
在關系數據庫管理系統中,表建立時各數據之間的關系不必確定,常把一個實體的所有信息存放在一個表中。當檢索數據時,通過連接操作查詢出存放在多個表中的不同實體的信息。連接操作給用戶帶來很大的靈活性,它們可以在任何時候增加新的數據類型。為不同實體創建新的表,之后通過連接進行查詢。
連接可以在`SELECT`語句的`FROM`子句或`WHERE`子句中建立,似是而非在FROM子句中指出連接時有助于將連接操作與WHERE子句中的搜索條件區分開來。所以,在Transact-SQL中推薦使用這種方法。
SQL-92標準所定義的FROM子句的連接語法格式為:
~~~sql
FROM join_table join_type join_table
[ON (join_condition)]
~~~
其中`join_table`指出參與連接操作的表名,連接可以對同一個表操作,也可以對多表操作,對同一個表操作的連接又稱做自連接。
`join_type` 指出連接類型,可分為三種:內連接、外連接和交叉連接。
* 內連接(`INNER JOIN`)使用比較運算符進行表間某(些)列數據的比較操作,并列出這些表中與連接條件相匹配的數據行。根據所使用的比較方式不同,內連接又分為等值連 接、自然連接和不等連接三種。
* 外連接分為左外連接(`LEFT OUTER JOIN`或`LEFT JOIN`)、右外連接(`RIGHT OUTER JOIN`或`RIGHT JOIN`)和全外連接(`FULL OUTER JOIN`或`FULL JOIN`)三種。與內連接不同的是,外連接不只列出與連接條件相匹配的行,而是列出左表(左外連接時)、右表(右外連接時)或兩個表(全外連接時)中所有 符合搜索條件的數據行。
* 交叉連接(`CROSS JOIN`)沒有`WHERE`子句,它返回連接表中所有數據行的笛卡爾積,其結果集合中的數據行數等于第一個表中符合查詢條件的數據行數乘以第二個表中符合查詢條件的數據行數。
連接操作中的`ON (join_condition)`子句指出連接條件,它由被連接表中的列和比較運算符、邏輯運算符等構成。
>[danger] ## 連接表- 簡要概述SQL Server中的連接類型,包括內連接,左連接,右連接和完全外連接。
在關系數據庫中,數據分布在多個邏輯表中。 要獲得完整有意義的數據集,需要使用連接來查詢這些表中的數據。 SQL Server支持多種連接,包括內連接,[左連接],右連接,全外連接]和交叉連接。 每種連接類型指定SQL Server如何使用一個表中的數據來選擇另一個表中的行。
為了方便演示,下面將創建一些示例表。
#### A. 創建示例表
首先,創建一個名為`hr`的新模式:
~~~sql
CREATE SCHEMA hr;
GO
~~~
其次,在`hr`模式中創建兩個名為`candidate`和`employees`的新表:
~~~sql
CREATE TABLE hr.candidates(
id INT PRIMARY KEY IDENTITY,
fullname VARCHAR(100) NOT NULL
);
CREATE TABLE hr.employees(
id INT PRIMARY KEY IDENTITY,
fullname VARCHAR(100) NOT NULL
);
~~~
第三,在`candidate`和`employees`表中插入一些行:
~~~sql
INSERT INTO
hr.candidates(fullname)
VALUES
('John Doe'),
('Lily Bush'),
('Peter Drucker'),
('Jane Doe');
INSERT INTO
hr.employees(fullname)
VALUES
('John Doe'),
('Jane Doe'),
('Michael Scott'),
('Jack Sparrow');
~~~
下面將`candidate`表用作左表,將`employees`表用作右表。
#### B. SQL Server內聯接
內聯接生成一個數據集,其中包含左表中的行,這些行具有右表中的匹配行。
以下示例使用`inner join`子句從`employees`表中獲取在`candidates`表的`fullname`列中具有相同的值的行記錄:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
INNER JOIN hr.employees e
ON e.fullname = c.fullname;
~~~
執行上面查詢語句,得到以下結果:

下圖說明了兩個結果集的內聯接的結果:

#### C. SQL Server左連接
左連接選擇從左表開始的數據和右表中的匹配行。 左連接返回左表中的所有行和右表中的匹配行。 如果左表中的行在右表中沒有匹配的行,則右表的列將具有空值。
左連接也稱為左外連接。 `outer`關鍵字是可選的。
以下語句使用`left join`將`employees`表與`employees`表連接起來:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
LEFT JOIN hr.employees e
ON e.fullname = c.fullname;
~~~
執行上面查詢語句,得到以下結果:
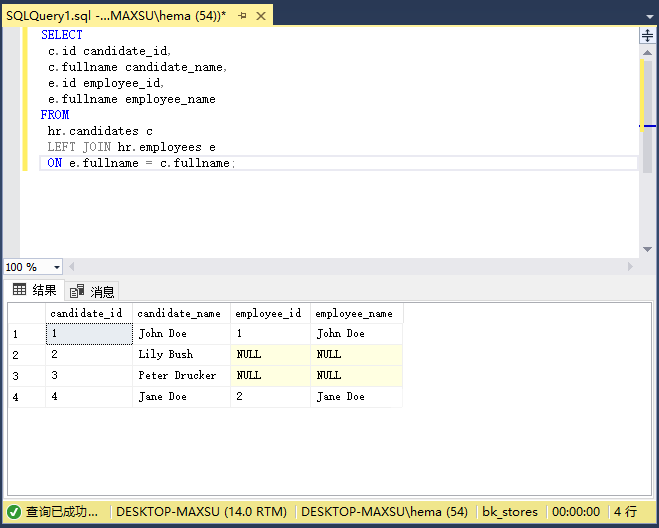
以下圖說明了兩個結果集的左連接結果:

要獲取僅在左表中可用但不在右表中可用的行,可以在上面的查詢中添加`WHERE`子句:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
LEFT JOIN hr.employees e
ON e.fullname = c.fullname
WHERE
e.id IS NULL;
~~~
執行上面查詢語句,得到以下結果:
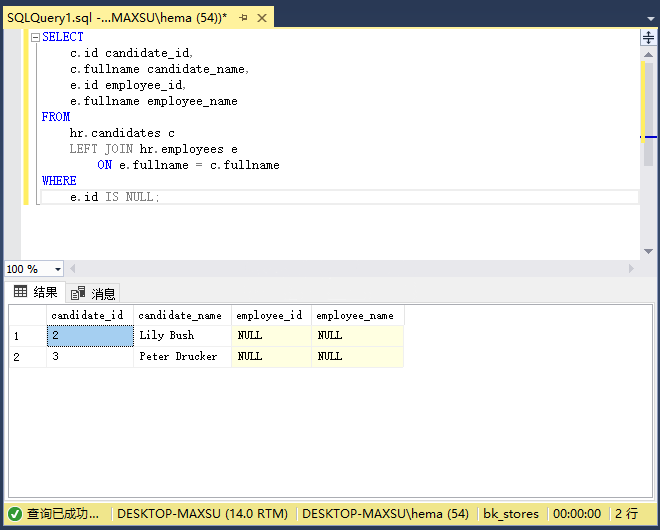
以下圖說明左連接的結果,它選擇僅在左表中可用的行:

#### D. SQL Server右連接
右連接或右外連接從右表開始選擇數據。 它是左連接的反轉版本。
右連接返回一個結果集,該結果集包含右表中的所有行和左表中的匹配行。 如果右表中的一行在左表中沒有匹配的行,則左表中的所有列都將包含`NULL`值。
以下示例使用右連接查詢`candidates` 和 `employees`表中的行:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
RIGHT JOIN hr.employees e
ON e.fullname = c.fullname;
~~~
執行上面查詢語句,得到以下結果:
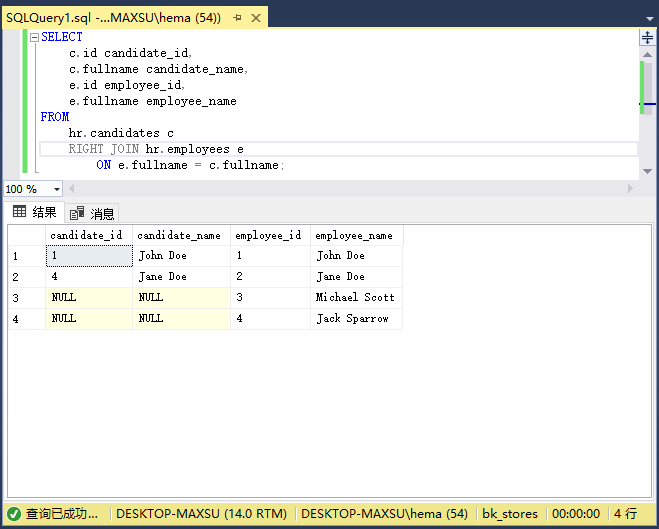
請注意,右表(`employees`)中的所有行都包含在結果集中。
下圖表說明了兩個結果集的右連接:

類似地,可以通過向上面的查詢添加`WHERE`子句來獲取僅在右表中可用的行,如下所示:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
RIGHT JOIN hr.employees e
ON e.fullname = c.fullname
WHERE
c.id IS NULL;
~~~
執行上面查詢語句,得到以下結果:
下圖說明了查詢操作的結果:

#### E. SQL Server全連接
完整外連接或完全連接返回一個結果集,該結果集包含左右表中的所有行,兩側的匹配行可用。 如果沒有匹配,則缺少的一方將具有`NULL`值。
以下示例顯示如何在`candidates` 和 `employees`表之間執行完全聯接:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
FULL JOIN hr.employees e
ON e.fullname = c.fullname;
~~~
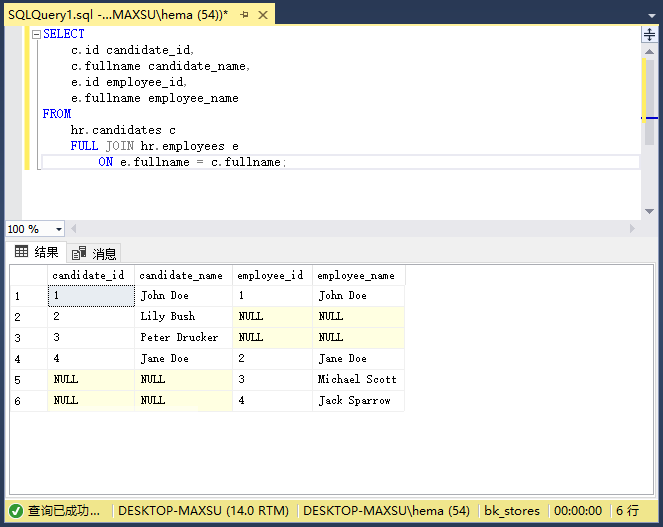
執行上面查詢語句,得到以下結果:
下圖說明了全連接:

要選擇存在左表或右表的行,可以通過添加`WHERE`子句來排除兩個表共有的行,如以下查詢中所示:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
FULL JOIN hr.employees e
ON e.fullname = c.fullname
WHERE
c.id IS NULL OR
e.id IS NULL;
~~~
執行上面查詢語句,得到以下結果:
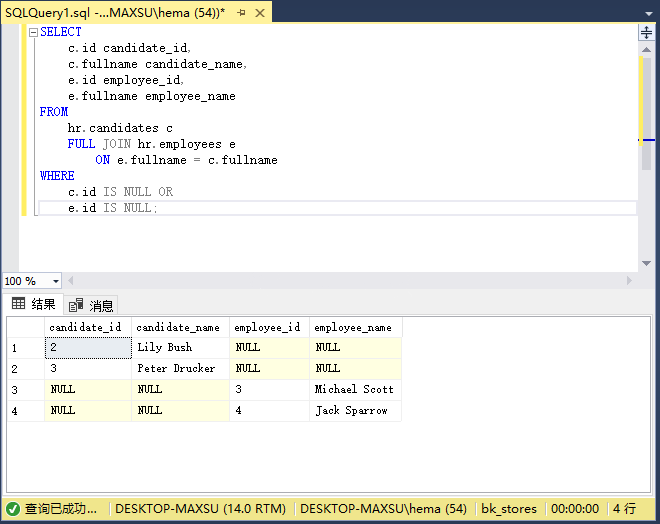
下圖說明了上述操作的結果:

>[danger] ## INNER JOIN- 從表中選擇在另一個表中具有匹配行的行。
## SQL Server INNER JOIN簡介
內連接是SQL Server中最常用的連接之一。 內部聯接子句用于查詢來自兩個或多個相關表的數據。
請參閱以下`products`和`categories`表:

以下語句從`products`表中檢索產品信息:
~~~sql
SELECT
product_name,
list_price,
category_id
FROM
production.products
ORDER BY
product_name DESC;
~~~
執行上面查詢語句,得到以下結果:
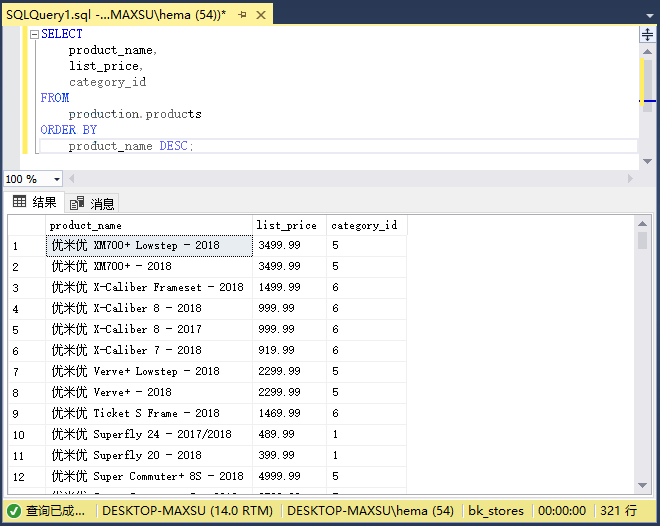
查詢僅返回類分類編號列表,不返回分類名稱。 要在結果集中包含分類名稱,請使用`INNER JOIN`子句,如下所示:
~~~sql
SELECT
product_name,
category_name,
list_price
FROM
production.products p
INNER JOIN production.categories c ON c.category_id = p.category_id
ORDER BY
product_name DESC;
~~~
執行上面查詢語句,得到以下結果:
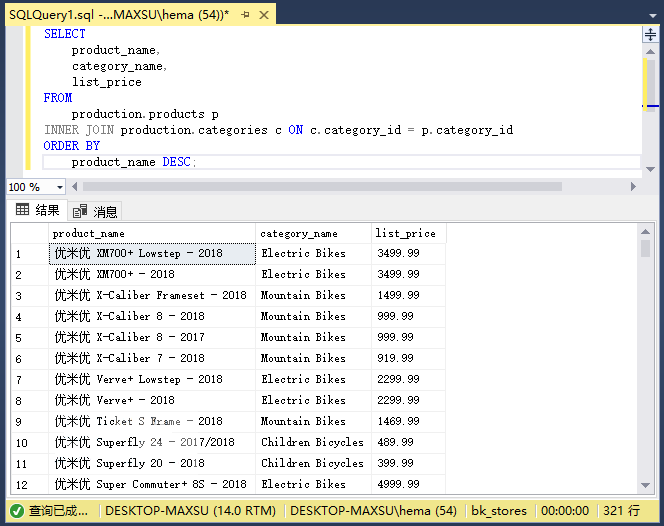
在此查詢中,內部連接子句匹配`products`和`categories`表中的行。 如果`products`表中的行在`category_id`列中具有與`categories`表中的行(`ID`列)相同的值,則查詢將選擇列表中指定的列的值組合為新行,并在結果集中包含該新行。
## SQL Server INNER JOIN語法
以下顯示了SQL Server `INNER JOIN`子句的語法:
~~~sql
SELECT
select_list
FROM
T1
INNER JOIN T2 ON join_predicate;
~~~
在此語法中,從`T1`和`T2`表中查詢檢索數據:
* 首先,在`FROM`子句中指定主表(`T1`)
* 其次,在`INNER JOIN`子句和連接謂詞中指定第二個表(`T2`)。 只有連接謂詞計算為`TRUE`的行才包含在結果集中。
`INNER JOIN`子句將表`T1`的每一行與表`T2`的行進行比較,以查找滿足連接謂詞的所有行對。 如果連接謂詞的計算結果為`TRUE`,則匹配的`T1`和`T2`行的列值將合并為一個新行并包含在結果集中。
下表說明了兩個表`T1(1,2,3)`和`T2(A,B,C)`的內部連接。 結果包括行:`(2,A)`和`(3,B)`,因為它們具有相同的模式。

## SQL Server內聯接示例
請參閱以下幾個表:`products`, `categories`和`brands`表:

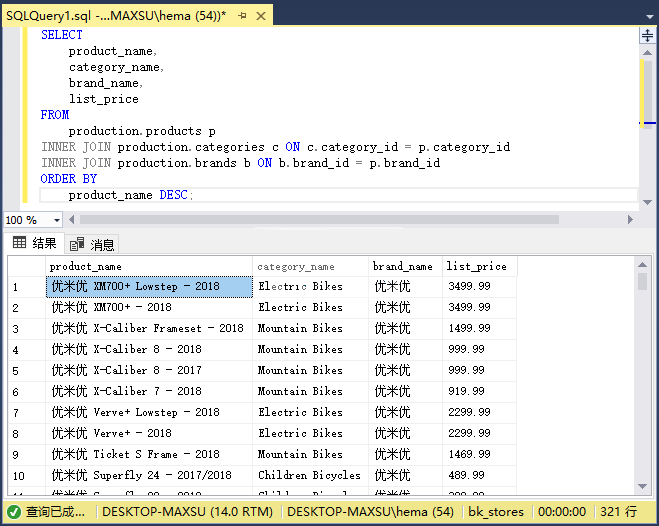
以下語句使用兩個`INNER JOIN`子句來查詢三個表中的數據:
~~~sql
SELECT
product_name,
category_name,
brand_name,
list_price
FROM
production.products p
INNER JOIN production.categories c ON c.category_id = p.category_id
INNER JOIN production.brands b ON b.brand_id = p.brand_id
ORDER BY
product_name DESC;
~~~
執行上面查詢語句,得到以下結果:
>[danger] ## LEFT JOIN- 返回左表中的所有行以及右表中的匹配行。 如果右表沒有匹配的行,請對右表中的列值使用`NULL`值。
## SQL Server LEFT JOIN子句簡介
`LEFT JOIN`子句用于查詢來自多個表的數據。它返回左表中的所有行和右表中的匹配行。 如果在右表中找不到匹配的行,則使用`NULL`代替顯示。
以下說明如何使用`LEFT JOIN`子句來連接兩個表`T1`和`T2`:
~~~sql
SELECT
select_list
FROM
T1
LEFT JOIN T2 ON
join_predicate;
~~~
在上面語法中,`T1`和`T2`分別是左表和右表。
對于`T1`表中的每一行,查詢將其與`T2`表中的所有行進行比較。 如果一對行導致連接謂詞計算為`TRUE`,則將組合這些行中的列值以形成新行,然后將其包含在結果集中。
如果左表(`T1`)中的行沒有與來自`T2`表的任何匹配行,則查詢將左表中的行的列值與來自右表的每個列值的`NULL`組合。
簡而言之,`LEFT JOIN`子句返回左表(`T1`)中的所有行以及右表(`T2`)中匹配的行或`NULL`值。
以下說明了兩個表`T1(1,2,3)`和`T2(A,B,C)`的`LEFT JOIN`過程:

在上面圖示中,`T2`表中的行不與`T1`表中的行`1`匹配,因此使用`NULL`。 `T1`表中的第`2`行和第`3`行分別與`T2`表中的行`A`和行`B`匹配。
## SQL Server LEFT JOIN示例
請參閱以下`products` 和 `order_items`表的結構:

每個銷售訂單項目包括一個產品。 `order_items`和`products`表之間的鏈接是通過`product_id`列中的值。
以下語句使用`LEFT JOIN`子句查詢`products`和`order_items`表中的數據:
~~~sql
SELECT
product_name,
order_id
FROM
production.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id
ORDER BY
order_id;
~~~
執行上面查詢語句,得到以下結果:
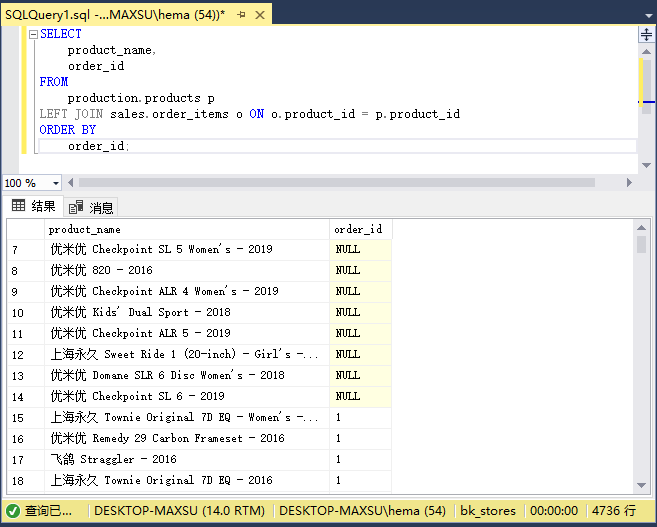
從結果集中可以清楚地看到,`order_id`列中的`NULL`列表表明相應的產品尚未銷售給任何客戶。
可以使用`WHERE`子句來過濾結果集。 以下查詢返回未出現在任何銷售訂單中的產品:
~~~sql
SELECT
product_name,
order_id
FROM
production.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id
WHERE order_id IS NULL
ORDER BY
order_id;
~~~
執行上面查詢語句,得到以下結果:
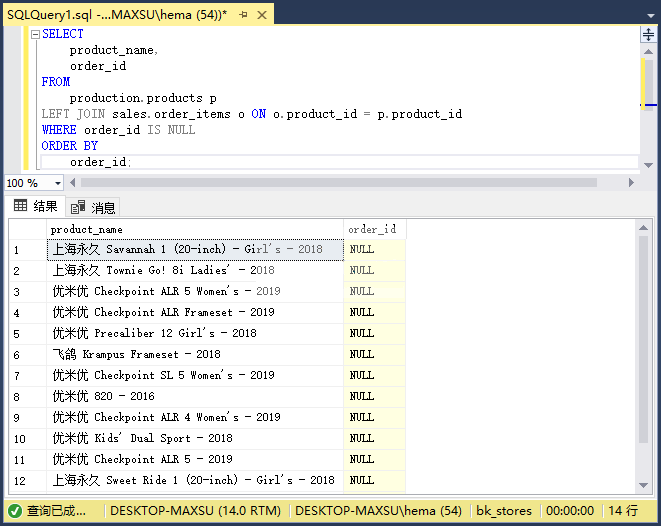
與往常一樣,SQL Server在`LEFT JOIN`子句之后處理`WHERE`子句。
#### SQL Server LEFT JOIN的條件:ON與WHERE子句
以下查詢查找屬于訂單ID為`100`的產品:
~~~sql
SELECT
product_name,
order_id
FROM
production.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id
WHERE order_id = 100
ORDER BY
order_id;
~~~
執行上面查詢語句,得到以下結果:

如果將條件`order_id = 100`移動到`ON`子句:
~~~sql
SELECT
p.product_id,
product_name,
order_id
FROM
production.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id AND p.product_id = 100
ORDER BY
order_id DESC;
~~~
執行上面查詢語句,得到以下結果:
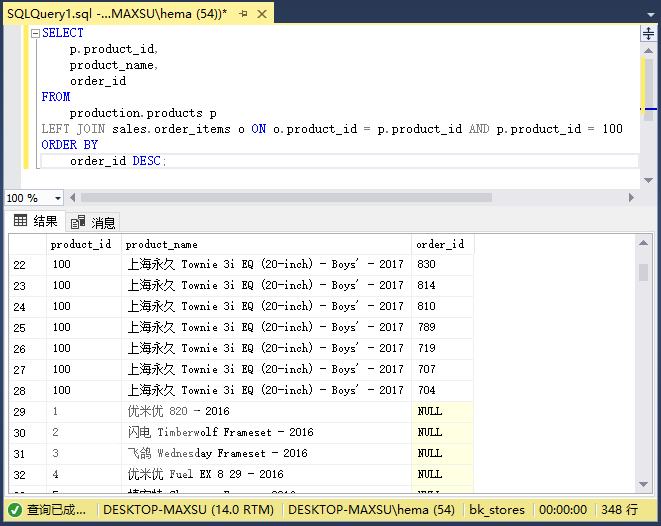
查詢返回了所有產品,但只有ID為`100`的產品具有關聯的訂單數據。
請注意,對于`INNER JOIN`子句,如果將`ON`子句中的條件放在`WHERE`子句中,則它在功能上是等效的。
>[danger] ## RIGHT JOIN- 學習左連接的反轉版本 - 右連接。
## SQL Server RIGHT JOIN子句簡介
`RIGHT JOIN`子句組合來自兩個或多個表的數據。 `RIGHT JOIN`開始從右表中選擇數據并與左表中的行匹配。 `RIGHT JOIN`返回一個結果集,該結果集包含右表中的所有行,無論是否具有左表中的匹配行。 如果右表中的行沒有來自右表的任何匹配行,則結果集中右表的列將使用`NULL`值。
以下是`RIGHT JOIN`的語法:
~~~sql
SELECT
select_list
FROM
T1
RIGHT JOIN T2 ON join_predicate;
~~~
在此語法中,`T1`是左表,`T2`是右表。
請注意,`RIGHT JOIN`和`RIGHT OUTER JOIN`是相同的。 `OUTER`關鍵字是可選的。
下圖說明了`RIGHT JOIN`操作:

橙色部分表示返回的結果集。
## SQL Server RIGHT JOIN示例
我們將使用[示例數據庫](https://www.yiibai.com/sqlserver/sql-server-sample-database.html "示例數據庫")中的`sales.order_items`和`production.products`表進行演示。

以下語句返回`production.products`表中的產品名稱和`sales.order_items`所有`order_id`:
~~~sql
SELECT
product_name,
order_id
FROM
sales.order_items o
RIGHT JOIN production.products p
ON o.product_id = p.product_id
ORDER BY
order_id;
~~~
執行上面查詢語句,得到以下結果:
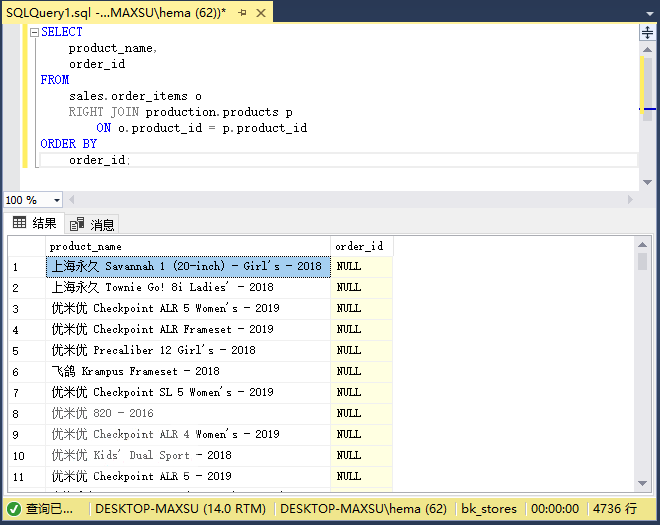
該查詢返回了`production.products`表(右表)中的所有行和`sales.order_items`表(左表)中的行。 如果產品沒有任何銷售,則order\_id列將為null。
要獲取沒有任何銷售記錄的產品,請在上述查詢中添加`WHERE`子句以過濾掉具有銷售額的產品:
~~~sql
SELECT
product_name,
order_id
FROM
sales.order_items o
RIGHT JOIN production.products p
ON o.product_id = p.product_id
WHERE
order_id IS NULL
ORDER BY
product_name;
~~~
執行上面查詢語句,得到以下結果:
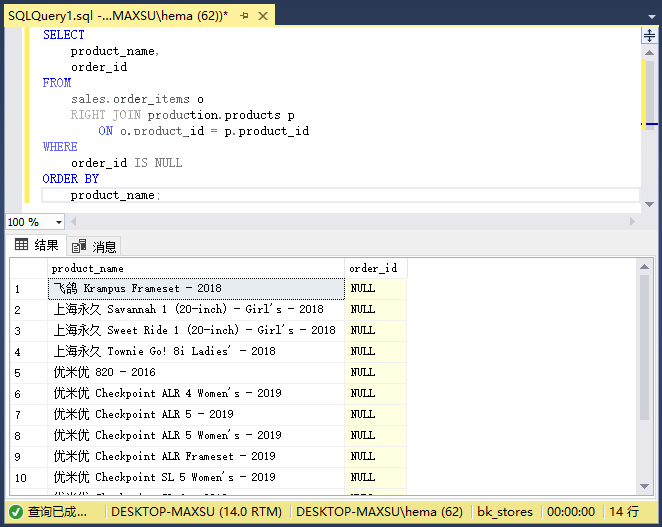
下面的圖說明了上面的`RIGHT JOIN`操作:

>[danger] ## FULL OUTER JOIN - 如果不存在匹配的行,則返回左右表中的匹配行以及每側的行。
## SQL Server全外連接簡介
`FULL OUTER JOIN`返回一個包括左右表中行記錄的結果集。 如果左表中的行不存在匹配的行,則右表的列將具有`NULL`值。 相反,如果右表中的行不存在匹配的行,則左表的列將具有`NULL`值。
下面顯示了連接兩個表時`FULL OUTER JOIN`的語法:
~~~sql
SELECT
select_list
FROM
T1
FULL OUTER JOIN T2 ON join_predicate;
~~~
`OUTER`關鍵字是可選的,因此可以不用寫上它,如以下查詢中所示:
~~~sql
SELECT
select_list
FROM
T1
FULL JOIN T2 ON join_predicate;
~~~
在這個語法中:
* 在`FROM`子句中指定左表`T1`。
* 指定右表`T2`和連接謂詞。
下圖說明了`FULL OUTER JOIN`的兩個結果集:

## SQL Server完全外連接示例
下面創建一些示例表來演示全外連接。
首先,創建一個名為`pm`的新模式,它代表項目管理。
~~~sql
CREATE SCHEMA pm;
GO
~~~
接下來,在`pm`模式中創建名為`projects`和`members`的新表:
~~~sql
CREATE TABLE pm.projects(
id INT PRIMARY KEY IDENTITY,
title VARCHAR(255) NOT NULL
);
CREATE TABLE pm.members(
id INT PRIMARY KEY IDENTITY,
name VARCHAR(120) NOT NULL,
project_id INT,
FOREIGN KEY (project_id)
REFERENCES pm.projects(id)
);
~~~
假設每個成員只能參與一個項目,每個項目都有零個或多個成員。 如果項目處于構思階段,則不會分配任何成員。
然后,向`projects`和`member`表中插入一些行記錄:
~~~sql
INSERT INTO
pm.projects(title)
VALUES
('New CRM for Project Sales'),
('ERP Implementation'),
('Develop Mobile Sales Platform');
INSERT INTO
pm.members(name, project_id)
VALUES
('John Doe', 1),
('Lily Bush', 1),
('Jane Doe', 2),
('Jack Daniel', null);
~~~
之后,查詢`projects`和`member`表中的數據:
~~~sql
SELECT * FROM pm.projects;
SELECT * FROM pm.members;
~~~
最后,使用`FULL OUTER JOIN`查詢`projects`和`member`表中的數據:
~~~sql
SELECT
m.name member,
p.title project
FROM
pm.members m
FULL OUTER JOIN pm.projects p
ON p.id = m.project_id;
~~~
執行上面查詢語句,得到以下結果:

在此示例中,查詢返回參與項目的成員,不參與任何項目的成員以及沒有任何成員的項目。
要查找不參與任何項目的成員和沒有任何成員的項目,請在上述查詢中添加`WHERE`子句:
~~~sql
SELECT
m.name member,
p.title project
FROM
pm.members m
FULL OUTER JOIN pm.projects p
ON p.id = m.project_id
WHERE
m.id IS NULL OR
P.id IS NULL;
~~~
執行上面查詢語句,得到以下結果:

如輸出中清楚顯示,`Jack Daniel`不參與任何項目,而`Develop Mobile Sales Platform`這個項目沒有任何成員。
>[danger] ## CROSS JOIN - 連接多個不相關的表,并在連接表中創建行的笛卡爾積。
以下是兩個表的SQL Server `CROSS JOIN`的語法:
~~~sql
SELECT
select_list
FROM
T1
CROSS JOIN T2;
~~~
`CROSS JOIN`將第一個表(T1)中的每一行與第二個表(T2)中的每一行連接起來。 換句話說,交叉連接返回兩個表中行的**笛卡爾積**。
與INNER JOIN或LEFT JOIN不同,交叉連接不會在連接的表之間建立關系。
假設`T1`表包含三行:`1`,`2`和`3`,`T2`表包含三行:`A`,`B`和`C`。
`CROSS JOIN`從第一個表(T1)獲取一行,然后為第二個表(T2)中的每一行創建一個新行。 然后它對第一個表(T1)中的下一行執行相同操作,依此類推。

在此圖中,`CROSS JOIN`總共創建了`9`行。 通常,如果第一個表有`n`行,第二個表有`m`行,則交叉連接將產生`n x m`行。
## SQL Server CROSS JOIN示例
以下語句返回所有產品和商店的組合。 結果集可用于月末和年終結算期間的盤點程序:
~~~sql
SELECT
product_id,
product_name,
store_id,
0 AS quantity
FROM
production.products
CROSS JOIN sales.stores
ORDER BY
product_name,
store_id;
~~~
執行上面查詢語句,得到以下結果:
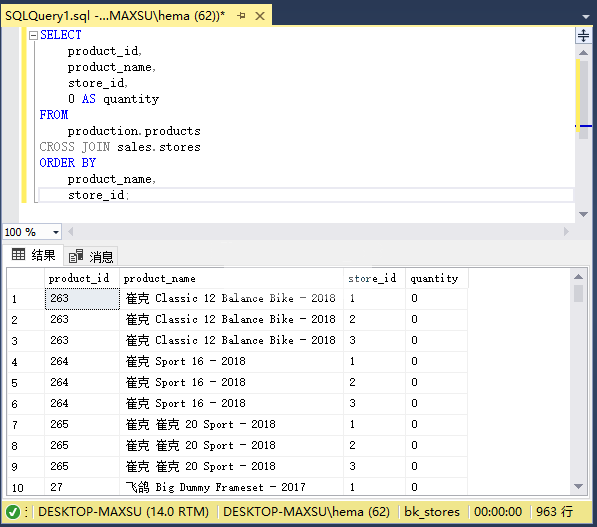
以下語句查找商店中沒有銷售的產品:
~~~sql
SELECT
s.store_id,
p.product_id,
ISNULL(sales, 0) sales
FROM
sales.stores s
CROSS JOIN production.products p
LEFT JOIN (
SELECT
s.store_id,
p.product_id,
SUM (quantity * i.list_price) sales
FROM
sales.orders o
INNER JOIN sales.order_items i ON i.order_id = o.order_id
INNER JOIN sales.stores s ON s.store_id = o.store_id
INNER JOIN production.products p ON p.product_id = i.product_id
GROUP BY
s.store_id,
p.product_id
) c ON c.store_id = s.store_id
AND c.product_id = p.product_id
WHERE
sales IS NULL
ORDER BY
product_id,
store_id;
~~~
執行上面查詢語句,得到以下結果:
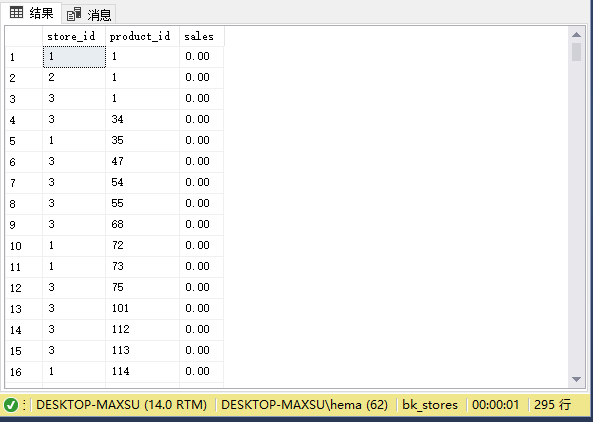
>[danger] ## 自聯接- 顯示如何使用自聯接查詢分層數據并比較同一表中的行。
## SQL Server自連接語法
自聯接用于將表連接到自身(同一個表)。 它對于查詢分層數據或比較同一個表中的行很有用。
自聯接使用內連接或左連接子句。 由于使用自聯接的查詢引用同一個表,因此表別名用于為查詢中的表分配不同的名稱。
> 請注意,如果在不使用表別名的情況下在查詢中多次引用同一個表,則會出現錯誤。
以下是將表`T`連接到自身的語法:
~~~sql
SELECT
select_list
FROM
T t1
[INNER | LEFT] JOIN T t2 ON
join_predicate;
~~~
上面查詢語句中兩次引用表`T`。表別名`t1`和`t2`用于為`T`表分配不同的名稱。
## SQL Server自連接示例
讓我們舉幾個例子來理解自連接的工作原理。
#### A. 使用自聯接查詢分層數據
請參考示例數據庫中的`staffs`表:

表中存儲的行記錄如下:

`staffs`表存儲員工信息,如身份證,名字,姓氏和電子郵件。 它還有一個名為`manager_id`的列,用于指定直接管理者。 例如,員工`Mireya`向管理員者`Fabiola`匯報工作,因為`Mireya`的`manager_id`列中的值是`Fabiola`。
`Fabiola`沒有經理,因為它的`manager_id`列是一個`NULL`值。
要獲取工作匯報關系,請使用自聯接,如以下查詢中所示:
~~~sql
SELECT
e.first_name + ' ' + e.last_name employee,
m.first_name + ' ' + m.last_name manager
FROM
sales.staffs e
INNER JOIN sales.staffs m ON m.staff_id = e.manager_id
ORDER BY
manager;
~~~
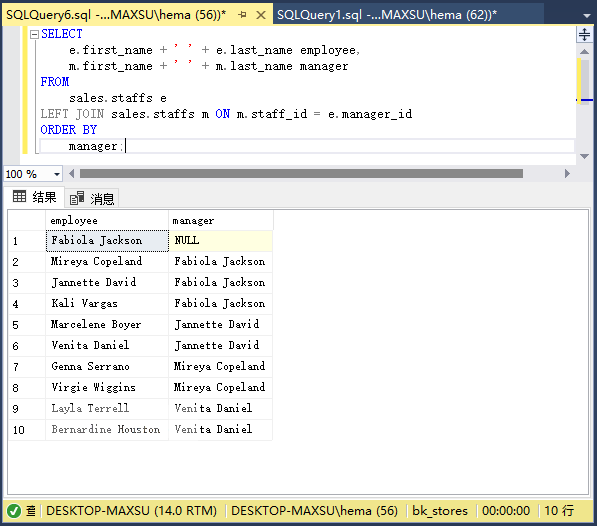
執行上面查詢語句,得到以下結果:
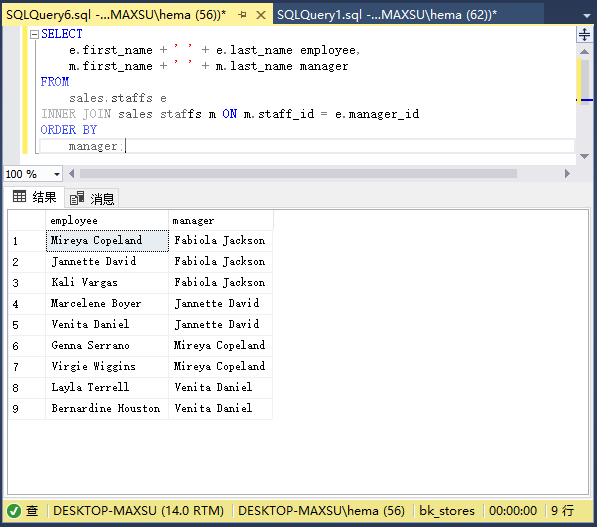
在這個例子中,兩次引用了`staffs`表:一個是員工的`e`,另一個是管理者的`m`。 連接謂詞使用`e.manager_id`和`m.staff_id`列中的值匹配`employee`和`manager`關系。
由于`INNER JOIN`效應,`employee`列沒有`Fabiola Jackson`。 如果用`LEFT JOIN`子句替換`INNER JOIN`子句,如以下查詢所示,將獲得在`employee`列中包含`Fabiola Jackson`的結果集:
~~~sql
SELECT
e.first_name + ' ' + e.last_name employee,
m.first_name + ' ' + m.last_name manager
FROM
sales.staffs e
LEFT JOIN sales.staffs m ON m.staff_id = e.manager_id
ORDER BY
manager;
~~~
執行上面查詢語句,得到以下結果:
#### B. 使用自聯接來比較表中的行
請參閱以下`customers`表:

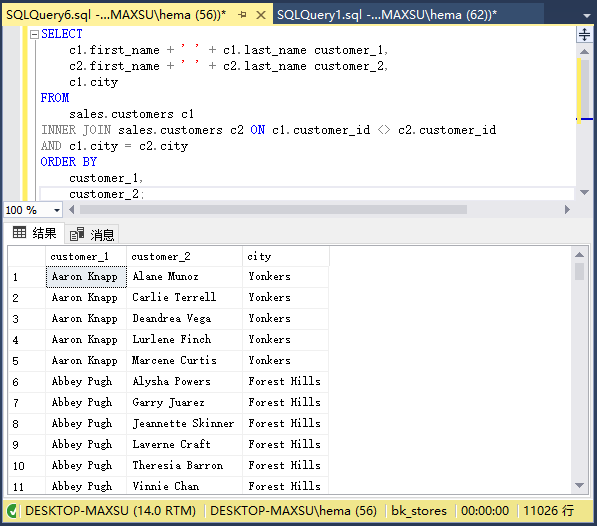
以下語句使用自聯接查找位于同一城市的客戶。
~~~sql
SELECT
c1.first_name + ' ' + c1.last_name customer_1,
c2.first_name + ' ' + c2.last_name customer_2,
c1.city
FROM
sales.customers c1
INNER JOIN sales.customers c2 ON c1.customer_id <> c2.customer_id
AND c1.city = c2.city
ORDER BY
customer_1,
customer_2;
~~~
執行上面查詢語句,得到以下結果:
- 第一章-測試理論
- 1.1軟件測試的概念
- 1.2測試的分類
- 1.3軟件測試的流程
- 1.4黑盒測試的方法
- 1.5AxureRP的使用
- 1.6xmind,截圖工具的使用
- 1.7測試計劃
- 1.8測試用例
- 1.9測試報告
- 2.0 正交表附錄
- 第二章-缺陷管理工具
- 2.1缺陷的內容
- 2.2書寫規范
- 2.3缺陷的優先級
- 2.4缺陷的生命周期
- 2.5缺陷管理工具簡介
- 2.6缺陷管理工具部署及使用
- 2.7軟件測試基礎面試
- 第三章-數據庫
- 3.1 SQL Server簡介及安裝
- 3.2 SQL Server示例數據庫
- 3.3 SQL Server 加載示例
- 3.3 SQL Server 中的數據類型
- 3.4 SQL Server 數據定義語言DDL
- 3.5 SQL Server 修改數據
- 3.6 SQL Server 查詢數據
- 3.7 SQL Server 連表
- 3.8 SQL Server 數據分組
- 3.9 SQL Server 子查詢
- 3.10.1 SQL Server 集合操作符
- 3.10.2 SQL Server聚合函數
- 3.10.3 SQL Server 日期函數
- 3.10.4 SQL Server 字符串函數
- 第四章-linux
- 第五章-接口測試
- 5.1 postman 接口測試簡介
- 5.2 postman 安裝
- 5.3 postman 創建請求及發送請求
- 5.4 postman 菜單及設置
- 5.5 postman New菜單功能介紹
- 5.6 postman 常用的斷言
- 5.7 請求前腳本
- 5.8 fiddler網絡基礎及fiddler簡介
- 5.9 fiddler原理及使用
- 5.10 fiddler 實例
- 5.11 Ant 介紹
- 5.12 Ant 環境搭建
- 5.13 Jmeter 簡介
- 5.14 Jmeter 環境搭建
- 5.15 jmeter 初識
- 5.16 jmeter SOAP/XML-RPC Request
- 5.17 jmeter HTTP請求
- 5.18 jmeter JDBC Request
- 5.19 jmeter元件的作用域與執行順序
- 5.20 jmeter 定時器
- 5.21 jmeter 斷言
- 5.22 jmeter 邏輯控制器
- 5.23 jmeter 常用函數
- 5.24 soapUI概述
- 5.25 SoapUI 斷言
- 5.26 soapUI數據源及參數化
- 5.27 SoapUI模擬REST MockService
- 5.28 Jenkins的部署與配置
- 5.29 Jmeter+Ant+Jenkins 搭建
- 5.30 jmeter腳本錄制
- 5.31 badboy常見的問題
- 第六章-性能測試
- 6.1 性能測試理論
- 6.2 性能測試及LoadRunner簡介
- 第七章-UI自動化
- 第八章-Maven
- 第九章-測試框架
- 第十章-移動測試
- 10.1 移動測試點及測試流程
- 10.2 移動測試分類及特點
- 10.3 ADB命令及Monkey使用
- 10.4 MonkeyRunner使用
- 10.5 appium工作原理及使用
- 10.6 Appium環境搭建(Java版)
- 10.7 Appium常用函數(Java版)
- 10.8 Appium常用函數(Python版)
- 10.9 兼容性測試