wikipedia.org/wiki/Java_(programming_language) 2
occur
http://en.wikipedia.org/wiki/Java_(programming_language) 2
```
當你運行的時候,檢索詞的順序可能有所不同。
同樣,運行`ant TestIndex`來確定完成了這部分練習。
