
[TOC]
## etcd
* 端口:2379
https://zhuanlan.zhihu.com/p/405811320
https://developer.aliyun.com/article/11035?spm=a2c6h.12873639.article-detail.61.630bc264HCgp1g
https://www.cnblogs.com/aganippe/p/16009137.html
### etcd的數據構成
raft_term:leader的任期,遞增的,沒進行一次選舉,這個值就會+1
revision:全局版本號,只要etcd發生改變就會+1
create_revision:創建key的版本號,即當時的revision數據
mod_revision:修改key的版本號
## ETCD工作原理
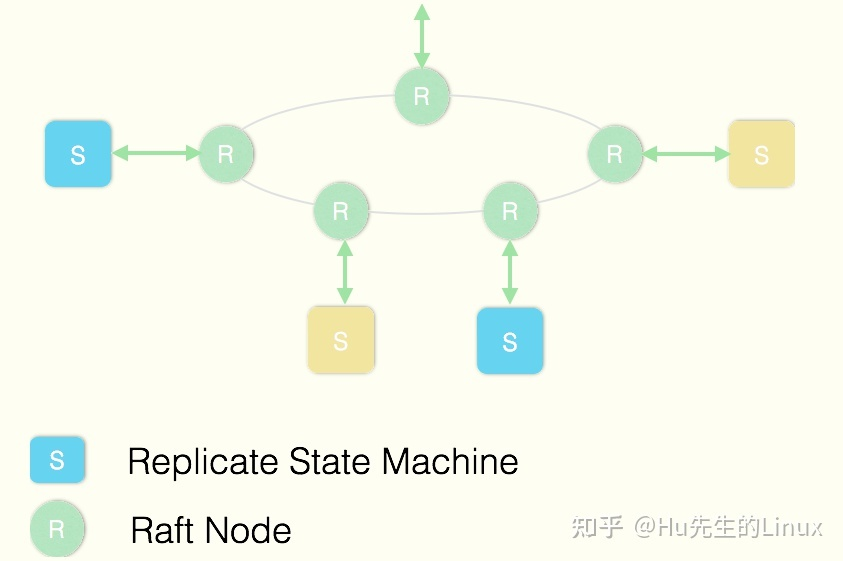
ETCD使用Raft協議來維護集群內各個節點狀態的一致性。簡單說,ETCD集群是一個分布式系統,由多個節點相互通信構成整體對外服務,每個節點都存儲了完整的數據,并且通過Raft協議保證每個節點維護的數據是一致的。
## V3版本架構圖
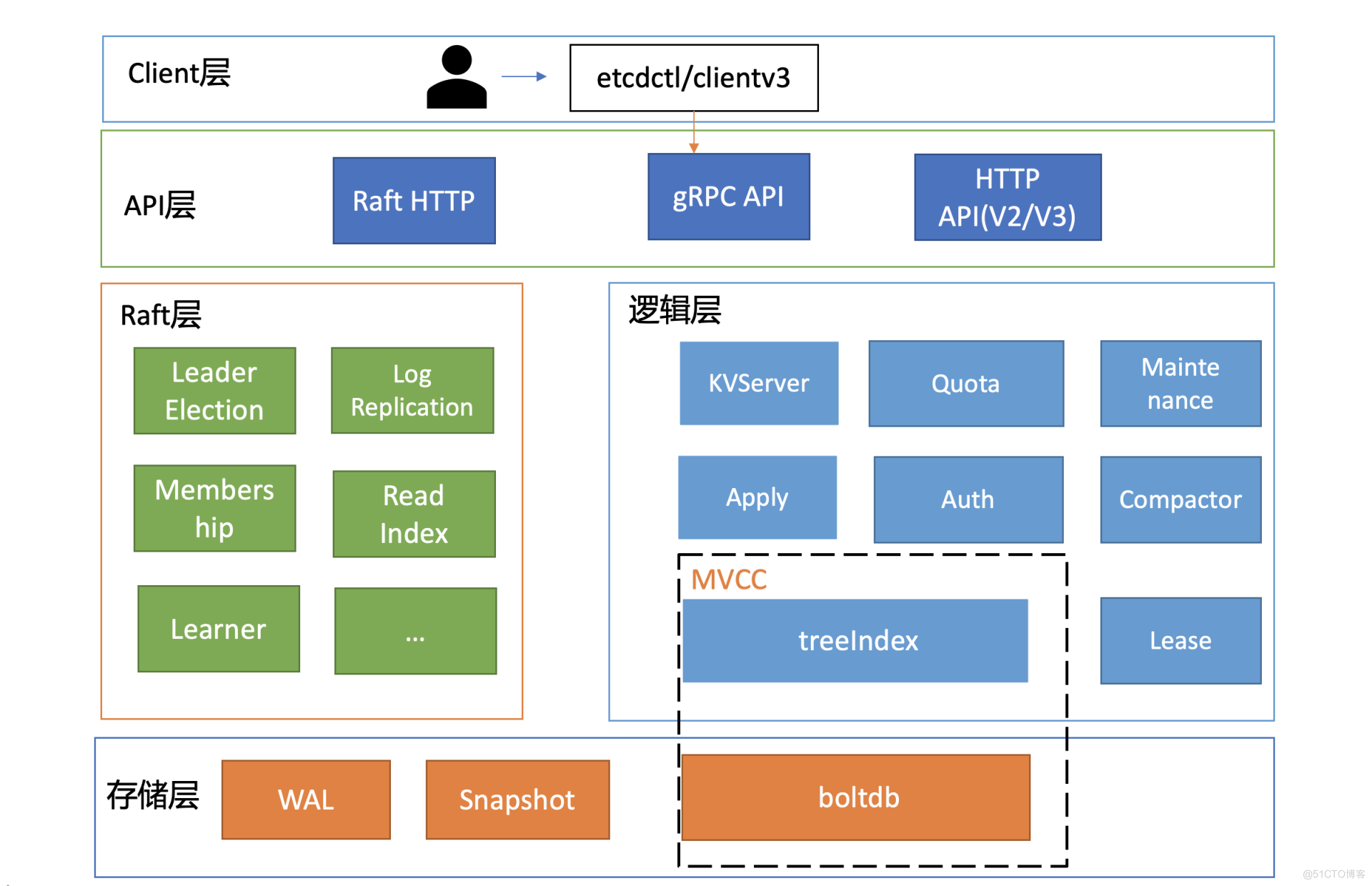
* Client 層:Client 層包括 client v2 和v3 兩個大版本 API 客戶端庫,提供了簡潔易用的
API,同時支持負載均衡、節點間故障自動轉移,可極大降低業務使用etcd 復雜度,提
升開發效率、服務可用性。
* API 網絡層:API 網絡層主要包括 dlient 訪問 server 和 server 節點之間的通信協議。
一方面,client 訪問 etcd server 的API 分為v2和v3 兩個大版本。V2 API 使用
HTTP/1.x 協議,V3 API 使用 gRPC 協議。同時v3通過etcd grpc-gateway 組件也支
持 HTTP/1.x 協議,便于各種語言的服務調用。另一方面,server 之間通信協議,是指
節點間通過 Raft 算法實現數據復制和 Leader 選舉等功能時使用的 HTTP 協議。
* Raft 算法層:Raft 算法層實現了 Leader 選舉、日志復制、Readlndex 等核心算法特
性,用于保障 etcd 多個節點間的數據一致性、提升服務可用性等,是etcd 的基石和亮
點。
* 功能邏輯層:etcd 核心特性實現層,如典型的 KVServer 模塊、MVCC 模塊、Auth 鑒
權模塊、Lease 租約模塊、Compactor 壓縮模塊等,其中 MVCC 模塊主要由
treelndex 模塊和 boltdb 模塊組成。
?存儲層:存儲層包含預寫日志 (WAL) 模塊、快照(Snapshot)模塊、boltdb模塊。其中
WAL 可保障 etcd crash 后數據不丟失,boltdb 則保存了集群元數據和用戶寫入的數
據.
## Raft協議
>主要分為三個部分:選主,日志復制,安全性
### **raft一致性算法**
在raft體系中,有一個強leader,由它全權負責接收客戶端的請求命令,并將命令作為日志條目復制給其他服務器,在確認安全的時候,將日志命令提交執行。
當leader故障時,會選舉產生一個新的leader。在強leader的幫助下,raft將一致性問題分解為了三個子問題:
* leader選舉:當已有的leader故障時必須選出一個新的leader
* 日志同步:leader接受來自客戶端的命令,記錄為日志,并復制給集群中的其他服務器,并強制其他節點的日志與leader保持一致
* 安全措施:通過一些措施確保系統的安全性,如確保所有狀態機按照相同順序執行相同命令的措施
可視化網站:http://thesecretlivesofdata.com/raft/
### 結構概念
leader:負責和客戶端進行交互,并且負責向其他節點同步日志的,一個集群只有一個leader
candidate:當leader宕機后,部分follower將轉為candidate,并為自己拉票,獲得半數以上票數的candidate成為新的leader
follower:一般情況下,除了leader,其他節點都是follower
term:term使用連續遞增的編號的進行識別,每一個term都從新的選舉開始。同時term也有指示邏輯時鐘的作用,最新日志的term越大證明越有資格成為leader
RequestVote RPC:它由選舉過程中的candidate發起,用于拉取選票
AppendEntries RPC:它由leader發起,用于復制日志或者發送心跳信號
>內部兩個超時機制:重置超時、心跳超時,每次follower接收到數據同步包,都會重置這兩個時間
>什么時候開始選舉?
當心跳超時之后,等選舉超時,就開始選舉,最先選舉超時的follower就會成為candidate,并進行選舉,只有當超過半數才能成為leader
### leader選舉
raft通過心跳機制發起leader選舉。節點都是從follower狀態開始的,如果收到了來自leader或candidate的RPC,那它就保持follower狀態,避免爭搶成為candidate
leader會發送空的AppendEntries RPC作為心跳信號來確立自己的地位,如果follower一段時間(election timeout)沒有收到心跳,它就會認為leader已經掛了,發起新的一輪選舉
選舉發起后,一個follower會增加自己的當前term編號并轉變為candidate
它會首先投自己一票,然后向其他所有節點并行發起RequestVote RPC,之后candidate狀態將可能發生如下三種變化:
* 贏得選舉,成為leader:如果它在一個term內收到了大多數的選票,將會在接下的剩余term時間內稱為leader,然后就可以通過發送心跳確立自己的地位。每一個server在一個term內只能投一張選票,并且按照先到先得的原則投出
* 其他server成為leader:在等待投票時,可能會收到其他server發出AppendEntries RPC心跳信號,說明其他leader已經產生了。這時通過比較自己的term編號和RPC過來的term編號,如果比對方大,說明leader的term過期了,就會拒絕該RPC,并繼續保持候選人身份; 如果對方編號不比自己小,則承認對方的地位,轉為follower
* 選票被瓜分,選舉失敗:如果沒有candidate獲取大多數選票,則沒有leader產生, candidate們等待超時后發起另一輪選舉。為了防止下一次選票還被瓜分,必須采取一些額外的措施,raft采用隨機election timeout的機制防止選票被持續瓜分。通過將timeout隨機設為一段區間上的某個值,因此很大概率會有某個candidate率先超時然后贏得大部分選票
### 日志同步
一旦leader被選舉成功,就可以對客戶端提供服務了
客戶端提交每一條命令都會被按順序記錄到leader的日志中,每一條命令都包含term編號和順序索引,然后向其他節點并行發送AppendEntries RPC用以復制命令(如果命令丟失會不斷重發)
當復制成功也就是大多數節點成功復制后,leader就會提交命令,即執行該命令并且將執行結果返回客戶端,raft保證已經提交的命令最終也會被其他節點成功執行。
leader會保存有當前已經提交的最高日志編號。順序性確保了相同日志索引處的命令是相同的,而且之前的命令也是相同的。當發送AppendEntries RPC時,會包含leader上一條剛處理過的命令,接收節點如果發現上一條命令不匹配,就會拒絕執行
在這個過程中可能會出現一種特殊故障。如果leader崩潰了,它所記錄的日志沒有完全被復制,會造成日志不一致的情況,follower相比于當前的leader可能會丟失幾條日志,也可能會額外多出幾條日志,這種情況可能會持續幾個term。
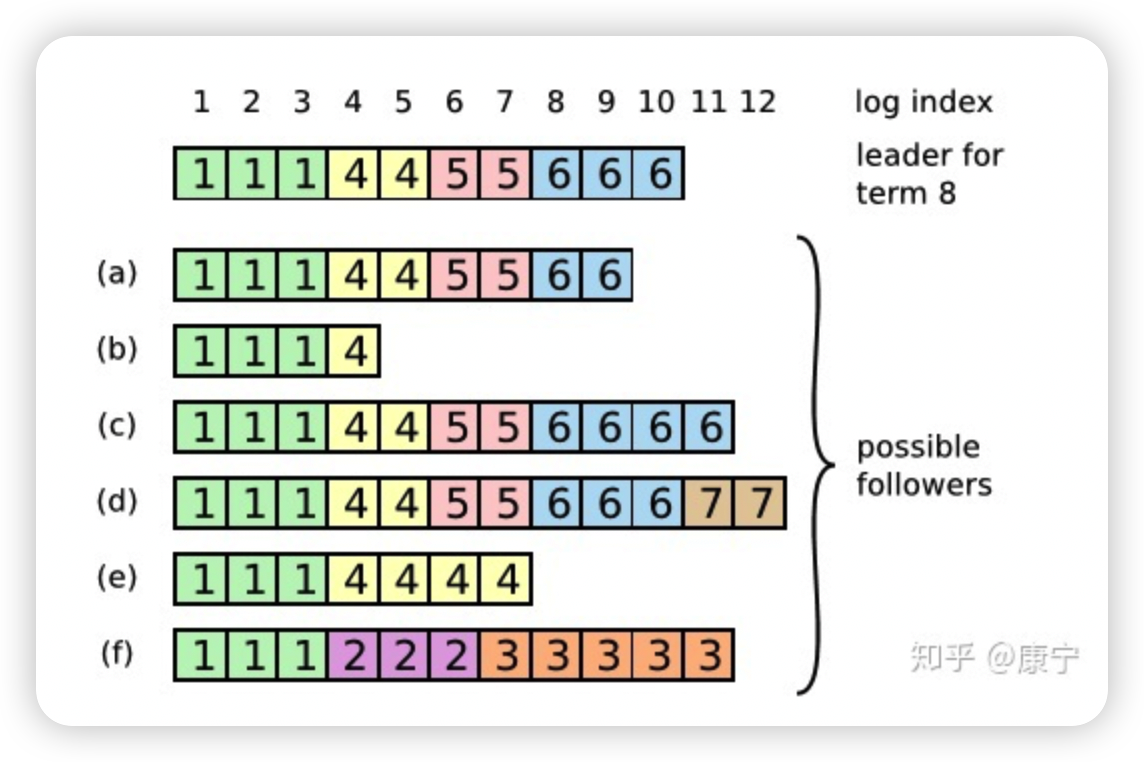
在上圖中,框內的數字是term編號,a、b丟失了一些命令,c、d多出來了一些命令,e、f既有丟失也有增多,這些情況都有可能發生。
比如f可能發生在這樣的情況下:f節點在term2時是leader,在此期間寫入了幾條命令,然后在提交之前崩潰了,在之后的term3中它很快重啟并再次成為leader,又寫入了幾條日志,在提交之前又崩潰了,等他蘇醒過來時新的leader來了,就形成了上圖情形。
在Raft中,leader通過強制follower復制自己的日志來解決上述日志不一致的情形,那么沖突的日志將會被重寫。為了讓日志一致,先找到最新的一致的那條日志(如f中索引為3的日志條目),然后把follower之后的日志全部刪除,leader再把自己在那之后的日志一股腦推送給follower,這樣就實現了一致。
而尋找該條日志,可以通過AppendEntries RPC,該RPC中包含著下一次要執行的命令索引,如果能和follower的當前索引對上,那就執行,否則拒絕,然后leader將會逐次遞減索引,直到找到相同的那條日志。
然而這樣也還是會有問題,比如某個follower在leader提交時宕機了,也就是少了幾條命令,然后它又經過選舉成了新的leader,這樣它就會強制其他follower跟自己一樣,使得其他節點上剛剛提交的命令被刪除,導致客戶端提交的一些命令被丟失了,下面一節內容將會解決這個問題。
Raft通過為選舉過程添加一個限制條件,解決了上面提出的問題,該限制確保leader包含之前term已經提交過的所有命令。Raft通過投票過程確保只有擁有全部已提交日志的candidate能成為leader。由于candidate為了拉選票需要通過RequestVote RPC聯系其他節點,而之前提交的命令至少會存在于其中某一個節點上,因此只要candidate的日志至少和其他大部分節點的一樣新就可以了,follower如果收到了不如自己新的candidate的RPC,就會將其丟棄。?
還可能會出現另外一個問題,如果命令已經被復制到了大部分節點上,但是還沒來的及提交就崩潰了,這樣后來的leader應該完成之前term未完成的提交。
Raft通過讓leader統計當前term內還未提交的命令已經被復制的數量是否半數以上,然后進行提交。
### 日志壓縮
隨著日志大小的增長,會占用更多的內存空間,處理起來也會耗費更多的時間,對系統的可用性造成影響,因此必須想辦法壓縮日志大小。
Snapshotting是最簡單的壓縮方法,系統的全部狀態會寫入一個snapshot保存起來,然后丟棄截止到snapshot時間點之前的所有日志。Raft中的snapshot內容如下圖所示:
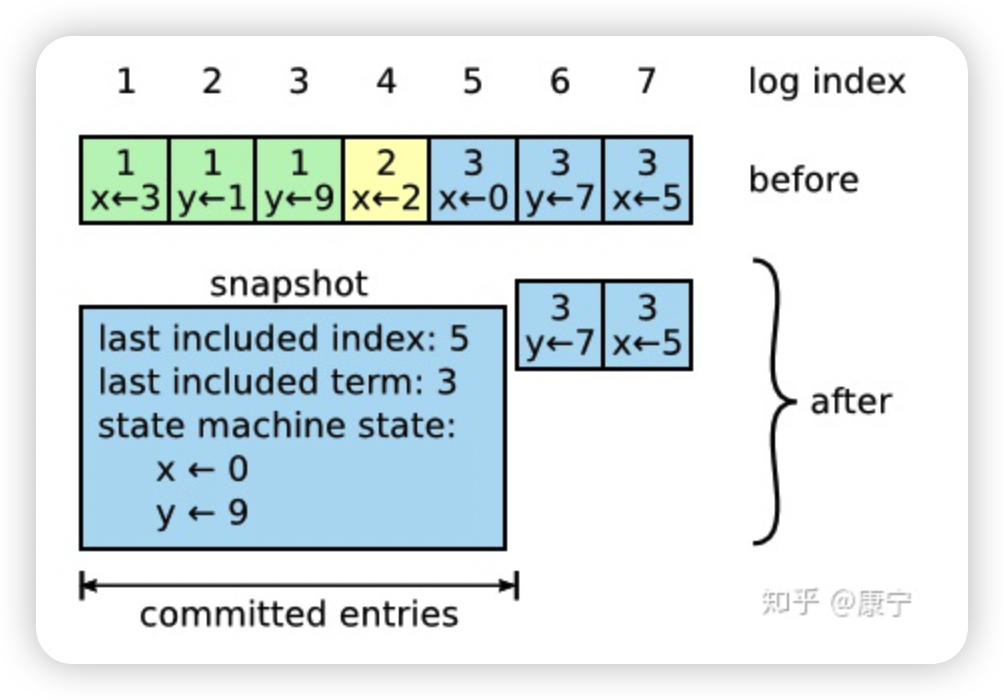
每一個server都有自己的snapshot,它只保存當前狀態,如上圖中的當前狀態為x=0,y=9,而last included index和last included term代表snapshot之前最新的命令,用于AppendEntries的狀態檢查。
雖然每一個server都保存有自己的snapshot,但是當follower嚴重落后于leader時,leader需要把自己的snapshot發送給follower加快同步,此時用到了一個新的RPC:InstallSnapshot RPC。follower收到snapshot時,需要決定如何處理自己的日志,如果收到的snapshot包含有更新的信息,它將丟棄自己已有的日志,按snapshot更新自己的狀態,如果snapshot包含的信息更少,那么它會丟棄snapshot中的內容,但是自己之后的內容會保存下來。
- Go準備工作
- 依賴管理
- Go基礎
- 1、變量和常量
- 2、基本數據類型
- 3、運算符
- 4、流程控制
- 5、數組
- 數組聲明和初始化
- 遍歷
- 數組是值類型
- 6、切片
- 定義
- slice其他內容
- 7、map
- 8、函數
- 函數基礎
- 函數進階
- 9、指針
- 10、結構體
- 類型別名和自定義類型
- 結構體
- 11、接口
- 12、反射
- 13、并發
- 14、網絡編程
- 15、單元測試
- Go常用庫/包
- Context
- time
- strings/strconv
- file
- http
- Go常用第三方包
- Go優化
- Go問題排查
- Go框架
- 基礎知識點的思考
- 面試題
- 八股文
- 操作系統
- 整理一份資料
- interface
- array
- slice
- map
- MUTEX
- RWMUTEX
- Channel
- waitGroup
- context
- reflect
- gc
- GMP和CSP
- Select
- Docker
- 基本命令
- dockerfile
- docker-compose
- rpc和grpc
- consul和etcd
- ETCD
- consul
- gin
- 一些小點
- 樹
- K8s
- ES
- pprof
- mycat
- nginx
- 整理后的面試題
- 基礎
- Map
- Chan
- GC
- GMP
- 并發
- 內存
- 算法
- docker