
豐富的過濾器插件是 logstash威力如此強大的重要因素,過濾器插件主要處理流經當前Logstash的事件信息,可以添加字段、移除字段、轉換字段類型,通過正則表達式切分數據等,也可以根據條件判斷來進行不同的數據處理方式。
[TOC]
## A grok正則捕獲插件
[Logstash簡單介紹](https://blog.csdn.net/chenleiking/article/details/73563930)
[grokdebug在線調試grok](http://grokdebug.herokuapp.com/)
[grok預裝正則表達式](https://www.cnblogs.com/stozen/p/5638369.html)
[github上的預裝正則表達式](https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns)
grok插件是一個十分耗費資源的插件,是Logstash中將非結構化數據解析成結構化數據以便于查詢的最好工具,非常適合解析syslog logs,apache log, mysql log,以及一些其他的web log
### **預定義表達式調用**
Logstash提供120個常用正則表達式可供安裝使用,安裝之后你可以通過名稱調用它們,語法如下:
```sh
%{SYNTAX:SEMANTIC}
SYNTAX:表示已經安裝的正則表達式的名稱
SEMANTIC:表示給Event中匹配到的內容指定什么名稱
```
>例如:Event的內容為`“[debug] 127.0.0.1 - test log content”`,匹配`%{IP:client}`將獲得`“client: 127.0.0.1”`的結果;
如果想對捕獲的數據進行數據類型轉換,可以使用`%{NUMBER:num:int}`這種語法
默認返回結果都是string類型,且當前Logstash所支持的轉換類型僅有“int”和“float”;
### **grok匹配事例:**
```sh
#日志內容:55.3.244.1 GET /index.html 15824 0.043
filter {
grok {
match => {"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"}
}
}
```
**?輸出結果:**
~~~sh
client: 55.3.244.1
method: GET
request: /index.html
bytes: 15824
duration: 0.043
~~~
### 自定義表達式
* 自定義表達式語法
語法:`(?<field_name>the_pattern)`
舉例:捕獲10或11和長度的十六進制`queue_id`
可以使用表達式`(?<queue_id>[0-9A-F]{10,11})`
* 安裝自定義表達式
可以將自定義的表達式配置到Logstash中,就可以像于定義的表達式一樣使用;
1. 在Logstash根目錄下創建文件夾`patterns`
2. 在`patterns`文件夾中創建文件`extra`(文件名自定義)
3. 在文件“extra”中添加表達式,格式:`patternName regexp`
4. 如:`POSTFIX_QUEUEID [0-9A-F]{10,11}`
5. 使用自定義的表達式時需要指定“patterns_dir”變量舉例如下:
```
filter {
grok {
patterns_dir => "/path/to/your/own/patterns"
match => { "message" => ........" }
}
}
```
## B date時間處理插件
這里需要合前面的grok插件剝離出來的值logdate配合使用。可以格式化為需要的樣子。
**為什什么要格式化?**
日志產生的時間肯定早于日志在logstash中處理的時間,如果不修改,保存進ES的時間(@timestamp)就是logstash當前處理數據的時間,時間就會不一致
格式化以后,可以通過target屬性來指定到@timestamp,這樣數據的時間就會是準確的,對以后圖表的建設來說萬分重要。
最后,順手刪除logdate這個字段已無用的字段。
~~~
filter{
date{
match=>["logdate","dd/MMM/yyyy:HH:mm:ss Z"]
target=>"@timestamp"
remove_field => 'logdate'
}
}
~~~
>需要強調的是,@timestamp字段的值,不可以隨便修改,最好就按照數據的某一個時間點來使用
如果是日志,就使用grok把時間摳出來,如果是數據庫,就指定一個字段的值來格式化
如果沒有這個字段的話,千萬不要試著去修改它。
## C mutate插件
mutate 插件是 Logstash另一個重要插件。提供了豐富的基礎類型數據處理能力。可以重命名,刪除,替換和修改事件中的字段。
~~~
filter {
mutate {
#接收一個數組,其形式為value,type
convert => [
#把request_time的值轉換為浮點型,把costTime的值轉換為整型
"request_time", "float",
"costTime", "integer"
]
}
}
~~~
* convert 字段轉換
將指定字段轉換為指定類型,字段內容是數組,則轉換所有數組元素,如果字段內容是hash,則不做任何處理
目前支持的轉換類型包括:integer,float, string, and boolean.
例如: convert=> { “fieldname” => “integer” }
* rename 字段重命名
修改一個或者多個字段的名稱。
例如: ` rename=> { “HOSTORIP” => “client_ip” }`
* replace 值替換
使用新值完整的替換掉指定字段的原內容,支持變量引用。
例如: 使用字段“source_host”的內容拼接上字符串“: My new message”之后的結果替換“message”的值:
`replace=> { “message” => “%{source_host}: My new message” }`
* gsub 字符串替換
類似replace方法,但是只針對字符串類型有效
例如:`[ “fieldname”, “/”, “:“, “fieldname2”, “[\\?#-]”, “.”]`,
解釋:使用`:`替換掉`fieldname`中的所有`/`,使用“.”替換掉“fieldname2”中的所有`\ ? # 和-`
* update 更新字段
更新現有字段的內容,
例如: 將“sample”字段的內容更新為“Mynew message”:
`update=> { “sample” => “My new message” }`
* join 連接數組字段
使用指定的符號將array字段的每個元素連接起來,對非array字段無效。
例如: 使用`,`將array字段`fieldname`的每一個元素連接成一個字符串:
`join=> { “fieldname” => “,” }
`
* merge 合并數組
合并兩個array或者hash,將一個array和一個hash合并。
例如: 將”added_field”合并到”dest_field”:
`merge=> { “dest_field” => “added_field” }`
* split 字段分割
按照自定的分隔符將字符串字段拆分成array字段,只能作用于string類型的字段。
例如: 將“fieldname”的內容按照`,`拆分成數組:
`split=> { “fieldname” => “,” }
`
* strip 去掉空格
去掉字段內容兩頭的空白字符。例如: `strip=> [“field1”, “field2”]`
* uppercase 大寫轉換
將指定的字段值轉換為大寫
* lowercase 小寫轉換
將指定的字段值轉換為小寫
## D ruby插件
ruby插件可以使用任何的ruby語法,無論是邏輯判斷,條件語句,循環語句,對字符串的操作,或是對EVENT對象的操作
**ruby插件有兩個屬性,一個init 還有一個code**
init屬性是用來初始化字段的,這個字段只是在ruby{}作用域里面生效。
code屬性使用兩個冒號進行標識,所有ruby語法都可以在里面進行。
~~~
filter {
ruby {
init => [field={}]
code => "
array=event.get('message').split('|')
array.each do |value|
if value.include? 'MD5_VALUE'
then
require 'digest/md5'
md5=Digest::MD5.hexdigest(value)
event.set('md5',md5)
end
if value.include? 'DEFAULT_VALUE'
then
event.set('value',value)
end
end
remove_field=>"message"
"
}
}
#首先,把message字段里面的值拿到,并按照“|”分割為數組
#第二步,循環數組判斷其值是否是我需要的數據(ruby條件語法、循環結構)
#第三步,把需要的字段添加進入EVEVT對象。
##event就是Logstash對象,可以在ruby插件的code屬性里面操作,可以添加屬性字段,刪除,修改,數值運算。
#第四步,選取一個值,進行MD5加密或其他操作,最后把冗余的message字段去除。
~~~
## E json插件
JSON插件用于解碼JSON格式的字符串,一般是一堆日志信息中,部分是JSON格式,部分不是的情況下,會將json格式部分的數據解析出來放到單獨的字段中
和input中的codec插件的json區別在于,input中的插件,解析json格式后,會替代message中的數據,而filter中的json插件,解析出的字段是單獨的,不會覆蓋message的數據
~~~
filter{
#source指定你的哪個值是json數據。
json {
source => "value"
}
}
~~~
>如果你的json數據是多層的,那么解析出來的數據在多層結里是一個數組,你可以使用ruby語法對他進行操作,最終把所有數據都轉換為平級的。
json插件還是需要注意一下使用的方法的,下圖就是多層結構的弊端:
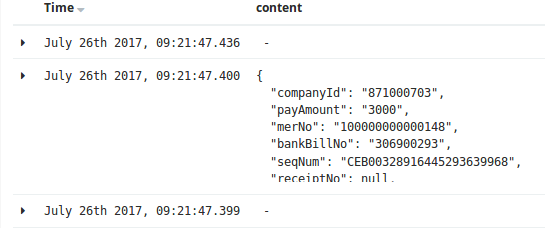
對應的解決方案為:
~~~ruby
ruby{
code=>"
kv=event.get('content')[0]
kv.each do |k,v|
event.set(k,v)
end"
remove_field => ['content','value','receiptNo','channelId','status']
}
~~~
- shell編程
- 變量1-規范-環境變量-普通變量
- 變量2-位置-狀態-特殊變量
- 變量3-變量子串
- 變量4-變量賦值三種方法
- 變量5-數組相關
- 計算1-數值計算命令和案例
- 計算2-expr命令舉例
- 計算3-條件表達式和各種操作符
- 計算4-條件表達式和操作符案例
- 循環1-函數的概念與作用
- 循環2-if與case語法
- 循環3-while語法
- 循環4-for循環
- 其他1-判斷傳入的參數為0或整數的多種思路
- 其他2-while+read按行讀取文件
- 其他3-給輸出內容加顏色
- 其他4-shell腳本后臺運行知識
- 其他5-6種產生隨機數的方法
- 其他6-break,continue,exit,return區別
- if語法案例
- case語法案例
- 函數語法案例
- WEB服務軟件
- nginx相關
- 01-簡介與對比
- 02-日志說明
- 03-配置文件和虛擬主機
- 04-location模塊和訪問控制
- 05-status狀態模塊
- 06-rewrite重寫模塊
- 07-負載均衡和反向代理
- 08-反向代理監控虛擬IP地址
- nginx與https自簽發證書
- php-nginx-mysql聯動
- Nginx編譯安裝[1.12.2]
- 案例
- 不同客戶端顯示不同信息
- 上傳和訪問資源池分離
- 配置文件
- nginx轉發解決跨域問題
- 反向代理典型配置
- php相關
- C6編譯安裝php.5.5.32
- C7編譯php5
- C6/7yum安裝PHP指定版本
- tomcxat相關
- 01-jkd與tomcat部署
- 02-目錄-日志-配置文件介紹
- 03-tomcat配置文件詳解
- 04-tomcat多實例和集群
- 05-tomcat監控和調優
- 06-Tomcat安全管理規范
- show-busy-java-threads腳本
- LVS與keepalived
- keepalived
- keepalived介紹和部署
- keepalived腦裂控制
- keepalived與nginx聯動-監控
- keepalived與nginx聯動-雙主
- LVS負載均衡
- 01-LVS相關概念
- 02-LVS部署實踐-ipvsadm
- 03-LVS+keepalived部署實踐
- 04-LVS的一些問題和思路
- mysql數據庫
- 配置和腳本
- 5.6基礎my.cnf
- 5.7基礎my.cnf
- 多種安裝方式
- 詳細用法和命令
- 高可用和讀寫分離
- 優化和壓測
- docker與k8s
- docker容器技術
- 1-容器和docker基礎知識
- 2-docker軟件部署
- 3-docker基礎操作命令
- 4-數據的持久化和共享互連
- 5-docker鏡像構建
- 6-docker鏡像倉庫和標簽tag
- 7-docker容器的網絡通信
- 9-企業級私有倉庫harbor
- docker單機編排技術
- 1-docker-compose快速入門
- 2-compose命令和yaml模板
- 3-docker-compose命令
- 4-compose/stack/swarm集群
- 5-命令補全和資源限制
- k8s容器編排工具
- mvn的dockerfile打包插件
- openstack與KVM
- kvm虛擬化
- 1-KVM基礎與快速部署
- 2-KVM日常管理命令
- 3-磁盤格式-快照和克隆
- 4-橋接網絡-熱添加與熱遷移
- openstack云平臺
- 1-openstack基礎知識
- 2-搭建環境準備
- 3-keystone認證服務部署
- 4-glance鏡像服務部署
- 5-nova計算服務部署
- 6-neutron網絡服務部署
- 7-horizon儀表盤服務部署
- 8-啟動openstack實例
- 9-添加計算節點流程
- 10-遷移glance鏡像服務
- 11-cinder塊存儲服務部署
- 12-cinder服務支持NFS存儲
- 13-新增一個網絡類型
- 14-云主機冷遷移前提設置
- 15-VXALN網絡類型配置
- 未分類雜項
- 部署環境準備
- 監控
- https證書
- python3.6編譯安裝
- 編譯安裝curl[7.59.0]
- 修改Redhat7默認yum源為阿里云
- 升級glibc至2.17
- rabbitmq安裝和啟動
- rabbitmq多實例部署[命令方式]
- mysql5.6基礎my.cnf
- centos6[upstart]/7[systemd]創建守護進程
- Java啟動參數詳解
- 權限控制方案
- app發包倉庫
- 版本發布流程
- elk日志系統
- rsyslog日志統一收集系統
- ELK系統介紹及YUM源
- 快速安裝部署ELK
- Filebeat模塊講解
- logstash的in/output模塊
- logstash的filter模塊
- Elasticsearch相關操作
- ES6.X集群及head插件
- elk收集nginx日志(json格式)
- kibana說明-漢化-安全
- ES安裝IK分詞器
- zabbix監控
- zabbix自動注冊模板實現監控項自動注冊
- hadoop大數據集群
- hadoop部署
- https證書
- certbot網站
- jenkins與CI/CD
- 01-Jenkins部署和初始化
- 02-Jenkins三種插件安裝方式
- 03-Jenkins目錄說明和備份
- 04-git與gitlab項目準備
- 05-構建自由風格項目和相關知識
- 06-構建html靜態網頁項目
- 07-gitlab自動觸發項目構建
- 08-pipelinel流水線構建項目
- 09-用maven構建java項目
- iptables
- 01-知識概念
- 02-常規命令實戰
- 03-企業應用模板
- 04-企業應用模板[1鍵腳本]
- 05-企業案例-共享上網和端口映射
- SSH與VPN
- 常用VPN
- VPN概念和常用軟件
- VPN之PPTP部署[6.x][7.x]
- 使用docker部署softether vpn
- softEther-vpn靜態路由表推送
- SSH服務
- SSH介紹和部署
- SSH批量分發腳本
- 開啟sftp日志并限制sftp訪問目錄
- sftp賬號權限分離-開發平臺
- ssh配置文件最佳實踐
- git-github-gitlab
- git安裝部署
- git詳細用法
- github使用說明
- gitlab部署和使用
- 緩存數據庫
- zookeeper草稿
- mongodb數據庫系列
- mongodb基本使用
- mongodb常用命令
- MongoDB配置文件詳解
- mongodb用戶認證管理
- mongodb備份與恢復
- mongodb復制集群
- mongodb分片集群
- docker部署mongodb
- memcached
- memcached基本概念
- memcached部署[6.x][7.x]
- memcached參數和命令
- memcached狀態和監控
- 會話共享和集群-優化-持久化
- memcached客戶端-web端
- PHP測試代碼
- redis
- 1安裝和使用
- 2持久化-事務-鎖
- 3數據類型和發布訂閱
- 4主從復制和高可用
- 5redis集群
- 6工具-安全-pythonl連接
- redis配置文件詳解
- 磁盤管理和存儲
- Glusterfs分布式存儲
- GlusterFS 4.1 版本選擇和部署
- Glusterfs常用命令整理
- GlusterFS 4.1 深入使用
- NFS文件存儲
- NFS操作和部署
- NFS文件系統-掛載和優化
- sersync與inotify
- rsync同步服務
- rsyncd.conf
- rsync操作和部署文檔
- rsync常見錯誤處理
- inotify+sersync同步服務
- inotify安裝部署
- inotify最佳腳本
- sersync安裝部署
- 時間服務ntp和chrony
- 時間服務器部署
- 修改utc時間為cst時間
- 批量操作與自動化
- cobbler與kickstart
- KS+COBBLER文件
- cobbler部署[7.x]
- kickstart部署[7.x]
- kickstar-KS文件和語法解析
- kickstart-PXE配置文件解析
- 自動化之ansible
- ansible部署和實踐
- ansible劇本編寫規范
- 配置文件示例
- 內網DNS服務
- 壓力測試
- 壓測工具-qpefr測試帶寬和延時