
說到 Java 虛擬機不得不提的一個詞就是 “垃圾回收”(GC,Garbage Collection),而垃圾回收的執行速度則影響著整個程序的執行效率,所以我們需要知道更多關于垃圾回收的具體執行細節,以便為我們選擇合適的垃圾回收器提供理論支持。
我們本課時的面試題是,如何判斷一個對象是否“死亡”?垃圾回收的算法有哪些?
#### 典型回答
垃圾回收器首先要做的就是,判斷一個對象是存活狀態還是死亡狀態,死亡的對象將會被標識為垃圾數據并等待收集器進行清除。
判斷一個對象是否為死亡狀態的常用算法有兩個:引用計數器算法和可達性分析算法。
引用計數算法(Reference Counting) 屬于垃圾收集器最早的實現算法了,它是指在創建對象時關聯一個與之相對應的計數器,當此對象被使用時加 1,相反銷毀時 -1。當此計數器為 0 時,則表示此對象未使用,可以被垃圾收集器回收。
引用計數算法的優缺點很明顯,其優點是垃圾回收比較及時,實時性比較高,只要對象計數器為 0,則可以直接進行回收操作;而缺點是無法解決循環引用的問題,比如以下代碼:
```
class CustomOne {
private CustomTwo two;
public CustomTwo getCustomTwo() {
return two;
}
public void setCustomTwo(CustomTwo two) {
this.two = two;
}
}
class CustomTwo {
private CustomOne one;
public CustomOne getCustomOne() {
return one;
}
public void setCustomOne(CustomOne one) {
this.one = one;
}
}
public class RefCountingTest {
public static void main(String[] args) {
CustomOne one = new CustomOne();
CustomTwo two = new CustomTwo();
one.setCustomTwo(two);
two.setCustomOne(one);
one = null;
two = null;
}
}
```
即使 one 和 two 都為 null,但因為循環引用的問題,兩個對象都不能被垃圾收集器所回收。
可達性分析算法(Reachability Analysis) 是目前商業系統中所采用的判斷對象死亡的常用算法,它是指從對象的起點(GC Roots)開始向下搜索,如果對象到 GC Roots 沒有任何引用鏈相連時,也就是說此對象到 GC Roots 不可達時,則表示此對象可以被垃圾回收器所回收,如下圖所示:
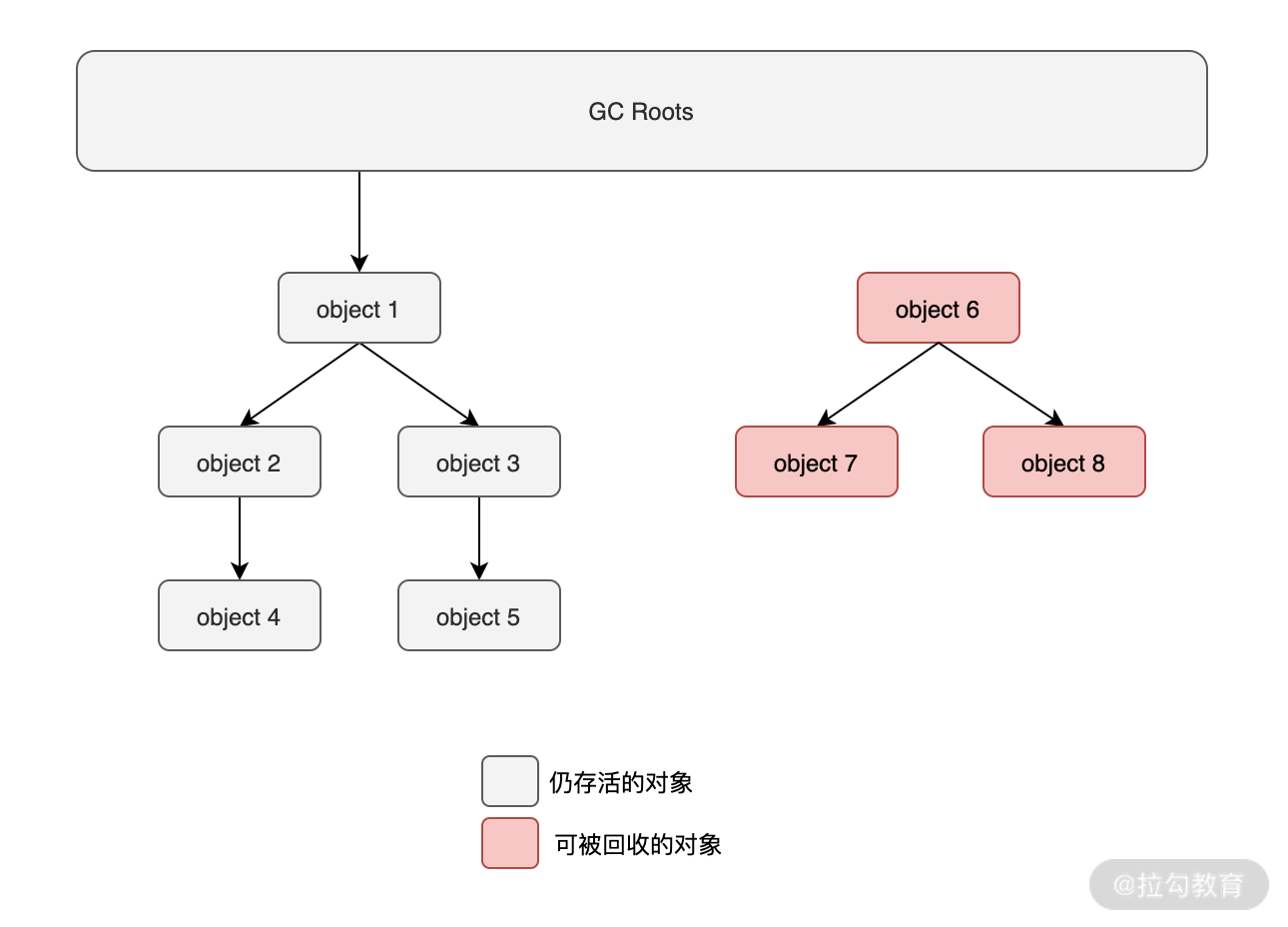
當確定了對象的狀態之后(存活還是死亡)接下來就是進行垃圾回收了,垃圾回收的常見算法有以下幾個:
* 標記-清除算法;
* 標記-復制算法;
*
標記-整理算法。
標記-清除(Mark-Sweep)算法屬于最早的垃圾回收算法,它是由標記階段和清除階段構成的。標記階段會給所有的存活對象做上標記,而清除階段會把沒有被標記的死亡對象進行回收。而標記的判斷方法就是前面講的引用計數算法和可達性分析算法。
標記-清除算法的執行流程如下圖所示:
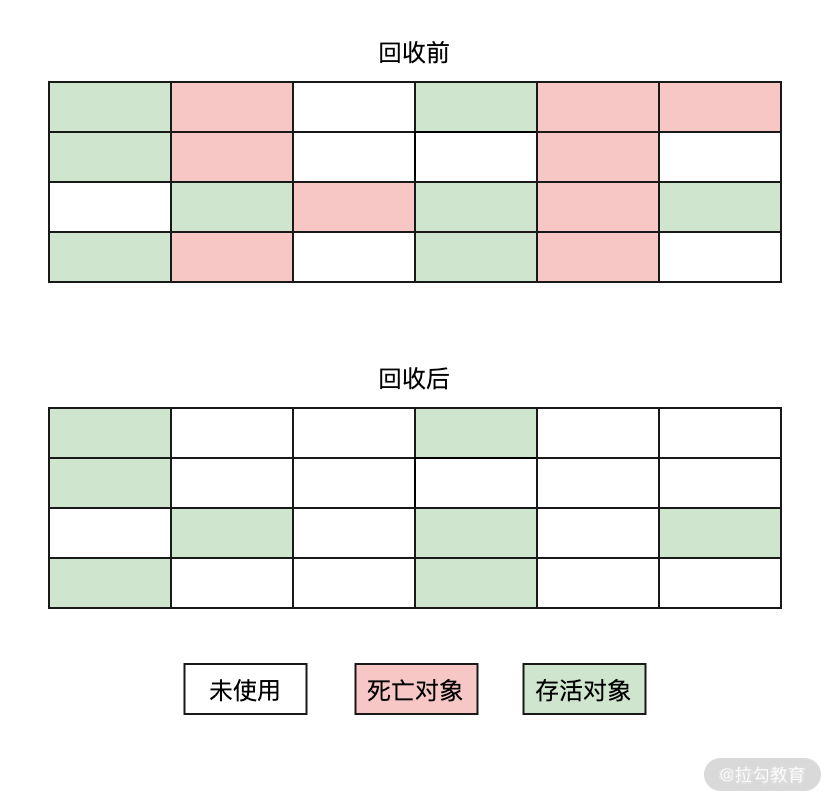
從上圖可以看出,標記-清除算法有一個最大的問題就是會產生內存空間的碎片化問題,也就是說標記-清除算法執行完成之后會產生大量的不連續內存,這樣當程序需要分配一個大對象時,因為沒有足夠的連續內存而導致需要提前觸發一次垃圾回收動作。
標記-復制算法是標記-清除算法的一個升級,使用它可以有效地解決內存碎片化的問題。它是指將內存分為大小相同的兩塊區域,每次只使用其中的一塊區域,這樣在進行垃圾回收時就可以直接將存活的東西復制到新的內存上,然后再把另一塊內存全部清理掉。這樣就不會產生內存碎片的問題了,其執行流程如下圖所示:
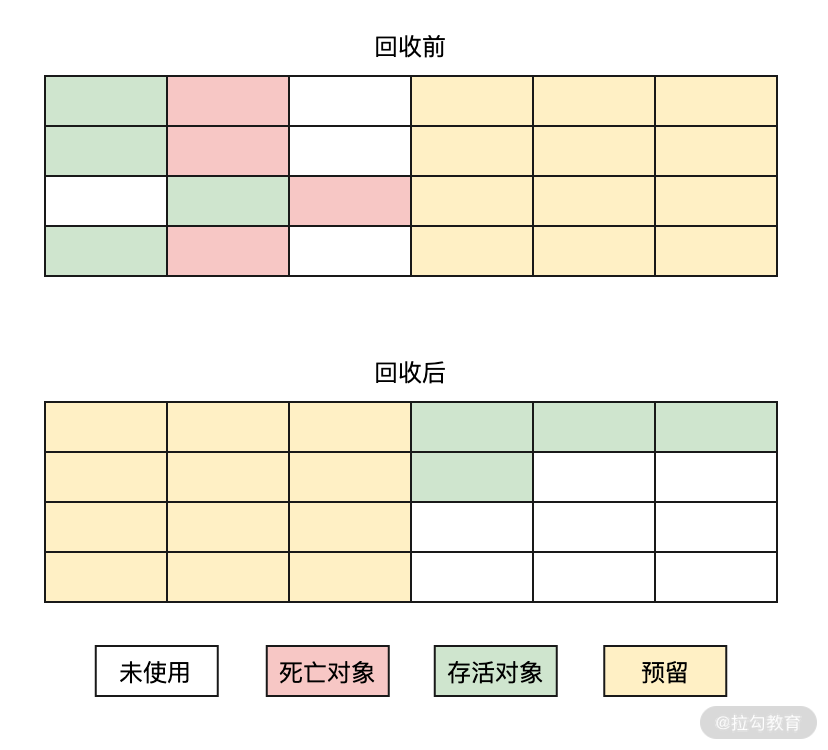
標記-復制的算法雖然可以解決內存碎片的問題,但同時也帶來了新的問題。因為需要將內存分為大小相同的兩塊內存,那么內存的實際可用量其實只有原來的一半,這樣此算法導致了內存的可用率大幅降低了。
標記-整理算法的誕生晚于標記-清除算法和標記-復制算法,它也是由兩個階段組成的:標記階段和整理階段。其中標記階段和標記-清除算法的標記階段一樣,不同的是后面的一個階段,標記-整理算法的后一個階段不是直接對內存進行清除,而是把所有存活的對象移動到內存的一端,然后把另一端的所有死亡對象全部清除,執行流程圖如下圖所示:
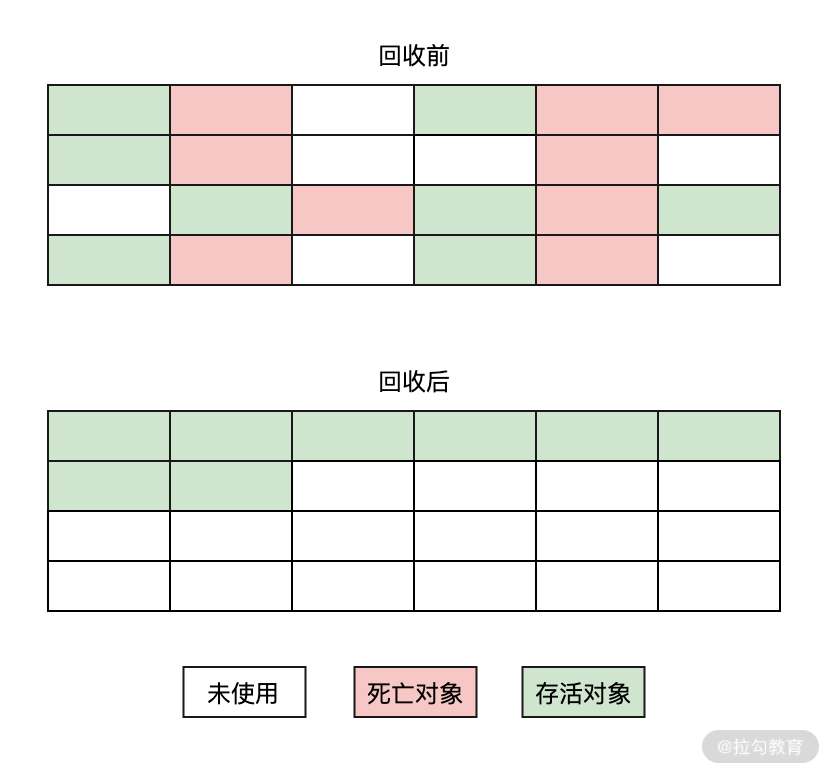
#### 考點分析
本題目考察的是關于垃圾收集的一些理論算法問題,都屬于概念性的問題,只要深入理解之后還是挺容易記憶的。和此知識點相關的面試題還有這些:
* Java 中可作為 GC Roots 的對象有哪些?
* 說一下死亡對象的判斷細節?
#### 知識擴展
* [ ] GC Roots
在 Java 中可以作為 GC Roots 的對象,主要包含以下幾個:
* 所有被同步鎖持有的對象,比如被 synchronize 持有的對象;
* 字符串常量池里的引用(String Table);
* 類型為引用類型的靜態變量;
* 虛擬機棧中引用對象;
* 本地方法棧中的引用對象。
* [ ] 死亡對象判斷
當使用可達性分析判斷一個對象不可達時,并不會直接標識這個對象為死亡狀態,而是先將它標記為“待死亡”狀態再進行一次校驗。校驗的內容就是此對象是否重寫了 finalize() 方法,如果該對象重寫了 finalize() 方法,那么這個對象將會被存入到 F-Queue 隊列中,等待 JVM 的 Finalizer 線程去執行重寫的 finalize() 方法,在這個方法中如果此對象將自己賦值給某個類變量時,則表示此對象已經被引用了。因此不能被標識為死亡狀態,其他情況則會被標識為死亡狀態。
以上流程對應的示例代碼如下:
```
public class FinalizeTest {
// 需要狀態判斷的對象
public static FinalizeTest Hook = null;
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("執行了 finalize 方法");
FinalizeTest.Hook = this;
}
public static void main(String[] args) throws InterruptedException {
Hook = new FinalizeTest();
// 卸載對象,第一次執行 finalize()
Hook = null;
System.gc();
Thread.sleep(500); // 等待 finalize() 執行
if (Hook != null) {
System.out.println("存活狀態");
} else {
System.out.println("死亡狀態");
}
// 卸載對象,與上一次代碼完全相同
Hook = null;
System.gc();
Thread.sleep(500); // 等待 finalize() 執行
if (Hook != null) {
System.out.println("存活狀態");
} else {
System.out.println("死亡狀態");
}
}
}
```
上述代碼的執行結果為:
```
執行了 finalize 方法
存活狀態
死亡狀態
```
從結果可以看出,卸載了兩次對象,第一次執行了 finalize() 方法,成功地把自己從待死亡狀態拉了回來;而第二次同樣的代碼卻沒有執行 finalize() 方法,從而被確認為了死亡狀態,這是因為任何對象的 finalize() 方法都只會被系統調用一次。
雖然可以從 finalize() 方法中把自己從死亡狀態“拯救”出來,但是不建議這樣做,因為所有對象的 finalize() 方法只會執行一次。因此同樣的代碼可能產生的結果是不同的,這樣就給程序的執行帶來了很大的不確定性。
#### 小結
本課時講了對象狀態判斷的兩種算法:引用計數算法和可達性分析算法。其中引用計數算法無法解決循環引用的問題,因此對于絕大多數的商業系統來說使用的都是可達性分析算法;同時還講了垃圾回收的三種算法:標記-清除算法、標記-復制算法、標記-整理算法,其中,標記-清除算法會帶來內存碎片的問題,而標記-復制算法會降低內存的利用率。所以,標記-整理算法算是一個不錯的方案。
#### 課后問答
* 1、這個文檔是不是有點問題?上面說的GC roots,在知識擴展,哪些可以作為GC roots對象時,卻是CG root
講師回復: 檢查了,文稿寫的是 GC Roots
* 2、GC Roots 的對象: 字符串常量池里的引用 這個怎么理解?字符串常量池不都是一些字符串常量嗎?垃圾回收算法 為什么沒有講到 分代垃圾回收算法呢?
編輯回復: Java 中有兩個不常用的概念——字面量和符號引用,可以配合其他資料看看哈。本專欄會講一些比較常見的知識點,但整個 Java 體系還有很多的內容,可以配合其他資料一起看哦。
* 3、講師你好,1、怎樣判斷對象到 GC Roots 沒有任何引用鏈相連呢?在代碼中是怎樣體現呢?2、垃圾回收的·fullGc是否是判斷沒有相連后才進行回收,而Mingor GC只是用來標記GC的次數嗎?還是?3、強弱軟虛四種引用在分別是怎樣判斷和GC Roots判斷沒有任何相連的呢?困擾了很多,但是看書沒看懂,期待回復
講師回復: 目前主流的虛擬機都是采用 GC Roots Tracing 的算法來實現跟引用查找的,該算法的核心算法是從 GC Roots 對象作為起始點,利用數學中圖論知識,圖中可達對象便是存活對象,而不可達對象則是需要回收的垃圾內存,這個不做 JVM 開發建議了解就可以了。 垃圾回收要看具體的垃圾回收器,可以看下 25 課時回收的執行流程,那個里面有答案哦。
- 前言
- 開篇詞
- 開篇詞:大廠技術面試“潛規則”
- 模塊一:Java 基礎
- 第01講:String 的特點是什么?它有哪些重要的方法?
- 第02講:HashMap 底層實現原理是什么?JDK8 做了哪些優化?
- 第03講:線程的狀態有哪些?它是如何工作的?
- 第04講:詳解 ThreadPoolExecutor 的參數含義及源碼執行流程?
- 第05講:synchronized 和 ReentrantLock 的實現原理是什么?它們有什么區別?
- 第06講:談談你對鎖的理解?如何手動模擬一個死鎖?
- 第07講:深克隆和淺克隆有什么區別?它的實現方式有哪些?
- 第08講:動態代理是如何實現的?JDK Proxy 和 CGLib 有什么區別?
- 第09講:如何實現本地緩存和分布式緩存?
- 第10講:如何手寫一個消息隊列和延遲消息隊列?
- 模塊二:熱門框架
- 第11講:底層源碼分析 Spring 的核心功能和執行流程?(上)
- 第12講:底層源碼分析 Spring 的核心功能和執行流程?(下)
- 第13講:MyBatis 使用了哪些設計模式?在源碼中是如何體現的?
- 第14講:SpringBoot 有哪些優點?它和 Spring 有什么區別?
- 第15講:MQ 有什么作用?你都用過哪些 MQ 中間件?
- 模塊三:數據庫相關
- 第16講:MySQL 的運行機制是什么?它有哪些引擎?
- 第17講:MySQL 的優化方案有哪些?
- 第18講:關系型數據和文檔型數據庫有什么區別?
- 第19講:Redis 的過期策略和內存淘汰機制有什么區別?
- 第20講:Redis 怎樣實現的分布式鎖?
- 第21講:Redis 中如何實現的消息隊列?實現的方式有幾種?
- 第22講:Redis 是如何實現高可用的?
- 模塊四:Java 進階
- 第23講:說一下 JVM 的內存布局和運行原理?
- 第24講:垃圾回收算法有哪些?
- 第25講:你用過哪些垃圾回收器?它們有什么區別?
- 第26講:生產環境如何排除和優化 JVM?
- 第27講:單例的實現方式有幾種?它們有什么優缺點?
- 第28講:你知道哪些設計模式?分別對應的應用場景有哪些?
- 第29講:紅黑樹和平衡二叉樹有什么區別?
- 第30講:你知道哪些算法?講一下它的內部實現過程?
- 模塊五:加分項
- 第31講:如何保證接口的冪等性?常見的實現方案有哪些?
- 第32講:TCP 為什么需要三次握手?
- 第33講:Nginx 的負載均衡模式有哪些?它的實現原理是什么?
- 第34講:Docker 有什么優點?使用時需要注意什么問題?
- 彩蛋
- 彩蛋:如何提高面試成功率?