
[TOC]
https://mp.weixin.qq.com/s/bb7C6VNbq7REP9u8PsreSg
應用程序的IO操作分為兩種動作:**IO調用和IO執行**。IO調用是由進程(應用程序的運行態)發起,而IO執行是**操作系統內核**的工作。
## 操作系統的一次IO過程
應用程序發起的一次IO操作包含兩個階段:
* IO調用:應用程序進程向操作系統**內核**發起調用。
* IO執行:操作系統內核完成IO操作。
操作系統內核完成IO操作還包括兩個過程:
* 準備數據階段:內核等待I/O設備準備好數據
* 拷貝數據階段:將數據從內核緩沖區拷貝到用戶進程緩沖區
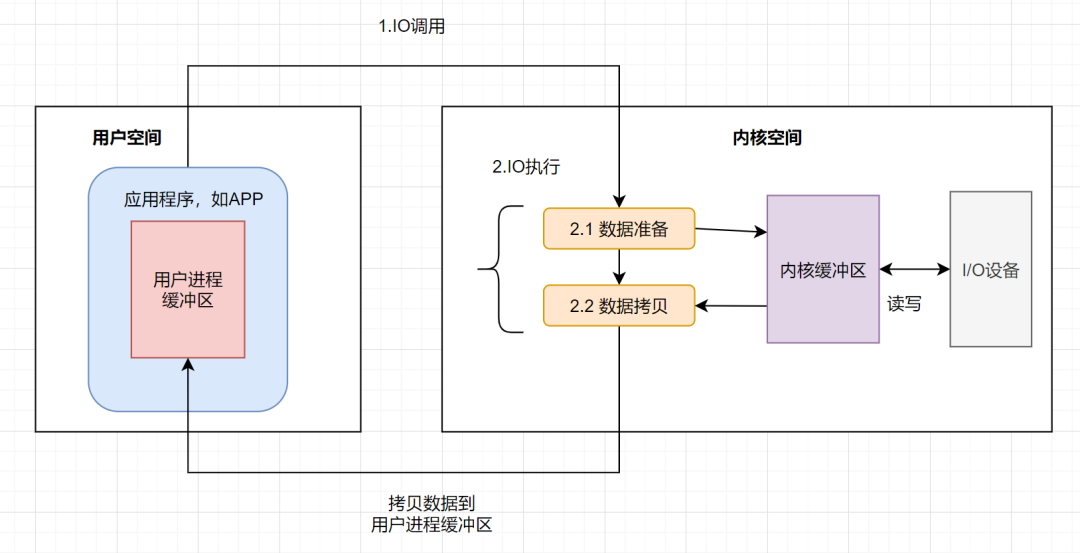
其實IO就是把進程的內部數據轉移到外部設備,或者把外部設備的數據遷移到進程內部。外部設備一般指硬盤、socket通訊的網卡。一個完整的**IO過程**包括以下幾個步驟:
* 應用程序進程向操作系統發起**IO調用請求**
* 操作系統**準備數據**,把IO外部設備的數據,加載到**內核緩沖區**
* 操作系統拷貝數據,即將內核緩沖區的數據,拷貝到用戶進程緩沖區
## 阻塞IO模型
阻塞IO:應用程序的進程發起**IO調用**,但**內核的數據還沒準備好**,應用程序進程就一直在**阻塞等待**,一直等到內核數據準備好了,從內核拷貝到用戶空間,才返回成功提示
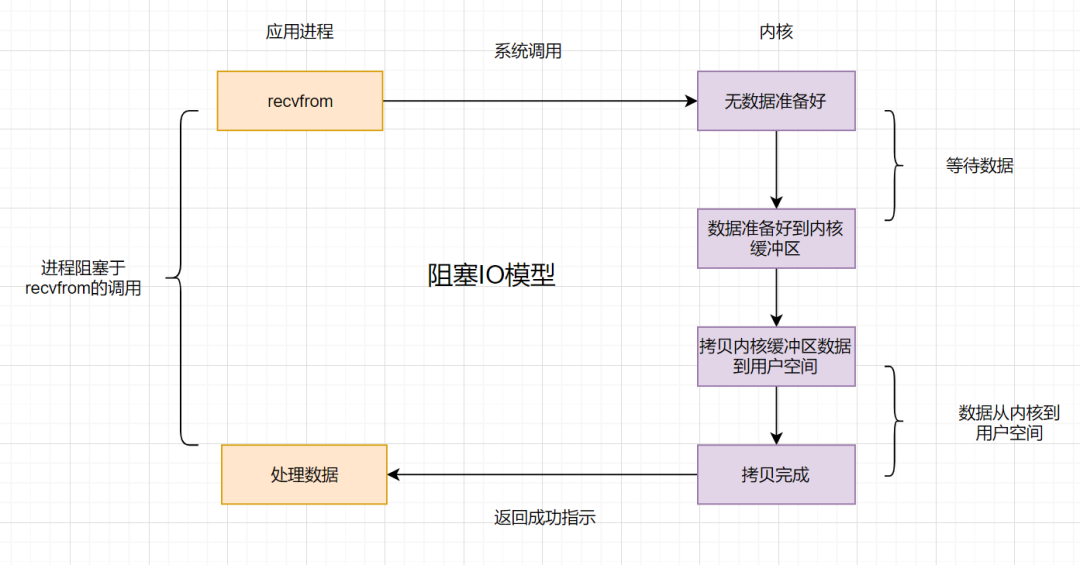
* 阻塞IO比較經典的應用就是**阻塞socket、Java BIO**。
* 阻塞IO的缺點就是:如果內核數據一直沒準備好,那用戶進程將一直阻塞,**浪費性能**,可以使用**非阻塞IO**優化。
## 非阻塞IO模型
非阻塞IO:如果內核數據還沒準備好,可以先返回錯誤信息給用戶進程,讓它不需要等待,而是通過輪詢的方式再來請求
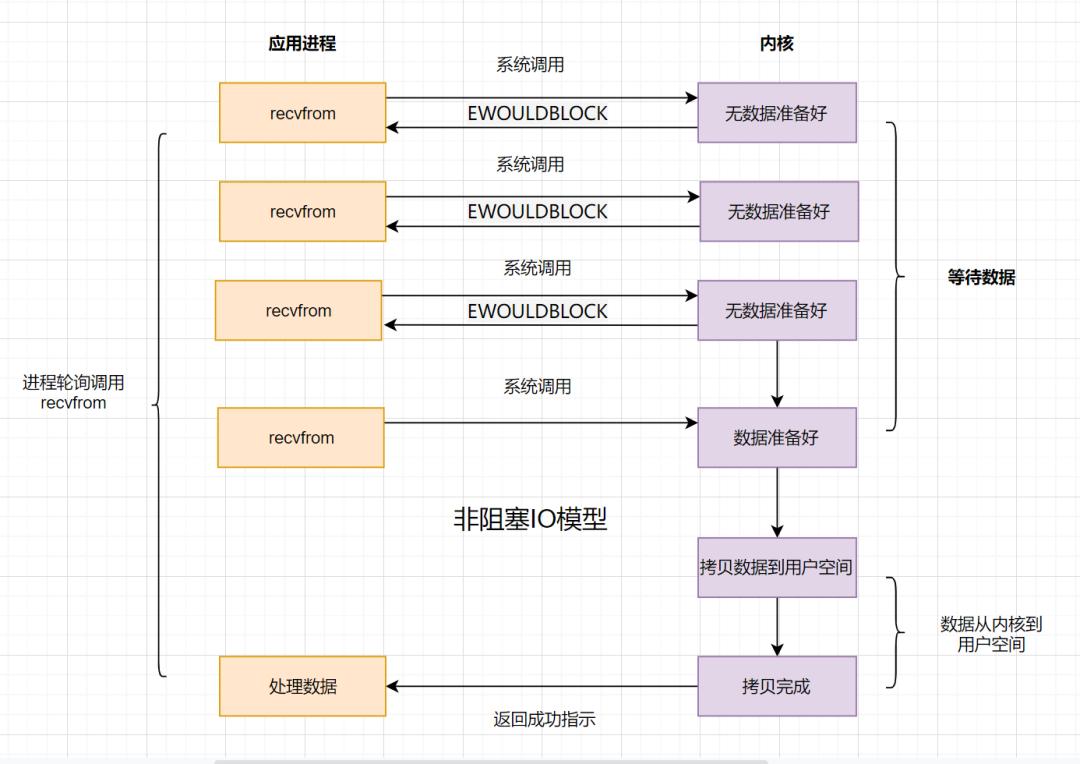
非阻塞IO的流程如下:
* 應用進程向操作系統內核,發起`recvfrom`讀取數據。
* 操作系統內核數據沒有準備好,立即返回`EWOULDBLOCK`錯誤碼。
* 應用程序進程輪詢調用,繼續向操作系統內核發起`recvfrom`讀取數據。
* 操作系統內核數據準備好了,從內核緩沖區拷貝到用戶空間。
* 完成調用,返回成功提示。
非阻塞IO模型,簡稱**NIO**,`Non-Blocking IO`。它相對于阻塞IO,雖然大幅提升了性能,但是它依然存在**性能問題**,即**頻繁的輪詢**,導致頻繁的系統調用,同樣會消耗大量的CPU資源。可以考慮**IO復用模型**,去解決這個問題。
## IO多路復用模型
### IO復用模型核心思路
系統給我們提供**一類函數**(如我們耳濡目染的**select、poll、epoll**函數),它們可以同時監控多個`fd`的操作,任何一個返回內核數據就緒,應用進程再發起`recvfrom`系統調用。
### IO多路復用之select
應用進程通過調用**select**函數,可以同時監控多個`fd`,在`select`函數監控的`fd`中,只要有任何一個數據狀態準備就緒了,`select`函數就會返回可讀狀態,這時應用進程再發起`recvfrom`請求去讀取數據。
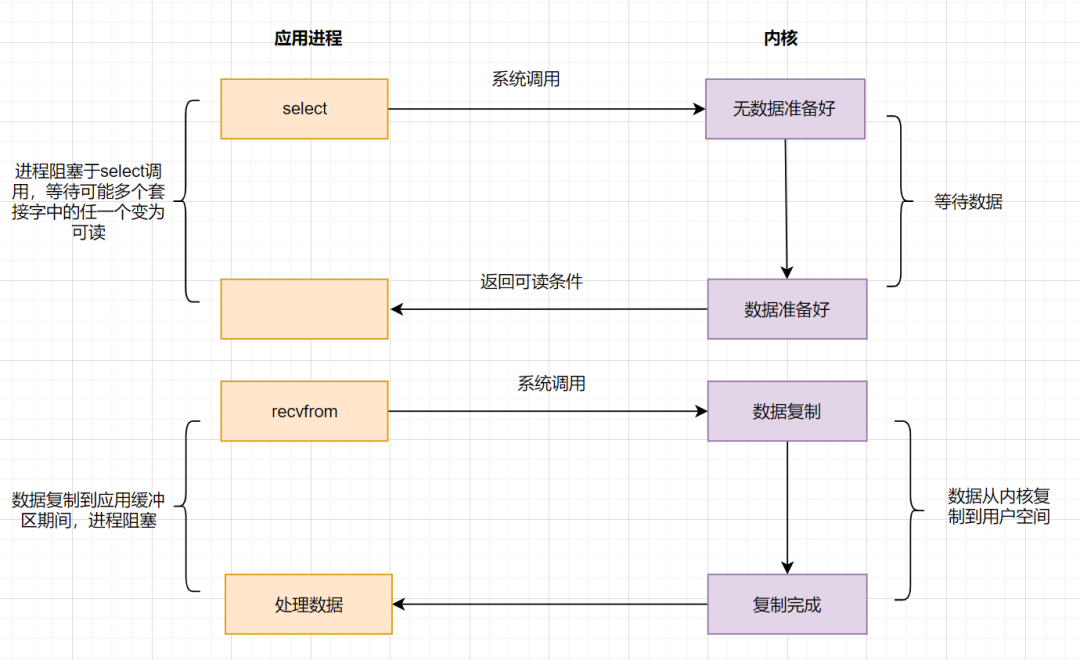
非阻塞IO模型(NIO)中,需要`N`(N>=1)次輪詢系統調用,然而借助`select`的IO多路復用模型,只需要發起一次詢問就夠了,大大優化了性能。
### 缺點
* 監聽的IO最大連接數有限,在Linux系統上一般為1024。
* select函數返回后,是通過**遍歷**`fdset`,找到就緒的描述符`fd`。(僅知道有I/O事件發生,卻不知是哪幾個流,所以**遍歷所有流**)
因為**存在連接數限制**,所以后來又提出了**poll**。與select相比,**poll**解決了**連接數限制問題**。但是呢,select和poll一樣,還是需要通過遍歷文件描述符來獲取已經就緒的`socket`。如果同時連接的大量客戶端,在一時刻可能只有極少處于就緒狀態,伴隨著監視的描述符數量的增長,**效率也會線性下降**。
### IO多路復用之epoll
為了解決`select/poll`存在的問題,多路復用模型`epoll`誕生,它采用事件驅動來實現。
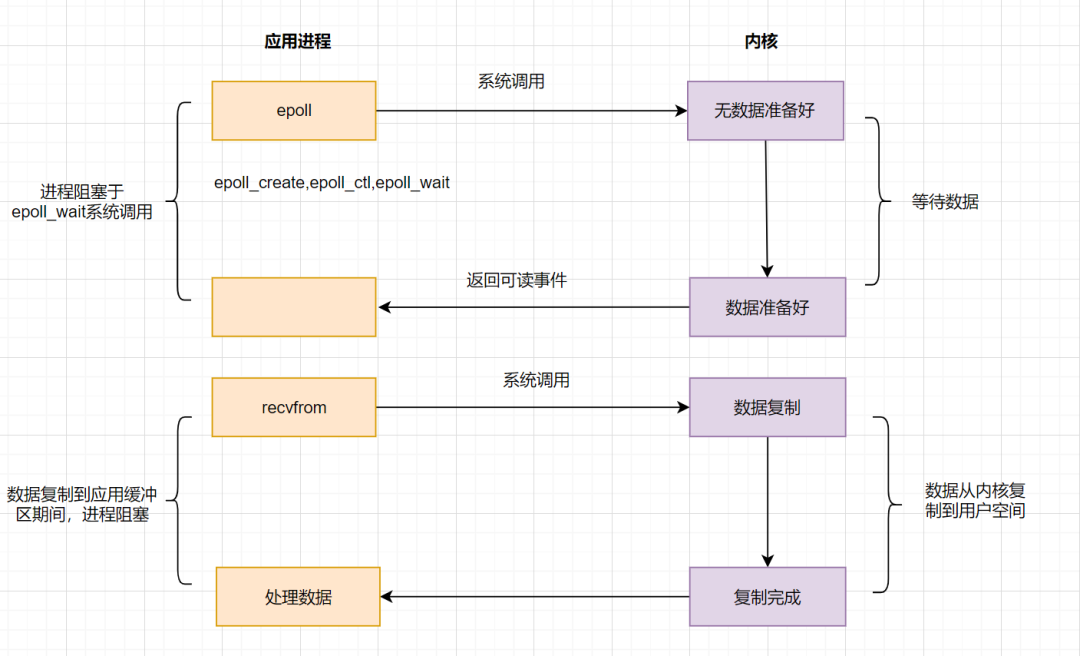
**epoll**先通過`epoll_ctl()`來注冊一個`fd`(文件描述符),一旦基于某個`fd`就緒時,內核會采用回調機制,迅速激活這個`fd`,當進程調用`epoll_wait()`時便得到通知。
采用**監聽事件回調**的機制
| select | poll | epoll |
| --- | --- | --- |
| 底層數據結構 | 數組 | 鏈表 | 紅黑樹和雙鏈表 |
| 獲取就緒的fd | 遍歷 | 遍歷 | 事件回調 |
| 事件復雜度 | O(n) | O(n) | O(1) |
| 最大連接數 | 1024 | 無限制 | 無限制 |
| fd數據拷貝 | 每次調用select,需要將fd數據從用戶空間拷貝到內核空間 | 每次調用poll,需要將fd數據從用戶空間拷貝到內核空間 | 使用內存映射(mmap),不需要從用戶空間頻繁拷貝fd數據到內核空間 |
**epoll**明顯優化了IO的執行效率,但在進程調用`epoll_wait()`時,仍然可能被阻塞
## IO模型之信號驅動模型
信號驅動IO不再用主動詢問的方式去確認數據是否就緒,而是向內核發送一個信號(調用`sigaction`的時候建立一個`SIGIO`的信號),然后應用用戶進程可以去做別的事,不用阻塞。當內核數據準備好后,再通過`SIGIO`信號通知應用進程,數據準備好后的可讀狀態。應用用戶進程收到信號之后,立即調用`recvfrom`,去讀取數據。
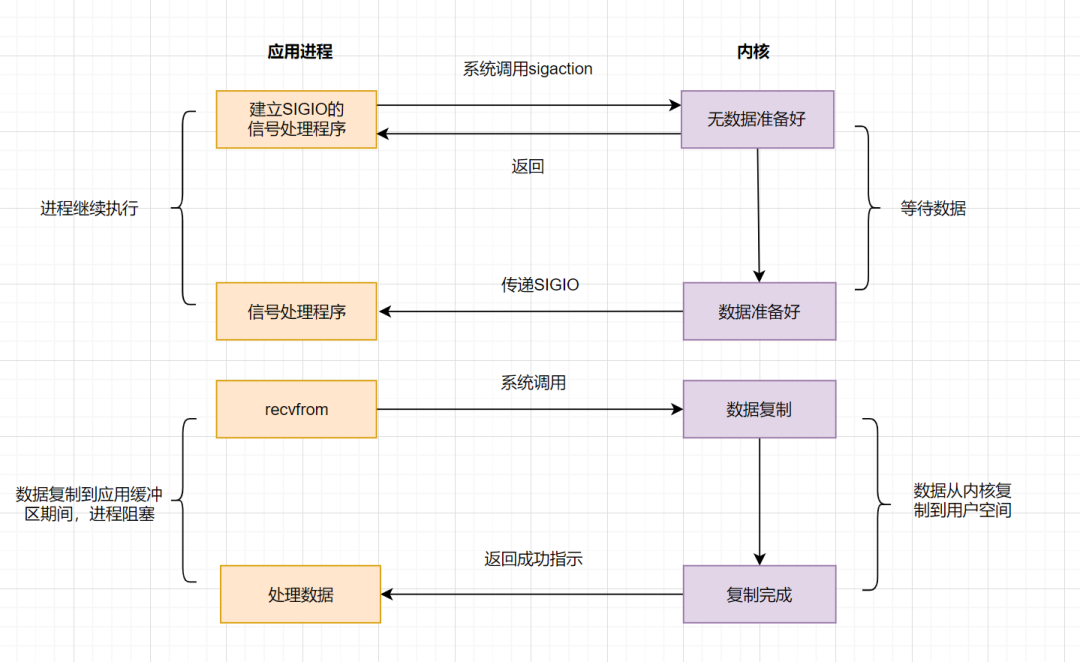
信號驅動IO模型,在應用進程發出信號后,是立即返回的,不會阻塞進程。它已經有異步操作的感覺了。但是你細看上面的流程圖,**發現數據復制到應用緩沖的時候**,應用進程還是阻塞的。回過頭來看下,不管是BIO,還是NIO,還是信號驅動,在數據從內核復制到應用緩沖的時候,都是阻塞的。還有沒有優化方案呢?**AIO**(真正的異步IO)!
## IO 模型之異步IO(AIO)
前面講的`BIO,NIO和信號驅動`,在數據從內核復制到應用緩沖的時候,都是**阻塞**的,因此都不算是真正的異步。
`AIO`實現了IO全流程的非阻塞,就是應用進程發出系統調用后,是立即返回的,但是**立即返回的不是處理結果,而是表示提交成功類似的意思**。等內核數據準備好,將數據拷貝到用戶進程緩沖區,發送信號通知用戶進程IO操作執行完畢。
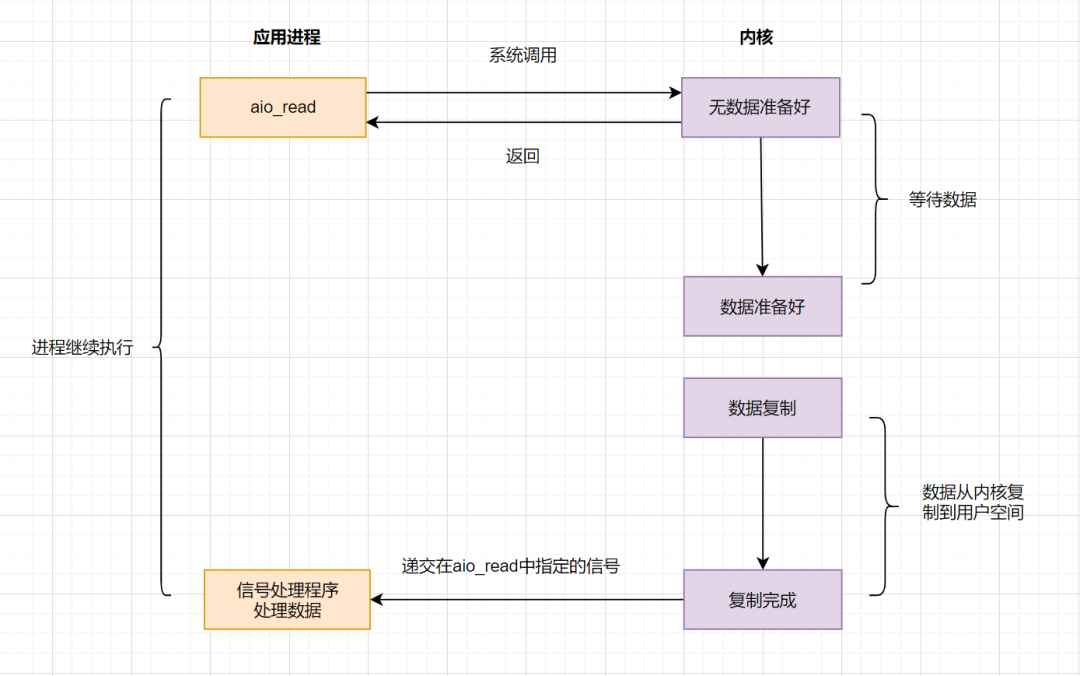
異步IO的優化思路很簡單,只需要向內核發送一次請求,就可以完成數據狀態詢問和數據拷貝的所有操作,并且不用阻塞等待結果。
日常開發中,有類似思想的業務場景:
>比如發起一筆批量轉賬,但是批量轉賬處理比較耗時,這時候后端可以先告知前端轉賬提交成功,等到結果處理完,再通知前端結果即可。
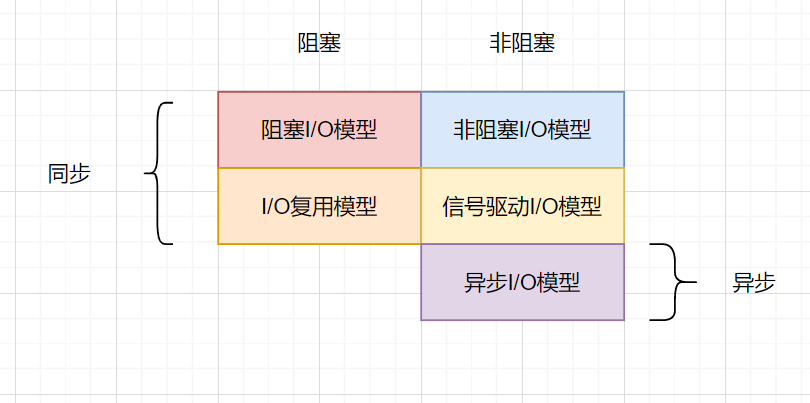
| IO模型 | |
| --- | --- |
| 阻塞I/O模型 | 同步阻塞 |
| 非阻塞I/O模型 | 同步非阻塞 |
| I/O多路復用模型 | 同步阻塞 |
| 信號驅動I/O模型 | 同步非阻塞 |
| 異步IO(AIO)模型 | 異步非阻塞 |
## 一個通俗例子讀懂BIO、NIO、AIO
* 同步阻塞(blocking-IO)簡稱BIO
* 同步非阻塞(non-blocking-IO)簡稱NIO
* 異步非阻塞(asynchronous-non-blocking-IO)簡稱AIO
**一個經典生活的例子:**
* 小明去吃同仁四季的椰子雞,就這樣在那里排隊,**等了一小時**,然后才開始吃火鍋。(**BIO**)
* 小紅也去同仁四季的椰子雞,她一看要等挺久的,于是去逛會商場,**每次逛一下,就跑回來看看,是不是輪到她了**。于是最后她既購了物,又吃上椰子雞了。(**NIO**)
* 小華一樣,去吃椰子雞,由于他是高級會員,所以店長說,**你去商場隨便逛會吧,等下有位置,我立馬打電話給你**。于是小華不用干巴巴坐著等,也不用每過一會兒就跑回來看有沒有等到,最后也吃上了美味的椰子雞(**AIO**)
- 消息隊列
- 為什么要用消息隊列
- 各種消息隊列產品的對比
- 消息隊列的優缺點
- 如何保證消息隊列的高可用
- 如何保證消息不丟失
- 如何保證消息不會重復消費?如何保證消息的冪等性?
- 如何保證消息消費的順序性?
- 基于MQ的分布式事務實現
- Beanstalk
- PHP
- 函數
- 基礎
- 基礎函數題
- OOP思想及原則
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收機制
- php-fpm相關
- 高級
- 設計模式
- 排序算法
- 正則
- OOP代碼基礎
- PHP運行原理
- zavl
- 網絡協議new
- 一面
- TCP和UDP
- 常見狀態碼和代表的意義以及解決方式
- 網絡分層和各層有啥協議
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 鎖
- 索引
- 事務
- 高可用?高并發?集群?
- 其他
- 主從復制
- 主從復制數據延遲
- SQL的語?分類
- mysqlQuestions
- Redis
- redis-question
- redis為什么那么快
- redis的優缺點
- redis的數據類型和使用場景
- redis的數據持久化
- 過期策略和淘汰機制
- 緩存穿透、緩存擊穿、緩存雪崩
- redis的事務
- redis的主從復制
- redis集群架構的理解
- redis的事件模型
- redis的數據類型、編碼、數據結構
- Redis連接時的connect與pconnect的區別是什么?
- redis的分布式鎖
- 緩存一致性問題
- redis變慢的原因
- 集群情況下,節點較少時數據分布不均勻怎么辦?
- redis 和 memcached 的區別?
- 基本算法
- MysqlNew
- 索引new
- 事務new
- 鎖new
- 日志new
- 主從復制new
- 樹結構
- mysql其他問題
- 刪除
- 主從配置
- 五種IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何實現手機掃碼登錄功能
- laravel框架的生命周期