
[TOC]
## 什么是索引
>索引是存儲引擎用于快速找到記錄的一種數據結構
### 索引是個什么樣的數據結構呢?
索引的數據結構和具體存儲引擎的實現有關, 在MySQL中使用較多的索引有Hash索引,B+樹索引等,而我們經常使用的InnoDB存儲引擎的默認索引實現為:B+樹索引。
### 索引的好處
* 減少查詢需要掃描的數據量(加快了查詢速度)
* 減少服務器的排序操作和創建臨時表的操作(加快了groupby和orderby等操作)
* 將服務器的隨機IO變為順序IO(加快查詢速度).
### 索引的壞處
* 索引占用磁盤或者內存空間
* 減慢了插入更新操作的速度
### 索引種類
1. **「主鍵索引」**(`PRIMARY KEY`):主鍵索引一般都是在創建表的時候指定,**「一個表只有一個主鍵索引」**,特點是**「唯一、非空」**。
2. **「唯一索引」**(`UNIQUE`):唯一索引具有的特點就是唯一性,可以在創建表的時候指定,也可以在創建表后創建。
3. **「普通索引」**(`INDEX`):普通索引唯一的作用就是加快查詢。
4. **「組合索引」**(`INDEX`):組合索引是創建一個**「多個字段的索引」**,這個概念是相對于上上面的單列索引而言,組合索引查詢遵循**「最左前綴原則」**。
5. **「全文索引」**(`FULLTEXT`):全文索引是針對一些大的**「文本字段」**創建的索引,也稱為**「全文檢索」**。
### 索引的數據結構
1. B+樹
2. hash
3. fulltext
4. R-tree
#### Hash 索引和 B+ 樹索引區別是什么?你在設計索引是怎么抉擇的?
* B+ 樹可以進行范圍查詢,Hash 索引不能。
* B+ 樹支持聯合索引的最左前綴原則,Hash 索引不支持。
* B+ 樹支持 order by 排序,Hash 索引不支持。
* Hash 索引在等值查詢上比 B+ 樹效率更高。
* B+ 樹使用 like 進行模糊查詢的時候,like 后面(比如%開頭)的話可以起到優化的作用,Hash 索引根本無法進行模糊查詢。
* hash索引任何時候都避免不了回表查詢數據,而B+樹在符合某些條件(聚簇索引,覆蓋索引等)的時候可以只通過索引完成查詢。
* 數組的話適用于范圍查詢和等值查詢,但是當插入和刪除數據時,可能造成數據的移動,效率很低
### 索引算法有哪些?
索引算法有`BTree算法和Hash算法`。
* BTree算法
BTree是最常用的mysql數據庫索引算法,也是mysql默認的算法。因為它不僅可以被用在=,>,>=,<,<=和between這些比較操作符上,而且還可以用于like操作符,只要它的查詢條件是一個不以通配符開頭的常量, 例如:
~~~
--?只要它的查詢條件是一個不以通配符開頭的常量select?*?from?user?where?name?like?'jack%';?
--?如果一通配符開頭,或者沒有使用常量,則不會使用索引,例如:?select?*?from?user?where?name?like?'%jack';?
~~~
* Hash算法
Hash Hash索引只能用于對等比較,例如=,(相當于=)操作符。由于是一次定位數據,不像BTree索引需要從根節點到枝節點,最后才能訪問到頁節點這樣多次IO訪問,所以檢索效率遠高于BTree索引。
>物理存儲
1. 聚簇索引
關系表記錄的物理順序與索引的邏輯順序相同,一張表最多也只能存在一個聚簇索引,而且主鍵值和所有列數據放在一起
2. 非聚簇索引
索引文件和數據文件是分開的,索引文件只存儲了值的地址
>前綴索引
在對一個比較長的字符串進行索引時,可以僅索引開始的一部分字符,這樣可以大大的節約索引空間,從而提高索引效率.但是這樣也會降低索引的選擇性.
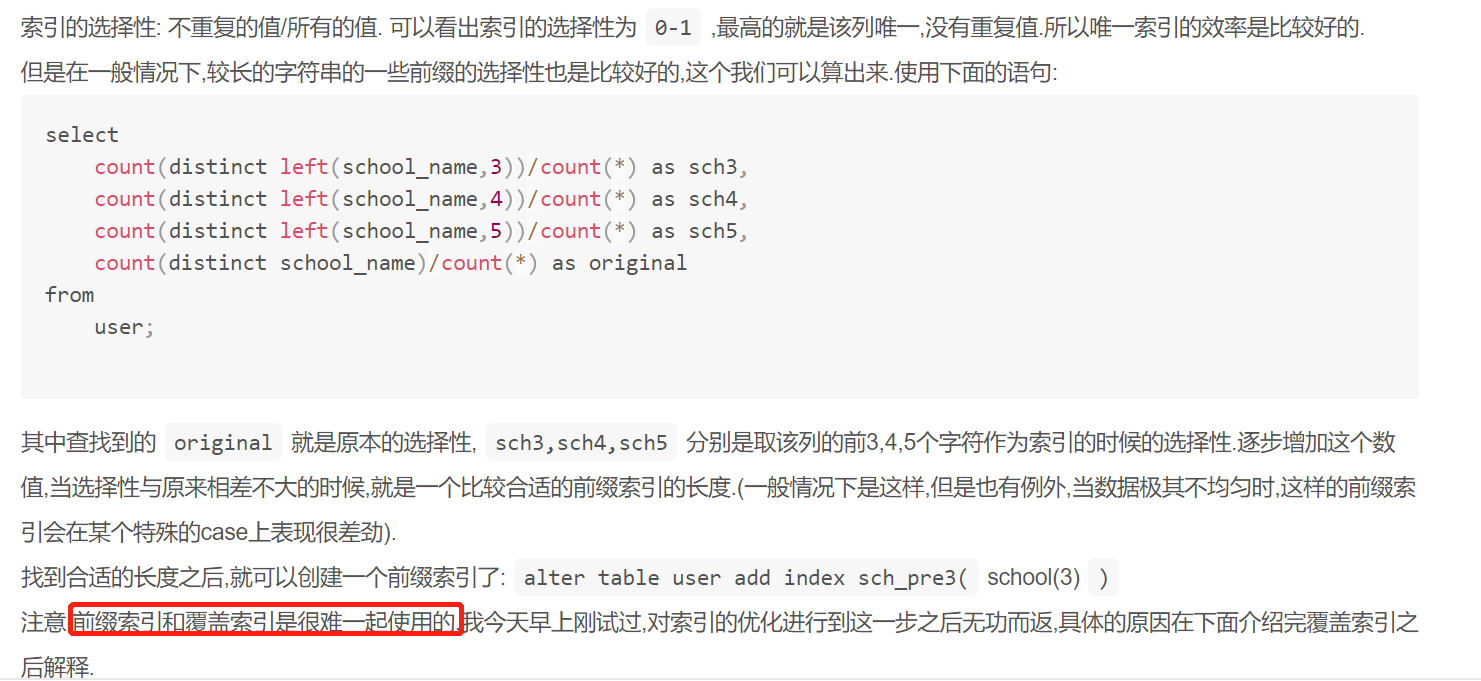
>聯合索引
組合索引即用多個字段創建一個索引,組合索引能夠避免**「回表查詢」**,相對于多字段的單列索引,組合索引的查詢效率更高。
## 什么是回表查詢?
**通過二級索引查詢數據,得不到完整的數據行,需要再次查詢主鍵索引來獲得數據行**
## 索引覆蓋
索引的葉子節點已經包含了查詢的數據,沒必要再回表進行查詢。
## 索引下推
就是在執行sql查詢的時候,會將一部分的索引列的判斷條件傳遞給存儲引擎,由存儲引擎通過判斷是否符合條件,只有符合條件的數據才會返回給Mysql服務器
## 索引碎片
在索引的創建刪除過程中,不可避免的會產品索引碎片,當然還有數據碎片,我們可以通過執行`optimize table xxx`來重新整理索引及數據,對于不支持此命令的存儲引擎來說,可以通過一條無意義的alter語句來觸發整理,比如:將表的存儲引擎更換為當前的引擎,
`alter table xxxx engine=innodb`
### 碎片的分類?
內部碎片:對于當前頁的數據來說,我們**更新**了某條數據的某個列,造成當前頁不能容納數據,造成了頁的分裂
外部碎片:對于當前頁的數據來說,**新增**一條數據,造成了頁的分裂
## 創建索引的原則
1、表的主鍵、外鍵必須有索引;
2、經常與其他表進行連接的表,在連接字段上應該建立索引;
3、經常出現在Where子句中的字段,特別是大表的字段,應該建立索引;
4、索引應該建在選擇性高的字段上;
5、索引應該建在小字段上,對于大的文本字段甚至超長字段,不要建索引;
6、頻繁進行數據更新的表,不要建立太多的索引,會早晨很多索引碎片;
7、刪除無用的索引,避免對執行計劃造成負面影響;
### 一般選擇在這樣的列上創建索引
1. 在經常需要搜索查詢的列上創建索引,可以加快搜索的速度;
2. 在作為主鍵的列上創建索引,強制該列的唯一性和組織表中數據的排列結構;
3. 在經常用在連接的列上創建索引,這些列主要是一些外鍵,可以加快連接的速度;
4. 在經常需要根據范圍進行搜索的列上創建索引,因為索引已經排序,其指定的范圍是連續的;
5. 在經常需要排序的列上創建索引,因為索引已經排序,這樣查詢可以利用索引的排序,加快排序查詢 時間;
6. 在經常使用在Where子句中的列上面創建索引,加快條件的判斷速度;
7. 為經常出現在關鍵字order by、group by、distinct后面的字段,建立索引。
### 創建索引需要注意的地方
1. 限制表上的索引數目。對一個存在大量更新操作的表,所建索引的數目一般不要超過3個,最多不要超過5個。索引雖說提高了訪問速度,但太多索引會影響數據的更新操作。
2. 對復合索引,按照字段在查詢條件中出現的頻度建立索引。在復合索引中,記錄首先按照第一個字段排序。對于在第一個字段上取值相同的記錄,系統再按照第二個字段的取值排序,以此類推。因此只有復合索引的第一個字段出現在查詢條件中,該索引才可能被使用。因此將應用頻度高的字段,放置在復合索引的前面,會使系統最大可能地使用此索引,發揮索引的作用。
3. 刪除不再使用,或者很少被使用的索引。表中的數據被大量更新,或者數據的使用方式被改變后,原有的一些索引可能不再被需要。數據庫管理員應當定期找出這些索引,將它們刪除,從而減少索引對更新操作的影響。
## explain 的各項解釋
各列的含義如下:
~~~
* id: SELECT 查詢的標識符. 每個 SELECT 都會自動分配一個唯一的標識符.
* select_type: SELECT 查詢的類型.
* table: 查詢的是哪個表
* partitions: 匹配的分區
* type: 判斷此次查詢是`全表掃描`還是`索引掃描`
* possible_keys: 此次查詢中【可能】選用的索引
* key: 此次查詢中【確切】使用到的索引.
* key_len: 使用了索引的字節數,這個字段可以評估組合索引是否完全被使用。
* ref: 哪個字段或常數與 key 一起被使用
* rows: 顯示此查詢一共掃描了多少行. 這個是一個估計值.越小性能越好。
* filtered: 表示此查詢條件所過濾的數據的百分比
* extra: 額外的信息,
~~~
需要重點關注的列:select_type,type,possible_keys,keys,key_len, rows,Extra。
(1)type 類型的性能比較:
`ALL < index < range ~ index_merge < ref < eq_ref < const < system`
`ALL`:Full Table Scan, MySQL將遍歷全表以找到匹配的行
`index`: Full Index Scan,index與ALL區別為index類型只遍歷索引樹
后面的幾種類型都是利用了索引來查詢數據, 因此可以過濾部分或大部分數據, 因此查詢效率就比較高了. 。
`range`: 表示使用索引范圍查詢。
`ref `:非唯一性索引掃描,范圍匹配某個單獨值得所有行。本質上也是一種索引訪問,他返回所有匹配某個單獨值的行,然而,它可能也會找到多個符合條件的行,多以他應該屬于查找和掃描的混合體
`eq_ref`:類似ref,區別就在使用的索引是唯一索引,對于每個索引鍵值,表中只有一條記錄匹配,簡單來說,就是多表連接中使用primary key或者 unique key作為關聯條件
`const`: 針對主鍵或唯一索引的等值查詢掃描, 最多只返回一行數據. const 查詢速度非常快, 因為它僅僅讀取一次即可.
`system`: 表中只有一條數據. 這個類型是特殊的`const`類型。
(2)rows基本是第一眼要看的指標。
(3)全表掃描時, possible_keys 和 key 字段都是 NULL。
(4)當 Extra 顯示:
* Using filesort
表示 MySQL 需額外的排序操作, 不能通過索引順序達到排序效果. 一般有`Using filesort`, 都建議優化去掉, 因為這樣的查詢 CPU 資源消耗大。
* Using index
"覆蓋索引掃描", 表示查詢在索引樹中就可查找所需數據, 不用掃描表數據文件, 往往說明性能不錯
* Using temporary
查詢有使用臨時表, 一般出現于排序, 分組和多表 join 的情況, 查詢效率不高, 建議優化.
## 導致索引失效的原因
* 列參與了數學運算或者函數;
* 如果條件中有or,即使其中有條件帶索引也不會使用(這也是為什么盡量少用or的原因);
* 對于多列索引,不符合最左匹配的命中規則;
* like查詢是以%開頭;
* 如果直接查比用索引快,那么數據庫會自動選擇最優方式,不用索引;
* in 和 not in 也要慎用,否則會導致全表掃描。
## innodb索引的實現原理是什么?
InnoDB使用的是聚簇索引,將主鍵組織到一棵B+樹中,而行數據就儲存在葉子節點上,若使用"where id = 14"這樣的條件查找主鍵,則按照B+樹的檢索算法即可查找到對應的葉節點,之后獲得行數據。若對Name列進行條件搜索,則需要兩個步驟:第一步在輔助索引B+樹中檢索Name,到達其葉子節點獲取對應的主鍵。第二步使用主鍵在主索引B+樹種再執行一次B+樹檢索操作,最終到達葉子節點即可獲取整行數據。
## 索引可以更快的查詢到數據,但數據結構有很多,我們到底該選擇哪一種數據結構才最適合數據庫操作呢?
(1)首先我們從數組來說,根據數組的數據結構來看,數組的查詢效率還是挺不錯的,如果是有序數組,那么我們采用二分查找效率則會更高;數組的弊端就是插入和刪除,數組為了保持內存的連續性,就會導致插入和刪除效率較低;
(2)其次是鏈表,從鏈表的數據結構來分析,鏈表的節點不僅存放了數據,也存放了儲存上一個節點或下一個節點地址的指針域,這就使鏈表在插入和刪除的時候只需要改變節點的指針域即可,效率很不錯;但是鏈表在存儲中是非連續、非順序的,這就導致了鏈表在進行查詢的時候需要從頭到尾,依次遍歷查找,效率不高;
(3)然后再談Hash表,哈希表又叫散列表,是根據關鍵碼值來進行訪問的數據結構,它通過散列函數(數據庫表字段與散列值的映射)來加快查找的效率,雖說它的單一查詢效率很高,但經不住范圍查詢,這就是我們選擇使用Hash或是B+tree的條件之一。
- 消息隊列
- 為什么要用消息隊列
- 各種消息隊列產品的對比
- 消息隊列的優缺點
- 如何保證消息隊列的高可用
- 如何保證消息不丟失
- 如何保證消息不會重復消費?如何保證消息的冪等性?
- 如何保證消息消費的順序性?
- 基于MQ的分布式事務實現
- Beanstalk
- PHP
- 函數
- 基礎
- 基礎函數題
- OOP思想及原則
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收機制
- php-fpm相關
- 高級
- 設計模式
- 排序算法
- 正則
- OOP代碼基礎
- PHP運行原理
- zavl
- 網絡協議new
- 一面
- TCP和UDP
- 常見狀態碼和代表的意義以及解決方式
- 網絡分層和各層有啥協議
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 鎖
- 索引
- 事務
- 高可用?高并發?集群?
- 其他
- 主從復制
- 主從復制數據延遲
- SQL的語?分類
- mysqlQuestions
- Redis
- redis-question
- redis為什么那么快
- redis的優缺點
- redis的數據類型和使用場景
- redis的數據持久化
- 過期策略和淘汰機制
- 緩存穿透、緩存擊穿、緩存雪崩
- redis的事務
- redis的主從復制
- redis集群架構的理解
- redis的事件模型
- redis的數據類型、編碼、數據結構
- Redis連接時的connect與pconnect的區別是什么?
- redis的分布式鎖
- 緩存一致性問題
- redis變慢的原因
- 集群情況下,節點較少時數據分布不均勻怎么辦?
- redis 和 memcached 的區別?
- 基本算法
- MysqlNew
- 索引new
- 事務new
- 鎖new
- 日志new
- 主從復制new
- 樹結構
- mysql其他問題
- 刪除
- 主從配置
- 五種IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何實現手機掃碼登錄功能
- laravel框架的生命周期