
[TOC]
kubernetes 對外稱,無損上下線服務。其實需要配置相關探針才能上線到該功能。**強烈建議**配置上該功能。
在分析流量有損的原因有很多,比如:
- 上線時,應用在就緒(readinessProbe)前收到流量,導致請求無法被處理
- 下線時,應用沒有做優雅退出導致請求中斷,應用沒有正確監聽到終止信號導致優雅退出無效,平臺路由規則更新不及時導致流量轉發到已經銷毀的副本等
# 滾動更新機制
在應用發布時,Kubernetes 會將已就緒的 Pod 添加到與 Service 同名的 Endpoint 對象中,并在 Endpoint 中移除處于 Terminating 狀態的 Pod。kube-controller-manger 和 kube-proxy 組件都會監聽 Service 和 Endpoint 對象的變化。在他們發生變化時,kube-proxy 組件會通過 ipvs 或 iptables 更新節點的流量轉發規則,kube-controller-manager 組件則會更新下游的后端。
Kubernetes 常用的三種工作負載:Deployment(無狀態應用)、StatefulSet(有狀態應用)、DaemonSet(守護進程) 對象都支持滾動更新。在滾動更新的過程中,通過 maxSurge 字段來控制允許超出期望副本數的副本個數,maxUnavailable 字段來控制更新過程中不可用的副本個數。
以 Deployment 為例,它的 maxSurge 和 maxUnavailable 默認值分別是25%。在滾動更新時,Kubernetes 會創建一個新的 ReplicaSet 對象來啟動新的副本,而舊的 ReplicaSet 對象會逐步減少副本數量。
假設有某應用有 5 個副本,這就意味著在滾動更新時,它最多存在 7 個副本(新增了 2 個副本,5 * 25% = 1.25,向上取整即為2)。最多只有 1 個副本(5 * 25% = 1.25,向下取整即為1)處于不可用的狀態。
# 服務上線有損分析
pod上線流程圖
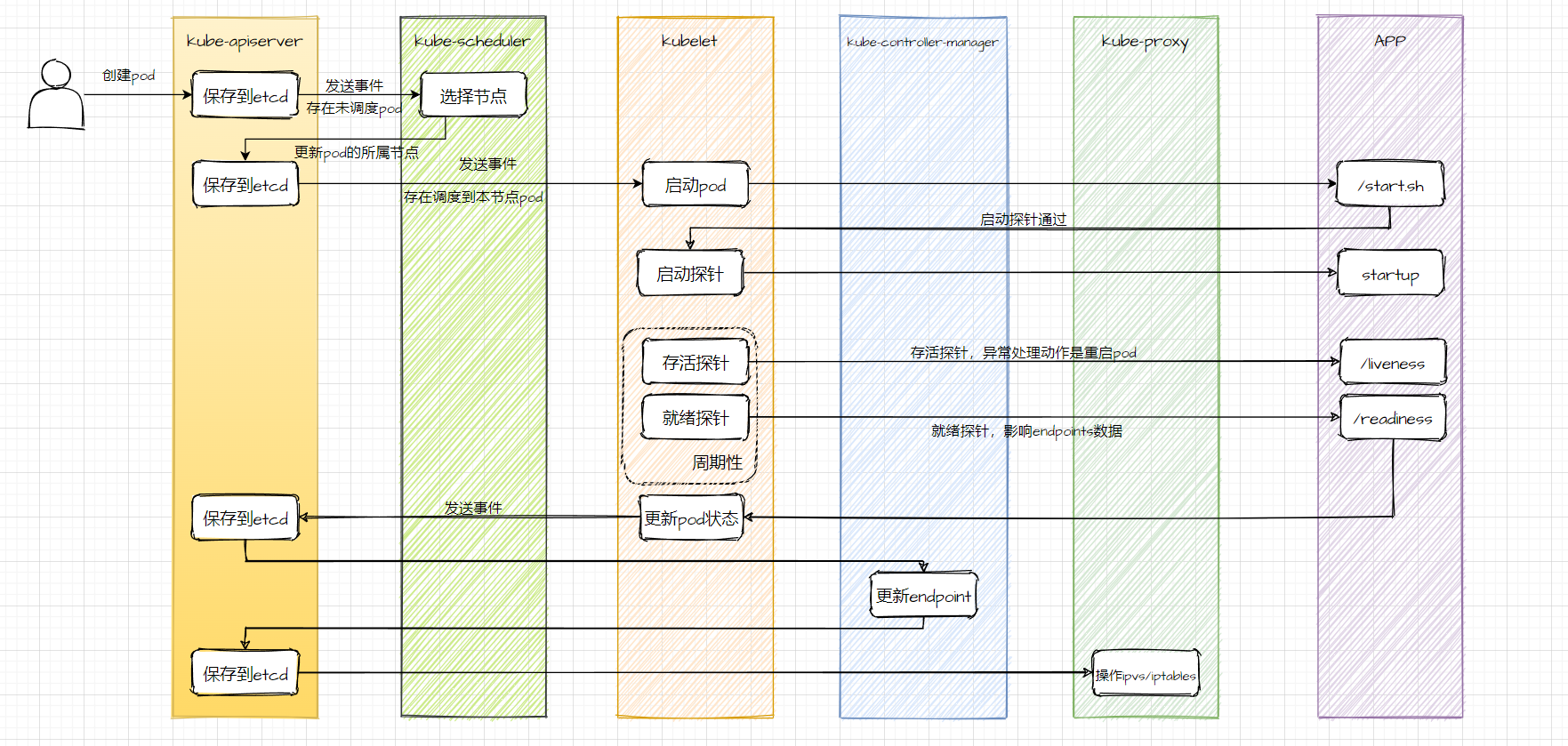
# 服務下線有損分析
pod下線流程圖
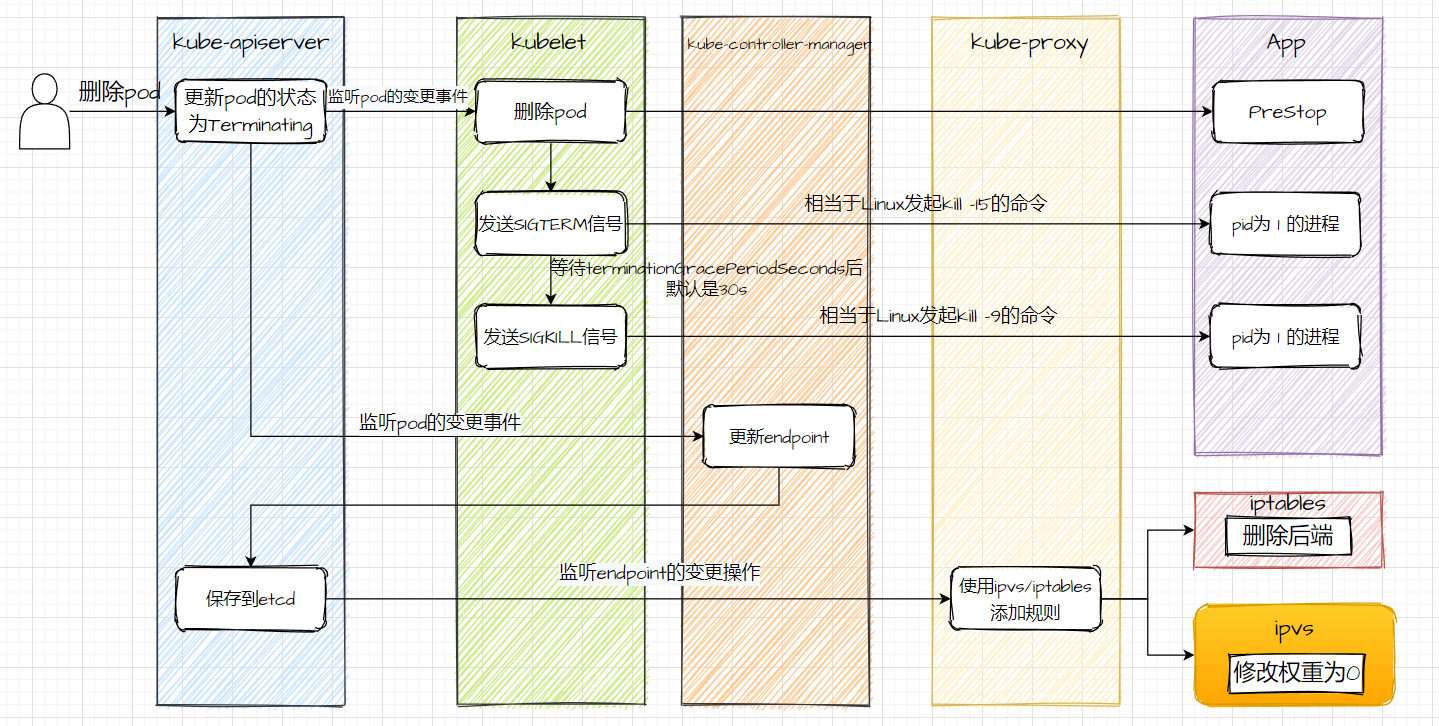
# dockerfile啟動服務
- 前言
- 架構
- 部署
- kubeadm部署
- kubeadm擴容節點
- 二進制安裝基礎組件
- 添加master節點
- 添加工作節點
- 選裝插件安裝
- Kubernetes使用
- k8s與dockerfile啟動參數
- hostPort與hostNetwork異同
- 應用上下線最佳實踐
- 進入容器命名空間
- 主機與pod之間拷貝
- events排序問題
- k8s會話保持
- 容器root特權
- CNI插件
- calico
- calicoctl安裝
- calico網絡通信
- calico更改pod地址范圍
- 新增節點網卡名不一致
- 修改calico模式
- calico數據存儲遷移
- 啟用 kubectl 來管理 Calico
- calico卸載
- cilium
- cilium架構
- cilium/hubble安裝
- cilium網絡路由
- IP地址管理(IPAM)
- Cilium替換KubeProxy
- NodePort運行DSR模式
- IP地址偽裝
- ingress使用
- nginx-ingress
- ingress安裝
- ingress高可用
- helm方式安裝
- 基本使用
- Rewrite配置
- tls安全路由
- ingress發布管理
- 代理k8s集群外的web應用
- ingress自定義日志
- ingress記錄真實IP地址
- 自定義參數
- traefik-ingress
- traefik名詞概念
- traefik安裝
- traefik初次使用
- traefik路由(IngressRoute)
- traefik中間件(middlewares)
- traefik記錄真實IP地址
- cert-manager
- 安裝教程
- 頒布者CA
- 創建證書
- 外部存儲
- 對接NFS
- 對接ceph-rbd
- 對接cephfs
- 監控平臺
- Prometheus
- Prometheus安裝
- grafana安裝
- Prometheus配置文件
- node_exporter安裝
- kube-state-metrics安裝
- Prometheus黑盒監控
- Prometheus告警
- grafana儀表盤設置
- 常用監控配置文件
- thanos
- Prometheus
- Sidecar組件
- Store Gateway組件
- Querier組件
- Compactor組件
- Prometheus監控項
- grafana
- Querier對接grafana
- alertmanager
- Prometheus對接alertmanager
- 日志中心
- filebeat安裝
- kafka安裝
- logstash安裝
- elasticsearch安裝
- elasticsearch索引生命周期管理
- kibana安裝
- event事件收集
- 資源預留
- 節點資源預留
- imagefs與nodefs驗證
- 資源預留 vs 驅逐 vs OOM
- scheduler調度原理
- Helm
- Helm安裝
- Helm基本使用
- 安全
- apiserver審計日志
- RBAC鑒權
- namespace資源限制
- 加密Secret數據
- 服務網格
- 備份恢復
- Velero安裝
- 備份與恢復
- 常用維護操作
- container runtime
- 拉取私有倉庫鏡像配置
- 拉取公網鏡像加速配置
- runtime網絡代理
- overlay2目錄占用過大
- 更改Docker的數據目錄
- Harbor
- 重置Harbor密碼
- 問題處理
- 關閉或開啟Harbor的認證
- 固定harbor的IP地址范圍
- ETCD
- ETCD擴縮容
- ETCD常用命令
- ETCD數據空間壓縮清理
- ingress
- ingress-nginx header配置
- kubernetes
- 驗證yaml合法性
- 切換KubeProxy模式
- 容器解析域名
- 刪除節點
- 修改鏡像倉庫
- 修改node名稱
- 升級k8s集群
- 切換容器運行時
- apiserver接口
- 其他
- 升級內核
- k8s組件性能分析
- ETCD
- calico
- calico健康檢查失敗
- Harbor
- harbor同步失敗
- Kubernetes
- 資源Terminating狀態
- 啟動容器報錯