
[TOC]
*****
**索引選取:**
根據某種條件篩選出數據的子集,類似sql那樣
整數列表的切片時前閉后開
pandas中標簽名稱切片是前后都閉合的
超出索引值范圍和 標簽名不存在會報錯
*****
標簽指的是索引列中的值
索引選取兩種方式:
1.基于loc(根據索引的標簽名選取)
2.基于iloc(根據行和列的位置,用整數選取)
*****
loc

沒必要使用callable function來進行索引選取
*****
iloc

*****
### 2.1.1. 基于label.loc
**Series操作**
```
#隨機生成6個數字,并生成series和索引列
s1 = pd.Series(np.random.randn(6), index=list('abcdef'))
```

*****
根據單個標簽名選取數據
```
s1.loc['c']
# 結果
0.7140279186233623
```
*****
根據標簽列表選取數據
```
s1.loc[['a','e','f']]
```

*****
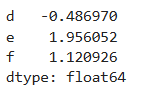
根據標簽切片選取數據,按照生成時的標簽順序進行切片
```
s1.loc['d':'f']
```
*****
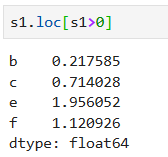
判斷s1中的每個元素是否大于0,返回一個布爾數組

根據布爾數組選取數據
**DataFrame操作**
DataFrame是二維數據,可以操控index與column。DataFrame的行索引是整數
*****
根據行和列選取數據

*****
根據列表

*****
根據切片

*****
根據布爾數組選取有關height行的數據
df.loc[df['height'] >= 200,['Player','height']]

下列代碼生成的是一個series

*****
### 2.1.2. 基于位置.iloc
用索引的位置下標選取數據

傳統切片 通過位置下標整數進行切片

*****
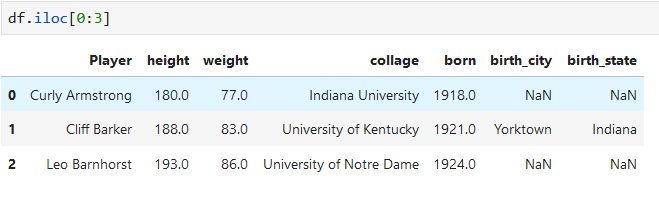
根據列表選取行

根據位置下表整數切片選取行
*****
用Player列作為索引列

*****
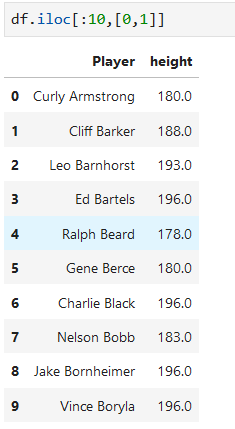
用iloc進行選取行或列,只能用 整數位置下標
例子:切片選取行,列表選取列,逗號分割的是行和列的參數
### 2.1.3. 隨機選取數據
使用sample()方法對數據進行列或者行的隨機選取,默認是對行進行選取。函數接受一個參數用來指定返回的數量或者百分比
```
隨機抽取10行
df.sample(10)
```

*****
```
隨機返回總數量的百分之一數據
df.sample(frac=0.01)
```

*****
**通過控制axis對列進行抽樣**
.head()默認顯示前五行
```
隨機抽取三列,并顯示前五行
df.sample(n = 3,axis = 1).head()
```

*****
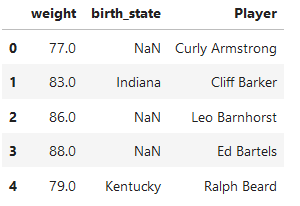
sample有一個參數,random_state是隨機數種子,決定是否返回固定的隨機數據
df.sample(n = 3,axis = 1,random_state=10).head()
*****
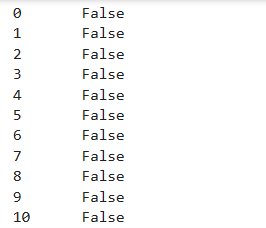
### 2.1.4. 使用isin()
該函數回返回一個布爾型向量,根據Series里面的值是否在給定的列表中。通過這個條件篩選出多行數據!
```
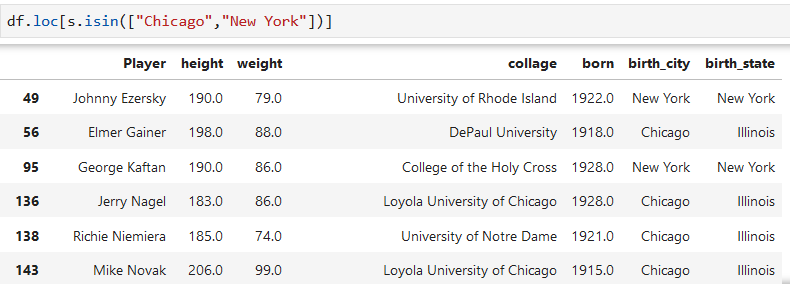
# 過濾 "Chicago","New York"
s = df['birth_city']
s.isin(["Chicago","New York"])
```
dataFrame默認按行選取

*****
*****
**對多列進行布爾值選取**
對于DataFrame我們可以使用dict進行處理,dict的key就是對應的column name.
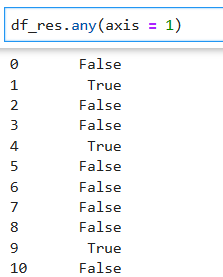
我們經常與all()或者any函數組合進行數據過濾選取
* all 指定axis上的元素全部為True
* any 指定axis上的元素至少一個為True

*****
選出全為true的列

*****
axis= 1是篩選行,axis=0是篩選列
一行中有一個true,這行被標記為true,通過loc返回行

### 2.1.5. 數據過濾
基于loc的強大功能,我們可以對數據做很多復雜的操作。第一個就是實現數據的過濾,類似于SQL里面的where功能選取出height >= 180 ,weight >= 80的運動員數據。
*****
選出符合條件的數據行

*****
* 如果height >= 180, weight >=80, 值為 “high"
* 如果height=170, weight=70 值為 ”msize"
* 其余的值為 "small"
```
#1 新建一個flag列,將符合條件的行的flag列填入"high"值
df.loc[(df['height'] >=180) & (df['weight'] >=80),"flag"] = "high"
```

*****
```
#2 新建一個flag列,將符合條件的行的flag列填入"msize"值
df.loc[((df['height'] <=180) & (df['height']>=170)) & ((df['weight'] <=80) & (df['weight'] >=70)),"flag"] = "msize"
```
*****
```
#3 其余的值為 "small" ~對條件1和2進行否定,不滿足條件一或2的。新建一個flag列,將符合條件的行的flag列填入"small"值
df.loc[~(((df['height'] >=180) & (df['weight'] >=80)) |(((df['height'] <=180) & (df['height']>=170))&((df['weight'] <=80) & (df['weight'] >=70)))),"flag"] = "small"
```
*****
對flag列各值的頻數進行統計

*****
對各行的height進行條件判斷,滿足條件,判定該行為true

*****
### 2.1.6. query()方法
使用表達式進行數據篩選.類似sql中的where表達式
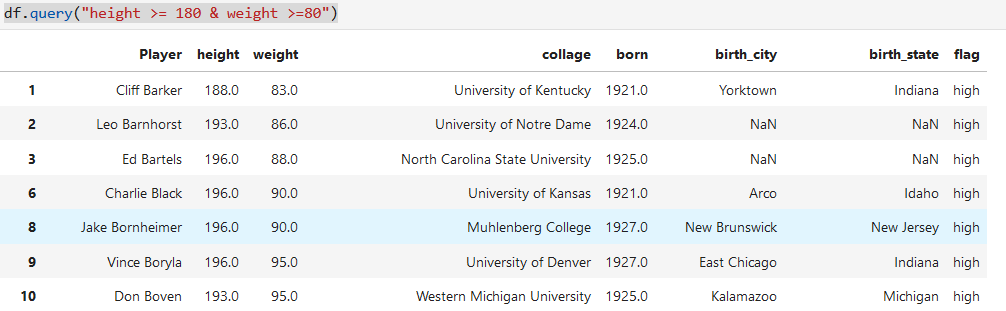

**注意**
query里面不可以引用變量

### 2.1.7. 索引設置
set_index()方法可以將一列或者多列設置為索引
```
#keys設置索引列,drop保留作為索引列的數據,append是否保留原來的位置索引,inplace修改原數據集
df.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
```
*****
把Player和collage列作為索引列

*****
將索引列放回數據框中,并且設置簡單的整數索引
```
df1.reset_index(level=None, drop=False, inplace=False, co_level=0, col_fill='')
```

### 2.1.8. where方法
* 通過布爾類型的數組選取數據僅僅返回數據的子集
* where()函數能夠確保返回的結果和原數據集的結構一樣
*****
保留符合條件的元素和索引
*****
保留原來數據集的結構

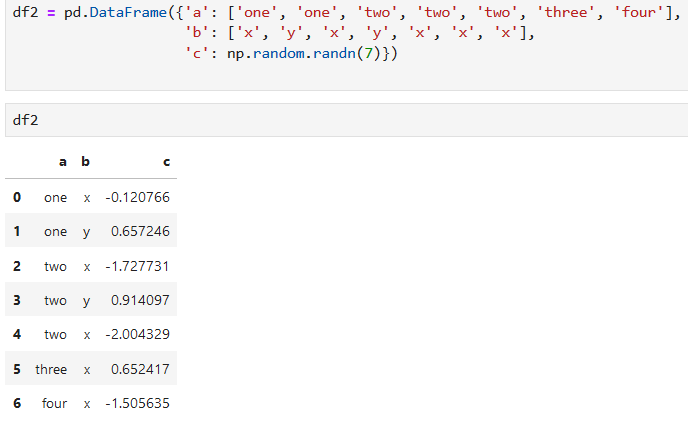
### 2.1.9. 重復數據 duplicate
* duplicated 返回一個和行數相等的布爾數組,表明某一行是否是重復的,true是重復值
* drop_duplicates 刪除重復行
*****
**通過keep參數來控制行的取舍**
* 除第一個值外,剩下重復的值都認為是重復值
keep='first' (default): mark / drop duplicates except for the first occurrence.
* 除最后一個值外,剩下重復的值都認為是重復值
keep='last': mark / drop duplicates except for the last occurrence.
* 標記所有的值為重復值
keep=False: mark / drop all duplicates.
*****
*****
```
#判斷是否有兩行是重復的
df2.duplicated()
```

*****
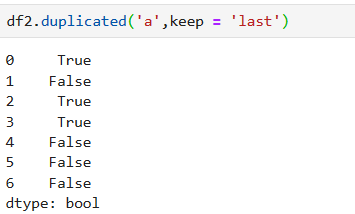
```
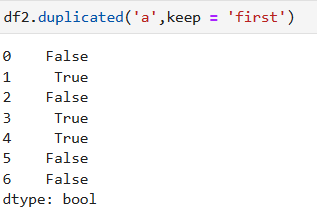
#判斷a列是否有重復值
df2.duplicated('a',keep = False)
```

*****
刪去重復行

*****
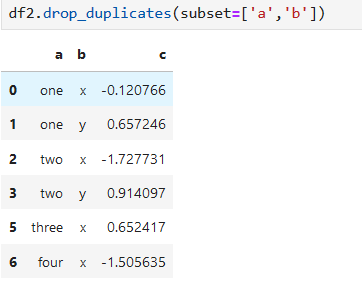
刪去a b兩列都一樣的行。第二行和第四行相等,默認刪去第四行
*****
keep = 'last',刪去最后一個重復的值之前的值

### 2.1.10. MultiIndex
層次索引可以允許我們操作更加復雜的數據
```
arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],
['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]
根據嵌套列表創建兩列索引,第一列索引叫first,第二列索引叫second
index = pd.MultiIndex.from_arrays(arrays, names=['first', 'second'])
```
第一列索引有四個值,第二列索引有兩個值。第一列索引分為四組,每組有兩個相同的值。第二列索引也分為四組,每組有兩個不同的值

*****
把數組變為元組

*****
```
#根據元組創建兩層索引
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
#得到第一層索引的值
index.get_level_values(0)
```

*****
```
#用隨機數創建series值,用建好的多層索引作為series的索引
pd.Series(np.random.randn(8), index=index)
```

*****
**索引選取**
```
#用隨機數創建8行4列的數據集。用兩層索引index作為數據集的索引。list('ABCD')作為數據集的列
df = pd.DataFrame(np.random.randn(8, 4), index=index,columns = list('ABCD'))
```

*****
```
#用多層索引,類似找書的第幾章第幾節。章是第一層索引,節是第二層索引
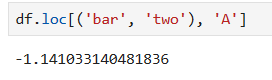
#loc根據索引標簽名選取數據 各層索引標簽名要放到一個元組里
df.loc[('bar', 'two')]
```

*****
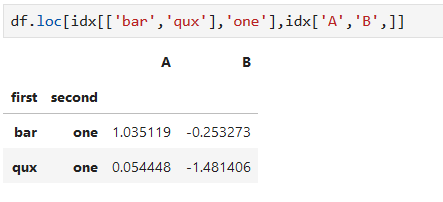
選指定多層索引的行與指定列交叉的數據
*****
多個多層索引放入列表中選取行

*****
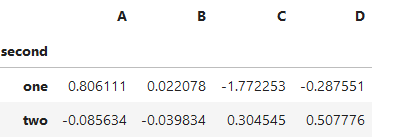
選中指定的第一層索引bar下的所有行
*****
對于多層索引,不可以跳過前面層的索引,用后面層的索引選擇行。
如:想選所有第二層索引為'one'的行 , 報錯

*****
**可以使用切片(slicers)對多重索引進行操作**
* 你可以使用任意的列表,元祖,布爾型作為Indexer
* 可以使用sclie(None)表達在某個level上選取全部的內容,不需要對全部的level進行指定,它們會被隱式的推導為slice(None)
* 所有的axis必須都被指定,意味著index和column上都要被顯式的指明
**正確的方式**
~~~python
選取第一層索引A1和第二層索引A3 選取所有的列
df.loc[(slice('A1', 'A3'), ...), :]
~~~
**錯誤的方式X**
沒有選擇列
~~~python
df.loc[(slice('A1', 'A3'), ...)]
~~~
*****
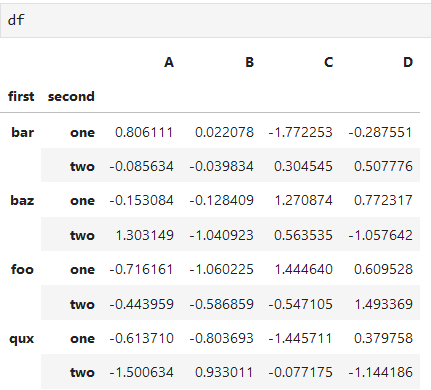
*****
```
#slice(None)選擇第一層全部索引,'one'選擇第二層帶'one'的索引,:選擇全部的列
df.loc[(slice(None),'one'),:]
```
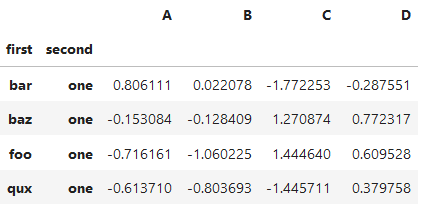
*****
```
# IndexSlice是一種更接近自然語法的用法,可以替換slice
# 生成IndexSlice
idx = pd.IndexSlice
# idx:選擇第一層全部索引。'one' : 第二層'one'索引。: 選擇全部的 列。
df.loc[idx[:,'one'],:]
```
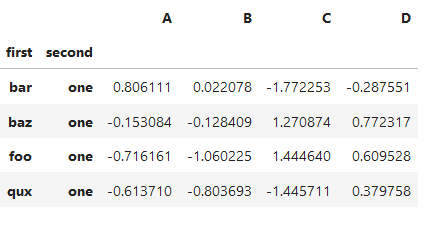
*****

*****
**函數xs()可以讓我們在指定level的索引上進行數據選取**
level=1 指定為第二層索引,第一層為level=0。選第二層帶 'one'索引的數據行
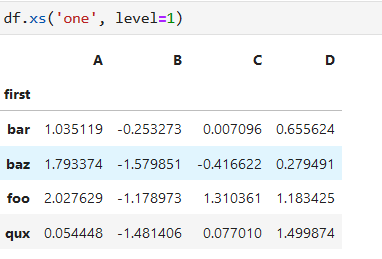
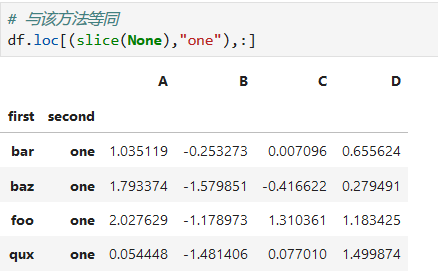

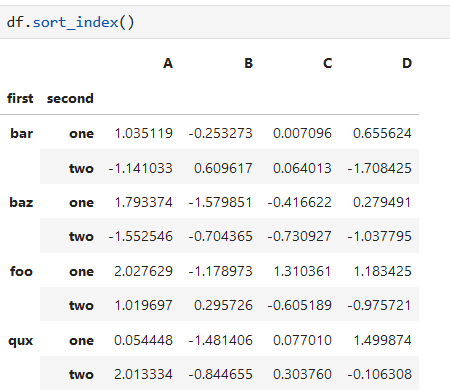
**索引排序**
先排第一層索引,下層索引再組內排序
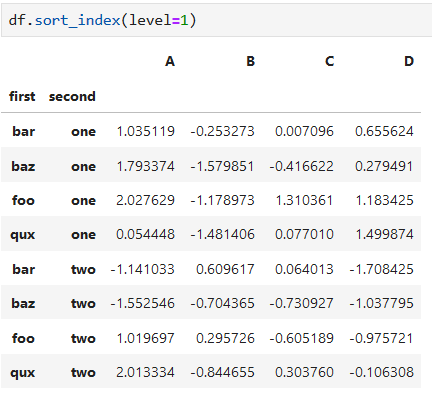
*****
數據行按第二層索引排序
- 第五節 Pandas數據管理
- 1.1 文件讀取
- 1.2 DataFrame 與 Series
- 1.3 常用操作
- 1.4 Missing value
- 1.5 文本數據
- 1.6 分類數據
- 第六節 pandas數據分析
- 2.1 索引選取
- 2.2. 分組計算
- 2.3. 表聯結
- 2.4. 數據透視與重塑(pivot table and reshape)
- 2.5 官方小結圖片
- 第七節 NUMPY科學計算
- 第八節 python可視化
- 第九節 統計學
- 01 單變量
- 02 雙變量
- 03 數值方法
- 第十節 概率
- 01 概率
- 02 離散概率分布
- 03 連續概率分布
- 第一節 抽樣與抽樣分布
- 01抽樣
- 02 點估計
- 03 抽樣分布
- 04 抽樣分布的性質
- 第十三節 區間估計
- 01總體均值的區間估計:??已知
- 02總體均值的區間估計:??未知
- 03總體容量的確定
- 04 總體比率