
說起RPC,就不能不提到**分布式**,這個促使RPC誕生的領域。
假設你有一個計算器接口,Calculator,以及它的實現類CalculatorImpl,那么在系統還是**單體應用**時,你要調用Calculator的add方法來執行一個加運算,直接new一個CalculatorImpl,然后調用add方法就行了,這其實就是非常普通的**本地函數調用**,因為在**同一個地址空間**,或者說在同一塊內存,所以通過方法棧和參數棧就可以實現。
****
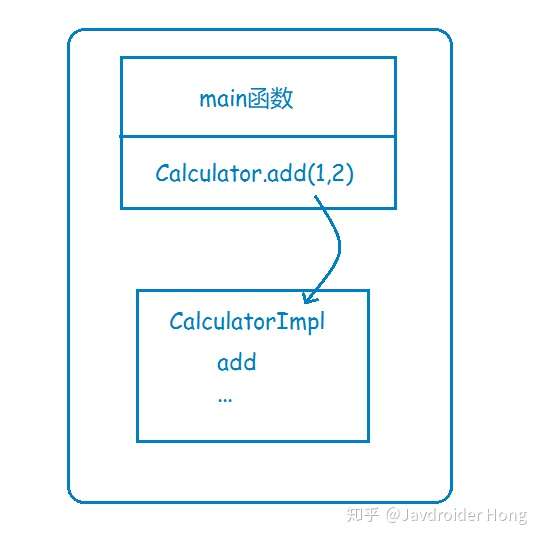
現在,基于高性能和高可靠等因素的考慮,你決定將系統改造為分布式應用,將很多可以共享的功能都單獨拎出來,比如上面說到的計算器,你單獨把它放到一個服務里頭,讓別的服務去調用它。
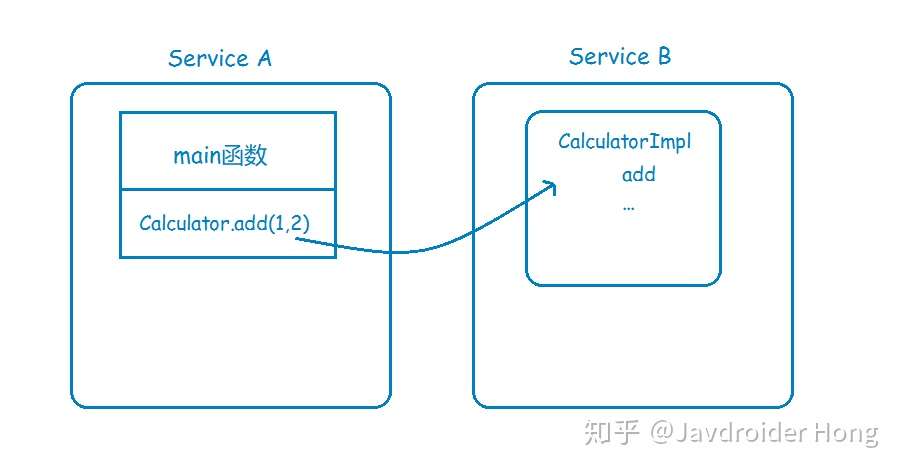
這下問題來了,服務A里頭并沒有CalculatorImpl這個類,那它要怎樣調用服務B的CalculatorImpl的add方法呢?
有同學會說,可以模仿B/S架構的調用方式呀,在B服務暴露一個Restful接口,然后A服務通過調用這個Restful接口來間接調用CalculatorImpl的add方法。
很好,這已經很接近RPC了,不過如果是這樣,那每次調用時,是不是都需要寫一串發起http請求的代碼呢?比如httpClient.sendRequest…之類的,能不能像本地調用一樣,去發起遠程調用,讓使用者感知不到遠程調用的過程呢,像這樣:
~~~java
@Reference
private Calculator calculator;
...
calculator.add(1,2);
...
~~~
這時候,有同學就會說,用**代理模式**呀!而且最好是結合Spring IoC一起使用,通過Spring注入calculator對象,注入時,如果掃描到對象加了@Reference注解,那么就給它生成一個代理對象,將這個代理對象放進容器中。而這個代理對象的內部,就是通過httpClient來實現RPC遠程過程調用的。
可能上面這段描述比較抽象,不過這就是很多RPC框架要解決的問題和解決的思路,比如阿里的Dubbo。
總結一下,**RPC要解決的兩個問題:**
1. **解決分布式系統中,服務之間的調用問題。**
2. **遠程調用時,要能夠像本地調用一樣方便,讓調用者感知不到遠程調用的邏輯。**
## 如何實現一個RPC
實際情況下,RPC很少用到http協議來進行數據傳輸,畢竟我只是想傳輸一下數據而已,何必動用到一個文本傳輸的應用層協議呢,我為什么不直接使用**二進制傳輸**?比如直接用Java的Socket協議進行傳輸?
不管你用何種協議進行數據傳輸,**一個完整的RPC過程,都可以用下面這張圖來描述**:
以左邊的Client端為例,Application就是rpc的調用方,Client Stub就是我們上面說到的代理對象,也就是那個看起來像是Calculator的實現類,其實內部是通過rpc方式來進行遠程調用的代理對象,至于Client Run-time Library,則是實現遠程調用的工具包,比如jdk的Socket,最后通過底層網絡實現實現數據的傳輸。
這個過程中最重要的就是**序列化**和**反序列化**了,因為數據傳輸的數據包必須是二進制的,你直接丟一個Java對象過去,人家可不認識,你必須把Java對象序列化為二進制格式,傳給Server端,Server端接收到之后,再反序列化為Java對象。
下一次我也將通過代碼,給大家演示一下,如何實現一個簡單的RPC。
## RPC vs Restful
其實這兩者并不是一個維度的概念,總得來說RPC涉及的維度更廣。
如果硬要比較,那么可以從RPC風格的url和Restful風格的url上進行比較。
比如你提供一個查詢訂單的接口,用RPC風格,你可能會這樣寫:
~~~text
/queryOrder?orderId=123
~~~
用Restful風格呢?
~~~text
Get
/order?orderId=123
~~~
再精煉一點,甚至可以這樣:
~~~text
Get
/order/123
~~~
**RPC是面向過程,Restful是面向資源**,并且使用了Http動詞。從這個維度上看,Restful風格的url在表述的精簡性、可讀性上都要更好。
## RPC vs RMI
嚴格來說這兩者也不是一個維度的。
RMI是Java提供的一種訪問遠程對象的協議,是已經實現好了的,可以直接用了。
而RPC呢?人家只是一種編程模型,并沒有規定你具體要怎樣實現,**你甚至都可以在你的RPC框架里面使用RMI來實現數據的傳輸**,比如Dubbo:[Dubbo - rmi協議](https://link.zhihu.com/?target=http%3A//dubbo.apache.org/books/dubbo-user-book/references/protocol/rmi.html)
## RPC沒那么簡單
**要實現一個RPC不算難,難的是實現一個高性能高可靠的RPC框架。**
比如,既然是分布式了,那么一個服務可能有多個實例,你在調用時,要如何獲取這些實例的地址呢?
這時候就需要一個服務注冊中心,比如在Dubbo里頭,就可以使用Zookeeper作為注冊中心,在調用時,從Zookeeper獲取服務的實例列表,再從中選擇一個進行調用。
那么選哪個調用好呢?這時候就需要負載均衡了,于是你又得考慮如何實現復雜均衡,比如Dubbo就提供了好幾種負載均衡策略。
這還沒完,總不能每次調用時都去注冊中心查詢實例列表吧,這樣效率多低呀,于是又有了緩存,有了緩存,就要考慮緩存的更新問題,blablabla……
你以為就這樣結束了,沒呢,還有這些:
* 客戶端總不能每次調用完都干等著服務端返回數據吧,于是就要支持異步調用;
* 服務端的接口修改了,老的接口還有人在用,怎么辦?總不能讓他們都改了吧?這就需要版本控制了;
* 服務端總不能每次接到請求都馬上啟動一個線程去處理吧?于是就需要線程池;
* 服務端關閉時,還沒處理完的請求怎么辦?是直接結束呢,還是等全部請求處理完再關閉呢?
* ……
如此種種,都是一個優秀的RPC框架需要考慮的問題。
*****
*****
.
## **二,RPC的實現原理**
正如上一講所說,RPC主要是為了解決的兩個問題:
* 解決分布式系統中,服務之間的調用問題。
* 遠程調用時,要能夠像本地調用一樣方便,讓調用者感知不到遠程調用的邏輯。
還是以計算器Calculator為例,如果實現類CalculatorImpl是放在本地的,那么直接調用即可:

現在系統變成分布式了,CalculatorImpl和調用方不在同一個地址空間,那么就必須要進行遠程過程調用:

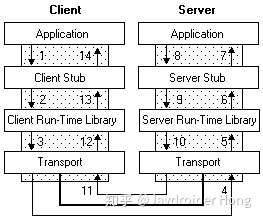
那么如何實現遠程過程調用,也就是RPC呢,一個完整的RPC流程,可以用下面這張圖來描述:

其中左邊的Client,對應的就是前面的Service A,而右邊的Server,對應的則是Service B。
下面一步一步詳細解釋一下。
1. Service A的應用層代碼中,調用了Calculator的一個實現類的add方法,希望執行一個加法運算;
2. 這個Calculator實現類,內部并不是直接實現計算器的加減乘除邏輯,而是通過遠程調用Service B的RPC接口,來獲取運算結果,因此稱之為**Stub**;
3. Stub怎么和Service B建立遠程通訊呢?這時候就要用到**遠程通訊工具**了,也就是圖中的**Run-time Library**,這個工具將幫你實現遠程通訊的功能,比如Java的**Socket**,就是這樣一個庫,當然,你也可以用基于Http協議的**HttpClient**,或者其他通訊工具類,都可以,**RPC并沒有規定說你要用何種協議進行通訊**;
4. Stub通過調用通訊工具提供的方法,和Service B建立起了通訊,然后將請求數據發給Service B。需要注意的是,由于底層的網絡通訊是基于**二進制格式**的,因此這里Stub傳給通訊工具類的數據也必須是二進制,比如calculator.add(1,2),你必須把參數值1和2放到一個Request對象里頭(這個Request對象當然不只這些信息,還包括要調用哪個服務的哪個RPC接口等其他信息),然后**序列化**為二進制,再傳給通訊工具類,這一點也將在下面的代碼實現中體現;
5. 二進制的數據傳到Service B這一邊了,Service B當然也有自己的通訊工具,通過這個通訊工具接收二進制的請求;
6. 既然數據是二進制的,那么自然要進行**反序列化**了,將二進制的數據反序列化為請求對象,然后將這個請求對象交給Service B的Stub處理;
7. 和之前的Service A的Stub一樣,這里的Stub也同樣是個“假玩意”,它所負責的,只是去解析請求對象,知道調用方要調的是哪個RPC接口,傳進來的參數又是什么,然后再把這些參數傳給對應的RPC接口,也就是Calculator的實際實現類去執行。很明顯,如果是Java,那這里肯定用到了**反射**。
8. RPC接口執行完畢,返回執行結果,現在輪到Service B要把數據發給Service A了,怎么發?一樣的道理,一樣的流程,只是現在Service B變成了Client,Service A變成了Server而已:Service B反序列化執行結果->傳輸給Service A->Service A反序列化執行結果 -> 將結果返回給Application,完畢。
理論的講完了,是時候把理論變成實踐了。
## **三,把理論變成實踐**
> *本文的示例代碼,可到[Github](https://link.zhihu.com/?target=https%3A//github.com/hzy38324/simple-rpc)下載。*
首先是Client端的應用層怎么發起RPC,ComsumerApp:
~~~java
public class ComsumerApp {
public static void main(String[] args) {
Calculator calculator = new CalculatorRemoteImpl();
int result = calculator.add(1, 2);
}
}
~~~
**通過一個CalculatorRemoteImpl,我們把RPC的邏輯封裝進去了,客戶端調用時感知不到遠程調用的麻煩**。下面再來看看CalculatorRemoteImpl,代碼有些多,但是其實就是把上面的2、3、4幾個步驟用代碼實現了而已,CalculatorRemoteImpl:
~~~java
public class CalculatorRemoteImpl implements Calculator {
public int add(int a, int b) {
List<String> addressList = lookupProviders("Calculator.add");
String address = chooseTarget(addressList);
try {
Socket socket = new Socket(address, PORT);
// 將請求序列化
CalculateRpcRequest calculateRpcRequest = generateRequest(a, b);
ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream());
// 將請求發給服務提供方
objectOutputStream.writeObject(calculateRpcRequest);
// 將響應體反序列化
ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream());
Object response = objectInputStream.readObject();
if (response instanceof Integer) {
return (Integer) response;
} else {
throw new InternalError();
}
} catch (Exception e) {
log.error("fail", e);
throw new InternalError();
}
}
}
~~~
add方法的前面兩行,lookupProviders和chooseTarget,可能大家會覺得不明覺厲。
分布式應用下,一個服務可能有多個實例,比如Service B,可能有ip地址為198.168.1.11和198.168.1.13兩個實例,lookupProviders,其實就是在尋找要調用的服務的實例列表。在分布式應用下,通常會有一個**服務注冊中心**,來提供查詢實例列表的功能。
查到實例列表之后要調用哪一個實例呢,只時候就需要chooseTarget了,其實內部就是一個**負載均衡**策略。
由于我們這里只是想實現一個簡單的RPC,所以暫時不考慮服務注冊中心和負載均衡,因此代碼里寫死了返回ip地址為127.0.0.1。
代碼繼續往下走,我們這里用到了Socket來進行遠程通訊,同時利用**ObjectOutputStream**的writeObject和**ObjectInputStream**的readObject,來實現序列化和反序列化。
最后再來看看Server端的實現,和Client端非常類似,ProviderApp:
~~~java
public class ProviderApp {
private Calculator calculator = new CalculatorImpl();
public static void main(String[] args) throws IOException {
new ProviderApp().run();
}
private void run() throws IOException {
ServerSocket listener = new ServerSocket(9090);
try {
while (true) {
Socket socket = listener.accept();
try {
// 將請求反序列化
ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream());
Object object = objectInputStream.readObject();
log.info("request is {}", object);
// 調用服務
int result = 0;
if (object instanceof CalculateRpcRequest) {
CalculateRpcRequest calculateRpcRequest = (CalculateRpcRequest) object;
if ("add".equals(calculateRpcRequest.getMethod())) {
result = calculator.add(calculateRpcRequest.getA(), calculateRpcRequest.getB());
} else {
throw new UnsupportedOperationException();
}
}
// 返回結果
ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream());
objectOutputStream.writeObject(new Integer(result));
} catch (Exception e) {
log.error("fail", e);
} finally {
socket.close();
}
}
} finally {
listener.close();
}
}
}
~~~
Server端主要是通過ServerSocket的accept方法,來接收Client端的請求,接著就是反序列化請求->執行->序列化執行結果,最后將二進制格式的執行結果返回給Client。
**就這樣我們實現了一個簡陋而又詳細的RPC。**
說它簡陋,是因為這個實現確實比較挫,在下一小節會說它為什么挫。
說它詳細,是因為它一步一步的演示了一個RPC的執行流程,方便大家了解RPC的內部機制。
## 為什么說這個RPC實現很挫
這個RPC實現只是為了給大家演示一下RPC的原理,要是想放到生產環境去用,那是絕對不行的。
1、缺乏通用性
我通過給Calculator接口寫了一個CalculatorRemoteImpl,來實現計算器的遠程調用,下一次要是有別的接口需要遠程調用,是不是又得再寫對應的遠程調用實現類?這肯定是很不方便的。
那該如何解決呢?先來看看使用Dubbo時是如何實現RPC調用的:
~~~java
@Reference
private Calculator calculator;
...
calculator.add(1,2);
...
~~~
Dubbo通過和Spring的集成,在Spring容器初始化的時候,如果掃描到對象加了@Reference注解,那么就給這個對象生成一個代理對象,這個代理對象會負責遠程通訊,然后將代理對象放進容器中。所以代碼運行期用到的calculator就是那個代理對象了。
我們可以先不和Spring集成,也就是先不采用依賴注入,但是我們要做到像Dubbo一樣,無需自己手動寫代理對象,怎么做呢?那自然是要求所有的遠程調用都遵循一套模板,**把遠程調用的信息放到一個RpcRequest對象里面,發給Server端,Server端解析之后就知道你要調用的是哪個RPC接口、以及入參是什么類型、入參的值又是什么**,就像Dubbo的RpcInvocation:
~~~java
public class RpcInvocation implements Invocation, Serializable {
private static final long serialVersionUID = -4355285085441097045L;
private String methodName;
private Class<?>[] parameterTypes;
private Object[] arguments;
private Map<String, String> attachments;
private transient Invoker<?> invoker;
...
~~~
2、集成Spring
在實現了代理對象通用化之后,下一步就可以考慮集成Spring的IOC功能了,通過Spring來創建代理對象,這一點就需要對Spring的bean初始化有一定掌握了。
3、長連接or短連接
總不能每次要調用RPC接口時都去開啟一個Socket建立連接吧?是不是可以保持若干個長連接,然后每次有rpc請求時,把請求放到任務隊列中,然后由線程池去消費執行?只是一個思路,后續可以參考一下Dubbo是如何實現的。
4、 服務端線程池
我們現在的Server端,是單線程的,每次都要等一個請求處理完,才能去accept另一個socket的連接,這樣性能肯定很差,是不是可以通過一個線程池,來實現同時處理多個RPC請求?同樣只是一個思路。
5、服務注冊中心
正如之前提到的,要調用服務,首先你需要一個服務注冊中心,告訴你對方服務都有哪些實例。Dubbo的服務注冊中心是可以配置的,官方推薦使用Zookeeper。如果使用Zookeeper的話,要怎樣往上面注冊實例,又要怎樣獲取實例,這些都是要實現的。
6、負載均衡
如何從多個實例里挑選一個出來,進行調用,這就要用到負載均衡了。負載均衡的策略肯定不只一種,要怎樣把策略做成可配置的?又要如何實現這些策略?同樣可以參考Dubbo,[Dubbo - 負載均衡](https://link.zhihu.com/?target=http%3A//dubbo.apache.org/books/dubbo-user-book/demos/loadbalance.html)
7、結果緩存
每次調用查詢接口時都要真的去Server端查詢嗎?是不是要考慮一下支持緩存?
8、多版本控制
服務端接口修改了,舊的接口怎么辦?
9、異步調用
客戶端調用完接口之后,不想等待服務端返回,想去干點別的事,可以支持不?
10、優雅停機
服務端要停機了,還沒處理完的請求,怎么辦?
……
諸如此類的優化點還有很多,這也是為什么實現一個高性能高可用的RPC框架那么難的原因。
當然,我們現在已經有很多很不錯的RPC框架可以參考了,我們完全可以借鑒一下前人的智慧。
**后面如果有(dian)機(zan)會(duo)的話**,也將和大家分享一下如何一步一步優化現有的這塊RPC代碼,把它做成一個小型RPC框架!
- 前言
- 服務器開發設計
- Reactor模式
- 一種心跳,兩種設計
- 聊聊 TCP 長連接和心跳那些事
- 學習TCP三次握手和四次揮手
- Linux基礎
- Linux的inode的理解
- 異步IO模型介紹
- 20個最常用的GCC編譯器參數
- epoll
- epoll精髓
- epoll原理詳解及epoll反應堆模型
- epoll的坑
- epoll的本質
- socket的SO_REUSEADDR參數全面分析
- 服務器網絡
- Protobuf
- Protobuf2 語法指南
- 一種自動反射消息類型的 Protobuf 網絡傳輸方案
- 微服務
- RPC框架
- 什么是RPC
- 如何科學的解釋RPC
- RPC 消息協議
- 實現一個極簡版的RPC
- 一個基于protobuf的極簡RPC
- 如何基于protobuf實現一個極簡版的RPC
- 開源RPC框架
- thrift
- grpc
- brpc
- Dubbo
- 服務注冊,發現,治理
- Redis
- Redis發布訂閱
- Redis分布式鎖
- 一致性哈希算法
- Redis常見問題
- Redis數據類型
- 緩存一致性
- LevelDB
- 高可用
- keepalived基本理解
- keepalived操做
- LVS 學習
- 性能優化
- Linux服務器程序性能優化方法
- SRS性能(CPU)、內存優化工具用法
- centos6的性能分析工具集合
- CentOS系統性能工具 sar 示例!
- Linux性能監控工具集sysstat
- gdb相關
- Linux 下如何產生core文件(core dump設置)