
[TOC]
*****
pandas對dataframe與series提供了豐富的操作方法
### 1.3.1. 查看屬性
1. columns
2. index
3. dtypes
4. shape
5. size
```
#查看數據框的列
df.columns
#查看數據框的索引
df.index
#數據框每一列的數據類型
df.dtypes
#數據框有多少行多少列
df.shape
#數據框有多少個數據,行*列
df.size
#數據框的長度,它有多少行
len(df)
```
### 1.3.2. 方法使用
1. head
2. tail
3. rename
4. replace
5. unique()
6. value_counts()
7. sort_values
8. describe
9. max/min/sum/mean
```
#重命名列名,"height"是原名字,"Height"是修改后的名字。inplace=True是對原數據集修改,inplace=false是根據原來生成一個新的數據集
df.rename(columns={"height":"Height","weight":"Weight"},inplace=True)
```
```
#顯示前兩行
df.head(2)
#顯示最后四行
df.tail(4)
```
```
#將player列中Curly Armstrong的數據換位xiao并放回一個新的數據集
df.replace({"Player":{"Curly Armstrong":"xiao"}})
```
```
#對值進行排序,默認是升序ascending=True,先按collage再按Height排
df.sort_values(by = ['collage','Height'],ascending=True).head()
```
```
#s1是數據框的birth_state列,是series
s1 = df['birth_state']
#該列中不重復的值的數量有多少個 s1.unique()看唯一值
len(s1.unique())
#結果129個
```
```
#該列中每個值的頻數計算
s1.value_counts()
```

```
#每一列的最小值
df.min()
```

每一列的最大值
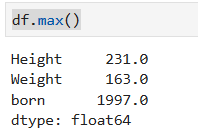
```
axis : {index (0), columns (1)}
Axis for the function to be applied on.
#axis=0 求每一列的數值和,axis =1 求每一行的數值和 max函數也有axis參數
# df.sum默認是 axis = 0
df.sum(axis=0)
```
**數據選取/添加/刪除**
```
#選擇Player列數據
df['Player']
#選擇兩列數據
df[['Player','Height']]
# 不推薦使用這種方式取Player列數據,分不清是自帶屬性還是數據框的一個列名
df.Player
```
```
# 給增加class列,該列的值都是1
df["class"] = 1
df['class']
df.class
```
```
#顯示數據框Height列中>=200或<=170的所有值
df[(df['Height'] >= 200) | (df['Height'] <=170)]
.head()默認顯示前五行
```
```
# 刪除df數據框中的class列
del df['class']
```
```
# somethong different
import numpy as np
a = np.array([[1,2,3,4,5,56],[3,4,5,1,7,3],[29,3,1,6,2,0]])
#np.sum(a,axis = 1) 求每一行數值和
#np.sum(a,axis = 0) 求每一列數值和
# 求所有數據的和,沒有axis=0的默認值 自己寫的時候要清楚是根據什么進行的求值
np.sum(a)
```

- 第五節 Pandas數據管理
- 1.1 文件讀取
- 1.2 DataFrame 與 Series
- 1.3 常用操作
- 1.4 Missing value
- 1.5 文本數據
- 1.6 分類數據
- 第六節 pandas數據分析
- 2.1 索引選取
- 2.2. 分組計算
- 2.3. 表聯結
- 2.4. 數據透視與重塑(pivot table and reshape)
- 2.5 官方小結圖片
- 第七節 NUMPY科學計算
- 第八節 python可視化
- 第九節 統計學
- 01 單變量
- 02 雙變量
- 03 數值方法
- 第十節 概率
- 01 概率
- 02 離散概率分布
- 03 連續概率分布
- 第一節 抽樣與抽樣分布
- 01抽樣
- 02 點估計
- 03 抽樣分布
- 04 抽樣分布的性質
- 第十三節 區間估計
- 01總體均值的區間估計:??已知
- 02總體均值的區間估計:??未知
- 03總體容量的確定
- 04 總體比率