
[TOC]
## InnoDB 引擎的 4 大特性,了解過嗎?
* 插入緩存:對于為非唯一索引,輔助索引的修改操作并非實時更新索引的葉子頁,而是把若干對同一頁面的更新緩存起來做合并為一次性更新操作,轉化隨機IO 為順序IO,這樣可以避免隨機IO帶來性能損耗,提高數據庫的寫性能。
* 二次寫:當頁需要寫回數據庫時,首先把頁備份到內存中的doublewrite buffer,然后每次1M,寫入到共享表空間中,共享表空間也是在磁盤上,因為是順序寫,所以很快,然后再將這些頁寫入到真的數據文件中,就算這個時候服務器出了問題,也是可以用共享表空間中的數據進行還原的
* 自適應hash:當某個非聚集索引被等值查詢的次數很多時,就會為這個非聚集索引再構造一個hash索引,hash索引對呀等值查詢是很快的,這個hash索引會放在緩存中
* 磁盤預讀:
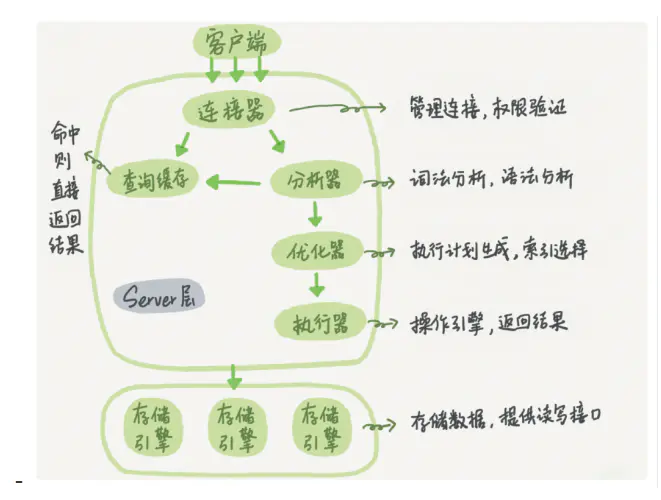
## 一條查詢語句發生了什么
## 三大范式是什么?
* 第一范式:數據表中的每一列(每個字段)必須是不可拆分的最小單元,也就是確保每一列的原子性;
* 第二范式(2NF):滿足1NF后,要求表中的所有列,都必須依賴于主鍵,而不能有任何一列與主鍵沒有關系,也就是說一個表只描述一件事情;
* 第三范式:必須先滿足第二范式(2NF),要求:表中的每一列只與主鍵直接相關而不是間接相關,(表中的每一列只能依賴于主鍵);
## 怎么區分三大范式?
第?一范式和第二范式在于有沒有分出兩張表,第二范式是說一張表中包含了所種不同的實體屬性,那么要必須分成多張表, 第三范式是要求已經分成了多張表,那么一張表中只能有另一張表中的id(主鍵),而不能有其他的任何信息(其他的信息一律用主鍵在另一表查詢)。
## 數據庫五大約束是什么?
1.primary KEY:設置主鍵約束;
2.UNIQUE:設置唯一性約束,不能有重復值;
3.DEFAULT 默認值約束,height DOUBLE(3,2)DEFAULT 1.2 height不輸入是默認為1,2
4.NOT NULL:設置非空約束,該字段不能為空;
5.FOREIGN key :設置外鍵約束。
## 主鍵是什么,怎么設置主鍵?
主鍵默認非空,默認唯一性約束,只有主鍵才能設置自動增長,自動增長一定是主鍵,主鍵不一定自動增長;
在定義列時設置:ID INT PRIMARY KEY
在列定義完之后設置:primary KEY(id)
## 數據庫的外鍵是什么?
只有INNODB的數據庫引擎支持外鍵。
不見已使用基于mysql的物理外鍵,這樣可能會有超出預期的后果。推薦使用邏輯外鍵,就是自己做表設計,根據代碼邏輯設定的外鍵,自行實現相關的數據操作。
## 主鍵索引和唯一索引的區別
1. 主鍵一定會創建一個唯一索引,但是有唯一索引的列不一定是主鍵;
2. 主鍵不允許為空值,唯一索引列允許空值;
3. 一個表只能有一個主鍵,但是可以有多個唯一索引;
4. 主鍵可以被其他表引用為外鍵,唯一索引列不可以;
5. 主鍵是一種約束,而唯一索引是一種索引,是表的冗余數據結構,兩者有本質的差別
## innodb和myisam有什么區別?
* InnoDB支持事務,而MyISAM不支持事物,崩潰后無法安全恢復,表鎖非常影響性能
* InnoDB支持行級鎖,而MyISAM支持表級鎖
* InnoDB支持MVCC,實現了四個標準的隔離級別 而MyISAM不支持
* InnoDB 表是基于聚族索引建立的,聚族索引對主鍵查詢有很高的性能
* InnoDB支持外鍵,而MyISAM不支持
* MyISAM 存儲引擎已經有了20年的歷史,在1995年時,MyISAM 是 MySQL 唯一的存儲引擎,服務了20多年,即將退居二線。隨著mysql5.7,8版本的提升,myisam優點已經逐漸被 InnoDB 實現了。比如全文索引,表空間優化,臨時表優化,高效的count(\*)
## btree和hash類型的索引有什么不同?
首先要知道Hash索引和B+樹索引的底層實現原理:
hash索引底層就是hash表,進行查找時,調用一次hash函數就可以獲取到相應的鍵值,之后進行回表查詢獲得實際數據.B+樹底層實現是多路平衡查找樹.對于每一次的查詢都是從根節點出發,查找到葉子節點方可以獲得所查鍵值,然后根據查詢判斷是否需要回表查詢數據.
那么可以看出他們有以下的不同:
* hash索引進行等值查詢更快(一般情況下),但是卻無法進行范圍查詢.
因為在hash索引中經過hash函數建立索引之后,索引的順序與原順序無法保持一致,不能支持范圍查詢.而B+樹的的所有節點皆遵循(左節點小于父節點,右節點大于父節點,多叉樹也類似),天然支持范圍.
* hash索引不支持使用索引進行排序,原理同上.
* hash索引不支持模糊查詢以及多列索引的最左前綴匹配.原理也是因為hash函數的不可預測.**AAAA**和**AAAAB**的索引沒有相關性.
* hash索引任何時候都避免不了回表查詢數據,而B+樹在符合某些條件(聚簇索引,覆蓋索引等)的時候可以只通過索引完成查詢.
* hash索引雖然在等值查詢上較快,但是不穩定.性能不可預測,當某個鍵值存在大量重復的時候,發生hash碰撞,此時效率可能極差.而B+樹的查詢效率比較穩定,對于所有的查詢都是從根節點到葉子節點,且樹的高度較低.
因此,在大多數情況下,直接選擇B+樹索引可以獲得穩定且較好的查詢速度.而不需要使用hash索引.
## drop、delete與truncate分別在什么場景之下使用?
我們來對比一下他們的區別:
drop table
* 1)屬于DDL
* 2)不可回滾
* 3)不可帶where
* 4)表內容和結構刪除
* 5)刪除速度快
truncate table
* 1)屬于DDL
* 2)不可回滾
* 3)不可帶where
* 4)表內容刪除
* 5)刪除速度快
delete from
* 1)屬于DML
* 2)可回滾
* 3)可帶where
* 4)表結構在,表內容要看where執行的情況
* 5)刪除速度慢,需要逐行刪除
總結:
**不再需要一張表的時候,用drop**
**想刪除部分數據行時候,用delete,并且帶上where子句**
**保留表而刪除所有數據的時候用truncate**
## MySQL中的varchar和char有什么區別?
1. char的長度是不可變的,而varchar的長度是可變的?。
2. 定義一個char\[10\]和varchar\[10\],如果存進去的是‘abcd’,那么char所占的長度依然為10,除了字符‘abcd’外,后面跟六個空格,而varchar就立馬把長度變為4了,取數據的時候,char類型的要用trim()去掉多余的空格,而varchar是不需要的,
3. char的存取速度比varchar要快得多,因為其長度固定,方便程序的存儲與查找;但是char也為此付出的是空間的代價,因為其長度固定,所以難免會有多余的空格占位符占據空間,可謂是以空間換取時間效率,而varchar是以空間效率為首位的。
4. char的存儲方式是,對英文字符(ASCII)占用1個字節,對一個漢字占用兩個字節;而varchar的存儲方式是,對每個英文字符占用2個字節,漢字也占用2個字節,兩者的存儲數據都非unicode的字符數據。
5. char適合存儲長度固定的數據,varchar適合存儲長度不固定的。
## varchar(10)和int(10)代表什么含義?
varchar的10代表了申請的空間長度,也是可以存儲的數據的最大長度,而int的10只是代表了展示的長度,不足10位以0填充.也就是說,int(1)和int(10)所能存儲的數字大小以及占用的空間都是相同的,只是在展示時按照長度展示.
## 超大分頁怎么處理?
超大的分頁一般從兩個方向上來解決.
* 數據庫層面,這也是我們主要集中關注的(雖然收效沒那么大),類似于`select * from table where age > 20 limit 1000000,10`這種查詢其實也是有可以優化的余地的. 這條語句需要load1000000數據然后基本上全部丟棄,只取10條當然比較慢. 當時我們可以修改為`select * from table where id in (select id from table where age > 20 limit 1000000,10)`.這樣雖然也load了一百萬的數據,但是由于索引覆蓋,要查詢的所有字段都在索引中,所以速度會很快. 同時如果ID連續的好,我們還可以`select * from table where id > 1000000 limit 10`,效率也是不錯的,優化的可能性有許多種,但是核心思想都一樣,就是減少load的數據.
* 從需求的角度減少這種請求....主要是不做類似的需求(直接跳轉到幾百萬頁之后的具體某一頁.只允許逐頁查看或者按照給定的路線走,這樣可預測,可緩存)以及防止ID泄漏且連續被人惡意攻擊.
解決超大分頁,其實主要是靠緩存,可預測性的提前查到內容,緩存至redis等k-V數據庫中,直接返回即可.
- 消息隊列
- 為什么要用消息隊列
- 各種消息隊列產品的對比
- 消息隊列的優缺點
- 如何保證消息隊列的高可用
- 如何保證消息不丟失
- 如何保證消息不會重復消費?如何保證消息的冪等性?
- 如何保證消息消費的順序性?
- 基于MQ的分布式事務實現
- Beanstalk
- PHP
- 函數
- 基礎
- 基礎函數題
- OOP思想及原則
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收機制
- php-fpm相關
- 高級
- 設計模式
- 排序算法
- 正則
- OOP代碼基礎
- PHP運行原理
- zavl
- 網絡協議new
- 一面
- TCP和UDP
- 常見狀態碼和代表的意義以及解決方式
- 網絡分層和各層有啥協議
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 鎖
- 索引
- 事務
- 高可用?高并發?集群?
- 其他
- 主從復制
- 主從復制數據延遲
- SQL的語?分類
- mysqlQuestions
- Redis
- redis-question
- redis為什么那么快
- redis的優缺點
- redis的數據類型和使用場景
- redis的數據持久化
- 過期策略和淘汰機制
- 緩存穿透、緩存擊穿、緩存雪崩
- redis的事務
- redis的主從復制
- redis集群架構的理解
- redis的事件模型
- redis的數據類型、編碼、數據結構
- Redis連接時的connect與pconnect的區別是什么?
- redis的分布式鎖
- 緩存一致性問題
- redis變慢的原因
- 集群情況下,節點較少時數據分布不均勻怎么辦?
- redis 和 memcached 的區別?
- 基本算法
- MysqlNew
- 索引new
- 事務new
- 鎖new
- 日志new
- 主從復制new
- 樹結構
- mysql其他問題
- 刪除
- 主從配置
- 五種IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何實現手機掃碼登錄功能
- laravel框架的生命周期