
[TOC]
https://www.jianshu.com/p/59999ddc0a6a
https://mp.weixin.qq.com/s/hY2zBZqzMjVSIgnDK19EUQ
https://blog.csdn.net/ZHHX666/article/details/125978591
https://www.cnblogs.com/wscw/p/16389764.html
https://blog.csdn.net/Zach1Lavine/article/details/124958771
https://blog.csdn.net/qq_44954571/article/details/122835659
ES默認端口:9200;
kibana默認端口:5601
### ES和Mysql 對比
| 類型 | | | | |
| --- | --- | --- | --- | --- |
| ES | 索引(index) | 類型(type) | 文檔(document) | field(每條數據里面的字段) |
| Mysql | 庫 | 表 | 行記錄 |列|
### 數據類型
> 僅對比,不是相等
| es | | mysql |
| --- | --- |--- |
|integer | | int |
| long | | bigint |
| date | 時間戳 | timestamp |
| byte | | tinyint |
。。。
### keyword和text區別
* keyword不會進行分詞,直接把字符串建立倒排索引
* text,先分詞,再建立倒排索引
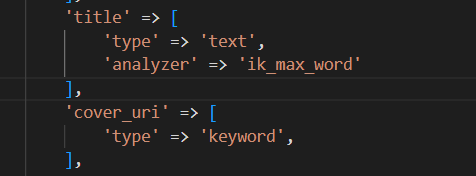
### 節點 node
#### 主節點 MasterNode
負責集群節點狀態的維護,索引的創建,刪除,數據的 rebalance,分片的分配等工作,不負責具體數據的索引和檢索
#### 數據節點 DataNode
負責集群中數據的寫入和檢索,屬于 IO,內存 和 CPU 密集型操作,需要的計算資源大
#### 提取節點 IngestNode
數據預處理通道,在數據被索引前預先處理文檔。
#### 協調節點 CoordinatingNode
接受客戶端請求,然后轉發到數據節點,最后將各個節點返回來的數據進行整合。對應著**兩個階段**
1. **分散階段,協調節點將請求轉發到保存數據的數據節點**
2. **收集階段,協調節點將每個數據節點的結果縮減為單個全局結果集**
### 分片 Shard 和 副本 Replica
Elasticsearch 的 索引是以分片的方式來組織的,每個分片就是 Lucene 中的索引。
分片分為**主分片**和**副本分片**,默認配置是 每個索引 5 個主分片,每個主分片都有一個副本分片,主分片和它的副本不在一個節點上,主要作用是**故障轉移和負載均衡**

## 倒排索引的結構

其中主要有如下幾個核心術語需要理解:
* **詞條(Term):**?索引里面最小的存儲和查詢單元,對于英文來說是一個單詞,對于中文來說一般指分詞后的一個詞。
* **詞典(Term Dictionary):**?或字典,是詞條 Term 的集合。搜索引擎的通常索引單位是單詞,單詞詞典是由文檔集合中出現過的所有單詞構成的字符串集合,單詞詞典內每條索引項記載單詞本身的一些信息以及指向“倒排列表”的指針。
* **倒排表(Post list):**?一個文檔通常由多個詞組成,倒排表記錄的是某個詞在哪些文檔里出現過以及出現的位置。每條記錄稱為一個倒排項(Posting)。倒排表記錄的不單是文檔編號,還存儲了詞頻等信息。
* **倒排文件(Inverted File):**?所有單詞的倒排列表往往順序地存儲在磁盤的某個文件里,這個文件被稱之為倒排文件,倒排文件是存儲倒排索引的物理文件。
從上圖我們可以了解到倒排索引主要由兩個部分組成:
* 詞典(存儲在內存)
* 倒排文件(存儲在磁盤)
詞典和倒排表是 Lucene 中很重要的兩種數據結構,是實現快速檢索的重要基石。
## ES 機制原理
>master 只負責把集群狀態信息的改變同步到其他節點,只有之間里索引和類型時才會需要master節點
### 寫索引原理
寫索引是只能寫在主分片上,然后同步到副本分片
#### 文檔怎么路由到對應的分片上
公式:
>shard?=?hash(routing)?%?number_of_primary_shards
`routing`是一個可變值,默認是文檔的`_id`,也可以設置成一個自定義的值。`routing`通過 hash 函數生成一個數字,然后這個數字再除以`number_of_primary_shards`(主分片的數量)后得到**余數**。這個分布在`0`到`number_of_primary_shards-1`之間的余數,就是我們所尋求的文檔所在分片的位置。
這就解釋了為什么我們要在創建索引的時候就確定好主分片的數量 并且永遠不會改變這個數量:因為如果數量變化了,那么所有之前路由的值都會無效,文檔也再也找不到了。
由于在 ES 集群中每個節點通過上面的計算公式都知道集群中的文檔的存放位置,所以每個節點都有處理讀寫請求的能力。
在一個寫請求被發送到某個節點后,該節點即為前面說過的協調節點,協調節點會根據路由公式計算出需要寫到哪個分片上,再將請求轉發到該分片的主分片節點上
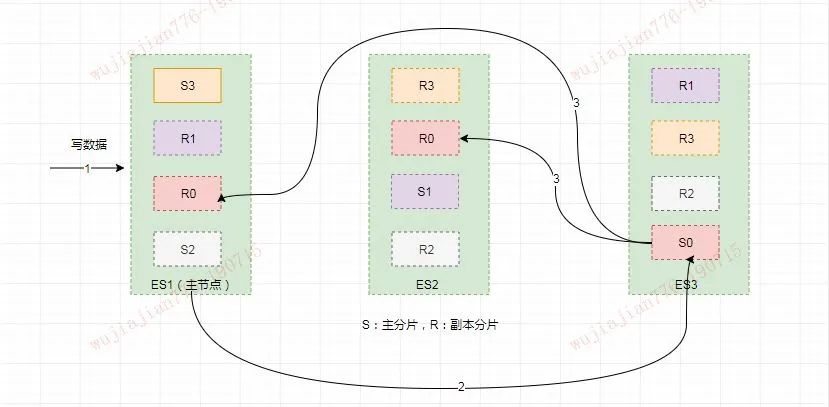
假如此時數據通過路由計算公式取余后得到的值是?`shard=hash(routing)%4=0`。
則具體流程如下:
* 客戶端向 ES1 節點(協調節點)發送寫請求,通過路由計算公式得到值為 0,則當前數據應被寫到主分片 S0 上。
* ES1 節點將請求轉發到 S0 主分片所在的節點 ES3,ES3 接受請求并寫入到磁盤。
* 并發將數據復制到兩個副本分片 R0 上,其中通過樂觀并發控制數據的沖突。一旦所有的副本分片都報告成功,則節點 ES3 將向協調節點報告成功,協調節點向客戶端報告成功。
## 查詢
### 全文級別查詢
match 是一個標準查詢,可以查詢文本、數字、日期格式的數據。match 查詢的一個主要用途是全文檢索
#### match
~~~
GET /_search
{
"query": {
"match" : {
"message" : "hello world"
}
}
}
~~~
#### match_phrase (match_phrase 與match查詢不同,它是精確匹配)
~~~
GET /_search
{
"query": {
"match_phrase" : {
"message" : "this is a test"
}
}
}
~~~
#### multi_match(允許在做match 查詢的基礎上查詢多個字段)
~~~
GET /_search
{
"query":{
"multi_match": {
"query": "full text search",
"fields": [ "title", "body" ]
}
}
}
~~~
### 詞條級別查詢
erm 用于精確值的查詢。使用boost參數可以提高指定字段的分數。boost的默認值為1。
string類型的數據在ES中可以使用text或者keyword的類型來存儲。ES存儲text類型的數據時會自動分詞,然后建立索引。keyword存儲數據時,不會分詞,直接建立索引。如果需要對string數據進行精確查詢,應該使用keyword的類型來存儲數據。
#### term
~~~
GET /_search
{
"query":{
"bool":{
"should":[
{
"term":{
"status":{
"value":"urgent",
"boost":2
}
}
},
{
"term":{
"status":"normal"
}
}
]
}
}
}
~~~
#### terms 可以指定一個字段的多個精確值。
~~~
GET /_search
{
"query": {
"constant_score" : {
"filter" : {
"terms" : { "user" : ["kimchy", "elasticsearch"]}
}
}
}
}
~~~
#### range
用于需要查詢指定范圍的內容。range 的常用參數有gte (greater-than or equal to), gt (greater-than) ,lte (less-than or equal to) 和 lt (less-than)。ES 的date類型的數值也可以使用range查詢。
~~~ada
GET /_search
{
"query": {
"range" : {
"age" : {
"gte" : 10,
"lte" : 20,
"boost" : 2.0
}
}
}
}
~~~
#### exists 返回在原始字段匯中至少有一個非空值的文檔
~~~routeros
GET /_search
{
"query": {
"exists" : { "field" : "user" }
}
}
~~~
#### 前綴
~~~routeros
GET /_search
{
"query": {
"prefix": {
"postcode": "W1"
}
}
}
~~~
### 復合查詢
bool 查詢可以合并多個過濾條件查詢的結果。bool 查詢可由 must, should, must not, filter 組合完成
* must 查詢的內容必須出現在檢索到的文檔中,并且會計算文檔匹配的相關度
* filter 查詢的內容必須出現在檢索到的文檔中。與must不同,filter中的查詢條件不會參與評分。filter對查詢的數據有緩存功能。filter效率會比must高一些,一般,除了需要計算相關度的查詢,一般使用filter
* should 至少有一個查詢條件匹配,相當于 or
* must\_mot 多個查詢條件的相反匹配,相當于 not
~~~routeros
GET /_search
{
"query":{
"bool":{
"must":{
"term":{
"user":"kimchy"
}
},
"filter":{
"term":{
"tag":"tech"
}
},
"must_not":{
"range":{
"age":{
"gte":10,
"lte":20
}
}
},
"should":[
{
"term":{
"tag":"wow"
}
},
{
"term":{
"tag":"elasticsearch"
}
}
]
}
}
}
~~~
## 聚合
`聚合(aggregations)`:可以實現對文檔數據的統計、分析、運算。
聚合常見的有三類:
* 桶(Bucket)排序:用來對文檔做分組。
* TermAggregation:按照文檔字段值分組。
* Date Histogram:按照日期階梯分組,例如一周為一組,或者一月為一組。
度量(Metric)聚合:用以計算一些值,比如:最大值、最小值、平均值等
* Avg:求平均值
* Max:求最大值
* Min:求最小值
* Stats:同時求max、min、avg、sum等
管道(pipeline)聚合:其它聚合的結果為基礎做聚合。
參與聚合的字段類型必須是:
* keyword
* 數值
* 日期
* 布爾
### DSL實現Bucket聚合
>案例一:統計所有數據中的酒店品牌,此時可以根據酒店品牌名稱做聚合。
```
GET /hotel1/_search
{
"size": 0, // 設置size為0,結果中不包含文檔,只包含聚合結果
"aggs": { // 定義聚合
"brandAggs": {
"terms": { // 聚合類型,按照品牌值聚合
"field": "brand", // 參與聚合的字段
"size": 20 // 希望獲取的聚合結果數量
}
}
}
}
```
>案例二:聚合結果排序
```
# 聚合功能,自定義排序規則
GET /hotel1/_search
{
"size": 0,
"aggs": {
"brandAggs": {
"terms": {
"order": {
"_count": "asc"
},
"field": "brand",
"size": 30
}
}
}
}
```
>限定聚合范圍
```
# 聚合功能,自定義聚合范圍
GET /hotel1/_search
{
"query": {
"range": {
"price": {
"lte": 200
}
}
},
"size": 0,
"aggs": {
"brandAggs": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
```
總結:
aggs代表聚合,與query同級,此時query的作用是限定聚合文檔的范圍。
聚合必須的三要素:
* 聚合名稱
* 聚合類型
* 聚合字段
聚合可配置屬性:
* size:指定聚合結果數量。
* order:指定聚合結果排序方式。
* field:指定聚合字段。
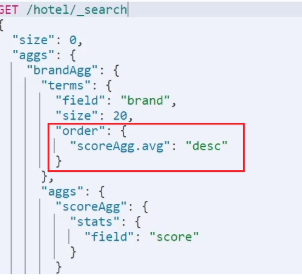
### Metric聚合語法
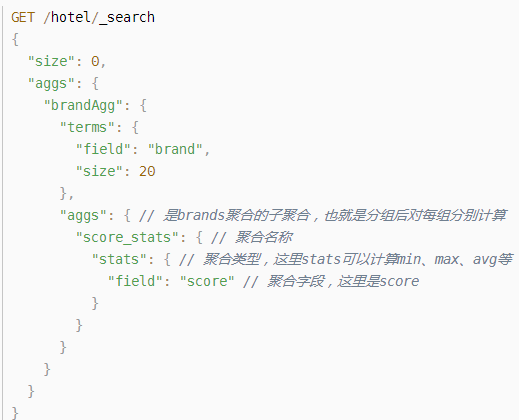
還可以給聚合結果做個排序

## ES 集群配置
### **集群搭建的實現步驟**
**eg:**
> 第一步:準備三臺服務器
服務器名稱 ? ? ? ? IP地址
?node-1 ? ? ? ? 192.168.86.130
?node-2 ? ? ? ? 192.168.86.131
?node-3 ? ? ? ? 192.168.86.132
>第二步:服務器集群配置
/opt/application/es6.7.0下執行cd config命令后,再執行vi elasticsearch.yml命令,然后修改:
1、cluster.name: myes? ? ? 保證三臺服務器節點集群名稱相同
2、node.name: node-1? ? ? 每個節點名稱不一樣,其他兩臺為node-2,node-3
3、network.host: 192.168.86.130? 實際服務器的ip地址
4、discovery.zen.ping.unicast.hosts: ["192.168.86.130", "192.168.86.131","192.168.86.132"]? ?多個服務集群ip
5、discovery.zen.minimum_master_nodes:1
6、關閉防火墻 systemctl stop firewalld.service
三臺服務器都做同樣的配置步驟,只有2和3不一樣,其他一模一樣。
>第三步:驗證集群效果
在瀏覽器中輸入:http://192.168.86.130/_cat/nodes?pretty
### **如何處理高并發場景**
1、分布式ElasticSearch
ElasticSearch是一個分布式全文檢索框架,隱藏了復雜的處理機制,內部使用分片機制、集群發現、分片負載均衡請求路由。
2、Shards分片
Shards分片:代表索引分片,ElasticSearch可以把一個完整的索引分成多個分片,這樣的好處是可以把一個大的索引拆分成多個,分布到不同的節點上。構成分布式搜索。分片的數量只能在索引創建前指定,并且索引創建后不能更改。
3、Replicas分片
Replicas分片:代表索引副本,ElasticSearch可以設置多個索引的副本,副本的作用一是提高系統的容錯性,當某個節點某個分片損壞或丟失時可以從副本中恢復。二是提高ElasticSearch的查詢效率,ElasticSearch會自動對搜索請求進行負載均衡。
### **集群核心原理分析**
> 什么是primary shards
每個索引會被分成多個分片shards進行存儲,默認創建索引是分配5個分片進行存儲,每個分片都會分布式部署在多個不同的節點上,該分片成為primary shards主分片。查看索引分片信息http://192.168.86.130:9200/mytest/\_settings:索引的主分片數量定義好后,不能修改。
>主分片如何實現高可用
每一個主分片為了實現高可用,都會有自己對應的備份分片,主分片對應的備份分片不能存放同一臺服務器上。就說明單臺ElasticSearch服務器上是沒有備份分片的。
### **大數量提高查詢效率**
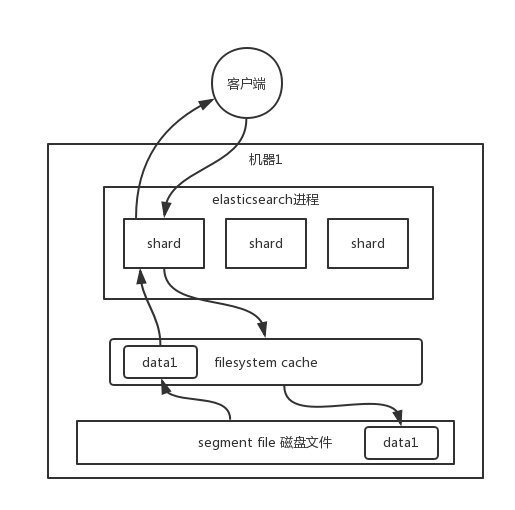
數據實際上都寫到磁盤文件里去了,查詢的時候,操作系統會將磁盤文件里的數據自動緩存到`filesystem cache`里面去,所以為了加快查詢效率,就要盡量使得查詢的數據在filesystem cache中,避免去磁盤文件查詢數據
1、盡量使得es可以有一半的數據在filesystem cache中
2、盡量存儲用于查詢的數據,不要把無關數據都存進去,避免無關數據占用filesystem cache的空間
3、數據預熱,對數據的搜索的做統計,把熱數據通過腳本每隔一段時間訪問一次,保證熱數據在filesystem cache
4、不要深分頁,因為效率會很低,例如:發送一條取前100條數據,實際上是把每個shard取100條,數據聚合后再進入排序返回,速度很慢
5、冷熱索引,把冷熱數據存在不能機器,避免冷數據占用cache
### **JVM 調優建議如下**:
* 確保堆內存最小值( Xms )與最大值( Xmx )的大小是相同的,防止程序在運行時改變堆內存大小。Elasticsearch 默認安裝后設置的堆內存是 1GB。可通過`?../config/jvm.option`?文件進行配置,但是最好不要超過物理內存的50%和超過 32GB。
* GC 默認采用 CMS 的方式,并發但是有 STW 的問題,可以考慮使用 G1 收集器。
* ES 非常依賴文件系統緩存(Filesystem Cache),快速搜索。一般來說,應該至少確保物理上有一半的可用內存分配到文件系統緩存。
- Go準備工作
- 依賴管理
- Go基礎
- 1、變量和常量
- 2、基本數據類型
- 3、運算符
- 4、流程控制
- 5、數組
- 數組聲明和初始化
- 遍歷
- 數組是值類型
- 6、切片
- 定義
- slice其他內容
- 7、map
- 8、函數
- 函數基礎
- 函數進階
- 9、指針
- 10、結構體
- 類型別名和自定義類型
- 結構體
- 11、接口
- 12、反射
- 13、并發
- 14、網絡編程
- 15、單元測試
- Go常用庫/包
- Context
- time
- strings/strconv
- file
- http
- Go常用第三方包
- Go優化
- Go問題排查
- Go框架
- 基礎知識點的思考
- 面試題
- 八股文
- 操作系統
- 整理一份資料
- interface
- array
- slice
- map
- MUTEX
- RWMUTEX
- Channel
- waitGroup
- context
- reflect
- gc
- GMP和CSP
- Select
- Docker
- 基本命令
- dockerfile
- docker-compose
- rpc和grpc
- consul和etcd
- ETCD
- consul
- gin
- 一些小點
- 樹
- K8s
- ES
- pprof
- mycat
- nginx
- 整理后的面試題
- 基礎
- Map
- Chan
- GC
- GMP
- 并發
- 內存
- 算法
- docker