
* 類似于SQL里面的group by 語句,不過pandas提供了更加復雜的函數方法
* 我們可以對index或者column進行分組,可以被一個元素,也可以是任意多個元素分組。分組后計算的方式是一樣的,無論是基于index還是column.
*****
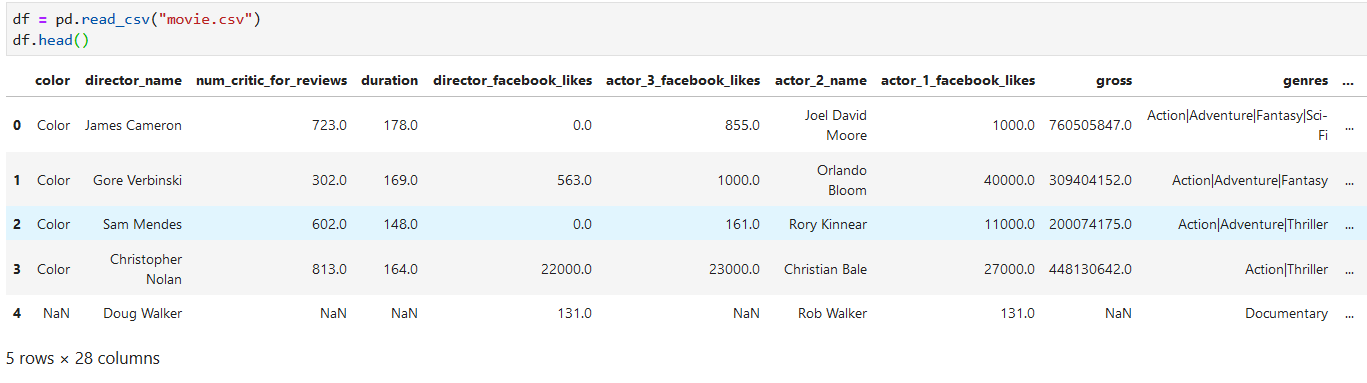
讀文件
*****
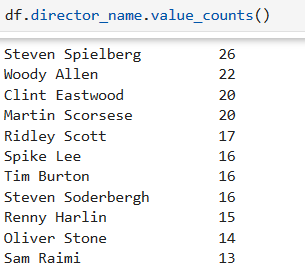
對director_name列的每個數據值進行頻數統計
*****
```
#將數據集按director_name分組
grouped = df.groupby("director_name")
```
*****
#分組后對各組進行頻數統計
```
grouped.size()
```

*****
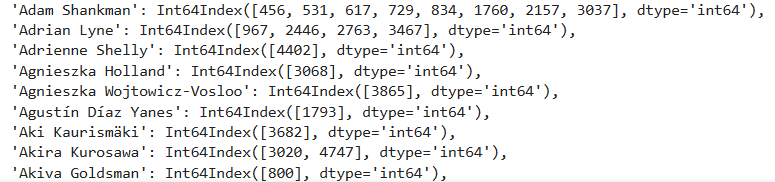
```
#可以看到每個分組的名字和在這個組下的各個索引
grouped.groups
```
*****
```
# 可以看到各個分組的名字,和每個分組下組內的各個數據
for name,group in grouped:
print(name)
print(group)
```
*****
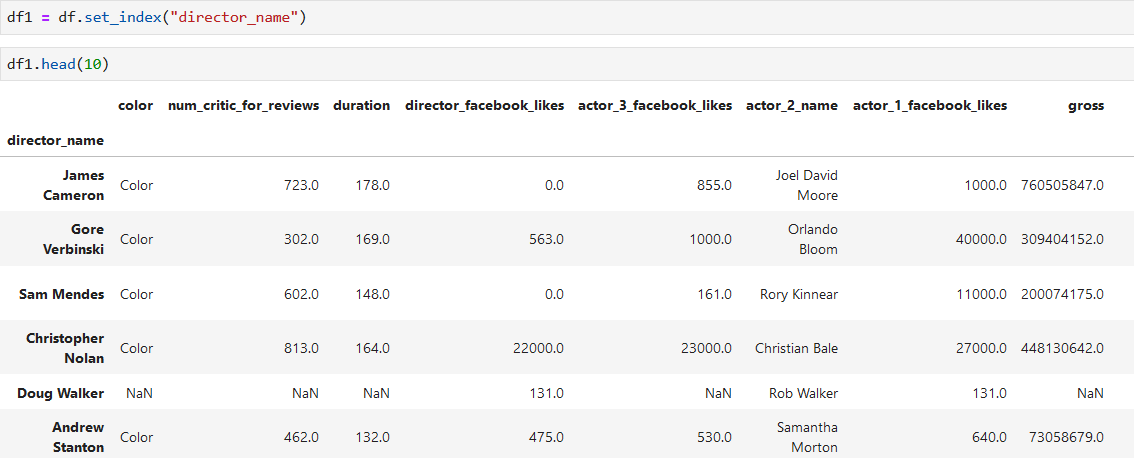
**把導演名字列作為索引,然后按照索引分組**
```
# 按照第一層索引分組
#g2 = df1.groupby(level=0)
g2 = df1.groupby(level=["director_name"])
```

### 2.2.1. 統計計算
1. 單個統計量計算 mean/sum/std
2. 多個統計量計算
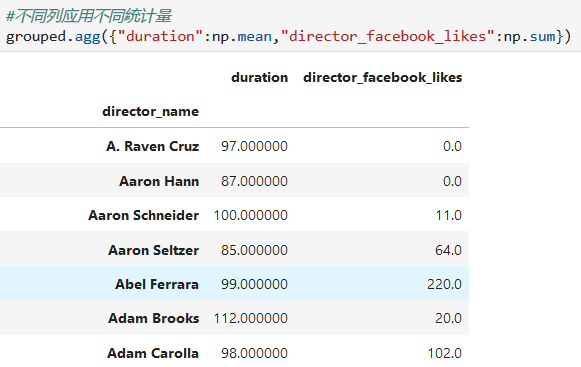
3. 不同列應用不同統計量
分組計算很重要的一點是:**我們的每一個統計函數都是作用在每一個group上,不是單個樣本,也不是全部數據**
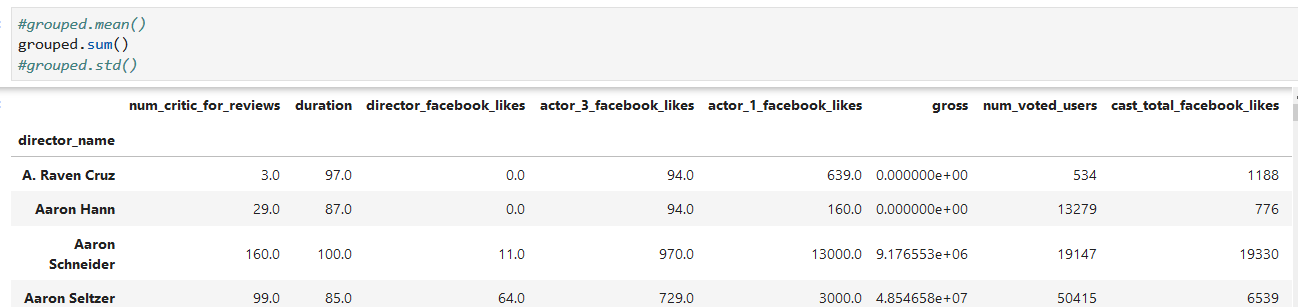
*****
對每個導演電影的時長進行求和統計
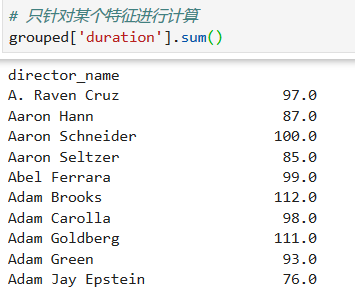
*****
對每組的兩列進行統計
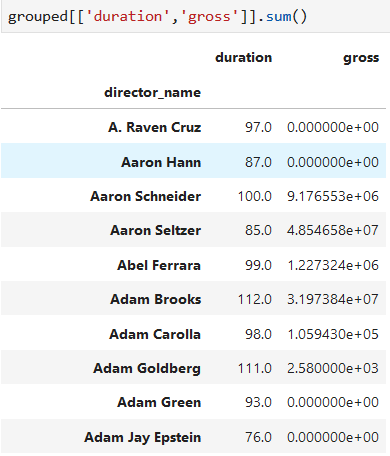
*****
對多個列進行多個統計量的統計
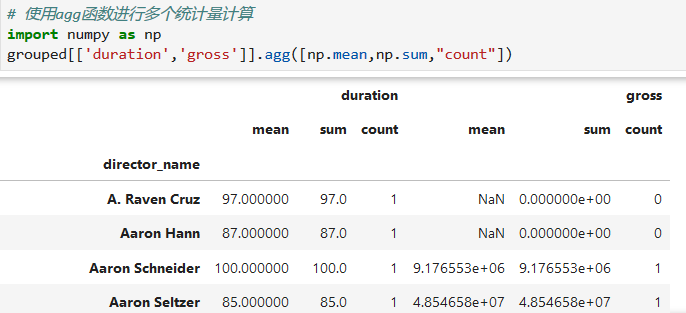
*****
*****
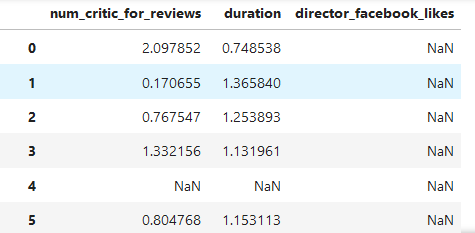
### 2.2.2. Transformation
基于每個分組操作,對組內元素進行轉換
```
#將缺失值都填充為0
df1 = df.fillna(0)
#將數據集按導演名字分組
grouped = df1.groupby("director_name")
#lambda表達式 z分數計算
z_score = lambda s : (s-s.mean())/ s.std()
#將每個列的每個組內元素根據z_score進行計算轉換,s.mean()是每個組的平均值
grouped[['num_critic_for_reviews','duration','director_facebook_likes']].transform(z_score)
```
*****
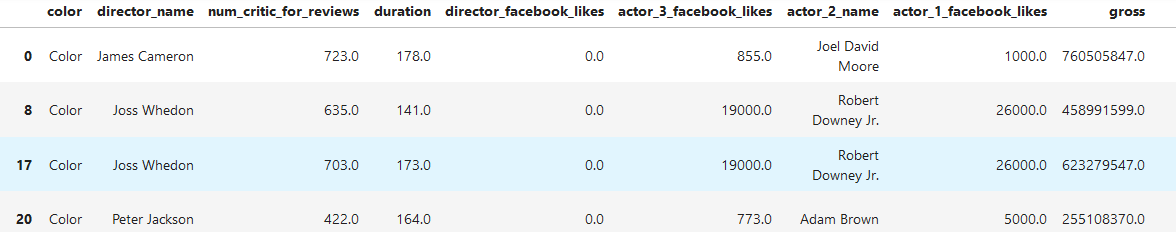
### 2.2.3. Filteration
分組過濾
```
#選出duration平均值大于等于150的分組
grouped.filter(lambda g : g['duration'].mean() >= 150)
```
*****
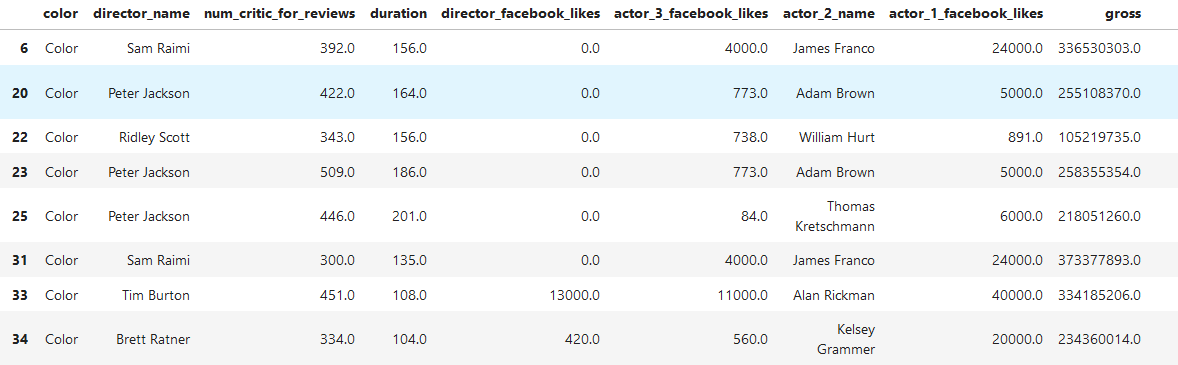
```
#選出組內數據數目大于等于10的分組
grouped.filter(lambda g : len(g) >=10)
```
- 第五節 Pandas數據管理
- 1.1 文件讀取
- 1.2 DataFrame 與 Series
- 1.3 常用操作
- 1.4 Missing value
- 1.5 文本數據
- 1.6 分類數據
- 第六節 pandas數據分析
- 2.1 索引選取
- 2.2. 分組計算
- 2.3. 表聯結
- 2.4. 數據透視與重塑(pivot table and reshape)
- 2.5 官方小結圖片
- 第七節 NUMPY科學計算
- 第八節 python可視化
- 第九節 統計學
- 01 單變量
- 02 雙變量
- 03 數值方法
- 第十節 概率
- 01 概率
- 02 離散概率分布
- 03 連續概率分布
- 第一節 抽樣與抽樣分布
- 01抽樣
- 02 點估計
- 03 抽樣分布
- 04 抽樣分布的性質
- 第十三節 區間估計
- 01總體均值的區間估計:??已知
- 02總體均值的區間估計:??未知
- 03總體容量的確定
- 04 總體比率