
[TOC]
## mysql主從同步
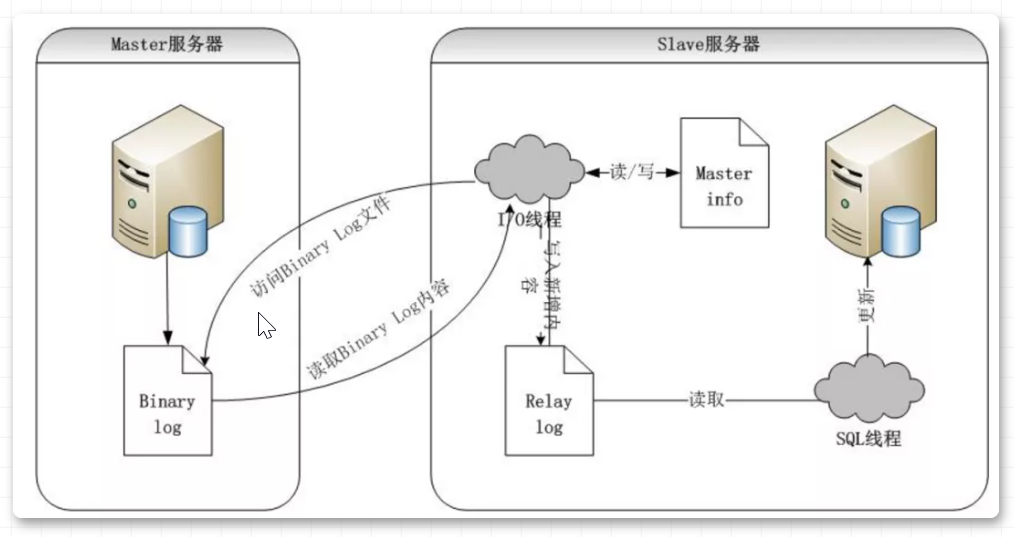
* 1.master 主庫將此次更新的事件類型**「寫入到主庫的 binlog 文件」**中
* 2.master**「創建 log dump 線程通知 slave」**需要更新數據
* 3.**「slave」**向 master 節點發送請求,**「將該 binlog 文件內容存到本地的 relaylog 中」**
* 4.**「slave 開啟 sql 線程」**讀取 relaylog 中的內容,**「將其中的內容在本地重新執行一遍」**,完成主從數據同步
**「同步策略」**:
* 1.**「全同步復制」**:主庫強制同步日志到從庫,等全部從庫執行完才返回客戶端,性能差
* 2.**「半同步復制」**:主庫收到至少一個從庫確認就認為操作成功,從庫寫入日志成功返回ack確認
這個更全面,回答時先回答上面兩條:
1. 「全同步策略」:Master會等待所有的Slave都回應后才會提交,這個主從的同步會受到嚴重的影響。
2. 「半同步策略」:Master至少會等待一個Slave回應后提交。
3. 「異步策略」:Master不用等待Slave回應就可以提交。
4. 「延遲策略」:Slave要落后于Master指定的時間。
## 主從延遲要怎么解決?
* 1.MySQL 5.6 版本以后,提供了一種**「并行復制」**的方式,通過將 SQL 線程轉換為多個 work 線程來進行重放
* 2.**「提高機器配置」**(王道)
* 3.在業務初期就選擇合適的分庫、分表策略,**「避免單表單庫過大」**帶來額外的復制壓力
* 4.**「避免長事務」**
* 5.**「避免讓數據庫進行各種大量運算」**
* 6.對于一些對延遲很敏感的業務**「直接使用主庫讀」**
## MySQL 主從復制原理的是啥?
主庫將變更寫入 binlog 日志,然后從庫連接到主庫之后,從庫有一個 IO 線程,將主庫的 binlog 日志拷貝到自己本地,寫入一個 relay 中繼日志中。接著從庫中有一個 SQL 線程會從中繼日志讀取 binlog,然后執行 binlog 日志中的內容,也就是在自己本地再次執行一遍 SQL,這樣就可以保證自己跟主庫的數據是一樣的。
這里有一個非常重要的一點,就是從庫同步主庫數據的過程是串行化的,也就是說主庫上并行的操作,在從庫上會串行執行。所以這就是一個非常重要的點了,由于從庫從主庫拷貝日志以及串行執行 SQL 的特點,在高并發場景下,從庫的數據一定會比主庫慢一些,是有延時的。所以經常出現,剛寫入主庫的數據可能是讀不到的,要過幾十毫秒,甚至幾百毫秒才能讀取到。
而且這里還有另外一個問題,就是如果主庫突然宕機,然后恰好數據還沒同步到從庫,那么有些數據可能在從庫上是沒有的,有些數據可能就丟失了。 所以 MySQL 實際上在這一塊有兩個機制,一個是半同步復制,用來解決主庫數據丟失問題;一個是并行復制,用來解決主從同步延時問題。
這個所謂半同步復制,也叫 semi-sync 復制,指的就是主庫寫入 binlog 日志之后,就會強制立即將數據同步到從庫,從庫將日志寫入自己本地的 relay log 之后,接著會返回一個 ack 給主庫,主庫接收到至少一個從庫的 ack 之后才會認為寫操作完成了。 所謂并行復制,指的是從庫開啟多個線程,并行讀取 relay log 中不同庫的日志,然后并行重放不同庫的日志,這是庫級別的并行。
## MySQL 主從同步延時問題
以前線上確實處理過因為主從同步延時問題而導致的線上的 bug,屬于小型的生產事故。 是這個么場景。有個同學是這樣寫代碼邏輯的。先插入一條數據,再把它查出來,然后更新這條數據。在生產環境高峰期,寫并發達到了 2000/s,這個時候,主從復制延時大概是在小幾十毫秒。線上會發現,每天總有那么一些數據,我們期望更新一些重要的數據狀態,但在高峰期時候卻沒更新。用戶跟客服反饋,而客服就會反饋給我們。
我們通過 MySQL 命令:
~~~
show status
~~~
查看 Seconds\_Behind\_Master,可以看到從庫復制主庫的數據落后了幾 ms。 一般來說,如果主從延遲較為嚴重,有以下解決方案:
1. 分庫,將一個主庫拆分為多個主庫,每個主庫的寫并發就減少了幾倍,此時主從延遲可以忽略不計。【此時是主庫的執行性能可能不好】
2. 打開 MySQL 支持的并行復制,多個庫并行復制。如果說某個庫的寫入并發就是特別高,單庫寫并發達到了 2000/s,并行復制還是沒意義。
3. 重寫代碼,寫代碼的同學,要慎重,插入數據時立馬查詢可能查不到。
4. 如果確實是存在必須先插入,立馬要求就查詢到,然后立馬就要反過來執行一些操作,對這個查詢設置直連主庫。不推薦這種方法,你要是這么搞,讀寫分離的意義就喪失了。
- 消息隊列
- 為什么要用消息隊列
- 各種消息隊列產品的對比
- 消息隊列的優缺點
- 如何保證消息隊列的高可用
- 如何保證消息不丟失
- 如何保證消息不會重復消費?如何保證消息的冪等性?
- 如何保證消息消費的順序性?
- 基于MQ的分布式事務實現
- Beanstalk
- PHP
- 函數
- 基礎
- 基礎函數題
- OOP思想及原則
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收機制
- php-fpm相關
- 高級
- 設計模式
- 排序算法
- 正則
- OOP代碼基礎
- PHP運行原理
- zavl
- 網絡協議new
- 一面
- TCP和UDP
- 常見狀態碼和代表的意義以及解決方式
- 網絡分層和各層有啥協議
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 鎖
- 索引
- 事務
- 高可用?高并發?集群?
- 其他
- 主從復制
- 主從復制數據延遲
- SQL的語?分類
- mysqlQuestions
- Redis
- redis-question
- redis為什么那么快
- redis的優缺點
- redis的數據類型和使用場景
- redis的數據持久化
- 過期策略和淘汰機制
- 緩存穿透、緩存擊穿、緩存雪崩
- redis的事務
- redis的主從復制
- redis集群架構的理解
- redis的事件模型
- redis的數據類型、編碼、數據結構
- Redis連接時的connect與pconnect的區別是什么?
- redis的分布式鎖
- 緩存一致性問題
- redis變慢的原因
- 集群情況下,節點較少時數據分布不均勻怎么辦?
- redis 和 memcached 的區別?
- 基本算法
- MysqlNew
- 索引new
- 事務new
- 鎖new
- 日志new
- 主從復制new
- 樹結構
- mysql其他問題
- 刪除
- 主從配置
- 五種IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何實現手機掃碼登錄功能
- laravel框架的生命周期