
[TOC]
### Map
Go語言中提供的映射關系容器為`map`,其內部使用`散列表(hash)`實現,所以它是一種`無序`的基于`key-value`的數據結構,同時也是一種引用類型,必須初始化才能使用。
### 結構
map主要包含兩個結構:`hmap`和`bmap`。
~~~
type hmap struct {
count int // 鍵值對的數目
flags uint8 //狀態標識,比如是否在被寫或者遷移等,因為map不是線程安全的所以操作時需要判斷flags
B uint8 // 桶的數目,是2的多少次冪
noverflow uint16 // 記錄使用的溢出桶的數量
hash0 uint32 // hash 種子,做key 哈希的時候會用到
buckets unsafe.Pointer // 2^B個桶對應的地址指針
oldbuckets unsafe.Pointer // 擴容階段記錄舊桶的指針
nevacuate uintptr // 遷移的進度,小于此地址的bucket已經遷移完
extra *mapextra // 溢出桶相關
}
type mapextra struct {
overflow *[]*bmap //已經使用溢出桶的地址集合
oldoverflow *[]*bmap //遷移過程中老的溢出桶的地址
?
nextOverflow *bmap //下一個空閑出的桶
}
?
type bmap struct {
tophash [bucketCnt]uint8
}
?
//在編譯期間會產生新的結構體
type bmap struct {
tophash [8]uint8 //存儲哈希值的高8位
data byte[1] //key value數據:key/key/key/.../value/value/value...
overflow *bmap //溢出bucket的地址
}
~~~
#### hmap
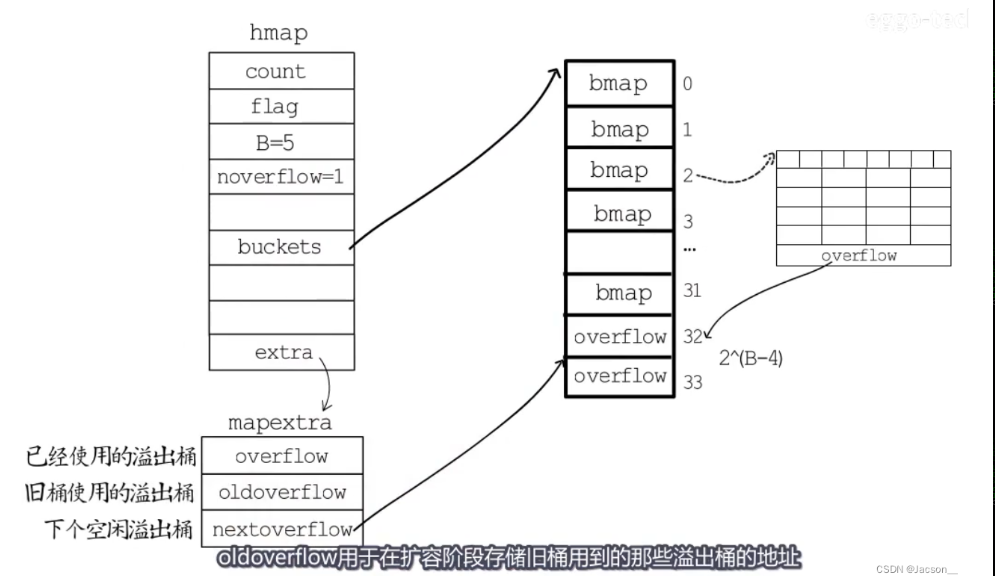
>溢出桶的創建
在創建map的時候如果B>=4,那么認為會使用到溢出桶的概率比較大,就會創建2^(B-4)個溢出桶,在內存上和常規的hmap是連續的。
#### bmap
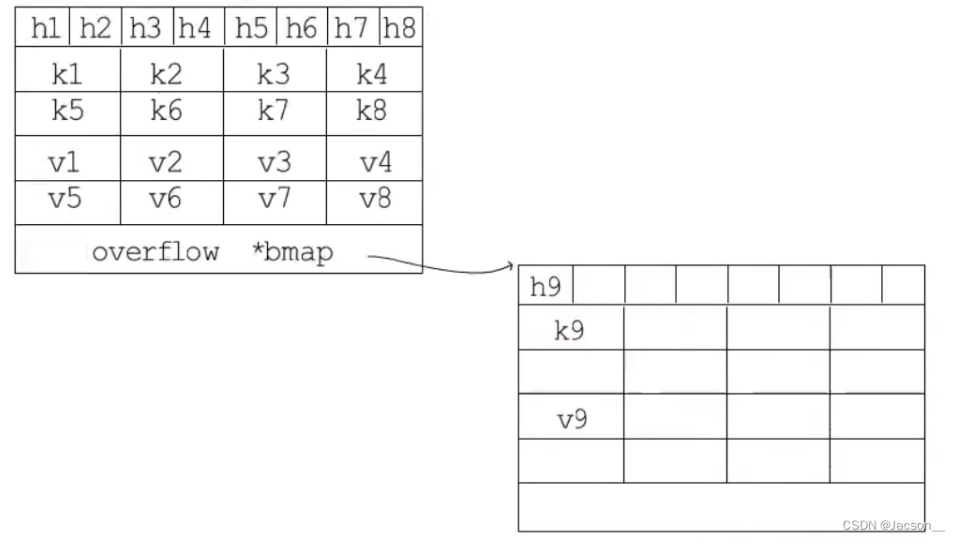
map使用的桶就是bmap,一個桶里可以放8個鍵值對,但是為了讓內存排列更加緊湊,8個key放一起,8個value放一起,8個key的前面則是8個tophash,每個tophash都是對應哈希值的高8位。最后這里是一個bmap型指針,指向一個溢出桶overflow,溢出桶的內存布局與常規桶相同,是為了減少擴容次數而引入的,當一個桶存滿了,還有空用的溢出桶時,就會在桶后面鏈一個溢出桶,繼續往這里面存。
### 擴容
#### 擴容的方式
擴容有兩種,一種是等量擴容,另一種是雙倍擴容
* **等量擴容**
負載因子沒有超標,但是使用的溢出桶很多,就會觸發等量擴容
>溢出桶多少的鑒定:
如果常規桶數目不大于2^15,那么使用溢出桶數目超過常規同就算是多了。
如果常規桶數目大于2 ^ 15,那么使用溢出桶數目一旦超過2^15就算是多了。
>原因
由于map中不斷的put和delete key,桶中可能會出現很多斷斷續續的空位,這些空位會導致連接的bmap溢出桶很長,導致掃描時間邊長。這種擴容實際上是一種整理,把后置位的數據整理到前面。**這種情況下,元素會發生重排,但不會換桶。**
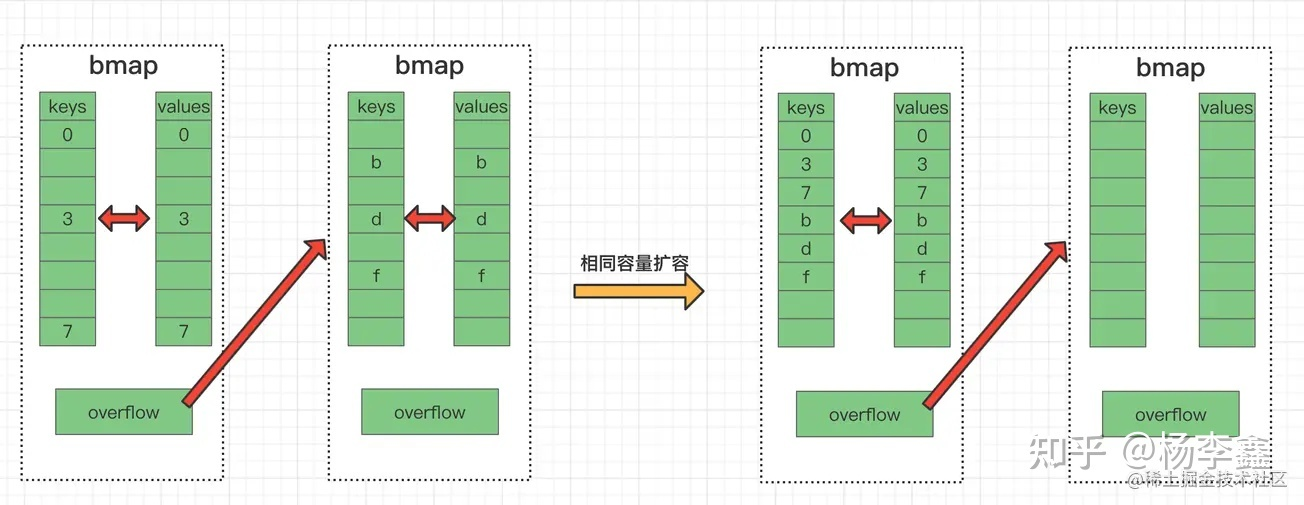
* **雙倍擴容(翻倍擴容)**
超過了6.5的負載因子,導致雙倍擴容
>原因
由于當前桶數組確實不夠用了,**發生這種擴容時,元素會重排,可能會發生桶遷移**。
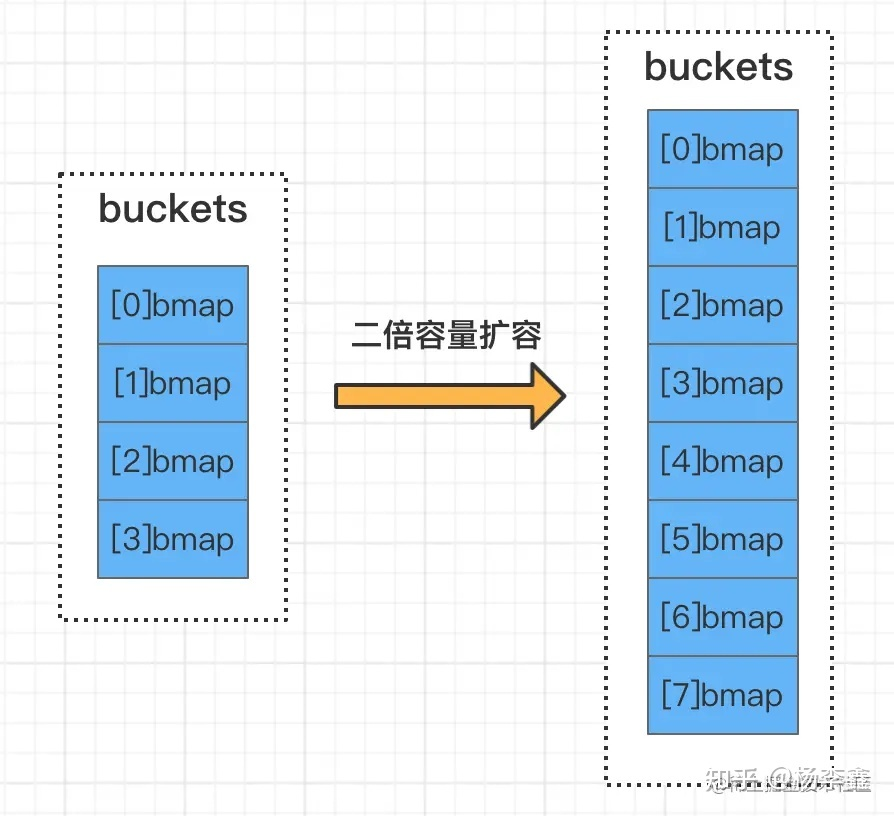
如圖中所示,擴容前B=2,擴容后B=3,假設一元素key的hash值后三位為101,那么由上文的介紹可知,在擴容前,由hash值的后兩位來決定幾號桶,即 01 所以元素在1號桶。 在擴容發生后,由hash值得后三位來決定幾號桶,即101所以元素會遷移到5號桶。
#### 什么時候擴容
* 觸發`load factor`的最大值,負載因子已達到當前界限
* 溢出桶`overflow buckets`過多
#### 擴容詳情
首先我們了解下**裝載因子(loadFactor)**的概念
loadFactor:=count / (2^B) 即 裝載因子 = map中元素的個數 / map中當前桶的個數
通過計算公式我們可以得知,**裝載因子是指當前map中,每個桶中的平均元素個數。**
**擴容條件1**:**裝載因子 > 6.5**(源碼中定義的)
這個也非常容易理解,正常情況下,如果沒有溢出桶,那么一個桶中最多有8個元素,當平均每個桶中的數據超過了6.5個,那就意味著當前容量要不足了,發生擴容。
**擴容條件2**:**溢出桶的數量過多**
當 B < 15 時,如果overflow的bucket數量超過 2^B。
當 B >= 15 時,overflow的bucket數量超過 2^15。
簡單來講,新加入key的hash值后B位都一樣,使得個別桶一直在插入新數據,進而導致它的溢出桶鏈條越來越長。如此一來,當map在操作數據時,掃描速度就會變得很慢。及時的擴容,可以對這些元素進行重排,使元素在桶的位置更平均一些。
#### 擴容時的細節
1. 在我們的hmap結構中有一個oldbuckets嗎,擴容剛發生時,會先將老數據存到這個里面。
2. 每次對map進行刪改操作時,會觸發從oldbucket中遷移到bucket的操作【非一次性,分多次】
3. 在擴容沒有完全遷移完成之前,每次get或者put遍歷數據時,都會先遍歷oldbuckets,然后再遍歷buckets。
### map的增刪查
#### 增
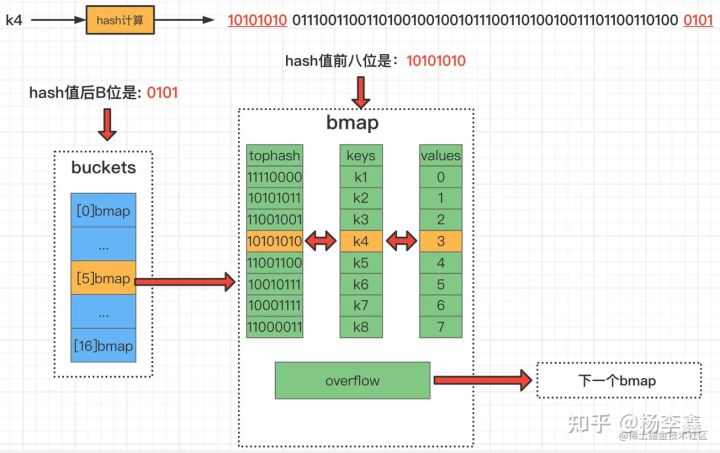
**map的賦值流程可總結位如下幾步:**
①**通過key的hash值后“B”位確定是哪一個桶**,圖中示例為4號桶。
② 遍歷當前桶,通過key的tophash和hash值,防止key重復,然后**找到第一個可以插入的位置**,即空位置處存儲數據。
③如果**當前桶元素已滿,會通過overflow鏈接創建一個新的桶**,來存儲數據。
**關于hash沖突**:當兩個不同的 key 落在同一個桶中,就是發生了哈希沖突。沖突的解決手段是采用鏈表法:在 桶 中,從前往后找到第一個空位進行插入。如果8個kv滿了,那么當前桶就會連接到下一個溢出桶(bmap)。
#### 刪
找到了map中的數據之后,針對key和value分別做如下操作:
~~~
1、如果``key``是一個指針類型的,則直接將其置為空,等待GC清除;
2、如果是值類型的,則清除相關內存。
3、同理,對``value``做相同的操作。
4、最后把key對應的高位值對應的數組index置為空。
~~~
#### 查
**假設當前 B=4 即桶數量為2^B=16個**,要從map中獲取k4對應的value

**參考上圖,k4的get流程可以歸納為如下幾步:**
①**計算k4的hash值**。\[由于當前主流機都是64位操作系統,所以計算結果有64個比特位\]
②**通過最后的“B”位來確定在哪號桶**,此時B為4,所以取k4對應哈希值的后4位,也就是0101,0101用十進制表示為5,所以在5號桶)
③**根據k4對應的hash值前8位快速確定是在這個桶的哪個位置**(額外說明一下,在bmap中存放了每個key對應的tophash,是key的哈希值前8位),一旦發現前8位一致,則會執行下一步
④**對比key完整的hash是否匹配**,如果匹配則獲取對應value
⑤**如果都沒有找到,就去連接的下一個溢出桶中找**
為什么要多維護一個tophash,即hash前8位?
這是因為tophash可以快速確定key是否正確,也可以把它理解成一種緩存措施,如果前8位都不對了,后面就沒有必要比較了。
### map的遷移
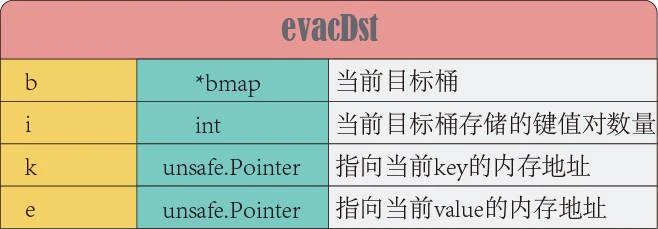
遷移的基礎結構是`evacDst`數據結構如下:
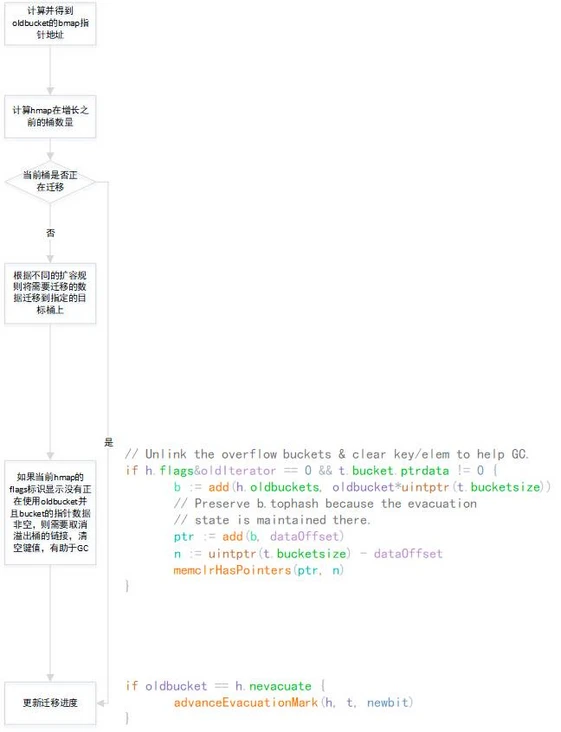
#### 遷移過程

### 總結
1. map的賦值難點在于數據的擴容和數據的遷移操作
2. bucket遷移是逐步進行的,在遷移的過程中每進行一次賦值,會做至少一次遷移工作。
3. 擴容不一定會增加空間,也可能只是做了內存整理
4. tophash的標志即可以判斷是否為空也可以判斷是否搬遷(用戶key的tophash最小值為5,5以下為標識,用于標識此tophash對應的值的搬遷進度及狀態),以及搬遷的位置。
5. 從map中刪除key,有可能導致出現很多空的kv,這會導致遷移操作,如果可以避免,盡量避免。
### 線程不安全
**map是線程不安全的**
在同一時間點,兩個 goroutine 對同一個map進行讀寫操作是不安全的。舉個栗子:
某map桶數量為4,即B=2。此時 goroutine1來插入key1, goroutine2來讀取 key2. 可能會發生如下過程:
① goroutine2 計算key2的hash值,B=2,并確定桶號為1。
② goroutine1添加key1,觸發擴容條件。
③ B=B+1=3, buckets數據遷移到oldbuckets。
④ goroutine2從桶1中遍歷,獲取數據失敗。
在工作中,當我們涉及到對一個map進行并發讀寫時,一般采用的做法是采用golang中自帶的mutex鎖
~~~go
type Resource struct {
sync.RWMutex
m map[string]int
}
?
func main() {
r := Resource{m: make(map[string]int)}
?
go func() { //開一個goroutine寫map
for j := 0; j < 100; j++ {
r.Lock()
r.m[fmt.Sprintf("resource_%d", j)] = j
r.Unlock()
}
}()
go func() { //開一個goroutine讀map
for j := 0; j < 100; j++ {
r.RLock()
fmt.Println(r.m[fmt.Sprintf("resource_%d", j)])
r.RUnlock()
}
}()
}
~~~
* 對map數據進行操作時不可取地址
因為隨著map元素的增長,map底層重新分配空間會導致之前的地址無效。
### map的key值
**能作為map key 的類型包括:**
|類型 |說明|
| --- | --- |
|boolean 布爾值 | |
|numeric 數字 | 包括整型、浮點型,以及復數 |
|string 字符串 | |
|pointer 指針 | 兩個指針類型相等,表示兩指針指向同一個變量或者同為nil |
|channel通道 | 兩個通道類型相等,表示兩個通道是被相同的make調用創建的或者同為nil |
|interface 接口| 兩個接口類型相等,表示兩個接口類型 的動態類型 和 動態值都相等 或者 兩接口類型 同為 nil |
|structs、arrays |只包含以上類型元素
| |
**不能作為map key 的類型包括:**
* slices
* maps
* functions
### sync.map (并發安全)
~~~
type Map struct {
mu Mutex //底層也是加鎖了
read atomic.Value // readOnly
dirty map[interface{}]*entry
misses int
}
~~~

~~~go
package main
import (
"fmt"
"strconv"
"sync"
)
// 并發安全的map
var m = sync.Map{}
func main() {
wg := sync.WaitGroup{}
// 對m執行20個并發的讀寫操作
for i := 0; i < 20; i++ {
wg.Add(1)
go func(n int) {
key := strconv.Itoa(n)
m.Store(key, n) // 存儲key-value
value, _ := m.Load(key) // 根據key取值
fmt.Printf("k=:%v,v:=%v\n", key, value)
wg.Done()
}(i)
}
wg.Wait()
}
~~~
### 鏈接
https://segmentfault.com/a/1190000040269520?sort=votes
https://zhuanlan.zhihu.com/p/495998623
- Go準備工作
- 依賴管理
- Go基礎
- 1、變量和常量
- 2、基本數據類型
- 3、運算符
- 4、流程控制
- 5、數組
- 數組聲明和初始化
- 遍歷
- 數組是值類型
- 6、切片
- 定義
- slice其他內容
- 7、map
- 8、函數
- 函數基礎
- 函數進階
- 9、指針
- 10、結構體
- 類型別名和自定義類型
- 結構體
- 11、接口
- 12、反射
- 13、并發
- 14、網絡編程
- 15、單元測試
- Go常用庫/包
- Context
- time
- strings/strconv
- file
- http
- Go常用第三方包
- Go優化
- Go問題排查
- Go框架
- 基礎知識點的思考
- 面試題
- 八股文
- 操作系統
- 整理一份資料
- interface
- array
- slice
- map
- MUTEX
- RWMUTEX
- Channel
- waitGroup
- context
- reflect
- gc
- GMP和CSP
- Select
- Docker
- 基本命令
- dockerfile
- docker-compose
- rpc和grpc
- consul和etcd
- ETCD
- consul
- gin
- 一些小點
- 樹
- K8s
- ES
- pprof
- mycat
- nginx
- 整理后的面試題
- 基礎
- Map
- Chan
- GC
- GMP
- 并發
- 內存
- 算法
- docker