
[TOC]
## **粘包說明**
說明粘包問題,需要先看做一次下面的小實驗,根據結果來看原理
### **基于TCP的簡單ssh程序**
寫一個遠程執行命令的程序,寫一個socket client端在windows端發送指令,一個socket server在Linux端執行命令并返回結果給客戶端
執行命令的話,肯定是用我們學過的subprocess模塊啦,但要**注意操作系統的編碼問題**:
Windows用的GBK,linux用的utf-8
~~~
res = subprocess.Popen(cmd.decode('utf-8'),shell=True,stderr=subprocess.PIPE,stdout=subprocess.PIPE)
~~~
**ssh server代碼**
僅在源代碼上加入了命令執行部分,其他結構都沒有變化
~~~
import socket,subprocess
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind(('127.0.0.1',8800))
phone.listen(5)
print('starting...')
while True: # 鏈接循環
conn,client_addr=phone.accept()
print(client_addr)
while True: #通信循環
try:
#1、收命令
cmd=conn.recv(1024)
if not cmd:break
#2、執行命令,拿到結果
obj = subprocess.Popen(cmd.decode('utf-8'), shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
stdout=obj.stdout.read()
stderr=obj.stderr.read()
#3、把命令的結果返回給客戶端
print(len(stdout)+len(stderr))
conn.send(stdout+stderr) #+是一個可以優化的點
except ConnectionResetError:
break
conn.close()
phone.close()
~~~
**ssh client代碼**
client端代碼無任何變化,僅添加部分注釋
~~~
import socket
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.connect(('127.0.0.1',8800))
while True:
#1、發命令
cmd=input('>>: ').strip() #ls /etc
if not cmd:continue
phone.send(cmd.encode('utf-8'))
#2、拿命令的結果,并打印
data=phone.recv(1024)
print(data.decode('utf-8'))
phone.close()
~~~
### **粘包說明**
在上面的程序中,嘗試執行ls、pwd等結果長度較少的命令時,拿到了正確的結果!
但執行一個結果比較長的命令,比如top -bn 1, 你發現依然可以拿到結果,再執行一條df -h的話,就發現拿到并不是df命令的結果,而是上一條top命令的部分結果。
這個現象叫做粘包,就是指兩次結果粘到一起了
* 起因
op命令的結果比較長,但客戶端只recv(1024), 可結果比1024長呀,那只好在服務器端的IO緩沖區里把客戶端還沒收走的暫時存下來,等客戶端下次再來收,所以當客戶端第2次調用recv(1024)就會首先把上次沒收完的數據先收下來,再收df命令的結果。
而且有關部門建議recv不要超過8192,再大反而會出現影響收發速度和不穩定的情況,所以不能通過該帶reve來解決
* 原因
所謂粘包問題主要還是因為接收方不知道消息之間的界限,不知道一次性提取多少字節的數據所造成的。
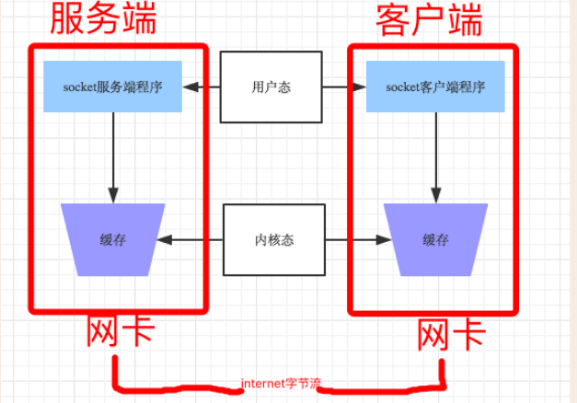
我們的應用程序實際上無權直接操作網卡的,操作網卡都是通過操作系統給用戶程序暴露出來的接口,每次程序要給遠程發數據時,其實是先把數據從用戶態copy到內核態后由操作系統完成后續工作,而Nagle算法會將多次間隔較小且數據量小的數據,合并成一個大的數據塊,然后進行封包,這樣接收方就收到了粘包數據。
### **粘包總結**
1. TCP(transport control protocol,傳輸控制協議)
是面向連接的,面向流的,提供高可靠性服務。收發兩端(客戶端和服務器端)都要有一一成對的socket,因此,發送端為了將多個發往接收端的包,更有效的發到對方,使用了優化方法(Nagle算法),將多次間隔較小且數據量小的數據,合并成一個大的數據塊,然后進行封包。這樣,接收端,就難于分辨出來了,必須提供科學的拆包機制。 **即面向流的通信是無消息保護邊界的。**
2. UDP(user datagram protocol,用戶數據報協議)
是無連接的,面向消息的,提供高效率服務。不會使用塊的合并優化算法,, 由于UDP支持的是一對多的模式,所以接收端的skbuff(套接字緩沖區)采用了鏈式結構來記錄每一個到達的UDP包,在每個UDP包中就有了消息頭(消息來源地址,端口等信息),這樣,對于接收端來說,就容易進行區分處理了。**即面向消息的通信是有消息保護邊界的。**
3. 空消息的處理
tcp是基于數據流的,于是收發的消息不能為空,這就需要在客戶端和服務端都添加空消息的處理機制,防止程序卡住
而udp是基于數據報的,即便輸入的是空內容,那也不是空消息,udp協議會幫你封裝上消息頭
## **粘包問題解決**
解決粘包問題的問題的思路,就是先發送數據前,先統計一下當前需要發送的數據有多長,然后將數據長度告訴對端,讓對端只接收指定長度的數據即可
### **兩種做法說明:**
1. low逼做法
手動統計數據長度,然后先發送數據長度給對端,待對端回復消息后再發送真實數據
2. 大牛做法
將數據長度作為數據報頭封裝到真實數據前面,只要能指定報頭長度(如4bytes),即可讓對端先接收指定長度的報頭,在根據報頭中寫入的數據長度大小,通過for循環接收真實數據
### **struct模塊解決粘包**
python中的struct模塊正好可以解決報頭定長的問題,通過len方法計算數據長度后,通過struct模塊轉換為定長數據,然后就可以用來做報頭數據了
**server端代碼**
```
import socket,subprocess,struct
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind(('127.0.0.1',8800))
phone.listen(5)
print('starting...')
while True: # 鏈接循環
conn,client_addr=phone.accept()
print(client_addr)
while True: #通信循環
try:
cmd=conn.recv(8096)
if not cmd:break
obj = subprocess.Popen(cmd.decode('utf-8'), shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
stdout=obj.stdout.read()
stderr=obj.stderr.read()
#第一步:制作固定長度的報頭
total_size = len(stdout) + len(stderr)
header=struct.pack('i',total_size)
#第二步:把報頭發送給客戶端
conn.send(header)
#第三步:再發送真實的數據
conn.send(stdout)
conn.send(stderr)
except ConnectionResetError:
break
conn.close()
phone.close()
```
**client端代碼**
```
import socket,struct
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.connect(('127.0.0.1',9909))
while True:
cmd=input('>>: ').strip() #ls /etc
if not cmd:continue
phone.send(cmd.encode('utf-8'))
#第一步:先收報頭
header=phone.recv(4) #報頭長度是自己計劃好的
#第二步:從報頭中解析出對真實數據的描述信息(數據的長度)
total_size=struct.unpack('i',header)[0]
#第三步:接收真實的數據
recv_size=0
recv_data=b''
while recv_size < total_size:
res=phone.recv(1024)
recv_data+=res
recv_size+=len(res)
print(recv_data.decode('utf-8'))
phone.close()
```
### **struct+json終極解決粘包**
既然可以用struct來做定長報頭,那就可以更進一步,使用json序列化模塊,在報頭中寫入更多信息
**server代碼**
```
import socket,subprocess,struct,json
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind(('127.0.0.1',9909))
phone.listen(5)
print('starting...')
while True: # 鏈接循環
conn,client_addr=phone.accept()
print(client_addr)
while True: #通信循環
try:
cmd=conn.recv(8096)
if not cmd:break
obj = subprocess.Popen(cmd.decode('utf-8'), shell=True,
stdout=subprocess.PIPE,stderr=subprocess.PIPE)
stdout=obj.stdout.read()
stderr=obj.stderr.read()
#第一步:制作固定長度的報頭
header_dic={
'filename':'a.txt',
'md5':'xxdxxx',
'total_size': len(stdout) + len(stderr)
}
header_json=json.dumps(header_dic)
header_bytes=header_json.encode('utf-8')
#第二步:先發送報頭的長度
conn.send(struct.pack('i',len(header_bytes)))
#第三步:再發報頭
conn.send(header_bytes)
#第四步:再發送真實的數據
conn.send(stdout)
conn.send(stderr)
except ConnectionResetError:
break
conn.close()
phone.close()
```
**client端代碼**
```
import socket,struct,json
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.connect(('127.0.0.1',9909))
while True:
cmd=input('>>: ').strip() #ls /etc
if not cmd:continue
phone.send(cmd.encode('utf-8'))
#第一步:先收報頭的長度
obj=phone.recv(4)
header_size=struct.unpack('i',obj)[0]
#第二步:再收報頭
header_bytes=phone.recv(header_size)
#第三步:從報頭中解析出對真實數據的描述信息
header_json=header_bytes.decode('utf-8')
header_dic=json.loads(header_json)
print(header_dic)
total_size=header_dic['total_size']
#第四步:接收真實的數據
recv_size=0
recv_data=b''
while recv_size < total_size:
res=phone.recv(1024) #按1024循環收取
recv_data+=res
recv_size+=len(res)
print(recv_data.decode('utf-8'))
phone.close()
```
- 基礎部分
- 基礎知識
- 變量
- 數據類型
- 數字與布爾詳解
- 列表詳解list
- 字符串詳解str
- 元組詳解tup
- 字典詳解dict
- 集合詳解set
- 運算符
- 流程控制與循環
- 字符編碼
- 編的小程序
- 三級菜單
- 斐波那契數列
- 漢諾塔
- 文件操作
- 函數相關
- 函數基礎知識
- 函數進階知識
- lambda與map-filter-reduce
- 裝飾器知識
- 生成器和迭代器
- 琢磨的小技巧
- 通過operator函數將字符串轉換回運算符
- 目錄規范
- 異常處理
- 常用模塊
- 模塊和包相關概念
- 絕對導入&相對導入
- pip使用第三方源
- time&datetime模塊
- random隨機數模塊
- os 系統交互模塊
- sys系統模塊
- shutil復制&打包模塊
- json&pickle&shelve模塊
- xml序列化模塊
- configparser配置模塊
- hashlib哈希模塊
- subprocess命令模塊
- 日志logging模塊基礎
- 日志logging模塊進階
- 日志重復輸出問題
- re正則表達式模塊
- struct字節處理模塊
- abc抽象類與多態模塊
- requests與urllib網絡訪問模塊
- 參數控制模塊1-optparse-過時
- 參數控制模塊2-argparse
- pymysql數據庫模塊
- requests網絡請求模塊
- 面向對象
- 面向對象相關概念
- 類與對象基礎操作
- 繼承-派生和組合
- 抽象類與接口
- 多態與鴨子類型
- 封裝-隱藏與擴展性
- 綁定方法與非綁定方法
- 反射-字符串映射屬性
- 類相關內置方法
- 元類自定義及單例模式
- 面向對象的軟件開發
- 網絡-并發編程
- 網絡編程SOCKET
- socket簡介和入門
- socket代碼實例
- 粘包及粘包解決辦法
- 基于UDP協議的socket
- 文件傳輸程序實戰
- socketserver并發模塊
- 多進程multiprocessing模塊
- 進程理論知識
- 多進程與守護進程
- 鎖-信號量-事件
- 隊列與生產消費模型
- 進程池Pool
- 多線程threading模塊
- 進程理論和GIL鎖
- 死鎖與遞歸鎖
- 多線程與守護線程
- 定時器-條件-隊列
- 線程池與進程池(新方法)
- 協程與IO模型
- 協程理論知識
- gevent與greenlet模塊
- 5種網絡IO模型
- 非阻塞與多路復用IO實現
- 帶著目標學python
- Pycharm基本使用
- 爬蟲
- 案例-爬mzitu美女
- 案例-爬小說
- beautifulsoup解析模塊
- etree中的xpath解析模塊
- 反爬對抗-普通驗證碼
- 反爬對抗-session登錄
- 反爬對抗-代理池
- 爬蟲技巧-線程池
- 爬蟲對抗-圖片懶加載
- selenium瀏覽器模擬