
[toc]
## 網絡IO的模型分類
此IO模型出至Richard Stevens的<<UNIX? Network Programming Volume 1>>
Stevens在文章中一共比較了五種IO Model:
* blocking IO 阻塞IO
* nonblocking IO 非阻塞IO
* IO multiplexing IO多路復用
* signal driven IO 型號驅動IO
* asynchronous IO 異步IO
>由signal driven IO(信號驅動IO)在實際中并不常用,所以主要介紹其余四種IO Model。
對于一個network IO (以read舉例),它會涉及到兩個系統對象,一個是調用這個IO的process (or thread),另一個就是系統內核(kernel)。當一個read操作發生時,該操作會經歷兩個階段:
~~~
1)等待數據準備 (Waiting for the data to be ready)
2)將數據從內核拷貝到進程中(Copying the data from the kernel to the process)
~~~
這兩點很重要,因為這些IO模型的區別就是在兩個階段上各有不同的情況。
## **阻塞IO(blocking IO)**
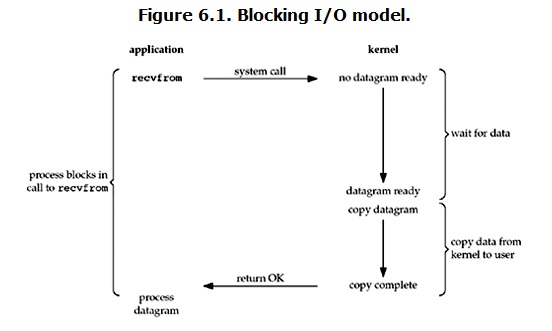
在linux中,默認情況下所有的socket都是blocking,一個典型的讀操作流程大概是這樣:
* 準備數據階段
當用戶進程調用了recvfrom這個系統調用,kernel就開始了IO的第一個階段:準備數據。對于network io來說,很多時候數據在一開始還沒有到達,這個時候kernel就要等待足夠的數據到來。
而在用戶進程這邊,整個進程會被阻塞。
* 拷貝數據階段
當kernel一直等到數據準備好了,它就會將數據從kernel中拷貝到用戶內存,然后kernel返回結果,用戶進程才解除block的狀態,重新運行起來。
* 總結
**blocking IO的特點就是在IO執行的兩個階段(等待數據和拷貝數據兩個階段)都被block了。**
* 多線程能否解決
**對應所面臨的可能同時出現的上千甚至上萬次的客戶端請求,“線程池”或“連接池”或許可以緩解部分壓力,但是不能解決所有問題。總之,多線程模型可以方便高效的解決小規模的服務請求,但面對大規模的服務請求,多線程模型也會遇到瓶頸**
可以用非阻塞接口來嘗試解決這個問題。
## **非阻塞IO(non-blocking IO)**
Linux下,可以通過設置socket使其變為non-blocking。當對一個non-blocking socket執行讀操作時,流程是這個樣子:

* 數據準備階段
當用戶進程發出read操作時,如果kernel中的數據還沒有準備好,那么它并不會block用戶進程,而是立刻返回一個error。
從用戶進程角度講 ,它發起一個read操作后,并不需要等待,而是馬上就得到了一個結果。用戶進程判斷結果是一個error時,它就知道數據還沒有準備好,于是用戶就可以在本次到下次再發起read詢問的時間間隔內做其他事情,或者直接再次發送read操作。
* 拷貝數據階段
一旦kernel中的數據準備好了,并且又再次收到了用戶進程的system call,那么它馬上就將數據拷貝到了用戶內存(這一階段仍然是阻塞的),然后返回。
~~~
也就是說非阻塞的recvform系統調用調用之后,進程并沒有被阻塞,
內核馬上返回給進程,如果數據還沒準備好,此時會返回一個error。
進程在返回之后,可以干點別的事情,然后再發起recvform系統調用。
重復上面的過程,循環往復的進行recvform系統調用,這個過程通常被稱之為輪詢。
輪詢檢查內核數據,直到數據準備好,再拷貝數據到進程,進行數據處理。
需要注意,拷貝數據整個過程,進程仍然是屬于阻塞的狀態。
~~~
* 總結
**在非阻塞式IO中,用戶進程其實是需要不斷的主動詢問kernel數據準備好了沒有。**
**但是非阻塞IO模型絕不被推薦。**
* 優點
能夠在等待任務完成的時間里干其他活了(包括提交其他任務,也就是 “后臺” 可以有多個任務在“”同時“”執行)。
* 缺點:
循環調用recv()將大幅度推高CPU占用率;
任務完成的響應延遲增大了,這會導致整體數據吞吐量的降低。
因為每過一段時間才去輪詢一次read操作,而任務可能在兩次輪詢之間的任意時間完成。
## **多路復用IO(IO multiplexing)**
IO multiplexing也可以說是select/epoll,也稱這種IO方式為**事件驅動IO**(event driven IO)。
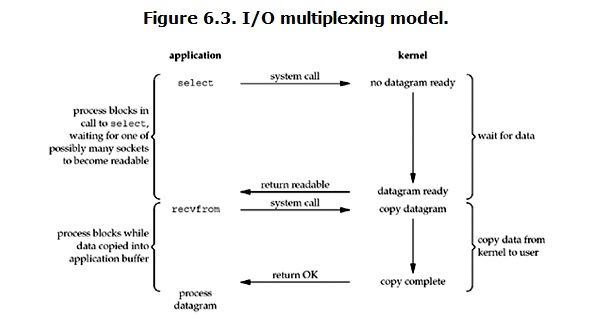
select/epoll的好處就在于單個process就可以同時處理多個網絡連接的IO。它的基本原理就是select/epoll這個function會不斷的輪詢所負責的所有socket,當某個socket有數據到達了,就通知用戶進程。它的流程如圖:
* 數據準備階段:
當用戶進程調用了select,那么整個進程會被block,而同時,kernel會“監視”所有select負責的socket
* 拷貝數據階段
當任何一個socket中的數據準備好了,select就會返回。這個時候用戶進程再調用read操作,將數據從kernel拷貝到用戶進程。
* 結論
**結論: select的優勢在于可以處理多個連接,不適用于單個連接**
用select的優勢在于它可以同時處理多個connection。
**可以使用selectors模塊,幫我們默認選擇當前平臺下最合適的IO多路復用模型**
* **該模型的優點:**
相比其他模型,使用select() 的事件驅動模型只用單線程(進程)執行,占用資源少,不消耗太多 CPU,同時能夠為多客戶端提供服務。
如果試圖建立一個簡單的事件驅動的服務器程序,這個模型有一定的參考價值。*
* **該模型的缺點:**
首先select()接口并不是實現“事件驅動”的最好選擇。因為當需要探測的句柄值較大時,select()接口本身需要消耗大量時間去輪詢各個句柄。
* **幾種多路復用IO的實現**
select 輪詢方式,windows只支持這種方式 ,linux也支持
poll 輪詢方式,linux支持,poll能夠監聽的對象比select要多
**epoll 回調函數的方式,只有linux ,是一種很高效的方式**
## 異步IO(Asynchronous I/O)
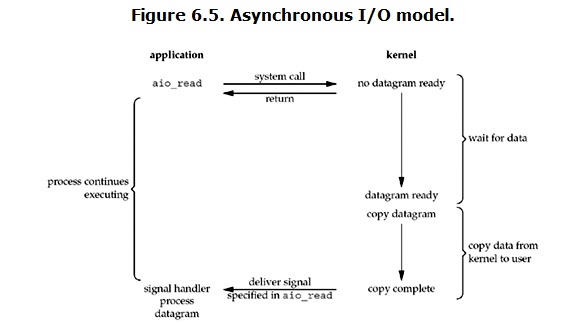
Linux下的asynchronous IO其實用得不多,從內核2.6版本才開始引入,。先看一下它的流程:
* 數據準備階段
用戶進程發起read操作之后,立刻就可以開始去做其它的事。而另一方面,從kernel的角度,當它受到一個asynchronous read之后,首先它會立刻返回,所以不會對用戶進程產生任何block。
* 數據準備階段
然后,kernel會等待數據準備完成,然后將數據拷貝到用戶內存,當這一切都完成之后,kernel會給用戶進程發送一個signal,告訴它read操作完成了。
* 優缺點
異步IO應該是最好的IO模型,因為它在兩個階段都沒有阻塞,但是python沒有辦法直接實現異步IO,但是可以使用開源的如`Tornado框架`等
- 基礎部分
- 基礎知識
- 變量
- 數據類型
- 數字與布爾詳解
- 列表詳解list
- 字符串詳解str
- 元組詳解tup
- 字典詳解dict
- 集合詳解set
- 運算符
- 流程控制與循環
- 字符編碼
- 編的小程序
- 三級菜單
- 斐波那契數列
- 漢諾塔
- 文件操作
- 函數相關
- 函數基礎知識
- 函數進階知識
- lambda與map-filter-reduce
- 裝飾器知識
- 生成器和迭代器
- 琢磨的小技巧
- 通過operator函數將字符串轉換回運算符
- 目錄規范
- 異常處理
- 常用模塊
- 模塊和包相關概念
- 絕對導入&相對導入
- pip使用第三方源
- time&datetime模塊
- random隨機數模塊
- os 系統交互模塊
- sys系統模塊
- shutil復制&打包模塊
- json&pickle&shelve模塊
- xml序列化模塊
- configparser配置模塊
- hashlib哈希模塊
- subprocess命令模塊
- 日志logging模塊基礎
- 日志logging模塊進階
- 日志重復輸出問題
- re正則表達式模塊
- struct字節處理模塊
- abc抽象類與多態模塊
- requests與urllib網絡訪問模塊
- 參數控制模塊1-optparse-過時
- 參數控制模塊2-argparse
- pymysql數據庫模塊
- requests網絡請求模塊
- 面向對象
- 面向對象相關概念
- 類與對象基礎操作
- 繼承-派生和組合
- 抽象類與接口
- 多態與鴨子類型
- 封裝-隱藏與擴展性
- 綁定方法與非綁定方法
- 反射-字符串映射屬性
- 類相關內置方法
- 元類自定義及單例模式
- 面向對象的軟件開發
- 網絡-并發編程
- 網絡編程SOCKET
- socket簡介和入門
- socket代碼實例
- 粘包及粘包解決辦法
- 基于UDP協議的socket
- 文件傳輸程序實戰
- socketserver并發模塊
- 多進程multiprocessing模塊
- 進程理論知識
- 多進程與守護進程
- 鎖-信號量-事件
- 隊列與生產消費模型
- 進程池Pool
- 多線程threading模塊
- 進程理論和GIL鎖
- 死鎖與遞歸鎖
- 多線程與守護線程
- 定時器-條件-隊列
- 線程池與進程池(新方法)
- 協程與IO模型
- 協程理論知識
- gevent與greenlet模塊
- 5種網絡IO模型
- 非阻塞與多路復用IO實現
- 帶著目標學python
- Pycharm基本使用
- 爬蟲
- 案例-爬mzitu美女
- 案例-爬小說
- beautifulsoup解析模塊
- etree中的xpath解析模塊
- 反爬對抗-普通驗證碼
- 反爬對抗-session登錄
- 反爬對抗-代理池
- 爬蟲技巧-線程池
- 爬蟲對抗-圖片懶加載
- selenium瀏覽器模擬