
[TOC]
## 數據結構
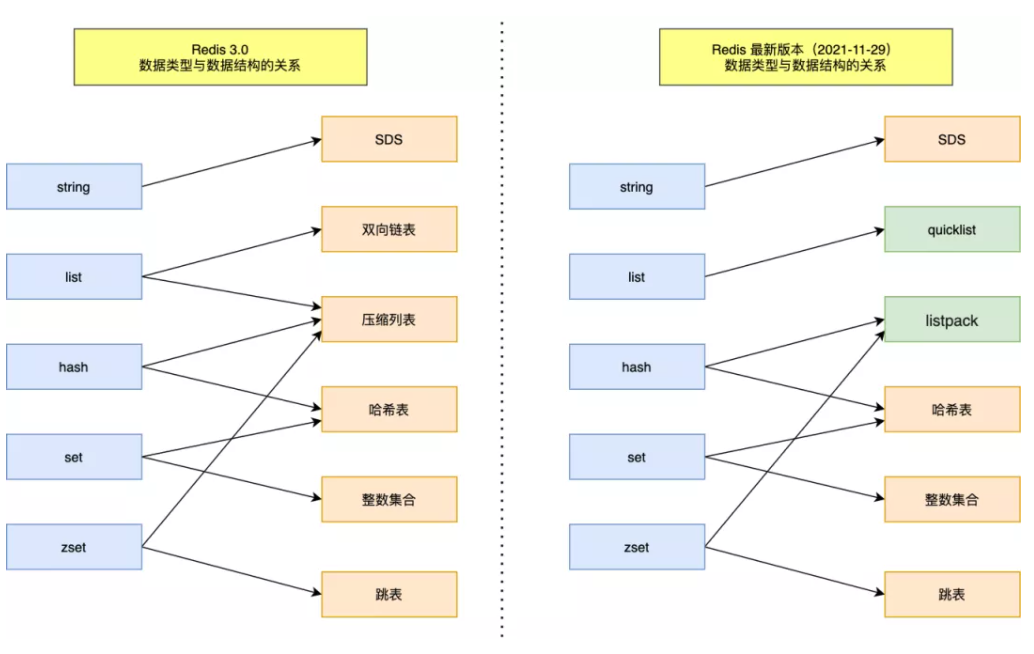
> 數據結構新舊共 9 種,**SDS、雙向鏈表、壓縮列表、哈希表、跳表、整數集合、quicklist、listpack。**
### 鍵值對數據庫是怎么實現的?
* set name "cccc"
* hset people name "cccc"
1、name是字符串的key,值是 字符串
2、people是哈希的key,值是 鍵值對的哈希表對象
#### 鍵值對是如何保存在 Redis 中的呢?
Redis 是使用了一個「哈希表」保存所有鍵值對,哈希表的最大好處就是讓我們可以用 O(1) 的時間復雜度來快速查找到鍵值對。哈希表其實就是一個數組,數組中的元素叫做哈希桶。
#### Redis 的哈希桶是怎么保存鍵值對數據的呢?
哈希桶存放的是指向鍵值對數據的指針(dictEntry\*),這樣通過指針就能找到鍵值對數據,然后因為鍵值對的值可以保存字符串對象和集合數據類型的對象,所以鍵值對的數據結構中并不是直接保存值本身,而是保存了 void \* key 和 void \* value 指針,分別指向了實際的鍵對象和值對象,這樣一來,即使值是集合數據,也可以通過 void \* value 指針找到。
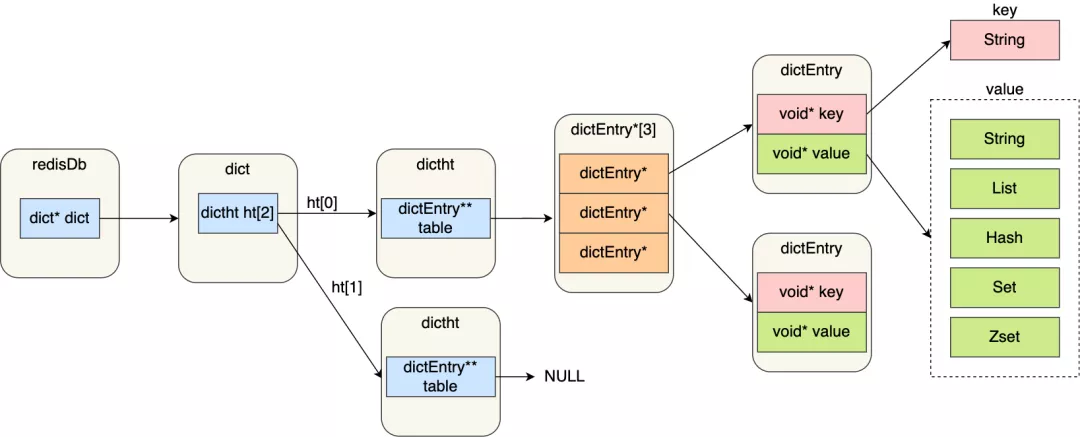
圖中涉及到的數據結構的名字和用途:
* redisDb 結構,表示 Redis 數據庫的結構,結構體里存放了指向了 dict 結構的指針;
* dict 結構,結構體里存放了 2 個哈希表,正常情況下都是用「哈希表1」,「哈希表2」只有在 rehash 的時候才用,具體什么是 rehash,我在本文的哈希表數據結構會講;
* ditctht 結構,表示哈希表的結構,結構里存放了哈希表數組,數組中的每個元素都是指向一個哈希表節點結構(dictEntry)的指針;
* dictEntry 結構,表示哈希表節點的結構,結構里存放了**void * key 和 void * value 指針, *key 指向的是 String 對象,而 *value 則可以指向 String 對象,也可以指向集合類型的對象,比如 List 對象、Hash 對象、Set 對象和 Zset 對象**。
void * key 和 void * value 指針指向的是**Redis 對象**,Redis 中的每個對象都由 redisObject 結構表示,如下圖:
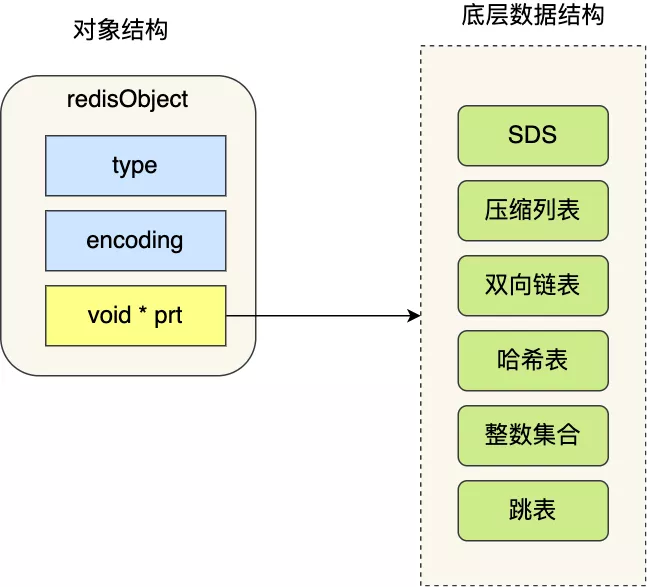
對象結構里包含的成員變量:
* type,標識該對象是什么類型的對象(String 對象、 List 對象、Hash 對象、Set 對象和 Zset 對象);
* encoding,標識該對象使用了哪種底層的數據結構;
* **ptr,指向底層數據結構的指針**
Redis 對象和數據結構的關系:

### SDS
#### 為什么沒有用C語言的原始的*char結構
* 獲取字符串長度的時間復雜度為 ?O(N);
* 字符串的結尾是以 “\0” 字符標識,字符串里面不能包含有 “\0” 字符因此不能保存二進制數據;
> eg:
str = 'xiaodingdang' len= 12
str= 'xiao\0dingdang' len= 4
* 字符串操作函數不高效且不安全,比如有緩沖區溢出的風險,有可能會造成程序運行終止;
#### redis5.0的SDS 數據結構

* **len,記錄了字符串長度**。這樣獲取字符串長度的時候,只需要返回這個成員變量值就行,時間復雜度只需要 O(1)。
* **alloc,分配給字符數組的空間長度**。這樣在修改字符串的時候,可以通過`alloc - len`計算出剩余的空間大小,可以用來判斷空間是否滿足修改需求,如果不滿足的話,就會自動將 SDS ?的空間擴展至執行修改所需的大小,然后才執行實際的修改操作,所以使用 SDS 既不需要手動修改 SDS 的空間大小,也不會出現前面所說的緩沖區溢出的問題。
* **flags,用來表示不同類型的 SDS**。一共設計了 5 種類型,分別是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64
* **buf[],字符數組,用來保存實際數據**。不僅可以保存字符串,也可以保存二進制數據。
** 通過len、allock、flags解決了C的缺陷
>1、O(1)復雜度獲取字符串長度
2、二進制安全,不再需要“\0”字符來標識字符串結尾了,長度由len直接返回,然后buf[]存儲的數據沒有任何限制,寫入和讀取的是一樣的,而且也能保存二進制數據
3、不會發生緩沖區溢出,因為引入了 alloc 和 len 成員變量,在計算剩余空間時,通過`alloc - len`計算,**當判斷出緩沖區大小不夠用時,Redis 會自動將擴大 SDS 的空間大小(小于 1MB 翻倍擴容,大于 1MB 按 1MB 擴容)**,為了**有效的減少內存分配次數**,在檢查空間是否夠用時,除了分配修改所必須要的空間,還會給 SDS 分配額外的「未使用空間」
4、節省內存空間,不再內存對齊
### 鏈表
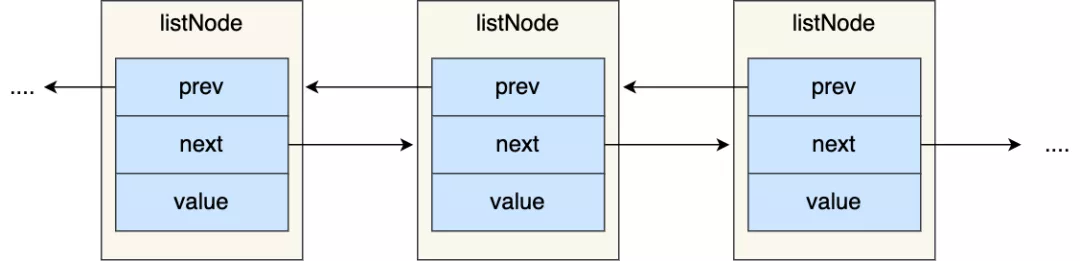
#### 鏈表節點結構設計
~~~
typedef struct?listNode?{
//前置節點
struct?listNode?*prev;
//后置節點
struct?listNode?*next;
//節點的值
void?*value;
}?listNode;
~~~
有前置和后置節點,
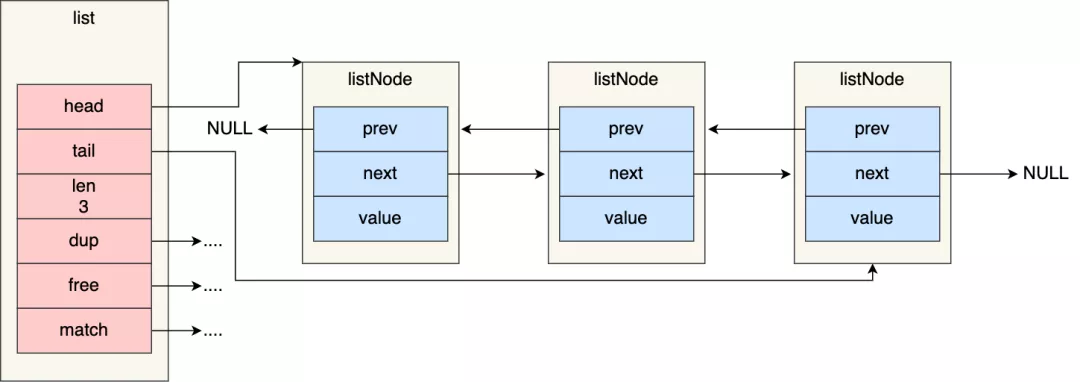
#### 鏈表結構設計
Redis 在 listNode 結構體基礎上又封裝了 list 這個數據結構,這樣操作起來會更方便,鏈表結構如下:
~~~
typedef struct?list?{
//鏈表頭節點
????listNode?*head;
//鏈表尾節點
????listNode?*tail;
//節點值復制函數
void?*(*dup)(void?*ptr);
//節點值釋放函數
void?(*free)(void?*ptr);
//節點值比較函數
int?(*match)(void?*ptr,?void?*key);
//鏈表節點數量
unsignedlong?len;
}?list;
~~~
list 結構為鏈表提供了鏈表頭指針 head、鏈表尾節點 tail、鏈表節點數量 len、以及可以自定義實現的 dup、free、match 函數。
#### 鏈表的優勢與缺陷
Redis 的鏈表實現優點如下:
* listNode 鏈表節點的結構里帶有 prev 和 next 指針,**獲取某個節點的前置節點或后置節點的時間復雜度只需O(1),而且這兩個指針都可以指向 NULL,所以鏈表是無環鏈表**;
* list 結構因為提供了表頭指針 head 和表尾節點 tail,所以**獲取鏈表的表頭節點和表尾節點的時間復雜度只需O(1)**;
* list 結構因為提供了鏈表節點數量 len,所以**獲取鏈表中的節點數量的時間復雜度只需O(1)**;
* listNode 鏈表節使用 void\* 指針保存節點值,并且可以通過 list 結構的 dup、free、match 函數指針為節點設置該節點類型特定的函數,因此**鏈表節點可以保存各種不同類型的值**;
鏈表的缺陷也是有的:
* 鏈表每個節點之間的內存都是不連續的,意味著**無法很好利用 CPU 緩存**。能很好利用 CPU 緩存的數據結構就是數組,因為數組的內存是連續的,這樣就可以充分利用 CPU 緩存來加速訪問。
* 即使保存一個鏈表節點的值都需要一個鏈表節點結構頭的分配,**內存開銷較大**。
因此,Redis 3.0 的 List 對象在數據量比較少的情況下,會采用「壓縮列表」作為底層數據結構的實現,它的優勢是節省內存空間,并且是內存緊湊型的數據結構。
### 壓縮列表
壓縮列表的最大特點,就是它被設計成一種內存緊湊型的數據結構,占用一塊連續的內存空間,不僅可以利用 CPU 緩存,而且會針對不同長度的數據,進行相應編碼,這種方法可以有效地節省內存開銷。
#### 壓縮列表結構設計
壓縮列表是 Redis 為了節約內存而開發的,它是**由連續內存塊組成的順序型數據結構**,有點類似于數組。

壓縮列表在表頭有三個字段:
* ***zlbytes***,記錄整個壓縮列表占用對內存字節數;
* ***zltail***,記錄壓縮列表「尾部」節點距離起始地址由多少字節,也就是列表尾的偏移量;
* ***zllen***,記錄壓縮列表包含的節點數量;
* ***zlend***,標記壓縮列表的結束點,固定值 0xFF(十進制255)。
在壓縮列表中,如果我們要查找定位第一個元素和最后一個元素,可以通過表頭三個字段的長度直接定位,復雜度是 O(1)。而**查找其他元素時,就沒有這么高效了,只能逐個查找,此時的復雜度就是 O(N) 了,因此壓縮列表不適合保存過多的元素**。
#### 壓縮列表節點(entry)的構成如下:
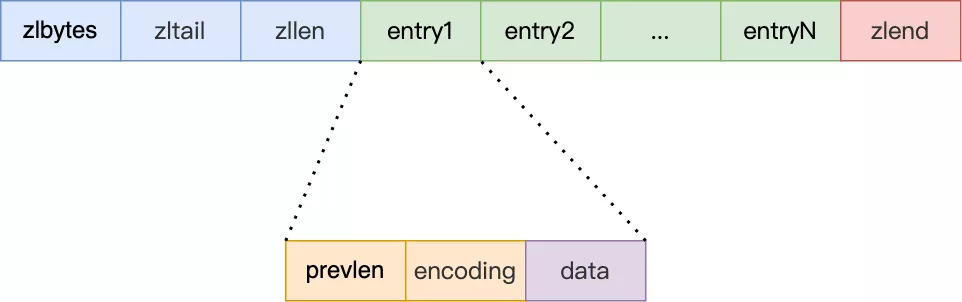
壓縮列表節點包含三部分內容:
* ***prevlen***,記錄了「前一個節點」的長度;
* ***encoding***,記錄了當前節點實際數據的類型以及長度;
* ***data***,記錄了當前節點的實際數據;
往壓縮列表中插入數據時,壓縮列表就會根據數據是字符串還是整數,以及數據的大小,會使用不同空間大小的 prevlen 和 encoding 這兩個元素里保存的信息,**這種根據數據大小和類型進行不同的空間大小分配的設計思想,正是 Redis 為了節省內存而采用的**。
>prevlen 和 encoding 是如何根據數據的大小和類型來進行不同的空間大小分配。
壓縮列表里的每個節點中的 ?prevlen 屬性都記錄了「前一個節點的長度」
prevlen 屬性的空間大小跟前一個節點長度值有關,
>* 如果**前一個節點的長度小于 254 字節**,那么 prevlen 屬性需要用**1 字節的空間**來保存這個長度值;
>* 如果**前一個節點的長度大于等于 254 字節**,那么 prevlen 屬性需要用**5 字節的空間**來保存這個長度值;
encoding 屬性的空間大小跟數據是字符串還是整數,以及字符串的長度有關:
>* 如果**當前節點的數據是整數**,則 encoding 會使用**1 字節的空間**進行編碼。
>* 如果**當前節點的數據是字符串,根據字符串的長度大小**,encoding 會使用**1 字節/2字節/5字節的空間**進行編碼。
#### 壓縮列表的缺陷:
* 不能保存過多的元素,否則查詢效率就會降低;
* 新增或修改某個元素時,壓縮列表占用的內存空間需要重新分配,甚至可能引發**連鎖更新**的問題。
因此,Redis 對象(List 對象、Hash 對象、Zset 對象)包含的元素數量較少,或者元素值不大的情況才會使用壓縮列表作為底層數據結構。
#### 連鎖更新
壓縮列表新增某個元素或修改某個元素時,如果空間不不夠,壓縮列表占用的內存空間就需要重新分配。而當新插入的元素較大時,可能會導致后續元素的 prevlen 占用空間都發生變化,從而引起「連鎖更新」問題,導致每個元素的空間都要重新分配,造成訪問壓縮列表性能的下降。
### quicklist
quicklist 就是「雙向鏈表 + 壓縮列表」組合,因為一個 quicklist 就是一個鏈表,而鏈表中的每個元素又是一個壓縮列表。
為了解決【連鎖更新】,**通過控制每個鏈表節點中的壓縮列表的大小或者元素個數,來規避連鎖更新的問題。因為壓縮列表元素越少或越小,連鎖更新帶來的影響就越小,從而提供了更好的訪問性能。**
#### quicklist 結構設計
~~~
typedef struct?quicklist?{
//quicklist的鏈表頭
????quicklistNode?*head;??
//quicklist的鏈表尾
????quicklistNode?*tail;?
//所有壓縮列表中的總元素個數
unsignedlong?count;
//quicklistNodes的個數
unsignedlong?len;???????
????...
}?quicklist;
~~~
quicklistNode 的結構定義:
~~~
typedef struct?quicklistNode?{
//前一個quicklistNode
struct?quicklistNode?*prev;
//下一個quicklistNode
struct?quicklistNode?*next;
//quicklistNode指向的壓縮列表
unsignedchar?*zl;??????????????
//壓縮列表的的字節大小
unsignedint?sz;????????????????
//壓縮列表的元素個數
unsignedint?count?:?16;????????//ziplist中的元素個數?
????....
}?quicklistNode;
~~~
可以看到,quicklistNode 結構體里包含了前一個節點和下一個節點指針,這樣每個 quicklistNode 形成了一個雙向鏈表。但是鏈表節點的元素不再是單純保存元素值,而是保存了一個壓縮列表,所以 quicklistNode 結構體里有個指向壓縮列表的指針 *zl。
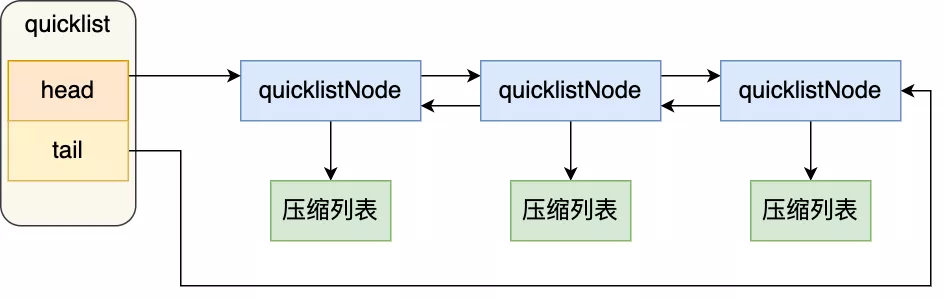
在向 quicklist 添加一個元素的時候,不會像普通的鏈表那樣,直接新建一個鏈表節點。而是會檢查插入位置的壓縮列表是否能容納該元素,如果能容納就直接保存到 quicklistNode 結構里的壓縮列表,如果不能容納,才會新建一個新的 quicklistNode 結構。
quicklist 會控制 quicklistNode 結構里的壓縮列表的大小或者元素個數,來規避潛在的連鎖更新的風險,但是這并沒有完全解決連鎖更新的問題。
### 哈希表
#### 簡介
哈希表優點在于,它**能以 O(1) 的復雜度快速查詢數據**(將 key 通過 Hash 函數的計算,就能定位數據在表中的位置,因為哈希表實際上是數組,所以可以通過索引值快速查詢到數據。)
但是存在的風險也是有,在哈希表大小固定的情況下,隨著數據不斷增多,那么**哈希沖突**的可能性也會越高。
>解決哈希沖突的方式,有很多種。
**Redis 采用了「鏈式哈希」來解決哈希沖突**,在不擴容哈希表的前提下,將具有相同哈希值的數據串起來,形成鏈接起,以便這些數據在表中仍然可以被查詢到。
#### 哈希表結構設計
哈希表結構如下:
~~~
typedef struct?dictht?{
//哈希表數組
????dictEntry?**table;
//哈希表大小
unsignedlong?size;??
//哈希表大小掩碼,用于計算索引值
unsignedlong?sizemask;
//該哈希表已有的節點數量
unsignedlong?used;
}?dictht;
~~~
哈希表是一個數組(dictEntry \*\*table),數組的每個元素是一個指向「哈希表節點(dictEntry)」的指針
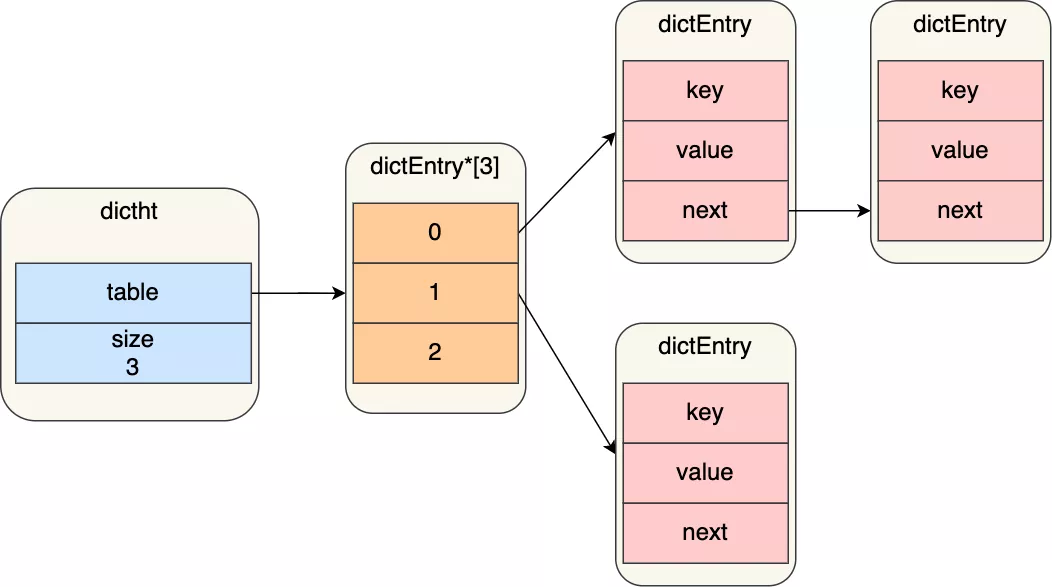
哈希表節點的結構如下:
~~~
typedef struct?dictEntry?{
//鍵值對中的鍵
void?*key;
//鍵值對中的值
union?{
void?*val;
uint64_t?u64;
int64_t?s64;
double?d;
????}?v;
//指向下一個哈希表節點,形成鏈表
struct?dictEntry?*next;
}?dictEntry;
~~~
dictEntry 結構里不僅包含指向鍵和值的指針,還包含了指向下一個哈希表節點的指針,這個指針可以將多個哈希值相同的鍵值對鏈接起來,以此來解決哈希沖突的問題,這就是鏈式哈希。
dictEntry 結構里鍵值對中的值是一個「聯合體 v」定義的,因此,鍵值對中的值可以是一個指向實際值的指針,或者是一個無符號的 64 位整數或有符號的 64 位整數或double 類的值。這么做的好處是可以節省內存空間,因為當「值」是整數或浮點數時,就可以將值的數據內嵌在 dictEntry 結構里,無需再用一個指針指向實際的值,從而節省了內存空間。
#### 哈希沖突
**當有兩個以上數量的 key 被分配到了哈希表中同一個哈希桶上時,此時稱這些 key 發生了沖突。**
#### 鏈式哈希
Redis 采用了「**鏈式哈希**」的方法來解決哈希沖突。
>鏈式哈希是怎么實現的?
每個哈希表節點都有一個 next 指針,用于指向下一個哈希表節點,因此多個哈希表節點可以用 next 指針構成一個單項鏈表,**被分配到同一個哈希桶上的多個節點可以用這個單項鏈表連接起來**,這樣就解決了哈希沖突。
鏈式哈希局限性也很明顯,隨著鏈表長度的增加,在查詢這一位置上的數據的耗時就會增加,因為鏈表的查詢的時間復雜度是 O(n)。要想解決這一問題,就需要進行 rehash,也就是對哈希表的大小進行擴展。
#### rehash
dict 結構體,定義了兩個哈希表
~~~
typedef struct?dict?{
????…
//兩個Hash表,交替使用,用于rehash操作
????dictht?ht[2];?
????…
}?dict;
~~~
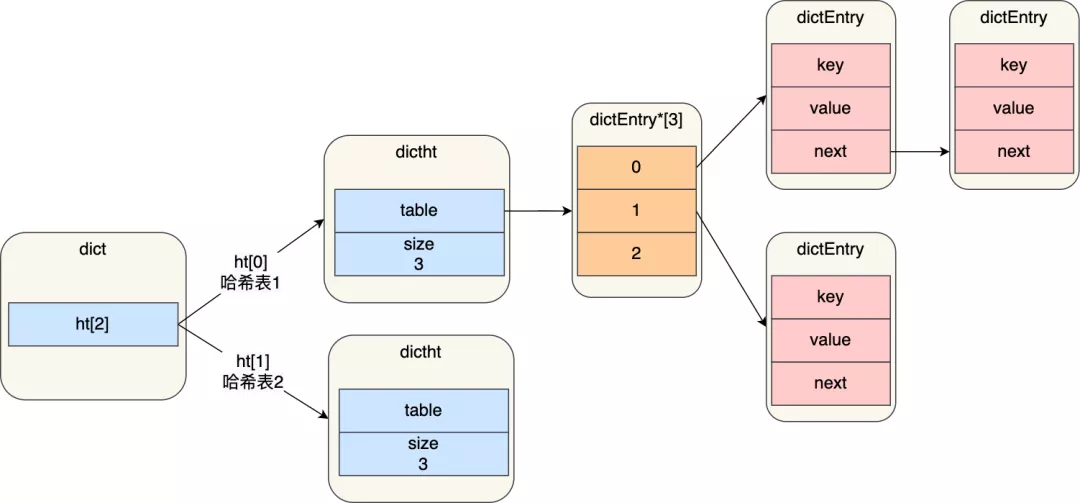
在正常服務請求階段,插入的數據,都會寫入到「哈希表 1」,此時的「哈希表 2 」 并沒有被分配空間。
隨著數據逐步增多,觸發了 rehash 操作,這個過程分為三步:
* 給「哈希表 2」 分配空間,一般會比「哈希表 1」 大 2 倍;
* 將「哈希表 1 」的數據遷移到「哈希表 2」 中;
* 遷移完成后,「哈希表 1 」的空間會被釋放,并把「哈希表 2」 設置為「哈希表 1」,然后在「哈希表 2」 新創建一個空白的哈希表,為下次 rehash 做準備。
**如果「哈希表 1 」的數據量非常大,那么在遷移至「哈希表 2 」的時候,因為會涉及大量的數據拷貝,此時可能會對 Redis 造成阻塞,無法服務其他請求**。
#### 漸進式 rehash
漸進式 rehash 步驟如下:
* 給「哈希表 2」 分配空間;
* **在 rehash 進行期間,每次哈希表元素進行新增、刪除、查找或者更新操作時,Redis 除了會執行對應的操作之外,還會順序將「哈希表 1 」中索引位置上的所有 key-value 遷移到「哈希表 2」 上**;
* 隨著處理客戶端發起的哈希表操作請求數量越多,最終在某個時間點,會把「哈希表 1 」的所有 key-value 遷移到「哈希表 2」,從而完成 rehash 操作。
>在進行漸進式 rehash 的過程中,會有兩個哈希表,所以在漸進式 rehash 進行期間,哈希表元素的刪除、查找、更新等操作都會在這兩個哈希表進行。新增的key-value都會保存到「哈希表 2」,這樣「哈希表 1」就會越來越少,直至為空
#### rehash 觸發條件
rehash 的觸發條件跟**負載因子(load factor)**有關系。
計算公式:

觸發 rehash 操作的條件,主要有兩個:
* **當負載因子大于等于 1 ,并且 Redis 沒有在執行 bgsave 命令或者 bgrewiteaof 命令,也就是沒有執行 RDB 快照或沒有進行 AOF 重寫的時候,就會進行 rehash 操作。**
* **當負載因子大于等于 5 時,此時說明哈希沖突非常嚴重了,不管有沒有有在執行 RDB 快照或 AOF 重寫,都會強制進行 rehash 操作。**
### 整數集合
>當一個 Set 對象只包含整數值元素,并且元素數量不多時,就會使用整數集這個數據結構作為底層實現
#### 整數集合結構設計
整數集合本質上是一塊連續內存空間,它的結構定義如下:
~~~
typedef struct?intset?{
//編碼方式
uint32_t?encoding;
//集合包含的元素數量
uint32_t?length;
//保存元素的數組
int8_t?contents[];
}?intset;
~~~
contents 被聲明為 int8_t 類型的數組,但是實際上 contents 數組并不保存任何 int8_t 類型的元素,contents 數組的真正類型取決于 intset 結構體里的 encoding 屬性的值。比如:
* 如果 encoding 屬性值為 INTSET_ENC_INT16,那么 contents 就是一個 int16_t 類型的數組,數組中每一個元素的類型都是 int16_t;
* 如果 encoding 屬性值為 INTSET_ENC_INT32,那么 contents 就是一個 int32_t 類型的數組,數組中每一個元素的類型都是 int32_t;
* 如果 encoding 屬性值為 INTSET_ENC_INT64,那么 contents 就是一個 int64_t 類型的數組,數組中每一個元素的類型都是 int64_t;
不同類型的 contents 數組,意味著數組的大小也會不同。
#### 整數集合的升級操作
整數集合會有一個升級規則,就是當我們將一個新元素加入到整數集合里面,如果新元素的類型(int32_t)比整數集合現有所有元素的類型(int16_t)都要長時,整數集合需要先進行升級,也就是按新元素的類型(int32_t)擴展 contents 數組的空間大小,然后才能將新元素加入到整數集合里,當然升級的過程中,也要維持整數集合的有序性。
整數集合升級的過程不會重新分配一個新類型的數組,而是在原本的數組上擴展空間,然后在將每個元素按間隔類型大小分割,如果 encoding 屬性值為 INTSET_ENC_INT16,則每個元素的間隔就是 16 位。
eg:
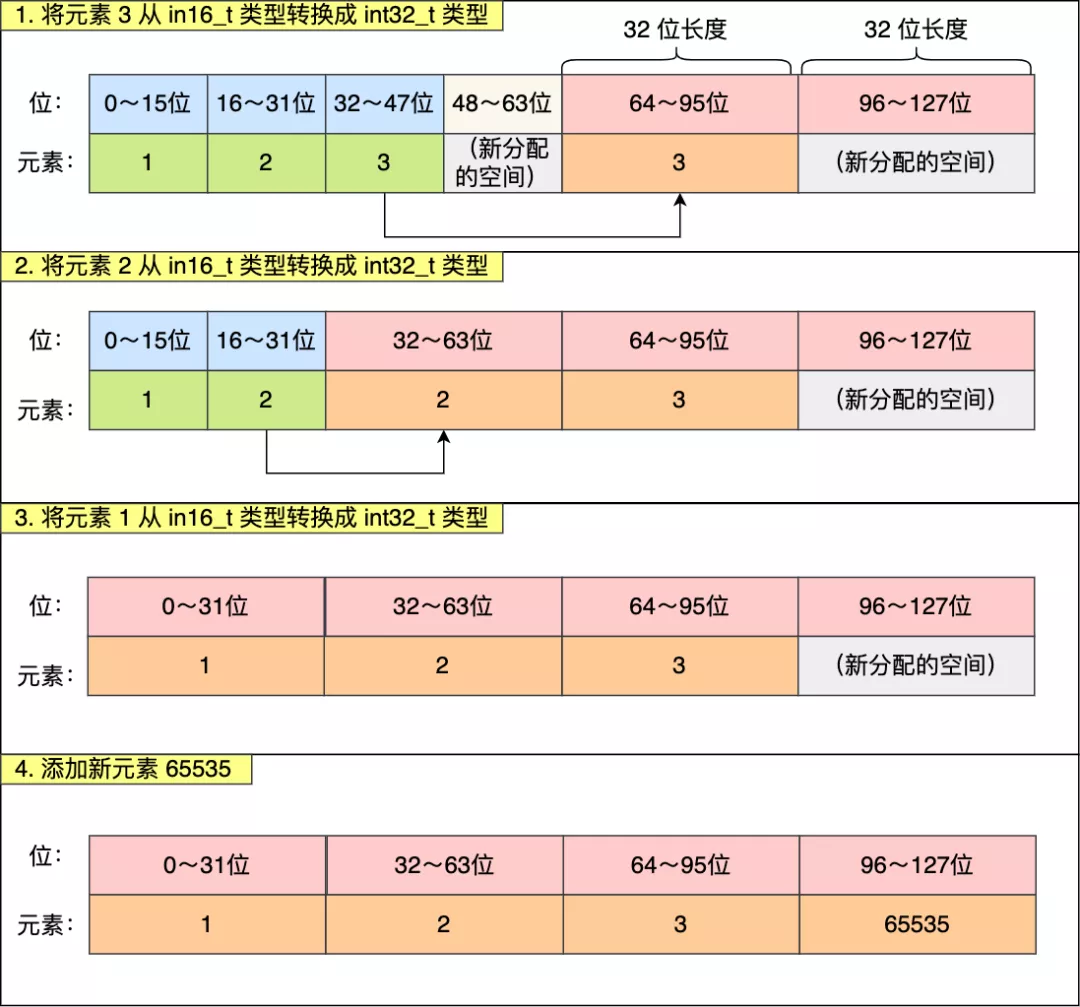
往這個整數集合中加入一個新元素 65535,這個新元素需要用 int32\_t 類型來保存,所以整數集合要進行升級操作,首先需要為 contents 數組擴容,**在原本空間的大小之上再擴容多 80 位(4x32-3x16=80),這樣就能保存下 4 個類型為 int32_t 的元素**。

擴容完 contents 數組空間大小后,需要將之前的三個元素轉換為 int32\_t 類型,并將轉換后的元素放置到正確的位上面,并且需要維持底層數組的有序性不變,整個轉換過程如下:
#### 整數集合升級有什么好處呢?
避免資源浪費,**節省內存資源**,如果一直向整數集合添加 int16_t 類型的元素,那么整數集合的底層實現就一直是用 int16_t 類型的數組,只有在我們要將 int32_t 類型或 int64_t 類型的元素添加到集合時,才會對數組進行升級操作。
**不支持降級操作**
### 跳表
跳表的優勢是能支持平均 O(logN) 復雜度的節點查找。采用了兩種數據結構,一個是跳表,一個是哈希表。這樣的好處是既能進行高效的范圍查詢,也能進行高效單點查詢。
https://blog.csdn.net/weixin_41622183/article/details/91126155 跳表
「跳表」結構體了,如下所示:
~~~
typedef?struct?zskiplist?{ ????
struct?zskiplistNode?*header,?*tail; ????
unsigned?long?length; ???
?int?level;
}?zskiplist;
~~~
跳表結構里包含了:
* 跳表的頭尾節點,便于在O(1)時間復雜度內訪問跳表的頭節點和尾節點;
* 跳表的長度,便于在O(1)時間復雜度獲取跳表節點的數量;
* 跳表的最大層數,便于在O(1)時間復雜度獲取跳表中層高最大的那個節點的層數量;
zset 對象:
~~~
typedef struct?zset?{
????dict?*dict;
????zskiplist?*zsl;
}?zset;
~~~
Zset 對象能支持范圍查詢(如 ZRANGEBYSCORE 操作),這是因為它的數據結構設計采用了跳表,而又能以常數復雜度獲取元素權重(如 ZSCORE 操作),這是因為它同時采用了哈希表進行索引。
#### 跳表結構設計
鏈表在查找元素的時候,因為需要逐一查找,所以查詢效率非常低,時間復雜度是O(N),于是就出現了跳表。**跳表是在鏈表基礎上改進過來的,實現了一種「多層」的有序鏈表**,這樣的好處是能快讀定位數據。
可以看到,這個查找過程就是在多個層級上跳來跳去,最后定位到元素。當數據量很大時,跳表的查找復雜度就是 O(logN)。
那跳表節點是怎么實現多層級的呢?這就需要看「跳表節點」的數據結構了,如下:
~~~
typedef struct?zskiplistNode?{
//Zset?對象的元素值
????sds?ele;
//元素權重值
double?score;
//后向指針
struct?zskiplistNode?*backward;
//節點的level數組,保存每層上的前向指針和跨度
struct?zskiplistLevel?{
struct?zskiplistNode?*forward;
unsignedlong?span;
????}?level[];
}?zskiplistNode;
~~~
Zset 對象要同時保存元素和元素的權重,對應到跳表節點結構里就是 sds 類型的 ele 變量和 double 類型的 score 變量。每個跳表節點都有一個后向指針,指向前一個節點,目的是為了方便從跳表的尾節點開始訪問節點,這樣倒序查找時很方便。
跳表是一個帶有層級關系的鏈表,而且每一層級可以包含多個節點,每一個節點通過指針連接起來,實現這一特性就是靠跳表節點結構體中的**zskiplistLevel 結構體類型的 level 數組**。
level 數組中的每一個元素代表跳表的一層,也就是由 zskiplistLevel 結構體表示,比如 leve\[0\] 就表示第一層,leve\[1\] 就表示第二層。zskiplistLevel 結構體里定義了「指向下一個跳表節點的指針」和「跨度」,跨度時用來記錄兩個節點之間的距離。
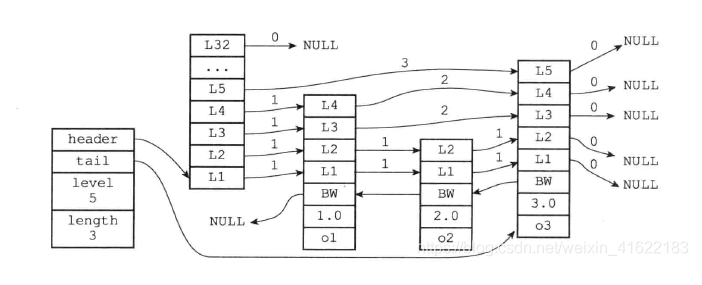
比如,下面這張圖,展示了各個節點的跨度。

第一眼看到跨度的時候,以為是遍歷操作有關,實際上并沒有任何關系,遍歷操作只需要用前向指針就可以完成了。
**跨度實際上是為了計算這個節點在跳表中的排位**。具體怎么做的呢?因為跳表中的節點都是按序排列的,那么計算某個節點排位的時候,從頭節點點到該結點的查詢路徑上,將沿途訪問過的所有層的跨度累加起來,得到的結果就是目標節點在跳表中的排位。
舉個例子,查找圖中節點 3 在跳表中的排位,從頭節點開始查找節點 3,查找的過程只經過了一個層(L2),并且層的跨度是 3,所以節點 3 在跳表中的排位是 3。
另外,圖中的頭節點其實也是 zskiplistNode 跳表節點,只不過頭節點的后向指針、權重、元素值都會被用到,所以圖中省略了這部分。
#### 跳表節點查詢過程
查找一個跳表節點的過程時,跳表會從頭節點的最高層開始,逐一遍歷每一層。在遍歷某一層的跳表節點時,會用跳表節點中的 SDS 類型的元素和元素的權重來進行判斷,共有兩個判斷條件:
* 如果當前節點的權重「小于」要查找的權重時,跳表就會訪問該層上的下一個節點。
* 如果當前節點的權重「等于」要查找的權重時,并且當前節點的 SDS 類型數據「小于」要查找的數據時,跳表就會訪問該層上的下一個節點。
如果上面兩個條件都不滿足,或者下一個節點為空時,跳表就會使用目前遍歷到的節點的 level 數組里的下一層指針,然后沿著下一層指針繼續查找,這就相當于跳到了下一層接著查找。
舉個例子,下圖有個 3 層級的跳表。

如果要查找「元素:abcd,權重:4」的節點,查找的過程是這樣的:
* 先從頭節點的最高層開始,L2 指向了「元素:abc,權重:3」節點,這個節點的權重比要查找節點的小,所以要訪問該層上的下一個節點;
* 但是該層上的下一個節點是空節點,于是就會跳到「元素:abc,權重:3」節點的下一層去找,也就是 leve\[1\];
* 「元素:abc,權重:3」節點的 ?leve\[1\] 的下一個指針指向了「元素:abcde,權重:4」的節點,然后將其和要查找的節點比較。雖然「元素:abcde,權重:4」的節點的權重和要查找的權重相同,但是當前節點的 SDS 類型數據「大于」要查找的數據,所以會繼續跳到「元素:abc,權重:3」節點的下一層去找,也就是 leve\[0\];
* 「元素:abc,權重:3」節點的 leve\[0\] 的下一個指針指向了「元素:abcd,權重:4」的節點,該節點正是要查找的節點,查詢結束。
#### 跳表節點層數設置
跳表的相鄰兩層的節點數量的比例會影響跳表的查詢性能。
舉個例子,下圖的跳表,第二層的節點數量只有 1 個,而第一層的節點數量有 7 個。

這時,如果想要查詢節點 6,那基本就跟鏈表的查詢復雜度一樣,就需要在第一層的節點中依次順序查找,復雜度就是 O(N) 了。所以,為了降低查詢復雜度,我們就需要維持相鄰層結點數間的關系。
**跳表的相鄰兩層的節點數量最理想的比例是 2:1,查找復雜度可以降低到 O(logN)**。
下圖的跳表就是,相鄰兩層的節點數量的比例是 2 : 1。

> 那怎樣才能維持相鄰兩層的節點數量的比例為 2 : 1 ?呢?
如果采用新增節點或者刪除節點時,來調整跳表節點以維持比例的方法的話,會帶來額外的開銷。
Redis 則采用一種巧妙的方法是,**跳表在創建節點的時候,隨機生成每個節點的層數**,并沒有嚴格維持相鄰兩層的節點數量比例為 2 : 1 的情況。
具體的做法是,**跳表在創建節點時候,會生成范圍為\[0-1\]的一個隨機數,如果這個隨機數小于 0.25(相當于概率 25%),那么層數就增加 1 層,然后繼續生成下一個隨機數,直到隨機數的結果大于 0.25 結束,最終確定該節點的層數**。
這樣的做法,相當于每增加一層的概率不超過 25%,層數越高,概率越低,層高最大限制是 64。
### listpack
它最大特點是每個節點不再包含前一個節點的長度了,壓縮列表每個節點正因為需要保存前一個節點的長度字段,就會有連鎖更新的隱患。
#### listpack 結構設計
listpack 采用了壓縮列表的很多優秀的設計,比如還是用一塊連續的內存空間來緊湊地保存數據,并且為了節省內存的開銷,listpack 節點會采用不同的編碼方式保存不同大小的數據。

listpack 頭包含兩個屬性,分別記錄了 listpack 總字節數和元素數量,然后 listpack 末尾也有個結尾標識。圖中的 listpack entry 就是 listpack 的節點。

主要包含三個方面內容:
* encoding,定義該元素的編碼類型,會對不同長度的整數和字符串進行編碼;
* data,實際存放的數據;
* len,encoding+data的總長度;
可以看到,**listpack 沒有壓縮列表中記錄前一個節點長度的字段了,listpack 只記錄當前節點的長度,當我們向 listpack 加入一個新元素的時候,不會影響其他節點的長度字段的變化,從而避免了壓縮列表的連鎖更新問題**。
## 類型、編碼轉換、數據結構
| 類型 | 數據結構 | 編碼轉換 |
| --- | --- | --- |
| String | SDS 動態字符串 | **int**(保存的是可以用long類型表示的整數值)、**raw**(保存長度大于44字節的字符串)、**embstr**( 保存長度小于44字節的字符串) |
| List | linkedList(雙端鏈表) zipList(壓縮鏈表) | zipList(列表保存元素個數小于512個、每個元素長度小于64字節) 不能滿足上面兩個條件使用linkedlist(雙端列表)編碼 |
| Hash | hashtable zipList |當同時滿足下面兩個條件使用ziplist編碼,否則使用hashtable編碼 **1.列表保存元素個數小于512個 2.每個元素長度小于64字節** |
| Set | intset(整型數組) hashtable | 當集合滿足下列兩個條件時,使用intset編碼,否則使用hashtable **1. 集合對象中的所有元素都是整數 2.集合對象所有元素數量不超過512** |
| Sort Set | zipList、skipList | 同時滿足下面兩個條件時使用zipList,否則用skipList:**1.列表保存元素個數小于512個 2. 每個元素長度小于64字節** |
## Redis 的對象 **redisObject**
redisobject最主要的信息:
~~~
redisobject源碼
typedef struct redisObject{
//類型 代表一個value對象具體是何種數據類型
unsigned type:4;
//編碼
unsigned encoding:4;
//指向底層數據結構的指針
void *ptr;
//引用計數
int refcount;
//記錄最后一次被程序訪問的時間
unsigned lru:22;
}robj
~~~
## 處理命令的過程
當執行一個處理數據類型的命令時,Redis執行以下步驟:
* 根據給定`key`,在數據庫字典中查找和它相對應的`redisObject`,如果沒找到,就返回`NULL`。
* 檢查`redisObject`的`type`屬性和執行命令所需的類型是否相符,如果不相符,返回類型錯誤。
* 根據`redisObject`的`encoding`屬性所指定的編碼,選擇合適的操作函數來處理底層的數據結構。
* 返回數據結構的操作結果作為命令的返回值。
- 消息隊列
- 為什么要用消息隊列
- 各種消息隊列產品的對比
- 消息隊列的優缺點
- 如何保證消息隊列的高可用
- 如何保證消息不丟失
- 如何保證消息不會重復消費?如何保證消息的冪等性?
- 如何保證消息消費的順序性?
- 基于MQ的分布式事務實現
- Beanstalk
- PHP
- 函數
- 基礎
- 基礎函數題
- OOP思想及原則
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收機制
- php-fpm相關
- 高級
- 設計模式
- 排序算法
- 正則
- OOP代碼基礎
- PHP運行原理
- zavl
- 網絡協議new
- 一面
- TCP和UDP
- 常見狀態碼和代表的意義以及解決方式
- 網絡分層和各層有啥協議
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 鎖
- 索引
- 事務
- 高可用?高并發?集群?
- 其他
- 主從復制
- 主從復制數據延遲
- SQL的語?分類
- mysqlQuestions
- Redis
- redis-question
- redis為什么那么快
- redis的優缺點
- redis的數據類型和使用場景
- redis的數據持久化
- 過期策略和淘汰機制
- 緩存穿透、緩存擊穿、緩存雪崩
- redis的事務
- redis的主從復制
- redis集群架構的理解
- redis的事件模型
- redis的數據類型、編碼、數據結構
- Redis連接時的connect與pconnect的區別是什么?
- redis的分布式鎖
- 緩存一致性問題
- redis變慢的原因
- 集群情況下,節點較少時數據分布不均勻怎么辦?
- redis 和 memcached 的區別?
- 基本算法
- MysqlNew
- 索引new
- 事務new
- 鎖new
- 日志new
- 主從復制new
- 樹結構
- mysql其他問題
- 刪除
- 主從配置
- 五種IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何實現手機掃碼登錄功能
- laravel框架的生命周期