
**一、建立一個測試計劃(test plan)**
之前有說過,jmeter打開后會自動生成一個空的test plan,用戶可以基于該test plan建立自己的test plan
一個性能測試的負載必須有一個線程組完成,而一個測試計劃必須有至少一個線程組。添加線程組操作如下:
在測試計劃處右鍵單擊:添加→Threads(Users)→線程組

每個測試計劃都必須包含至少一個線程組,當然,也可以包含多個,多個線程組的運行在jmeter中采用的是并行的方式,即:同時被初始化且同時執行其下的sampler
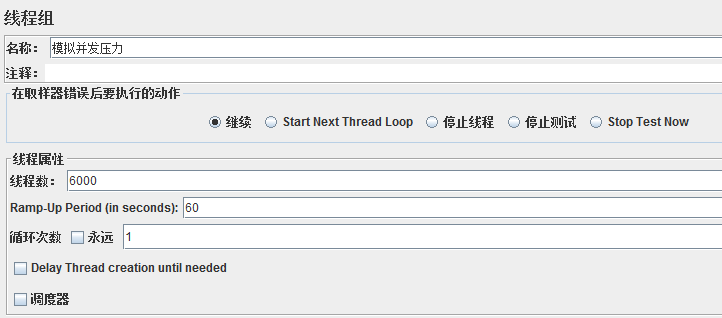
線程組主要包含三個參數:
**線程數:**虛擬用戶的數量,一個線程指一個線程或者進程
**Ramp—Up Period(in seconds):**準備時長。設置的線程數需要多久全部啟動,比如上圖,線程數為6000,啟動時間為60,那么需要60S內啟動6000個線程;
**循環次數:**每個線程發送請求的次數。如上圖,6000個線程,每個線程發送1次,如果勾選了永遠,那么它將永遠發送下去,直到停止腳本;
設置合理的線程數對能否達到測試目標有決定性影響。比如在本例中,如果線程數太少,則無法達到設定的要求;
另外,設置合理的循環次數也很重要,除了給定的設置循環次數和永遠,還可以通過勾選**調度器**,設置開始和結束時間來控制。
**二、添加sampler**
添加完線程組后,在線程組上右鍵單擊:添加→Sampler→SOAP/XML-RPC Request(SOAP/XML-RPC:都是報文中不同的數據格式)
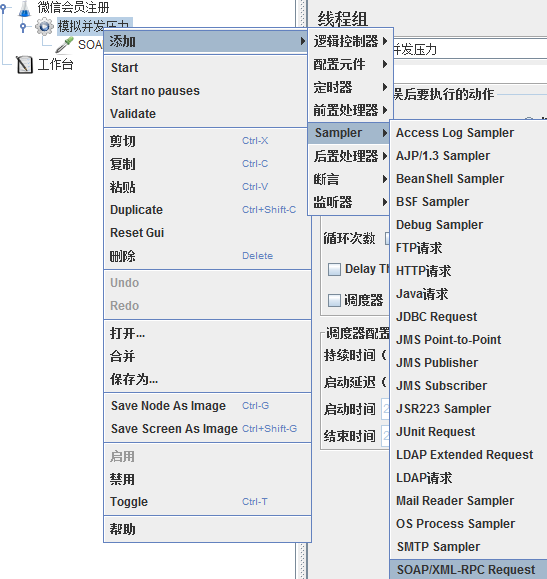
前面說過,取樣器(Sampler)是與服務器進行交互的單元。一個取樣器通常進行三部分的工作:向服務器發送請求,記錄服務器的響應數據和記錄相應時間信息
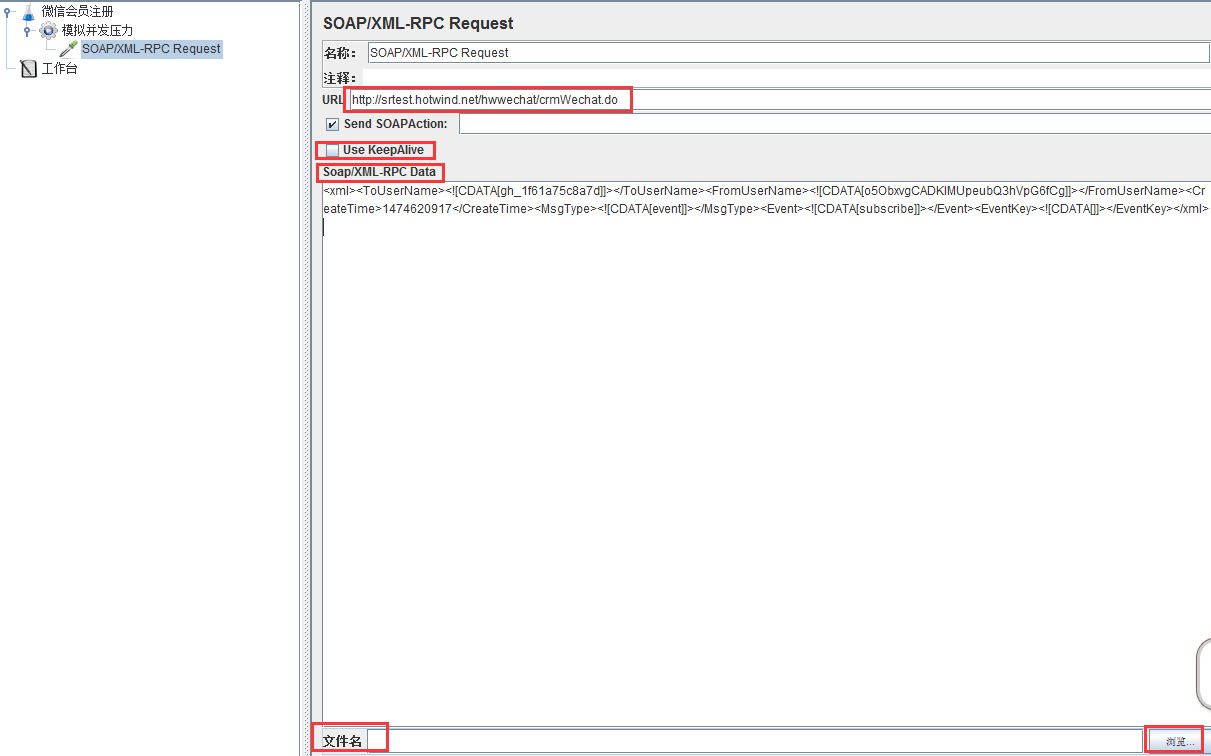
這里解釋一下,因為微信H5界面的會員注冊,向微信端發送的是xml文件,所以這里我選擇的取樣器是SOAP/XML-RPC Request
上面的圖中,選擇SOAP/XML-RPC Request取樣器,然后URL一欄輸入我們需要進行加壓的URL
然后默認選項,Use KeepAlive的意思是:保持連接,這個是http協議報文中的一個首部字段,之前的關于HTTP協議的隨筆寫過
下面的SOAP/XML-RPC Data輸入需要發送的xml格式的文件就行(也可以導入xml文件的文件夾進行讀取),下面是xml和json的區別:

添加完取樣器和具體的地址參數之后,接下來就是添加監聽器,對測試結果進行獲取
**三、添加監聽器**
在線程組上右鍵單擊,添加你需要的監聽器,一般常用的就是結果樹和聚合報告
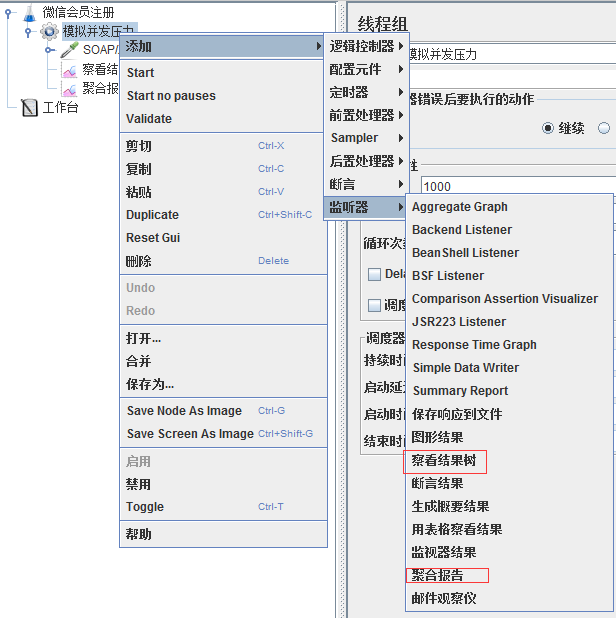
添加后啟動線程組進行測試,等線程執行完成后,根據結果樹中的請求和響應結果(成功或者失敗)就可以分析我們的測試是否成功,以及根據聚合報告結果來確認我們這次確認是否達成了預期結果。
**四、聚合報告簡析**
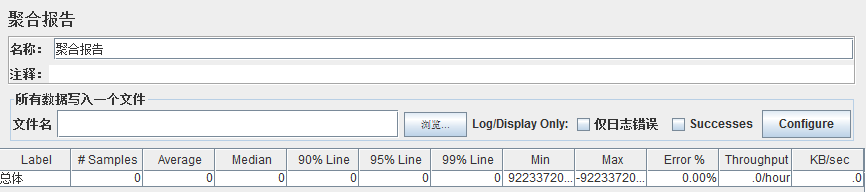
**ggregate Report:**?****JMeter****?常用的一個 Listener,中文被翻譯為“聚合報告”
**Label:**每個 JMeter 的 element(例如 HTTP Request)都有一個 Name 屬性,這里顯示的就是 Name 屬性的值
**#Samples:**表示你這次測試中一共發出了多少個請求,如果模擬10個用戶,每個用戶迭代10次,那么這里顯示100
**Average:**平均響應時間——默認情況下是單個 Request 的平均響應時間,當使用了 Transaction Controller 時,也可以以Transaction 為單位顯示平均響應時間
**Median:**中位數,也就是 50% 用戶的響應時間
**90% Line:**90% 用戶的響應時間
Note:關于 50% 和 90% 并發用戶數的含義
**Min:**最小響應時間
**Max:**最大響應時間
**Error%:**本次測試中出現錯誤的請求的數量/請求的總數
**Throughput:**吞吐量——默認情況下表示每秒完成的請求數(Request per Second),當使用了 Transaction Controller 時,也可以表示類似?****LoadRunner****?的 Transaction per Second 數
**KB/Sec:**每秒從服務器端接收到的數據量,相當于LoadRunner中的Throughput/Sec
- 第一章-測試理論
- 1.1軟件測試的概念
- 1.2測試的分類
- 1.3軟件測試的流程
- 1.4黑盒測試的方法
- 1.5AxureRP的使用
- 1.6xmind,截圖工具的使用
- 1.7測試計劃
- 1.8測試用例
- 1.9測試報告
- 2.0 正交表附錄
- 第二章-缺陷管理工具
- 2.1缺陷的內容
- 2.2書寫規范
- 2.3缺陷的優先級
- 2.4缺陷的生命周期
- 2.5缺陷管理工具簡介
- 2.6缺陷管理工具部署及使用
- 2.7軟件測試基礎面試
- 第三章-數據庫
- 3.1 SQL Server簡介及安裝
- 3.2 SQL Server示例數據庫
- 3.3 SQL Server 加載示例
- 3.3 SQL Server 中的數據類型
- 3.4 SQL Server 數據定義語言DDL
- 3.5 SQL Server 修改數據
- 3.6 SQL Server 查詢數據
- 3.7 SQL Server 連表
- 3.8 SQL Server 數據分組
- 3.9 SQL Server 子查詢
- 3.10.1 SQL Server 集合操作符
- 3.10.2 SQL Server聚合函數
- 3.10.3 SQL Server 日期函數
- 3.10.4 SQL Server 字符串函數
- 第四章-linux
- 第五章-接口測試
- 5.1 postman 接口測試簡介
- 5.2 postman 安裝
- 5.3 postman 創建請求及發送請求
- 5.4 postman 菜單及設置
- 5.5 postman New菜單功能介紹
- 5.6 postman 常用的斷言
- 5.7 請求前腳本
- 5.8 fiddler網絡基礎及fiddler簡介
- 5.9 fiddler原理及使用
- 5.10 fiddler 實例
- 5.11 Ant 介紹
- 5.12 Ant 環境搭建
- 5.13 Jmeter 簡介
- 5.14 Jmeter 環境搭建
- 5.15 jmeter 初識
- 5.16 jmeter SOAP/XML-RPC Request
- 5.17 jmeter HTTP請求
- 5.18 jmeter JDBC Request
- 5.19 jmeter元件的作用域與執行順序
- 5.20 jmeter 定時器
- 5.21 jmeter 斷言
- 5.22 jmeter 邏輯控制器
- 5.23 jmeter 常用函數
- 5.24 soapUI概述
- 5.25 SoapUI 斷言
- 5.26 soapUI數據源及參數化
- 5.27 SoapUI模擬REST MockService
- 5.28 Jenkins的部署與配置
- 5.29 Jmeter+Ant+Jenkins 搭建
- 5.30 jmeter腳本錄制
- 5.31 badboy常見的問題
- 第六章-性能測試
- 6.1 性能測試理論
- 6.2 性能測試及LoadRunner簡介
- 第七章-UI自動化
- 第八章-Maven
- 第九章-測試框架
- 第十章-移動測試
- 10.1 移動測試點及測試流程
- 10.2 移動測試分類及特點
- 10.3 ADB命令及Monkey使用
- 10.4 MonkeyRunner使用
- 10.5 appium工作原理及使用
- 10.6 Appium環境搭建(Java版)
- 10.7 Appium常用函數(Java版)
- 10.8 Appium常用函數(Python版)
- 10.9 兼容性測試