
在 JDK 1.5 之前共享對象的協調機制只有 synchronized 和 volatile,在 JDK 1.5 中增加了新的機制 ReentrantLock,該機制的誕生并不是為了替代 synchronized,而是在 synchronized 不適用的情況下,提供一種可以選擇的高級功能。
我們本課時的面試題是,synchronized 和 ReentrantLock 是如何實現的?它們有什么區別?
#### 典型回答
synchronized 屬于獨占式悲觀鎖,是通過 JVM 隱式實現的,synchronized 只允許同一時刻只有一個線程操作資源。
在 Java 中每個對象都隱式包含一個 monitor(監視器)對象,加鎖的過程其實就是競爭 monitor 的過程,當線程進入字節碼 monitorenter 指令之后,線程將持有 monitor 對象,執行 monitorexit 時釋放 monitor 對象,當其他線程沒有拿到 monitor 對象時,則需要阻塞等待獲取該對象。
ReentrantLock 是 Lock 的默認實現方式之一,它是基于 AQS(Abstract Queued Synchronizer,隊列同步器)實現的,它默認是通過非公平鎖實現的,在它的內部有一個 state 的狀態字段用于表示鎖是否被占用,如果是 0 則表示鎖未被占用,此時線程就可以把 state 改為 1,并成功獲得鎖,而其他未獲得鎖的線程只能去排隊等待獲取鎖資源。
synchronized 和 ReentrantLock 都提供了鎖的功能,具備互斥性和不可見性。在 JDK 1.5 中 synchronized 的性能遠遠低于 ReentrantLock,但在 JDK 1.6 之后 synchronized 的性能略低于 ReentrantLock,它的區別如下:
* synchronized 是 JVM 隱式實現的,而 ReentrantLock 是 Java 語言提供的 API;
* ReentrantLock 可設置為公平鎖,而 synchronized 卻不行;
* ReentrantLock 只能修飾代碼塊,而 synchronized 可以用于修飾方法、修飾代碼塊等;
* ReentrantLock 需要手動加鎖和釋放鎖,如果忘記釋放鎖,則會造成資源被永久占用,而 synchronized 無需手動釋放鎖;
* ReentrantLock 可以知道是否成功獲得了鎖,而 synchronized 卻不行。
#### 考點分析
synchronized 和 ReentrantLock 是比線程池還要高頻的面試問題,因為它包含了更多的知識點,且涉及到的知識點更加深入,對面試者的要求也更高,前面我們簡要地介紹了 synchronized 和 ReentrantLock 的概念及執行原理,但很多大廠會更加深入的追問更多關于它們的實現細節,比如:
* ReentrantLock 的具體實現細節是什么?
* JDK 1.6 時鎖做了哪些優化?
#### 知識擴展
* [ ] ReentrantLock 源碼分析
本課時從源碼出發來解密 ReentrantLock 的具體實現細節,首先來看 ReentrantLock 的兩個構造函數:
```
public ReentrantLock() {
sync = new NonfairSync(); // 非公平鎖
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
```
無參的構造函數創建了一個非公平鎖,用戶也可以根據第二個構造函數,設置一個 boolean 類型的值,來決定是否使用公平鎖來實現線程的調度。
* [ ] 公平鎖 VS 非公平鎖
公平鎖的含義是線程需要按照請求的順序來獲得鎖;而非公平鎖則允許“插隊”的情況存在,所謂的“插隊”指的是,線程在發送請求的同時該鎖的狀態恰好變成了可用,那么此線程就可以跳過隊列中所有排隊的線程直接擁有該鎖。
而公平鎖由于有掛起和恢復所以存在一定的開銷,因此性能不如非公平鎖,所以 ReentrantLock 和 synchronized 默認都是非公平鎖的實現方式。
ReentrantLock 是通過 lock() 來獲取鎖,并通過 unlock() 釋放鎖,使用代碼如下:
```
Lock lock = new ReentrantLock();
try {
// 加鎖
lock.lock();
//......業務處理
} finally {
// 釋放鎖
lock.unlock();
}
```
ReentrantLock 中的 lock() 是通過 sync.lock() 實現的,但 Sync 類中的 lock() 是一個抽象方法,需要子類 NonfairSync 或 FairSync 去實現,NonfairSync 中的 lock() 源碼如下:
```
final void lock() {
if (compareAndSetState(0, 1))
// 將當前線程設置為此鎖的持有者
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
```
FairSync 中的 lock() 源碼如下:
```
final void lock() {
acquire(1);
}
```
可以看出非公平鎖比公平鎖只是多了一行 compareAndSetState 方法,該方法是嘗試將 state 值由 0 置換為 1,如果設置成功的話,則說明當前沒有其他線程持有該鎖,不用再去排隊了,可直接占用該鎖,否則,則需要通過 acquire 方法去排隊。
acquire 源碼如下:
```
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
```
tryAcquire 方法嘗試獲取鎖,如果獲取鎖失敗,則把它加入到阻塞隊列中,來看 tryAcquire 的源碼:
```
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
// 公平鎖比非公平鎖多了一行代碼 !hasQueuedPredecessors()
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) { //嘗試獲取鎖
setExclusiveOwnerThread(current); // 獲取成功,標記被搶占
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc); // set state=state+1
return true;
}
return false;
}
```
對于此方法來說,公平鎖比非公平鎖只多一行代碼 !hasQueuedPredecessors(),它用來查看隊列中是否有比它等待時間更久的線程,如果沒有,就嘗試一下是否能獲取到鎖,如果獲取成功,則標記為已經被占用。
如果獲取鎖失敗,則調用 addWaiter 方法把線程包裝成 Node 對象,同時放入到隊列中,但 addWaiter 方法并不會嘗試獲取鎖,acquireQueued 方法才會嘗試獲取鎖,如果獲取失敗,則此節點會被掛起,源碼如下:
```
/**
* 隊列中的線程嘗試獲取鎖,失敗則會被掛起
*/
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true; // 獲取鎖是否成功的狀態標識
try {
boolean interrupted = false; // 線程是否被中斷
for (;;) {
// 獲取前一個節點(前驅節點)
final Node p = node.predecessor();
// 當前節點為頭節點的下一個節點時,有權嘗試獲取鎖
if (p == head && tryAcquire(arg)) {
setHead(node); // 獲取成功,將當前節點設置為 head 節點
p.next = null; // 原 head 節點出隊,等待被 GC
failed = false; // 獲取成功
return interrupted;
}
// 判斷獲取鎖失敗后是否可以掛起
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
// 線程若被中斷,返回 true
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
```
該方法會使用 for(;;) 無限循環的方式來嘗試獲取鎖,若獲取失敗,則調用 shouldParkAfterFailedAcquire 方法,嘗試掛起當前線程,源碼如下:
```
/**
* 判斷線程是否可以被掛起
*/
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 獲得前驅節點的狀態
int ws = pred.waitStatus;
// 前驅節點的狀態為 SIGNAL,當前線程可以被掛起(阻塞)
if (ws == Node.SIGNAL)
return true;
if (ws > 0) {
do {
// 若前驅節點狀態為 CANCELLED,那就一直往前找,直到找到一個正常等待的狀態為止
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
// 并將當前節點排在它后邊
pred.next = node;
} else {
// 把前驅節點的狀態修改為 SIGNAL
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
```
線程入列被掛起的前提條件是,前驅節點的狀態為 SIGNAL,SIGNAL 狀態的含義是后繼節點處于等待狀態,當前節點釋放鎖后將會喚醒后繼節點。所以在上面這段代碼中,會先判斷前驅節點的狀態,如果為 SIGNAL,則當前線程可以被掛起并返回 true;如果前驅節點的狀態 >0,則表示前驅節點取消了,這時候需要一直往前找,直到找到最近一個正常等待的前驅節點,然后把它作為自己的前驅節點;如果前驅節點正常(未取消),則修改前驅節點狀態為 SIGNAL。
到這里整個加鎖的流程就已經走完了,最后的情況是,沒有拿到鎖的線程會在隊列中被掛起,直到擁有鎖的線程釋放鎖之后,才會去喚醒其他的線程去獲取鎖資源,整個運行流程如下圖所示:
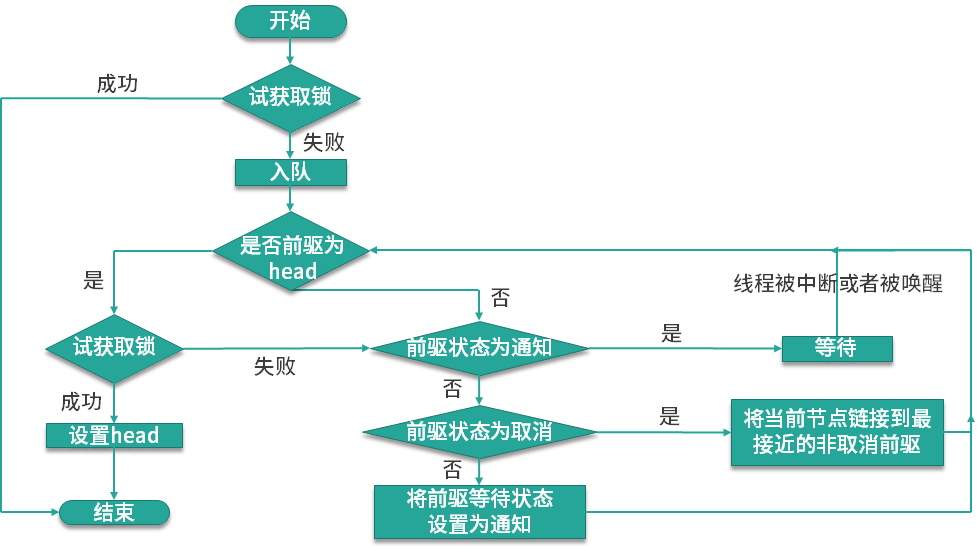
unlock 相比于 lock 來說就簡單很多了,源碼如下:
```
public void unlock() {
sync.release(1);
}
public final boolean release(int arg) {
// 嘗試釋放鎖
if (tryRelease(arg)) {
// 釋放成功
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
```
鎖的釋放流程為,先調用 tryRelease 方法嘗試釋放鎖,如果釋放成功,則查看頭結點的狀態是否為 SIGNAL,如果是,則喚醒頭結點的下個節點關聯的線程;如果釋放鎖失敗,則返回 false。
tryRelease 源碼如下:
```
/**
* 嘗試釋放當前線程占有的鎖
*/
protected final boolean tryRelease(int releases) {
int c = getState() - releases; // 釋放鎖后的狀態,0 表示釋放鎖成功
// 如果擁有鎖的線程不是當前線程的話拋出異常
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) { // 鎖被成功釋放
free = true;
setExclusiveOwnerThread(null); // 清空獨占線程
}
setState(c); // 更新 state 值,0 表示為釋放鎖成功
return free;
}
```
在 tryRelease 方法中,會先判斷當前的線程是不是占用鎖的線程,如果不是的話,則會拋出異常;如果是的話,則先計算鎖的狀態值 getState() - releases 是否為 0,如果為 0,則表示可以正常的釋放鎖,然后清空獨占的線程,最后會更新鎖的狀態并返回執行結果。
#### JDK 1.6 鎖優化
* [ ] 自適應自旋鎖
JDK 1.5 在升級為 JDK 1.6 時,HotSpot 虛擬機團隊在鎖的優化上下了很大功夫,比如實現了自適應式自旋鎖、鎖升級等。
JDK 1.6 引入了自適應式自旋鎖意味著自旋的時間不再是固定的時間了,比如在同一個鎖對象上,如果通過自旋等待成功獲取了鎖,那么虛擬機就會認為,它下一次很有可能也會成功 (通過自旋獲取到鎖),因此允許自旋等待的時間會相對的比較長,而當某個鎖通過自旋很少成功獲得過鎖,那么以后在獲取該鎖時,可能會直接忽略掉自旋的過程,以避免浪費 CPU 的資源,這就是自適應自旋鎖的功能。
* [ ] 鎖升級
鎖升級其實就是從偏向鎖到輕量級鎖再到重量級鎖升級的過程,這是 JDK 1.6 提供的優化功能,也稱之為鎖膨脹。
偏向鎖是指在無競爭的情況下設置的一種鎖狀態。偏向鎖的意思是它會偏向于第一個獲取它的線程,當鎖對象第一次被獲取到之后,會在此對象頭中設置標示為“01”,表示偏向鎖的模式,并且在對象頭中記錄此線程的 ID,這種情況下,如果是持有偏向鎖的線程每次在進入的話,不再進行任何同步操作,如 Locking、Unlocking 等,直到另一個線程嘗試獲取此鎖的時候,偏向鎖模式才會結束,偏向鎖可以提高帶有同步但無競爭的程序性能。但如果在多數鎖總會被不同的線程訪問時,偏向鎖模式就比較多余了,此時可以通過 -XX:-UseBiasedLocking 來禁用偏向鎖以提高性能。
輕量鎖是相對于重量鎖而言的,在 JDK 1.6 之前,synchronized 是通過操作系統的互斥量(mutex lock)來實現的,這種實現方式需要在用戶態和核心態之間做轉換,有很大的性能消耗,這種傳統實現鎖的方式被稱之為重量鎖。
而輕量鎖是通過比較并交換(CAS,Compare and Swap)來實現的,它對比的是線程和對象的 Mark Word(對象頭中的一個區域),如果更新成功則表示當前線程成功擁有此鎖;如果失敗,虛擬機會先檢查對象的 Mark Word 是否指向當前線程的棧幀,如果是,則說明當前線程已經擁有此鎖,否則,則說明此鎖已經被其他線程占用了。當兩個以上的線程爭搶此鎖時,輕量級鎖就膨脹為重量級鎖,這就是鎖升級的過程,也是 JDK 1.6 鎖優化的內容。
#### 小結
本課時首先講了 synchronized 和 ReentrantLock 的實現過程,然后講了 synchronized 和 ReentrantLock 的區別,最后通過源碼的方式講了 ReentrantLock 加鎖和解鎖的執行流程。接著又講了 JDK 1.6 中的鎖優化,包括自適應式自旋鎖的實現過程,以及 synchronized 的三種鎖狀態和鎖升級的執行流程。
synchronized 剛開始為偏向鎖,隨著鎖競爭越來越激烈,會升級為輕量級鎖和重量級鎖。如果大多數鎖被不同的線程所爭搶就不建議使用偏向鎖了。
#### 課后問答
* 1、在自適應自旋鎖中,“而當某個鎖通過自旋很少成功獲得過鎖”有點理解不了。請問磊哥 鎖獲得鎖是什么情況?
講師回復: 可以理解為通過不停的循環獲得了(CPU的)執行權
* 2、而公平鎖由于有掛起和恢復所以存在一定的開銷,因此性能不如非公平鎖。非公平鎖也有掛起和恢復吧。
講師回復: 可以看下第六課時哈,有相應的答案。
* 3、老師,請問自旋鎖的自旋是什么意思?發現好多專有名詞
講師回復: 就是自己循環獲取鎖的意思
* 4、synchronized沒有結合markword分析加鎖的過程!如何進行鎖的升級的?
講師回復: 內容有限,源碼沒貼,但升級的過程有文字描述,可以自行對照源碼看一下。
* 5、意思是如果偏向鎖被禁用,那后邊的競爭機制是輕量級鎖嗎?
編輯回復: 對,偏向到輕量到重量這個過程
* 9、為什么兩個以上線程競爭鎖的時候會升級為重量級鎖?java中哪些是重量級鎖,我理解的是CAS是類似自旋的,多個就耗費CPU了,重量級會進休眠狀態?
講師回復: 文中有寫,JDK 1.6 以后引入自適應自旋了
- 前言
- 開篇詞
- 開篇詞:大廠技術面試“潛規則”
- 模塊一:Java 基礎
- 第01講:String 的特點是什么?它有哪些重要的方法?
- 第02講:HashMap 底層實現原理是什么?JDK8 做了哪些優化?
- 第03講:線程的狀態有哪些?它是如何工作的?
- 第04講:詳解 ThreadPoolExecutor 的參數含義及源碼執行流程?
- 第05講:synchronized 和 ReentrantLock 的實現原理是什么?它們有什么區別?
- 第06講:談談你對鎖的理解?如何手動模擬一個死鎖?
- 第07講:深克隆和淺克隆有什么區別?它的實現方式有哪些?
- 第08講:動態代理是如何實現的?JDK Proxy 和 CGLib 有什么區別?
- 第09講:如何實現本地緩存和分布式緩存?
- 第10講:如何手寫一個消息隊列和延遲消息隊列?
- 模塊二:熱門框架
- 第11講:底層源碼分析 Spring 的核心功能和執行流程?(上)
- 第12講:底層源碼分析 Spring 的核心功能和執行流程?(下)
- 第13講:MyBatis 使用了哪些設計模式?在源碼中是如何體現的?
- 第14講:SpringBoot 有哪些優點?它和 Spring 有什么區別?
- 第15講:MQ 有什么作用?你都用過哪些 MQ 中間件?
- 模塊三:數據庫相關
- 第16講:MySQL 的運行機制是什么?它有哪些引擎?
- 第17講:MySQL 的優化方案有哪些?
- 第18講:關系型數據和文檔型數據庫有什么區別?
- 第19講:Redis 的過期策略和內存淘汰機制有什么區別?
- 第20講:Redis 怎樣實現的分布式鎖?
- 第21講:Redis 中如何實現的消息隊列?實現的方式有幾種?
- 第22講:Redis 是如何實現高可用的?
- 模塊四:Java 進階
- 第23講:說一下 JVM 的內存布局和運行原理?
- 第24講:垃圾回收算法有哪些?
- 第25講:你用過哪些垃圾回收器?它們有什么區別?
- 第26講:生產環境如何排除和優化 JVM?
- 第27講:單例的實現方式有幾種?它們有什么優缺點?
- 第28講:你知道哪些設計模式?分別對應的應用場景有哪些?
- 第29講:紅黑樹和平衡二叉樹有什么區別?
- 第30講:你知道哪些算法?講一下它的內部實現過程?
- 模塊五:加分項
- 第31講:如何保證接口的冪等性?常見的實現方案有哪些?
- 第32講:TCP 為什么需要三次握手?
- 第33講:Nginx 的負載均衡模式有哪些?它的實現原理是什么?
- 第34講:Docker 有什么優點?使用時需要注意什么問題?
- 彩蛋
- 彩蛋:如何提高面試成功率?