
[TOC]
*****
dataframe與series中經常有文本格式的數據存在,pandas提供了良好的工具用來處理這些文本
```
#用列表創建Series
s = pd.Series(['A', 'B', 'C', 'Aaba ', ' Baca', 'CABA ', 'dog', 'cat'])
```

```
#調用s.str將series-S變為String 然后再去除兩端空格
s.str.strip() # 去除空格
```

```
# 將字符串轉換成大寫
s.str.upper()
```

```
#pandas中字符串函數可以連用,strip之后仍然是series需要再調用str變為字符串,并尋找結尾為a的字符串
s.str.strip().str.endswith("a")
```

```
#外面再套一個series,會返回結果為true的值
s[s.str.strip().str.endswith("a")]
```

*****
一個很常用的場景就是當你的index或者column名稱前后包含了空格的時候,你可以用str的方法剔除這些空格,從而避免不必要的麻煩
```
#注意age和name前后有空格
a = {"name ":["xiaoming","xiaohong","xiaogang"]," age":[12,13,14]}
test = pd.DataFrame(data = a)
```
#此時列名age和name有空格,但看不出來
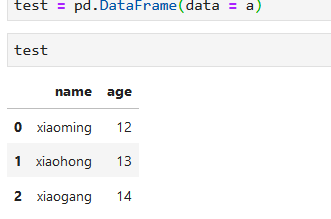
這時
```
#會報錯,是test[' age']
test['age']
```
去掉列名前后空格,這次打印正確
```
test.columns = test.columns.str.strip()
test['age']
```

### 1.5.1. Splitting and Replacing String
split方法用于根據某個分隔符對字符進行分割,返回一個列表
```
#取Player列所有數據
df['Player']
```
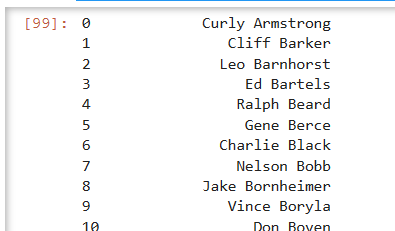
目標將姓和名進行分割
```
#.str將series變成字符串對象再用split 結果
df['Player'].str.split(" ")
```
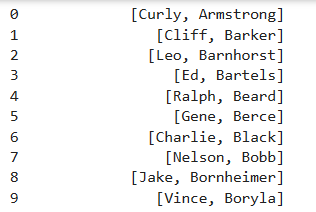
*****
取得Player列分割后所有列表的第一個元素(姓)
```
# 使用get方法獲取指定位置的元素
df['Player'].str.split(" ").str.get(1)
```
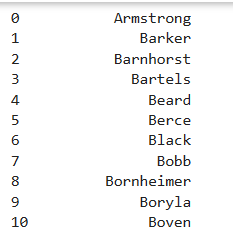
```
# 使用expand方法,將分割出的列表變為多個列,expand-擴展
df['Player'].str.split(" ",expand = True)
```
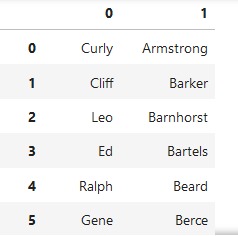
*****
使用\[\]對字符串的位置進行索引選取
```
#.str應用在Player列的每一個元素上,將series的元素變為字符串,對字符串使用切片索引選取
df['Player'].str[:3]
```
### 1.5.2. Extracting substring
通過正則表達式選取字符串中的子集
- 第五節 Pandas數據管理
- 1.1 文件讀取
- 1.2 DataFrame 與 Series
- 1.3 常用操作
- 1.4 Missing value
- 1.5 文本數據
- 1.6 分類數據
- 第六節 pandas數據分析
- 2.1 索引選取
- 2.2. 分組計算
- 2.3. 表聯結
- 2.4. 數據透視與重塑(pivot table and reshape)
- 2.5 官方小結圖片
- 第七節 NUMPY科學計算
- 第八節 python可視化
- 第九節 統計學
- 01 單變量
- 02 雙變量
- 03 數值方法
- 第十節 概率
- 01 概率
- 02 離散概率分布
- 03 連續概率分布
- 第一節 抽樣與抽樣分布
- 01抽樣
- 02 點估計
- 03 抽樣分布
- 04 抽樣分布的性質
- 第十三節 區間估計
- 01總體均值的區間估計:??已知
- 02總體均值的區間估計:??未知
- 03總體容量的確定
- 04 總體比率