
我來嘗試寫篇文章,讓您“一次性的”入門機器學習。從神經網絡入手到深度學習基礎為止,您就不用再閱讀別的教材了。換個網紅通用說法就是:如果看了俺的文章……您還不會機器學習,甚至不會編程的話……
就來掐死俺吧。
(哈哈)
首先講一下:
BP(Back Propagation)神經網絡,后面簡稱“bp網絡”與 其它模型 比如 M-P模型的區別:
M-P模型,它實際上就是對單個神經元的一種建模,還不足以模擬人腦神經系統的功能。由這些人工神經元構建出來的網絡,才能夠具有學習、聯想、記憶和模式識別的能力。BP網絡就是一種簡單的人工神經網絡。
我來介紹一下一種非常常見的神經網絡模型——反向傳播(Back Propagation)神經網絡。
概述
BP(Back Propagation)神經網絡是1986年由Rumelhart和McCelland為首的科研小組提出,參見他們發表在Nature上的論文 [Learning representations by back-propagating errors](http://www.cs.toronto.edu/~hinton/absps/naturebp.pdf) 。
BP神經網絡是一種按誤差逆傳播算法訓練的多層前饋網絡,是目前應用最廣泛的神經網絡模型之一。BP網絡能學習和存貯大量的 輸入-輸出模式映射關系,而無需事前揭示描述這種映射關系的數學方程。它的學習規則是使用最速下降法,通過反向傳播來不斷 調整網絡的權值和閾值,使網絡的誤差平方和最小。
BP算法的基本思想
多層感知器在如何獲取隱層的權值的問題上遇到了瓶頸。既然我們無法直接得到隱層的權值,能否先通過輸出層得到輸出結果和期望輸出的誤差來間接調整隱層的權值呢?BP算法就是采用這樣的思想設計出來的算法,它的基本思想是,學習過程由信號的正向傳播與誤差的反向傳播兩個過程組成。
正向傳播時,輸入樣本從輸入層傳入,經各隱層逐層處理后,傳向輸出層。若輸出層的實際輸出與期望的輸出(教師信號)不符,則轉入誤差的反向傳播階段。
反向傳播時,將輸出以某種形式通過隱層向輸入層逐層反傳,并將誤差分攤給各層的所有單元,從而獲得各層單元的誤差信號,此誤差信號即作為修正各單元權值的依據。
這兩個過程的具體流程會在后面介紹。
懶得畫圖,所以截個(Ian Goodfellow的《深度學習》)教材的圖片上來:
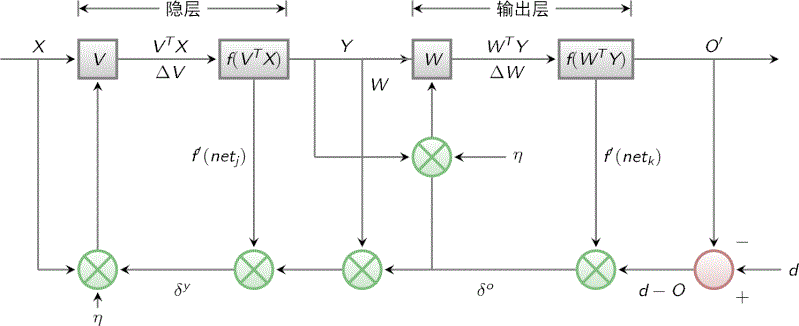
BP算法的信號流向圖如下圖所示:
BP網絡特性分析——BP三要素
我們分析一個ANN時,通常都是從它的三要素入手,即
1)網絡拓撲結構;
2)傳遞函數(又稱 “激活函數”、“激勵函數”都是它* neural network 的激活函數:
* [激活函數](https://fanyi.baidu.com/#zh/en/%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0)activation function)of Neural Network;
3)學習算法。
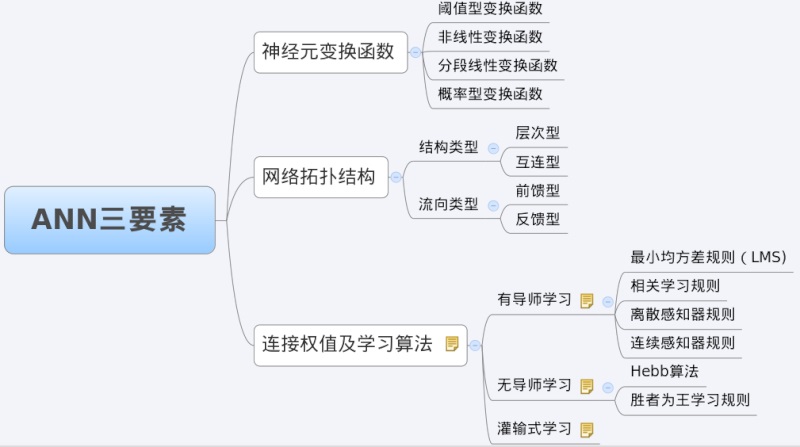
每一個要素的特性加起來就決定了這個ANN的功能特性。所以,我們也從這三要素入手對BP網絡的研究。
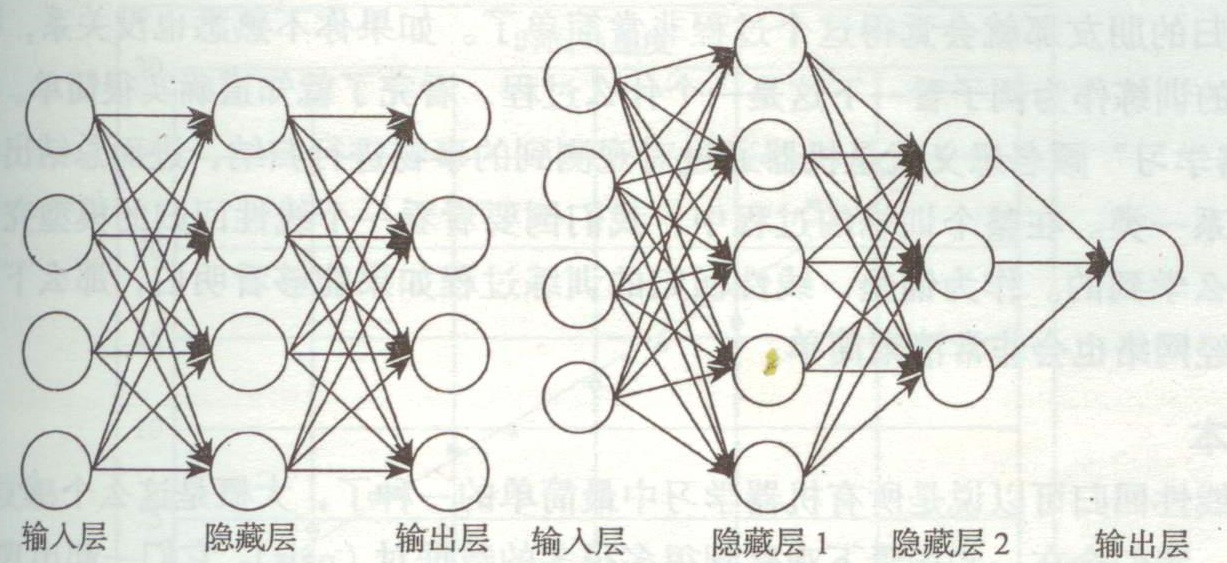
3.1 BP網絡的拓撲結構
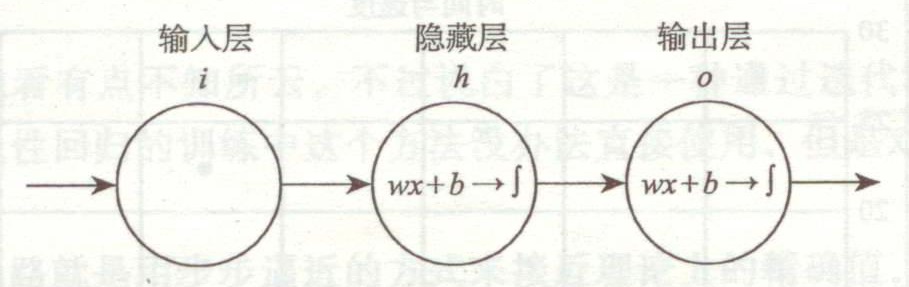
上一次已經說了,BP網絡實際上就是多層感知器,因此它的拓撲結構和多層感知器的拓撲結構相同。由于單隱層(三層)感知器已經能夠解決簡單的非線性問題,因此應用最為普遍。三層感知器的拓撲結構如下圖所示。
3.2 BP網絡的傳遞函數
BP網絡采用的傳遞函數是非線性變換函數——Sigmoid函數(又稱S函數)。其特點是函數本身及其導數都是連續的,因而在處理上十分方便。為什么要選擇這個函數,等下在介紹BP網絡的學習算法的時候會進行進一步的介紹。
單極性S型函數曲線如下圖所示。
f(x)=1/1+e^(?x)
C語言寫成:
f(x)= 1/ 1+ exp(-0.1*x);
*又如(雙極性S型函數曲線如下:
f(x)=1?e?x1+e?x )
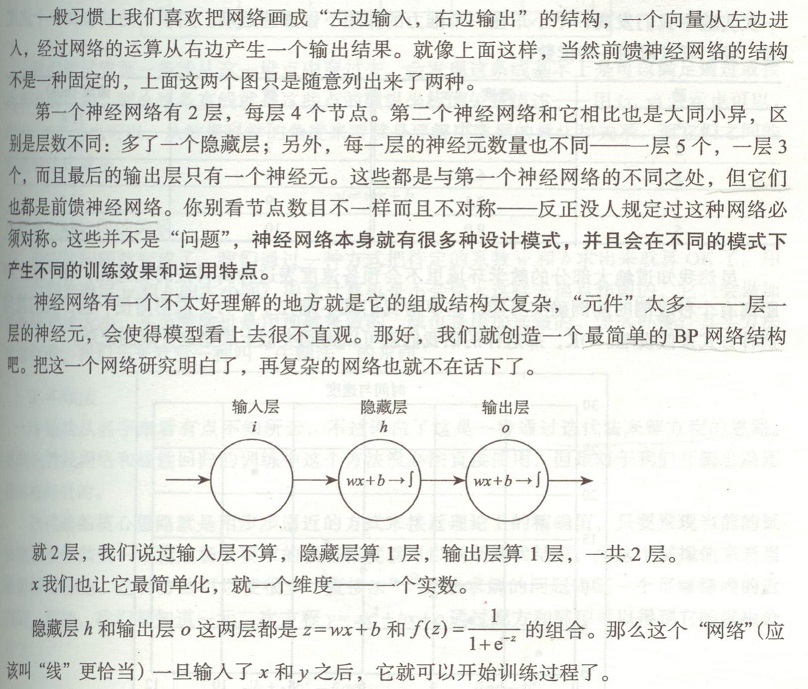
3.3 BP網絡的學習算法
BP網絡的學習算法就是BP算法,又叫 δ 算法(在ANN的學習過程中我們會發現不少具有多個名稱的術語), 以三層感知器為例,當網絡輸出與期望輸出不等時,存在輸出誤差 E ,定義如下
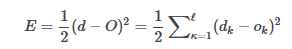
E=12(d?O)2=12∑?κ=1(dk?ok)2
將以上誤差定義式展開至隱層,有
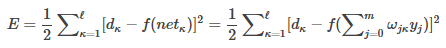
E=12∑?κ=1[dκ?f(netκ)]2=12∑?κ=1[dκ?f(∑mj=0ωjκyj)]2
進一步展開至輸入層,有
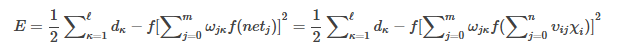
E=12∑?κ=1dκ?f[∑mj=0ωjκf(netj)]2=12∑?κ=1dκ?f[∑mj=0ωjκf(∑nj=0υijχi)]2
由上式可以看出,網絡輸入誤差是各層權值ωjκ
、υij的函數,因此調整權值可改變誤差 E
。 顯然,調整權值的原則是使誤差不斷減小,因此應使權值與誤差的梯度下降成正比,即
Δωjκ=?η?E?ωjκj=0,1,2,…,m;κ=1,2,…,?
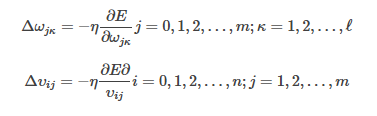
Δυij=?η?E?υiji=0,1,2,…,n;j=1,2,…,m

(有看官可能會問,你這是不是抄教材)……呵呵,人家定義如此,誰能寫出別的新花樣呢?
容易看出,BP學習算法中,各層權值調整公式形式上都是一樣的,均由3個因素決定,即:
1、學習率 η
2、本層輸出的誤差信號δ
3、本層輸入信號 Y(或X)
其中輸入層誤差信號與網絡的期望輸出與實際輸出之差有關,直接反應了輸出誤差,而各隱層的誤差信號與前面各層的誤差信號有關,是從輸出層開始逐層反傳過來的。
可以看出BP算法屬于δ學習規則類,這類算法常被稱為誤差的梯度下降算法。δ學習規則可以看成是Widrow-Hoff(LMS)學習規則的一般化(generalize)情況。LMS學習規則與神經元采用的變換函數無關,因而不需要對變換函數求導,δ學習規則則沒有這個性質,要求變換函數可導。這就是為什么我們前面采用Sigmoid函數的原因。
下面我們會介紹BP網絡的學習訓練的具體過程。
BP網絡的訓練分解
訓練一個BP神經網絡,實際上就是調整網絡的權重和偏置這兩個參數,BP神經網絡的訓練過程分兩部分:
前向傳輸,逐層波浪式的傳遞輸出值;
逆向反饋,反向逐層調整權重和偏置;
我們先來看前向傳輸。
前向傳輸(Feed-Forward前向反饋)
在訓練網絡之前,我們需要隨機初始化權重和偏置,對每一個權重取[?1,1]
的一個隨機實數,每一個偏置取[0,1]
的一個隨機實數,之后就開始進行前向傳輸。
神經網絡的訓練是由多趟迭代完成的,每一趟迭代都使用訓練集的所有記錄,而每一次訓練網絡只使用一條記錄,抽象的描述如下:
while 終止條件未滿足:
for record:dataset:
trainModel(record)
首先設置輸入層的輸出值,假設屬性的個數為100,那我們就設置輸入層的神經單元個數為100,輸入層的結點Ni
為記錄第i維上的屬性值xi
。對輸入層的操作就這么簡單,之后的每層就要復雜一些了,除輸入層外,其他各層的輸入值是上一層輸入值按權重累加的結果值加上偏置,每個結點的輸出值等該結點的輸入值作變換
前向傳輸的輸出層的計算過程公式如下:
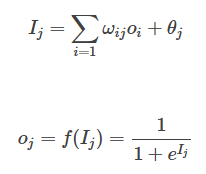
Ij=∑i=1ωijoi+θj
oj=f(Ij)=11+eIj
對隱藏層和輸出層的每一個結點都按照如上圖的方式計算輸出值,就完成前向傳播的過程,緊接著是進行逆向反饋。
逆向反饋(Backpropagation)
逆向反饋從最后一層即輸出層開始,我們訓練神經網絡作分類的目的往往是希望最后一層的輸出能夠描述數據記錄的類別,比如對于一個二分類的問題,我們常常用兩個神經單元作為輸出層,如果輸出層的第一個神經單元的輸出值比第二個神經單元大,我們認為這個數據記錄屬于第一類,否則屬于第二類。
還記得我們第一次前向反饋時,整個網絡的權重和偏置都是我們隨機取,因此網絡的輸出肯定還不能描述記錄的類別,因此需要調整網絡的參數,即權重值和偏置值,而調整的依據就是網絡的輸出層的輸出值與類別之間的差異,通過調整參數來縮小這個差異,這就是神經網絡的優化目標。對于輸出層:
Ej=Oj(1?Oj)(Tj?Oj)
其中Ej表示第j個結點的誤差值,Oj表示第j個結點的輸出值,Tj記錄輸出值,比如對于2分類問題,我們用01表示類標1,10表示類別2,如果一個記錄屬于類別1,那么其T1=0,T2=1。
中間的隱藏層并不直接與數據記錄的類別打交道,而是通過下一層的所有結點誤差按權重累加,計算公式如下:
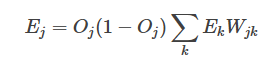
Ej=Oj(1?Oj)∑kEkWjk
其中Wjk表示當前層的結點j到下一層的結點k的權重值,Ek下一層的結點k的誤差率。
計算完誤差率后,就可以利用誤差率對權重和偏置進行更新,首先看權重的更新:
這里寫圖片描述
其中λ表示表示學習速率,取值為0到1,學習速率設置得大,訓練收斂更快,但容易陷入局部最優解,學習速率設置得比較小的話,收斂速度較慢,但能一步步逼近全局最優解。
更新完權重后,還有最后一項參數需要更新,即偏置:
這里寫圖片描述
至此,我們完成了一次神經網絡的訓練過程,通過不斷的使用所有數據記錄進行訓練,從而得到一個分類模型。不斷地迭代,不可能無休止的下去,總歸有個終止條件
訓練終止條件
每一輪訓練都使用數據集的所有記錄,但什么時候停止,停止條件有下面兩種:
1、設置最大迭代次數,比如使用數據集迭代100次后停止訓練;
2、計算訓練集在網絡上的預測準確率,達到一定門限值后停止訓練。
BP網絡運行的具體流程
網絡結構:
輸入層有n個神經元,隱含層有p個神經元,輸出層有q個神經元。
變量定義
輸入變量:
x=(x1,x2,…,xn)
隱含層輸入變量:
hi=(hi1,hi2,…,hip)
隱含層輸出變量:
ho=(ho1,ho2,…,hop)
輸出層輸入變量:
yi=(yi1,yi2,…,yiq)
輸出層輸出變量:
yo=(yo1,yo2,…,yoq)
期望輸出向量:
do=(d1,d2,…,dq)
輸入層與中間層的連接權值:
wih
隱含層與輸出層的連接權值:
who
隱含層各神經元的閾值:
bh
輸出層各神經元的閾值:
bo
樣本數據個數:
k=1,2,…,m
激活函數:
f(?)
誤差函數:
e=12∑o=1q(do(k)?yoo(k))2
第一步:網絡初始化
給各連接權值分別賦一個區間(?1,1)
內的隨機數,設定誤差函數e,給定計算精度值ε和最大學習次數M
。
第二步:隨機選取
隨機選取第k
個輸入樣本以及對應的期望輸出
x(k)=(x1(k),x2(k),…,xn(k))do(k)=(d1(k),d2(k),…,dq(k))
第三部:隱含層計算
計算隱含層各神經元的輸入和輸出
hih(k)=∑i=1nwihxi(k)?bh(h=1,2,…,p)
hih(k)=f(hih(k))(h=1,2,…,p)
yio(k)=∑h=1pwhohoh(k)?bo(o=1,2,…,q)
yoo(k)=f(yio(k))(o=1,2,…,q)
第四步:求偏導數
利用網絡期望輸出和實際輸出,計算誤差函數對輸出層的各神經元的偏導數δo(k)

第五、誤差累加,并且
適當調整,俗稱:“挪挪看”!

第六步:修正權值
利用輸出層各神經元的δo(k)
和隱含層各神經元的輸出來修正連接權值who(k)

。
第七部:修正權值
利用隱含層各神經元的δh(k)
和輸入層各神經元的輸入修正連接權值。
這里寫圖片描述
第八步:計算全局誤差
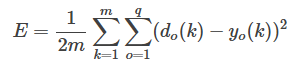
第九步:判斷模型合理性
判斷網絡誤差是否滿足要求。
當誤差達到預設精度或者學習次數大于設計的最大次數,則結束算法。
否則,選取下一個學習樣本以及對應的輸出期望,返回第三部,進入下一輪學習。
BP網絡的設計
在進行BP網絡的設計是,一般應從網絡的層數、每層中的神經元個數和激活函數、初始值以及學習速率等幾個方面來進行考慮,下面是一些選取的原則。
1.網絡的層數
理論已經證明,具有偏差和至少一個S型隱層加上一個線性輸出層的網絡,能夠逼近任何有理函數,增加層數可以進一步降低誤差,提高精度,但同時也是網絡 復雜化。另外不能用僅具有非線性激活函數的單層網絡來解決問題,因為能用單層網絡解決的問題,用自適應線性網絡也一定能解決,而且自適應線性網絡的 運算速度更快,而對于只能用非線性函數解決的問題,單層精度又不夠高,也只有增加層數才能達到期望的結果。
2.隱層神經元的個數
網絡訓練精度的提高,可以通過采用一個隱含層,而增加其神經元個數的方法來獲得,這在結構實現上要比增加網絡層數簡單得多。一般而言,我們用精度和 訓練網絡的時間來恒量一個神經網絡設計的好壞:
(1)神經元數太少時,網絡不能很好的學習,訓練迭代的次數也比較多,訓練精度也不高。
(2)神經元數太多時,網絡的功能越強大,精確度也更高,訓練迭代的次數也大,可能會出現過擬合(over fitting)現象。
由此,我們得到神經網絡隱層神經元個數的選取原則是:在能夠解決問題的前提下,再加上一兩個神經元,以加快誤差下降速度即可。
3.初始權值的選取
一般初始權值是取值在(?1,1)之間的隨機數。另外威得羅等人在分析了兩層網絡是如何對一個函數進行訓練后,提出選擇初始權值量級為s√r的策略, 其中r為輸入個數,s為第一層神經元個數。
4.學習速率
學習速率一般選取為0.01?0.8,大的學習速率可能導致系統的不穩定,但小的學習速率導致收斂太慢,需要較長的訓練時間。對于較復雜的網絡, 在誤差曲面的不同位置可能需要不同的學習速率,為了減少尋找學習速率的訓練次數及時間,比較合適的方法是采用變化的自適應學習速率,使網絡在 不同的階段設置不同大小的學習速率。
5.期望誤差的選取
在設計網絡的過程中,期望誤差值也應當通過對比訓練后確定一個合適的值,這個合適的值是相對于所需要的隱層節點數來確定的。一般情況下,可以同時對兩個不同 的期望誤差值的網絡進行訓練,最后通過綜合因素來確定其中一個網絡。
BP網絡的局限性
BP網絡具有以下的幾個問題:
(1)需要較長的訓練時間:這主要是由于學習速率太小所造成的,可采用變化的或自適應的學習速率來加以改進。
(2)完全不能訓練:這主要表現在網絡的麻痹上,通常為了避免這種情況的產生,一是選取較小的初始權值,而是采用較小的學習速率。
(3)局部最小值:這里采用的梯度下降法可能收斂到局部最小值,采用多層網絡或較多的神經元,有可能得到更好的結果。
BP網絡的改進
P算法改進的主要目標是加快訓練速度,避免陷入局部極小值等,常見的改進方法有帶動量因子算法、自適應學習速率、變化的學習速率以及作用函數后縮法等。 動量因子法的基本思想是在反向傳播的基礎上,在每一個權值的變化上加上一項正比于前次權值變化的值,并根據反向傳播法來產生新的權值變化。而自適應學習 速率的方法則是針對一些特定的問題的。改變學習速率的方法的原則是,若連續幾次迭代中,若目標函數對某個權倒數的符號相同,則這個權的學習速率增加, 反之若符號相反則減小它的學習速率。而作用函數后縮法則是將作用函數進行平移,即加上一個常數。
BP網絡實現
```
// con_a_bpnetwork200301.cpp : 此文件包含 "main" 函數。程序執行將在此處開始并結束。
//
#include "pch.h"
#include <iostream>
#include "math.h"
#include "time.h"
#include "stdio.h"
#include "stdlib.h"
#include "ctype.h"
#define Ni 1
#define Nm 4
#define No 1
#define L 100
#define Enom 0.02
#define loopmax 100000
#define e 2.71828182845904523536028747135266249775724709369995
//50 位夠長嗎:2.71828182845904523536028747135266249775724709369995
double E;
double a, u, n;
double W1[Ni][Nm], D1[Ni][Nm], W2[Nm][No], D2[Nm][No];
double D22[Nm][No], D11[Ni][No];
double a1[Ni][Nm], a2[Nm][No];
double Pi[L][Ni], Pm[L][Nm], Po[L][No], T[L][No];
double Xm[L][Nm], Xo[L][No];
double Qm[L][Nm], Qo[L][No];
void proceed();
void proceedR();
void forQ();
void amend();
void initiate();
double newa(double a, double D);
double cal(double d);
double vcal(double d);
//https ://blog.csdn.net/u013007900/article/details/50118945
int main()
{
std::cout << "Hello World!\n";
long int i;
int flag;
char choice;
for (;;)
{
flag = 0;
initiate();
for (i = 0;; i++)
{
proceed();
if (E < Enom)
{
flag = 1;
break;
}
if (i >= loopmax)
{
flag = -1;
break;
}
if (i % 2500 == 0)
printf("第%10d輪誤差:%20f,學習速率:%10f\n", i, E, a1[0][0]);
forQ();
amend();
}
if (flag > 0)proceedR();
else printf("訓練失敗!\n");
for (;;)
{
choice = 'Y';
//choice = getchar();
printf("是否繼續?(Y/N)\n");
//choice = getchar();
choice = toupper(choice);
if (choice == 'Y')break;
if (choice == 'N')exit(0);
}
}
//
}//
void initiate()
{
int i, j;
int random;
double x;
double step;
int stime;
long ltime;
ltime = time(NULL);
stime = (unsigned)ltime / 2;
srand(stime);
a = 0.02;
u = 1;
n = 1;
printf("本程序將用BP神經網絡擬合函數:Y=sin(X)\n\n");
for (i = 0; i < Nm; i++)
{
for (j = 0; j < Ni; j++)
{
random = rand() % 100 - 50;
x = random;
x = x / 100;
W1[j][i] = x;
D11[j][i] = 0;
D1[j][i] = 0;
a1[j][i] = 0.01;
}
for (j = 0; j < No; j++)
{
random = rand() % 100 - 50;
x = random;
x = x / 100;
W2[i][j] = x;
D22[i][j] = 0;
D2[i][j] = 0;
a2[i][j] = 0.01;
}
}
step = 1.0 / L;
for (i = 0; i < L; i++)
{
x = i;
Pi[i][0] = x * step;
T[i][0] = sin(Pi[i][0]);
}
printf("初始化成功!\n\n下面將對神經網絡進行訓練請稍候。\n");
}
void proceed()
{
int i, j, k;
E = 0;
for (i = 0; i < L; i++)
{
for (j = 0; j < Nm; j++)
{
Pm[i][j] = 0;
for (k = 0; k < Ni; k++)
{
Pm[i][j] = Pi[i][k] * W1[k][j] + Pm[i][j];
}
Xm[i][j] = cal(Pm[i][j]);
}
for (j = 0; j < No; j++)
{
Po[i][j] = 0;
for (k = 0; k < Nm; k++)
{
Po[i][j] = Xm[i][k] * W2[k][j] + Po[i][j];
}
Xo[i][j] = cal(Po[i][j]);
E = E + (Xo[i][j] - T[i][j]) * (Xo[i][j] - T[i][j]) / 2;
}
}
}
void forQ()
{
int i, j, k;
for (i = 0; i < L; i++)
{
for (j = 0; j < No; j++)
{
Qo[i][j] = (T[i][j] - Xo[i][j])* vcal(Xo[i][j]);
}
for (j = 0; j < Nm; j++)
{
Qm[i][j] = 0;
for (k = 0; k < No; k++)
{
Qm[i][j] = Qo[i][k] * W2[j][k] + Qm[i][j];
}
Qm[i][j] = Qm[i][j] * vcal(Xm[i][j]);
}
}
}
void amend()
{
int i, j, k;
double D;
for (i = 0; i < Nm; i++)
{
for (j = 0; j < Ni; j++)
{
D1[j][i] = 0;
}
for (j = 0; j < No; j++)
{
D2[i][j] = 0;
}
}
for (i = 0; i < Ni; i++)
{
for (j = 0; j < Nm; j++)
{
for (k = 0; k < L; k++)
{
D1[i][j] = Qm[k][j] * Pi[k][i] + D1[i][j];
}
D = D1[i][j] * D11[i][j];//為D11付初值
a1[i][j] = newa(a1[i][j], D); // a 付初值
W1[i][j] = W1[i][j] + a1[i][j] * (n * D1[i][j] + (1 - n) * D11[i][j]);
D11[i][j] = D1[i][j];
}
}
for (i = 0; i < Nm; i++)
{
for (j = 0; j < No; j++)
{
for (k = 0; k < L; k++)
{
D2[i][j] = Qo[k][j] * Xm[k][i] + D2[i][j];
}
D = D2[i][j] * D22[i][j];//為D11付初值
a2[i][j] = newa(a2[i][j], D);
W2[i][j] = W2[i][j] + a2[i][j] * (n * D2[i][j] + (1 - n) * D22[i][j]);
D22[i][j] = D2[i][j];
}
}
}
void proceedR()
{
int i, j;
float x;
double input, output;
char choice;
for (;;)
{
for (;;)
{
printf("在此輸入需要計算的值(0,1):\n");
scanf_s("%f", &x);
input = (double)x;
if ((input >= 0)&(input <= 1))break;
printf("注意輸入值應介于0、1之間!\n");
for (;;)
{
choice = 'Y';
choice = getchar();
printf("是否繼續?(Y/N)\n");
//choice = getchar();
choice = toupper(choice);
if (choice == 'Y')break;
if (choice == 'N')exit(0);
}
}
for (i = 0; i < Nm; i++)
{
Pm[0][i] = 0;
for (j = 0; j < Ni; j++)
{
Pm[0][i] = input * W1[j][i] + Pm[0][i];
}
Xm[0][i] = cal(Pm[0][i]);
}
for (i = 0; i < No; i++)
{
Po[0][i] = 0;
for (j = 0; j < Nm; j++)
{
Po[0][i] = Xm[0][j] * W2[j][i] + Po[0][i];
}
}
output = cal(Po[0][0]);
printf("輸入值為%20f對應的結果為%f\n", input, output);
printf("輸入值為%20f對應的正常結果為%f\n", input, sin(input));
for (;;)
{
choice = 'Y';
choice = getchar();
printf("是否繼續?(Y/N)\n");
// choice = getchar();
choice = toupper(choice);
if (choice == 'Y')break;
if (choice == 'N')exit(0);
}
}
}
double newa(double a, double D)
{
if (D > 0)
{
{
if (a <= 0.04)
a = a * 2;
else a = 0.08;
}
}
else
if (D < 0)
{
if (a >= 0.02)
{
a = a / 2;
}
else a = 0.01;
}
return a;
}
double cal(double d)
{
d = -(d * u); // chushihua
d = exp(d);
d = 1 / (1 + d);
return d;
}
double vcal(double d)
{
return u * d * (1 - d);
}
// VS-C++2017實現:運行程序: Ctrl + F5 或調試 >“開始執行(不調試)”菜單
// 調試程序: F5 或調試 >“開始調試”菜單
// 入門提示:
// 1. 使用解決方案資源管理器窗口添加/管理文件
// 2. 使用團隊資源管理器窗口連接到源代碼管理
// 3. 使用輸出窗口查看生成輸出和其他消息
// 4. 使用錯誤列表窗口查看錯誤
// 5. 轉到“項目”>“添加新項”以創建新的代碼文件,或轉到“項目”>“添加現有項”以將現有代碼文件添加到項目
// 6. 將來,若要再次打開此項目,請轉到“文件”>“打開”>“項目”并選擇 .sln 文件
```
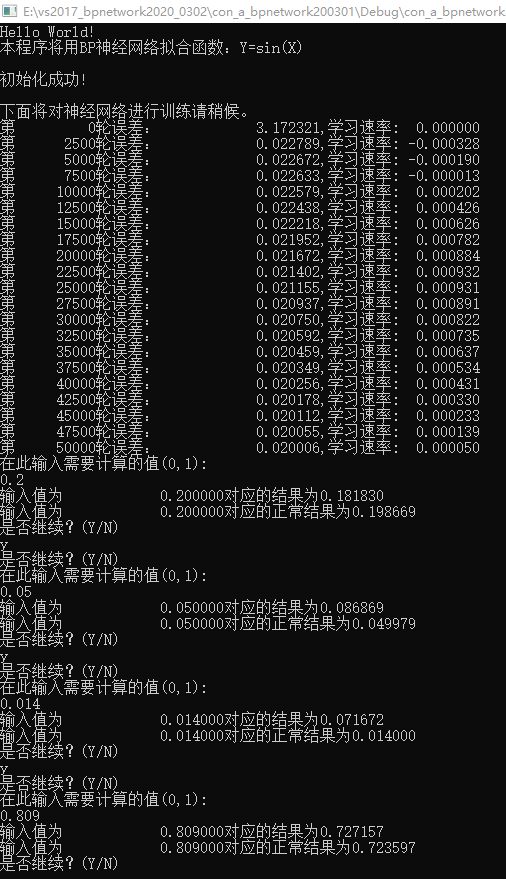
結果:
最后,對剛入門的朋友啰嗦一條:
有人可能會問,我都知道函數是什么了!你還用“BP網絡”一個勁兒的Trainning訓練、收斂(或稱擬合)個什么勁兒呢?
**答案很簡單也很重要::
如果你有一堆不知道是按照什么樣的函數產生的…甚至不知道是不是由函數產生的數(標量、矢量或者張量)……需要擬合的時候……?那時你到底怎么做呢?不就用到神經網絡比較好了嗎?
而且,最重要的是:你要擬合的那堆數字,(大自然)有時根本不會告訴你,原函數 是個“啥”啊。**
------------------------------------------------------------------------
下面是Matlab的代碼:
```
% BP網絡函數逼近實例
% 1.首先定義正弦函數,采樣率為20Hz,頻率為1Hz
k = 1; % 設定正弦信號頻率
p = [0:0.05:4];
t = cos(k*pi*p) + 3*sin(pi*p);
plot(p, t, '-'), xlabel('時間'); ylabel('輸入信號');
% 2.生成BP網絡。用newff函數生成前向型BP網絡,設定隱層中神經元數目為10
% 分別選擇隱層的傳遞函數為 tansig,輸出層的傳遞函數為 purelin,
% 學習算法為trainlm。
net =
newff(minmax(p),[10,10,1],{'tansig','tansig','purelin'},'trainlm');
% 3.對生成的網絡進行仿真并做圖顯示。
y1 = sim(net,p); plot(p, t, '-', p, y1, '--')
% 4.訓練。對網絡進行訓練,設定訓練誤差目標為 1e-5,最大迭代次數為300,
% 學習速率為0.05。
net.trainParam.lr=0.05;
net.trainParam.epochs=1000;
net.trainParam.goal=1e-5;
[net,tr]=train(net,p,t);
%5.再次對生成的網絡進行仿真并做圖顯示。
y2 = sim(net,p);
plot(p, t, '-', p, y2, '--')
```
Matlab是專門干這種事兒的大型商用數學軟件,其中:
~~~
net =
newff(minmax(p),[10,10,1],{'tansig','tansig','purelin'},'trainlm');
~~~
等工具 是 專門 用來 構建 神經網絡的……
(實現相同功能時)代碼當然簡單多咯。
- BP神經網絡到c++實現等--機器學習“掐死教程”
- 訓練bp(神經)網絡學會“乘法”--用”蚊子“訓練高射炮
- Ann計算異或&前饋神經網絡20200302
- 神經網絡ANN的表示20200312
- 簡單神經網絡的后向傳播(Backpropagration, BP)算法
- 牛頓迭代法求局部最優(解)20200310
- ubuntu安裝numpy和pip3等
- 從零實現一個神經網絡-numpy篇01
- _美國普林斯頓大學VictorZhou神經網絡神文的改進和翻譯20200311
- c語言-普林斯頓victorZhou神經網絡實現210301
- bp網絡實現xor異或的C語言實現202102
- bp網絡實現xor異或-自動錄入輸入(寫死20210202
- Mnist在python3.6上跑tensorFlow2.0一步一坑20210210
- numpy手寫數字識別-直接用bp網絡識別210201