
[TOC]
### **什么是 GMP?**
> 先解釋代表的意思:
G:Goroutine,實際上我們每次調用`go func`就是生成了一個 G。
P:Processor,處理器,一般 P 的數量就是處理器的核數,可以通過`GOMAXPROCS`進行修改。
M:Machine,系統線程。
> 再說GMP模型構成
在Go中,**線程是運行goroutine的實體,調度器的功能是把可運行的goroutine分配到工作線程上**
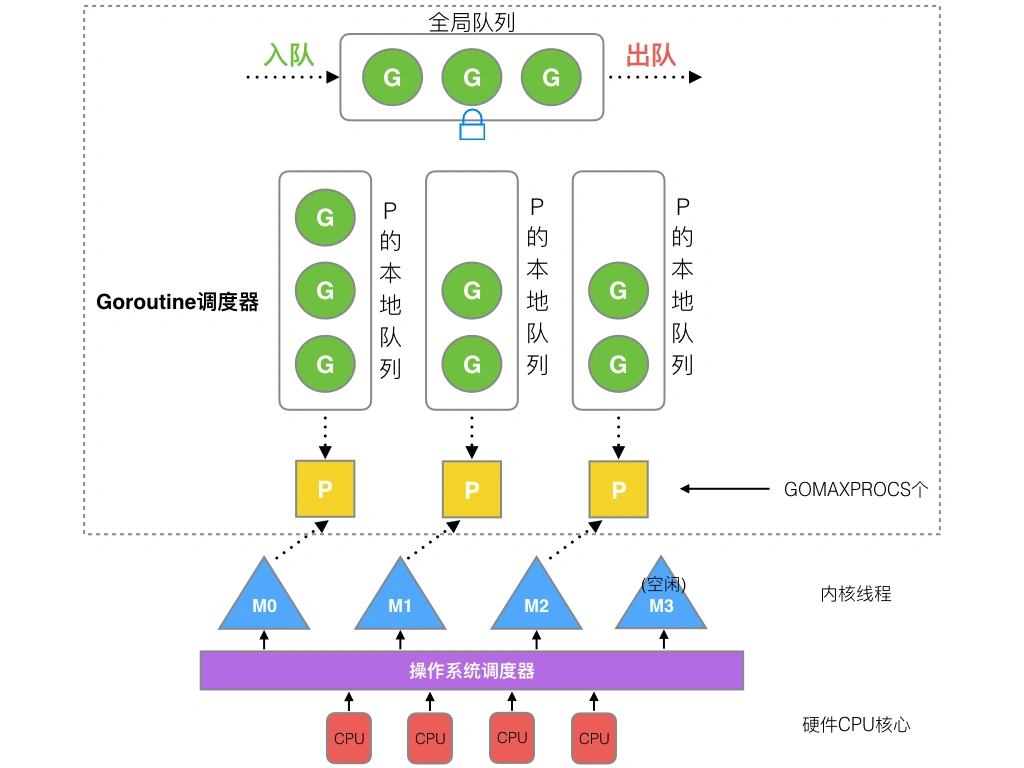
1. **全局隊列**(Global Queue):存放等待運行的G。
2. **P的本地隊列**:同全局隊列類似,存放的也是等待運行的G,存的數量有限,不超過256個。新建G'時,G'優先加入到P的本地隊列,如果隊列滿了,則會把本地隊列中一半的G移動到全局隊列。
3. **P列表**:所有的P都在程序啟動時創建,并保存在數組中,最多有`GOMAXPROCS`(可配置)個。
4. **M**:線程想運行任務就得獲取P,從P的本地隊列獲取G,P隊列為空時,M也會嘗試從全局隊列**拿**一批G放到P的本地隊列,或從其他P的本地隊列**偷**一半放到自己P的本地隊列。M運行G,G執行之后,M會從P獲取下一個G,不斷重復下去。
> 最后說調度流程
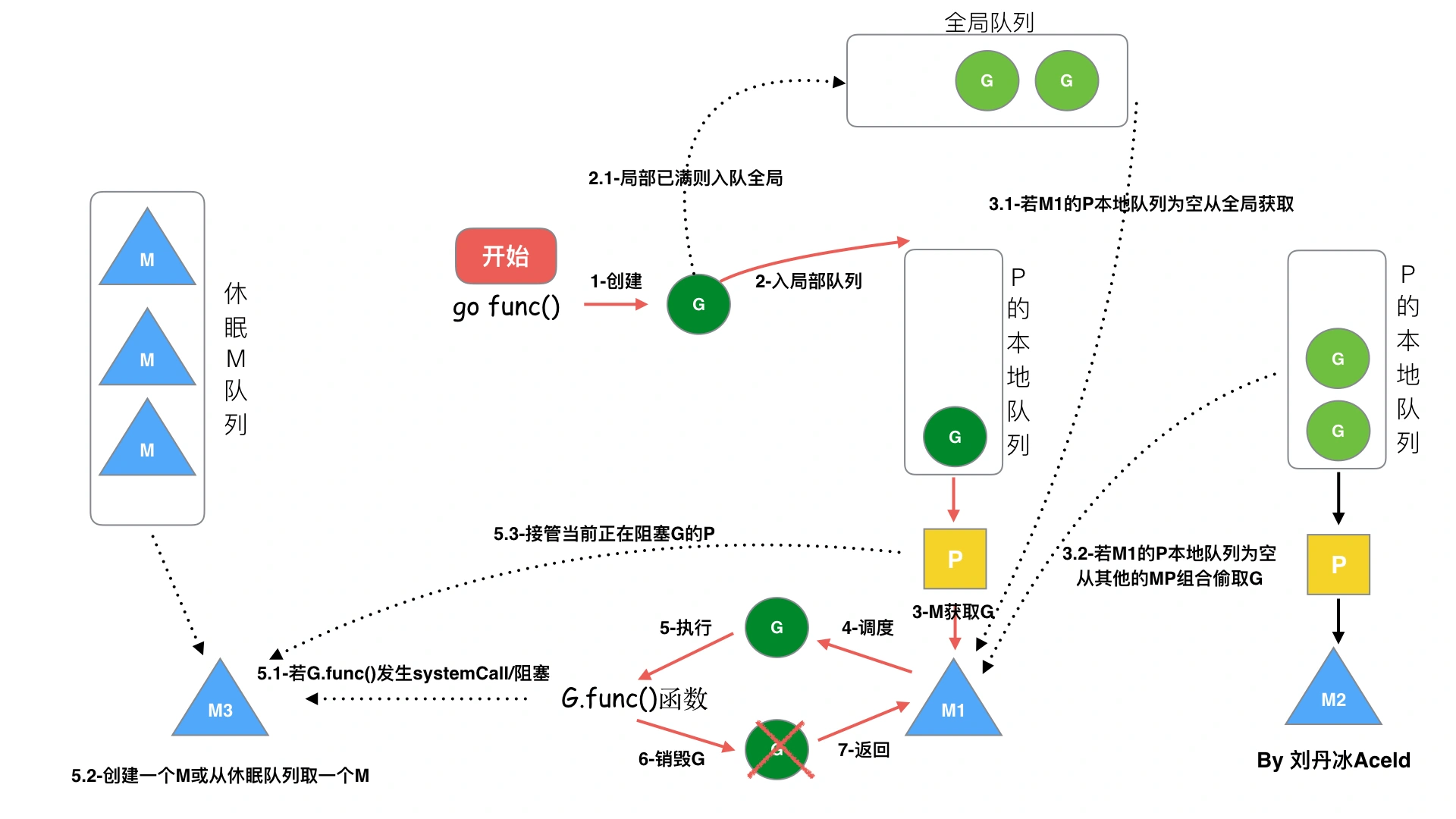
1、 GPM 的調度流程從 go func()開始創建一個 goroutine,新建的G優先放入P的本地隊列保存待執行的 goroutine(流程 2),當 M 綁定的 P 的的局部隊列已經滿了之后就會把 goroutine 放到全局隊列(流 程 2-1)
2、每個 P 和一個 M 綁定,M 是真正的執行 P 中 goroutine 的實體(流程 3), M 從綁定的 P 中的局部隊列獲取 G 來執行
3、當 M 綁定的 P 的局部隊列為空時,M 會從全局隊列獲取到本地隊列來執行 G (流程 3.1),當從全局隊列中沒有獲取到可執行的 G 時候,M 會從其他 P 的局部隊列中偷取 G 來執行(流程 3.2),這種從其他 P 偷的方式稱為 work stealing
4、一個M調度G執行的過程是一個循環機制
5、 當 G 因系統調用(syscall)阻塞時會阻塞 M,此時 P 會和 M 解綁即 hand off,并尋找新的空閑的 M,若沒有空閑的 M 就會新建一個 M(流程 5.1)
6、當 G 因 channel 或者 network I/O 阻塞時,不會阻塞 M,M 會尋找其他的 G;當阻塞的 G 恢復后會重新進入 runnable 進入 P 隊列等待執 行(流程 5.3)
7、 當M系統調用結束時候,這個G會嘗試獲取一個空閑的P執行,并放入到這個P的本地隊列。如果獲取不到P,則將G放入全局隊列,等待被其他的P調度。然后M將進入緩存池睡眠。
### **搶占調度方式**
>協作式的搶占式調度
程序只能依靠 Goroutine 主動讓出 CPU 資源才能觸發調度,長時間占用線程,會造成其他Goroutine饑餓
>基于信號的搶占式調度(反應可能遲鈍)
通過 sysmon 監控實現的搶占式調度,最快20us,最慢10-20ms
### **G-M-P的數量關系**
* M:有限制,默認數量限制是 10000,可調整。(debug.SetMaxThreads 設置)
* G:沒限制,但受內存影響。
~~~
假設一個 Goroutine 創建需要 4k:
4k * 80,000 = 320,000k ≈ 0.3G內存
4k * 1,000,000 = 4,000,000k ≈ 4G內存
以此就可以相對計算出來一臺單機在通俗情況下,所能夠創建 Goroutine 的大概數量級別。
注:Goroutine 創建所需申請的 2-4k 是需要連續的內存塊。
~~~
* P:受本機的核數影響,可大可小,不影響 G 的數量創建。(**`GOMAXPROCS`**)
### **GMP 調度過程中存在哪些阻塞**
* I/O,select
* block on syscall
* channel
* 等待鎖
* runtime.Gosched()
### **Sysmon 有什么作用**
Sysmon 也叫監控線程,變動的周期性檢查
* 釋放閑置超過 5 分鐘的 span 物理內存;
* 如果超過 2 分鐘沒有垃圾回收,強制執行;
* 將長時間未處理的 netpoll 添加到全局隊列; 30
* 向長時間運行的 G 任務發出搶占調度(超過 10ms 的 g,會進行 retake);
* 收回因 syscall 長時間阻塞的 P;
- Go準備工作
- 依賴管理
- Go基礎
- 1、變量和常量
- 2、基本數據類型
- 3、運算符
- 4、流程控制
- 5、數組
- 數組聲明和初始化
- 遍歷
- 數組是值類型
- 6、切片
- 定義
- slice其他內容
- 7、map
- 8、函數
- 函數基礎
- 函數進階
- 9、指針
- 10、結構體
- 類型別名和自定義類型
- 結構體
- 11、接口
- 12、反射
- 13、并發
- 14、網絡編程
- 15、單元測試
- Go常用庫/包
- Context
- time
- strings/strconv
- file
- http
- Go常用第三方包
- Go優化
- Go問題排查
- Go框架
- 基礎知識點的思考
- 面試題
- 八股文
- 操作系統
- 整理一份資料
- interface
- array
- slice
- map
- MUTEX
- RWMUTEX
- Channel
- waitGroup
- context
- reflect
- gc
- GMP和CSP
- Select
- Docker
- 基本命令
- dockerfile
- docker-compose
- rpc和grpc
- consul和etcd
- ETCD
- consul
- gin
- 一些小點
- 樹
- K8s
- ES
- pprof
- mycat
- nginx
- 整理后的面試題
- 基礎
- Map
- Chan
- GC
- GMP
- 并發
- 內存
- 算法
- docker