
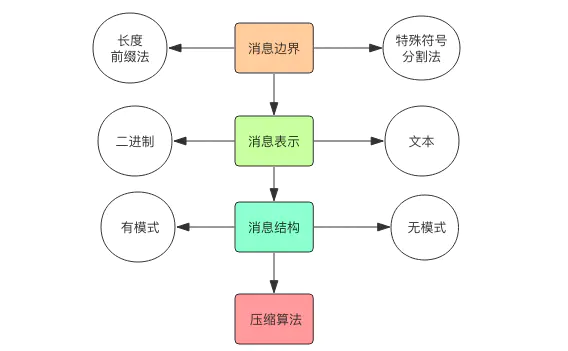
對于一串消息流,我們必須能確定消息邊界,提取出單條消息的字節流片段,然后對這個片段按照一定的規則進行反序列化來生成相應的消息對象。
消息表示指的是序列化后的消息字節流在直觀上的表現形式,它看起來是對人類友好還是對計算機友好。文本形式對人類友好,二進制形式對計算機友好。
每個消息都有其內部字段結構,結構構成了消息內部的邏輯規則,程序要按照結構規則來決定字段序列化的順序。
## 消息邊界
RPC 需要在一條 TCP 鏈接上進行多次消息傳遞。在連續的兩條消息之間必須有明確的分割規則,以便接收端可以將消息分割開來,這里的接收端可以是 RPC 服務器接收請求,也可以是 RPC 客戶端接收響應。
基于 TCP 鏈接之上的單條消息如果過大,就會被網絡協議棧拆分為多個數據包進行傳送。如果消息過小,網絡協議棧可能會將多個消息組合成一個數據包進行發送。對于接收端來說它看到的只是一串串的字節數組,如果沒有明確的消息邊界規則,接收端是無從知道這一串字節數組究竟是包含多條消息還是只是某條消息的一部分。
比較常用的兩種分割方式是特殊分割符法和長度前綴法。

消息發送端在每條消息的末尾追加一個特殊的分割符,并且保證消息中間的數據不能包含特殊分割符。比如最為常見的分割符是`\r\n`。當接收端遍歷字節數組時發現了`\r\n`,就立即可以斷定`\r\n`之前的字節數組是一條完整的消息,可以傳遞到上層邏輯繼續進行處理。HTTP 和 Redis 協議就大量使用了`\r\n`分割符。此種消息一般要求消息體的內容是文本消息。

消息發送端在每條消息的開頭增加一個 4 字節長度的整數值,標記消息體的長度。這樣消息接受者首先讀取到長度信息,然后再讀取相應長度的字節數組就可以將一個完整的消息分離出來。此種消息比較常用于二進制消息。
基于特殊分割符法的優點在于消息的可讀性比較強,可以直接看到消息的文本內容,缺點是不適合傳遞二進制消息,因為二進制的字節數組里面很容易就冒出連續的兩個字節內容正好就是`\r\n`分割符的 ascii 值。如果需要傳遞的話,一般是對二進制進行 base64 編碼轉變成普通文本消息再進行傳送。
基于長度前綴法的優點和缺點同特殊分割符法正好是相反的。長度前綴法因為適用于二進制協議,所以可讀性很差。但是對傳遞的內容本身沒有特殊限制,文本和內容皆可以傳輸,不需要進行特殊處理。HTTP 協議的 Content-Length 頭信息用來標記消息體的長度,這個也可以看成是長度前綴法的一種應用。
~~~
HTTP/1.0 200 OK
Server: SimpleHTTP/0.6 Python/2.7.13
Date: Thu, 10 May 2018 02:38:03 GMT
Content-type: text/html; charset=utf-8
Content-Length: 10393
# 此處省略 10393 字節消息體數據
~~~
HTTP 協議是一種基于特殊分割符和長度前綴法的混合型協議。比如 HTTP 的消息頭采用的是純文本外加`\r\n`分割符,而消息體則是通過消息頭中的 Content-Type 的值來決定長度。HTTP 協議雖然被稱之為文本傳輸協議,但是也可以在消息體中傳輸二進制數據數據的,例如音視頻圖像,所以 HTTP 協議被稱之為「超文本」傳輸協議。
## 消息的結構
每條消息都有它包含的語義結構信息,有些消息協議的結構信息是顯式的,還有些是隱式的。比如 json 消息,它的結構就可以直接通過它的內容體現出來,所以它是一種顯式結構的消息協議。
~~~
{
"firstName": "John",
"lastName": "Smith",
"gender": "male",
"age": 25,
"address":
{
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": "10021"
},
"phoneNumber":
[
{
"type": "home",
"number": "212 555-1234"
},
{
"type": "fax",
"number": "646 555-4567"
}
]
}
~~~
json 這種直觀的消息協議的可讀性非常棒,但是它的缺點也很明顯,有太多的冗余信息。比如每個字符串都使用雙引號來界定邊界,key/value 之間必須有冒號分割,對象之間必須使用大括號分割等等。這些還只是冗余的小頭,最大的冗余還在于連續的多條 json 消息即使結構完全一樣,僅僅只是 value 的值不一樣,也需要發送同樣的 key 字符串信息。
消息的結構在同一條消息通道上是可以復用的,比如在建立鏈接的開始 RPC 客戶端和服務器之間先交流協商一下消息的結構,后續發送消息時只需要發送一系列消息的 value 值,接收端會自動將 value 值和相應位置的 key 關聯起來,形成一個完成的結構消息。在 Hadoop 系統中廣泛使用的 avro 消息協議就是通過這種方式實現的,在 RPC 鏈接建立之處就開始交流消息的結構,后續消息的傳遞就可以節省很多流量。
消息的隱式結構一般是指那些結構信息由代碼來約定的消息協議,在 RPC 交互的消息數據中只是純粹的二進制數據,由代碼來確定相應位置的二進制是屬于哪個字段。比如下面的這段代碼
~~~
// 發送端寫消息
class AuthUserOutput {
int platformId;
long deviceId;
String productId;
String channelId;
String versionId;
String phoneModel;
@Override
public void writeImpl() {
writeByte((byte) this.platformId);
writeLong(deviceId);
writeStr(productId);
writeStr(channelId);
writeStr(versionId);
writeStr(phoneModel);
}
}
// 接收端讀取消息
class AuthorizeInput {
int platformId;
long deviceId;
String productId;
String channelId;
String versionId;
String phoneModel;
@Override
public void readImpl() {
this.platformId = readByte();
this.deviceId = readLong();
this.productId = readStr();
this.channelId = readStr();
this.versionId = readStr();
this.phoneModel = readStr();
}
}
~~~
如果純粹看消息內容是無法知道節點消息內容中的哪些字節的含義,它的消息結構是通過代碼的結構順序來確定的。這種隱式的消息的優點就在于節省傳輸流量,它完全不需要傳輸結構信息。
## 消息壓縮
如果消息的內容太大,就要考慮對消息進行壓縮處理,這可以減輕網絡帶寬壓力。但是這同時也會加重 CPU 的負擔,因為壓縮算法是 CPU 計算密集型操作,會導致操作系統的負載加重。所以,最終是否進行消息壓縮,一定要根據業務情況加以權衡。
如果確定壓縮,那么在選擇壓縮算法包時,務必挑選那些底層用 C 語言實現的算法庫,因為 Python 的字節碼執行起來太慢了。比較流行的消息壓縮算法有 Google 的 snappy 算法,它的運行性能非常好,壓縮比例雖然不是最優的,但是離最優的差距已經不是很大。阿里的 SOFA RPC 就使用了 snappy 作為協議層壓縮算法。
## 流量的極致優化
開源的流行 RPC 消息協議往往對消息流量優化到了極致,它們通過這種方式來打動用戶,吸引用戶來使用它們。比如對于一個整形數字,一般使用 4 個字節來表示一個整數值。
但是經過研究發現,消息傳遞中大部分使用的整數值都是很小的非負整數,如果全部使用 4 個字節來表示一個整數會很浪費。所以就發明了一個類型叫變長整數varint。數值非常小時,只需要使用一個字節來存儲,數值稍微大一點可以使用 2 個字節,再大一點就是 3 個字節,它還可以超過 4 個字節用來表達長整形數字。
其原理也很簡單,就是保留每個字節的最高位的 bit 來標識是否后面還有字節,1 表示還有字節需要繼續讀,0 表示到讀到當前字節就結束。

那如果是負數該怎么辦呢?-1 的 16 進制數是 0xFFFFFFFF,如果要按照這個編碼那豈不是要 6 個字節才能存的下。-1 也是非常常見的整數啊。
于是 zigzag 編碼來了,專門用來解決負數問題。zigzag 編碼將整數范圍一一映射到自然數范圍,然后再進行 varint 編碼。
~~~
0 => 0
-1 => 1
1 => 2
-2 => 3
2 => 4
-3 => 5
3 => 6
~~~
zigzag 將負數編碼成正奇數,正數編碼成偶數。解碼的時候遇到偶數直接除 2 就是原值,遇到奇數就加 1 除 2 再取負就是原值。
## 小結
現在我們知道了 RPC 消息結構的設計原理,遵循這些基本方法,就可以創造出一個又一個不同的消息協議。
- 前言
- 服務器開發設計
- Reactor模式
- 一種心跳,兩種設計
- 聊聊 TCP 長連接和心跳那些事
- 學習TCP三次握手和四次揮手
- Linux基礎
- Linux的inode的理解
- 異步IO模型介紹
- 20個最常用的GCC編譯器參數
- epoll
- epoll精髓
- epoll原理詳解及epoll反應堆模型
- epoll的坑
- epoll的本質
- socket的SO_REUSEADDR參數全面分析
- 服務器網絡
- Protobuf
- Protobuf2 語法指南
- 一種自動反射消息類型的 Protobuf 網絡傳輸方案
- 微服務
- RPC框架
- 什么是RPC
- 如何科學的解釋RPC
- RPC 消息協議
- 實現一個極簡版的RPC
- 一個基于protobuf的極簡RPC
- 如何基于protobuf實現一個極簡版的RPC
- 開源RPC框架
- thrift
- grpc
- brpc
- Dubbo
- 服務注冊,發現,治理
- Redis
- Redis發布訂閱
- Redis分布式鎖
- 一致性哈希算法
- Redis常見問題
- Redis數據類型
- 緩存一致性
- LevelDB
- 高可用
- keepalived基本理解
- keepalived操做
- LVS 學習
- 性能優化
- Linux服務器程序性能優化方法
- SRS性能(CPU)、內存優化工具用法
- centos6的性能分析工具集合
- CentOS系統性能工具 sar 示例!
- Linux性能監控工具集sysstat
- gdb相關
- Linux 下如何產生core文件(core dump設置)