
性能優化(Optimize)指的是在保證系統正確性的前提下,能夠更快速響應請求的一種手段。而且有些性能問題,比如慢查詢等,如果積累到一定的程度或者是遇到急速上升的并發請求之后,會導致嚴重的后果,輕則造成服務繁忙,重則導致應用不可用。它對我們來說就像一顆即將被引爆的定時炸彈一樣,時刻威脅著我們。因此在上線項目之前需要嚴格的把關,以確保 MySQL 能夠以最優的狀態進行運行。同時,在實際工作中還有面試中關于 MySQL 優化的知識點,都是面試官考察的重點內容。
我們本課時的面試題是,MySQL 的優化方案有哪些?
#### 典型回答
MySQL 數據庫常見的優化手段分為三個層面:SQL 和索引優化、數據庫結構優化、系統硬件優化等,然而每個大的方向中又包含多個小的優化點,下面我們具體來看看。
* [ ] 1.SQL 和索引優化
此優化方案指的是通過優化 SQL 語句以及索引來提高 MySQL 數據庫的運行效率,具體內容如下。
* ① 使用正確的索引
索引是數據庫中最重要的概念之一,也是提高數據庫性能最有效的手段之一,它的誕生本身就是為了提高數據查詢效率的,就像字典的目錄一樣,通過目錄可以很快找到相關的內容,如下圖所示:


假如我們沒有添加索引,那么在查詢時就會觸發全表掃描,因此查詢的數據就會很多,并且查詢效率會很低,為了提高查詢的性能,我們就需要給最常使用的查詢字段上,添加相應的索引,這樣才能提高查詢的性能。
> 小貼士:我們應該盡可能的使用主鍵查詢,而非其他索引查詢,因為主鍵查詢不會觸發回表查詢,因此節省了一部分時間,變相的提高了查詢的性能。
在 MySQL 5.0 之前的版本要盡量避免使用 or 查詢,可以使用 union 或者子查詢來替代,因為早期的 MySQL 版本使用 or 查詢可能會導致索引失效,在 MySQL 5.0 之后的版本中引入了索引合并,簡單來說就是把多條件查詢,比如 or 或 and 查詢的結果集進行合并交集或并集的功能,因此就不會導致索引失效的問題了。
避免在 where 查詢條件中使用 != 或者 <> 操作符,因為這些操作符會導致查詢引擎放棄索引而進行全表掃描。
適當使用前綴索引,MySQL 是支持前綴索引的,也就是說我們可以定義字符串的一部分來作為索引。我們知道索引越長占用的磁盤空間就越大,那么在相同數據頁中能放下的索引值也就越少,這就意味著搜索索引需要的查詢時間也就越長,進而查詢的效率就會降低,所以我們可以適當的選擇使用前綴索引,以減少空間的占用和提高查詢效率。比如,郵箱的后綴都是固定的“@xxx.com”,那么類似這種后面幾位為固定值的字段就非常適合定義為前綴索引。
* ② 查詢具體的字段而非全部字段
要盡量避免使用 select *,而是查詢需要的字段,這樣可以提升速度,以及減少網絡傳輸的帶寬壓力。
* ③ 優化子查詢
盡量使用 Join 語句來替代子查詢,因為子查詢是嵌套查詢,而嵌套查詢會新創建一張臨時表,而臨時表的創建與銷毀會占用一定的系統資源以及花費一定的時間,但 Join 語句并不會創建臨時表,因此性能會更高。
* ④ 注意查詢結果集
我們要盡量使用小表驅動大表的方式進行查詢,也就是如果 B 表的數據小于 A 表的數據,那執行的順序就是先查 B 表再查 A 表,具體查詢語句如下:
```
select name from A where id in (select id from B);
```
* ⑤ 不要在列上進行運算操作
不要在列字段上進行算術運算或其他表達式運算,否則可能會導致查詢引擎無法正確使用索引,從而影響了查詢的效率。
* ⑥ 適當增加冗余字段
增加冗余字段可以減少大量的連表查詢,因為多張表的連表查詢性能很低,所有可以適當的增加冗余字段,以減少多張表的關聯查詢,這是以空間換時間的優化策略。
* [ ] 2.數據庫結構優化
* ① 最小數據長度
一般說來數據庫的表越小,那么它的查詢速度就越快,因此為了提高表的效率,應該將表的字段設置的盡可能小,比如身份證號,可以設置為 char(18) 就不要設置為 varchar(18)。
* ② 使用最簡單數據類型
能使用 int 類型就不要使用 varchar 類型,因為 int 類型比 varchar 類型的查詢效率更高。
* ③ 盡量少定義 text 類型
text 類型的查詢效率很低,如果必須要使用 text 定義字段,可以把此字段分離成子表,需要查詢此字段時使用聯合查詢,這樣可以提高主表的查詢效率。
* ④ 適當分表、分庫策略
分表和分庫方案也是我們經常說的垂直分隔(分表)和水平分隔(分庫)。
分表是指當一張表中的字段更多時,可以嘗試將一張大表拆分為多張子表,把使用比較高頻的主信息放入主表中,其他的放入子表,這樣我們大部分查詢只需要查詢字段更少的主表就可以完成了,從而有效的提高了查詢的效率。
分庫是指將一個數據庫分為多個數據庫。比如我們把一個數據庫拆分為了多個數據庫,一個主數據庫用于寫入和修改數據,其他的用于同步主數據并提供給客戶端查詢,這樣就把一個庫的讀和寫的壓力,分攤給了多個庫,從而提高了數據庫整體的運行效率。
* [ ] 3.硬件優化
MySQL 對硬件的要求主要體現在三個方面:磁盤、網絡和內存。
* ① 磁盤
磁盤應該盡量使用有高性能讀寫能力的磁盤,比如固態硬盤,這樣就可以減少 I/O 運行的時間,從而提高了 MySQL 整體的運行效率。
磁盤也可以盡量使用多個小磁盤而不是一個大磁盤,因為磁盤的轉速是固定的,有多個小磁盤就相當于擁有多個并行運行的磁盤一樣。
* ② 網絡
保證網絡帶寬的通暢(低延遲)以及夠大的網絡帶寬是 MySQL 正常運行的基本條件,如果條件允許的話也可以設置多個網卡,以提高網絡高峰期 MySQL 服務器的運行效率。
* ③ 內存
MySQL 服務器的內存越大,那么存儲和緩存的信息也就越多,而內存的性能是非常高的,從而提高了整個 MySQL 的運行效率。
#### 考點分析
MySQL 性能優化的方案很多,因此它可以全面考察的一個程序員的經驗是否豐富。當然這個問題的回答也是可深可淺,不同的崗位對此問題的答案要求也是不同的,這個問題也可以引申出更多的面試問題,比如:
* 聯合索引需要注意什么問題?
* 如何排查慢查詢?
#### 知識擴展
* [ ] 正確使用聯合索引
使用了 B+ 樹的 MySQL 數據庫引擎,比如 InnoDB 引擎,在每次查詢復合字段時是從左往右匹配數據的,因此在創建聯合索引的時候需要注意索引創建的順序。例如,我們創建了一個聯合索引是 idx(name,age,sex),那么當我們使用,姓名+年齡+性別、姓名+年齡、姓名等這種最左前綴查詢條件時,就會觸發聯合索引進行查詢;然而如果非最左匹配的查詢條件,例如,性別+姓名這種查詢條件就不會觸發聯合索引。
當然,當我們已經有了(name,age)這個聯合索引之后,一般情況下就不需要在 name 字段單獨創建索引了,這樣就可以少維護一個索引。
* [ ] 慢查詢
慢查詢通常的排查手段是先使用慢查詢日志功能,查詢出比較慢的 SQL 語句,然后再通過 explain 來查詢 SQL 語句的執行計劃,最后分析并定位出問題的根源,再進行處理。
慢查詢日志指的是在 MySQL 中可以通過配置來開啟慢查詢日志的記錄功能,超過 long_query_time 值的 SQL 將會被記錄在日志中。我們可以通過設置“slow_query_log=1”來開啟慢查詢,它的開啟方式有兩種:
* 通過 MySQL 命令行的模式進行開啟,只需要執行“set global slow_query_log=1”即可,然而這種配置模式再重啟 MySQL 服務之后就會失效;
* 另一種方式可通過修改 MySQL 配置文件的方式進行開啟,我們需要配置 my.cnf 中的“slow_query_log=1”即可,并且可以通過設置“slow_query_log_file=/tmp/mysql_slow.log”來配置慢查詢日志的存儲目錄,但這種方式配置完成之后需要重啟 MySQL 服務器才可生效。
需要注意的是,在開啟慢日志功能之后,會對 MySQL 的性能造成一定的影響,因此在生產環境中要慎用此功能。
explain 執行計劃的使用示例 SQL 如下:
```
explain select * from person where uname = 'Java';
```
它的執行結果如下圖所示:

摘要說明如下表所示:
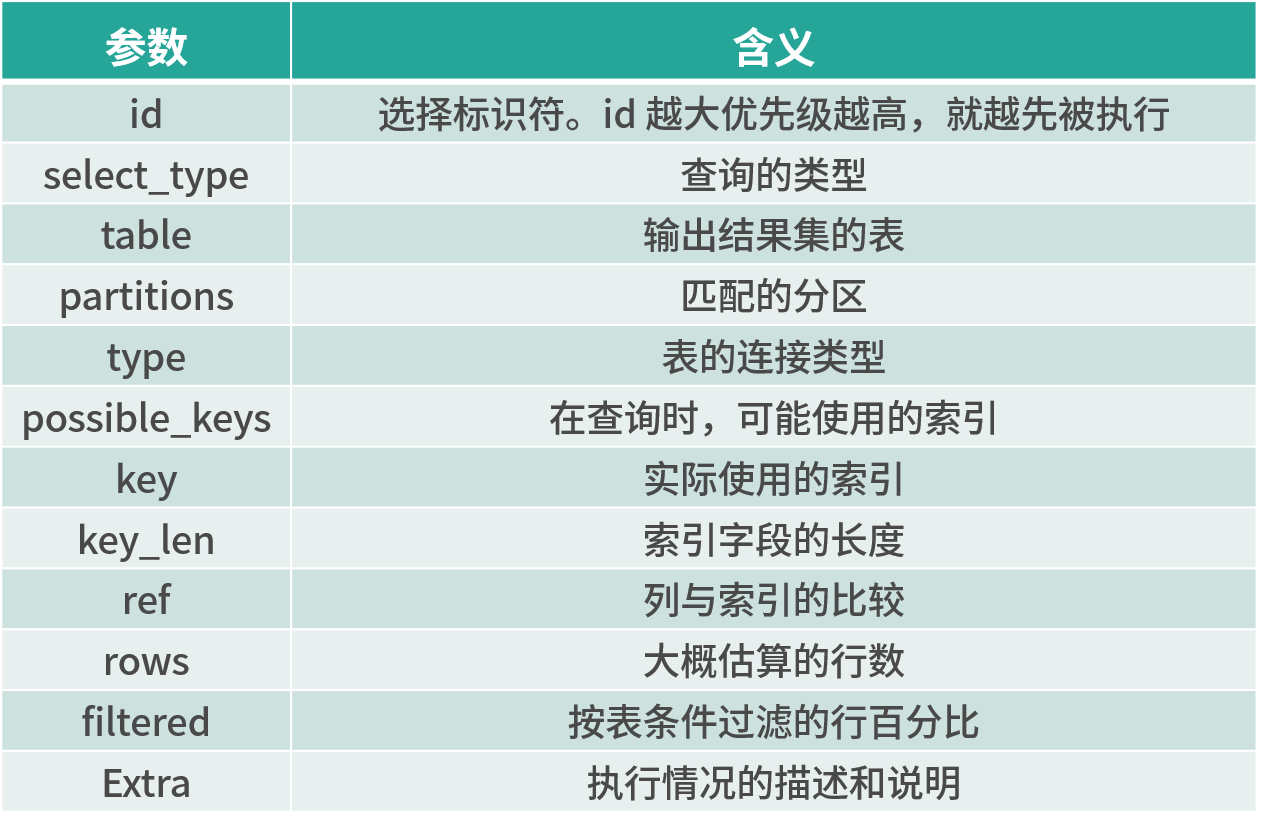
以上字段中最重要的就是 type 字段,它的所有值如下所示:
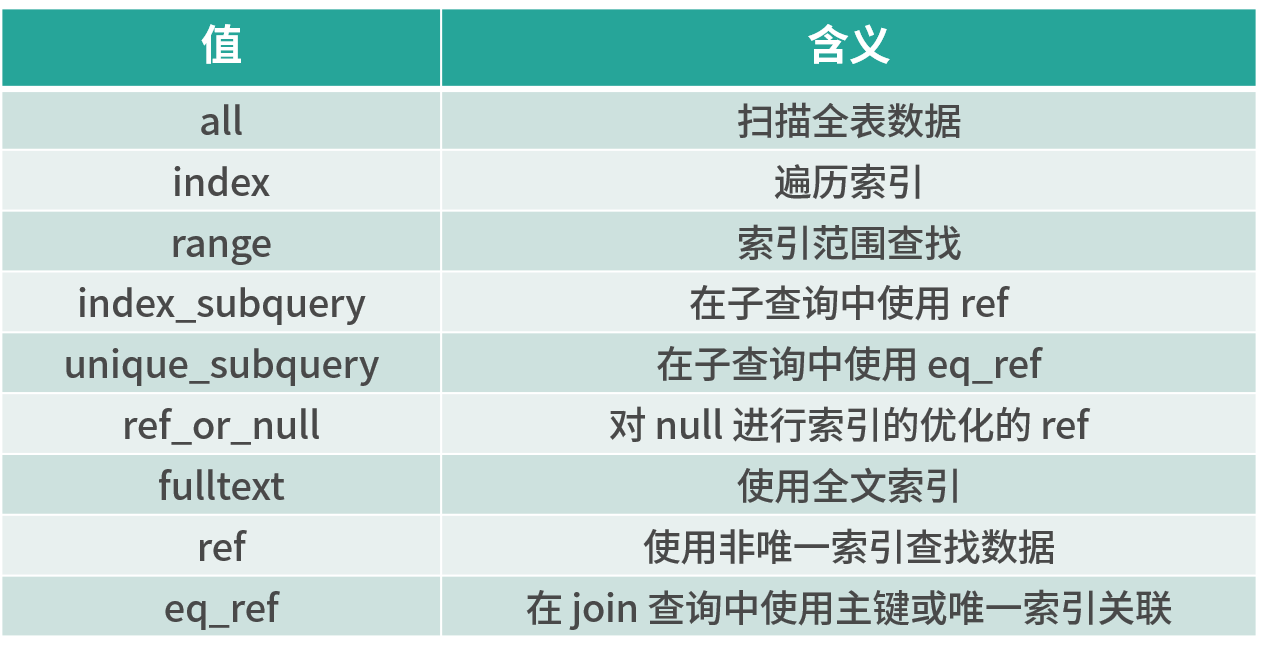
當 type 為 all 時,則表示全表掃描,因此效率會比較低,此時需要查看一下為什么會造成此種原因,是沒有創建索引還是索引創建的有問題?以此來優化整個 MySQL 運行的速度。
#### 小結
本課時我們從三個維度講了 MySQL 的優化手段:SQL 和索引優化、數據庫結構優化以及系統硬件優化等;同時深入到每個維度中,詳細地介紹了 MySQL 具體的優化細節;最后我們講了聯合索引的最左匹配原則,以及慢查詢的具體解決方案。
- 前言
- 開篇詞
- 開篇詞:大廠技術面試“潛規則”
- 模塊一:Java 基礎
- 第01講:String 的特點是什么?它有哪些重要的方法?
- 第02講:HashMap 底層實現原理是什么?JDK8 做了哪些優化?
- 第03講:線程的狀態有哪些?它是如何工作的?
- 第04講:詳解 ThreadPoolExecutor 的參數含義及源碼執行流程?
- 第05講:synchronized 和 ReentrantLock 的實現原理是什么?它們有什么區別?
- 第06講:談談你對鎖的理解?如何手動模擬一個死鎖?
- 第07講:深克隆和淺克隆有什么區別?它的實現方式有哪些?
- 第08講:動態代理是如何實現的?JDK Proxy 和 CGLib 有什么區別?
- 第09講:如何實現本地緩存和分布式緩存?
- 第10講:如何手寫一個消息隊列和延遲消息隊列?
- 模塊二:熱門框架
- 第11講:底層源碼分析 Spring 的核心功能和執行流程?(上)
- 第12講:底層源碼分析 Spring 的核心功能和執行流程?(下)
- 第13講:MyBatis 使用了哪些設計模式?在源碼中是如何體現的?
- 第14講:SpringBoot 有哪些優點?它和 Spring 有什么區別?
- 第15講:MQ 有什么作用?你都用過哪些 MQ 中間件?
- 模塊三:數據庫相關
- 第16講:MySQL 的運行機制是什么?它有哪些引擎?
- 第17講:MySQL 的優化方案有哪些?
- 第18講:關系型數據和文檔型數據庫有什么區別?
- 第19講:Redis 的過期策略和內存淘汰機制有什么區別?
- 第20講:Redis 怎樣實現的分布式鎖?
- 第21講:Redis 中如何實現的消息隊列?實現的方式有幾種?
- 第22講:Redis 是如何實現高可用的?
- 模塊四:Java 進階
- 第23講:說一下 JVM 的內存布局和運行原理?
- 第24講:垃圾回收算法有哪些?
- 第25講:你用過哪些垃圾回收器?它們有什么區別?
- 第26講:生產環境如何排除和優化 JVM?
- 第27講:單例的實現方式有幾種?它們有什么優缺點?
- 第28講:你知道哪些設計模式?分別對應的應用場景有哪些?
- 第29講:紅黑樹和平衡二叉樹有什么區別?
- 第30講:你知道哪些算法?講一下它的內部實現過程?
- 模塊五:加分項
- 第31講:如何保證接口的冪等性?常見的實現方案有哪些?
- 第32講:TCP 為什么需要三次握手?
- 第33講:Nginx 的負載均衡模式有哪些?它的實現原理是什么?
- 第34講:Docker 有什么優點?使用時需要注意什么問題?
- 彩蛋
- 彩蛋:如何提高面試成功率?