
高可用是通過設計,減少系統不能提供服務的時間,是分布式系統的基礎也是保障系統可靠性的重要手段。而 Redis 作為一款普及率最高的內存型中間件,它的高可用技術也非常的成熟。
我們本課時的面試題是,Redis 是如何保證系統高可用的?它的實現方式有哪些?
#### 典型回答
Redis 高可用的手段主要有以下四種:
* 數據持久化
* 主從數據同步(主從復制)
* Redis 哨兵模式(Sentinel)
* Redis 集群(Cluster)
其中數據持久化保證了系統在發生宕機或者重啟之后數據不會丟失,增加了系統的可靠性和減少了系統不可用的時間(省去了手動恢復數據的過程);而主從數據同步可以將數據存儲至多臺服務器,這樣當遇到一臺服務器宕機之后,可以很快地切換至另一臺服務器以繼續提供服務;哨兵模式用于發生故障之后自動切換服務器;而 Redis 集群提供了多主多從的 Redis 分布式集群環境,用于提供性能更好的 Redis 服務,并且它自身擁有故障自動切換的能力。
#### 考點分析
高可用的問題屬于 Redis 中比較大的面試題了,因為很多知識點都和這個面試題有關,同時也屬于比較難的面試題了。因為涉及了分布式集群,而分布式集群屬于 Redis 中比較難懂的一個知識點。和此問題相關的面試題還有以下幾個:
* 數據持久化有幾種方式?
* Redis 主從同步有幾種模式?
* 什么是 Redis 哨兵模式?它解決了什么問題?
* Redis 集群的優勢是什么?
#### 知識擴展
* [ ] 1.數據持久化
持久化功能是 Redis 和 Memcached 的主要區別之一,因為只有 Redis 提供了此功能。
在 Redis 4.0 之前數據持久化方式有兩種:AOF 方式和 RDB 方式。
* RDB(Redis DataBase,快照方式)是將某一個時刻的內存數據,以二進制的方式寫入磁盤。
* AOF(Append Only File,文件追加方式)是指將所有的操作命令,以文本的形式追加到文件中。
RDB 默認的保存文件為 dump.rdb,優點是以二進制存儲的,因此占用的空間更小、數據存儲更緊湊,并且與 AOF 相比,RDB 具備更快的重啟恢復能力。
AOF 默認的保存文件為 appendonly.aof,它的優點是存儲頻率更高,因此丟失數據的風險就越低,并且 AOF 并不是以二進制存儲的,所以它的存儲信息更易懂。缺點是占用空間大,重啟之后的數據恢復速度比較慢。
可以看出 RDB 和 AOF 各有利弊,RDB 具備更快速的數據重啟恢復能力,并且占用更小的磁盤空間,但有數據丟失的風險;而 AOF 文件的可讀性更高,但卻占用了更大的空間,且重啟之后的恢復速度更慢,于是在 Redis 4.0 就推出了混合持久化的功能。
混合持久化的功能指的是 Redis 可以使用 RDB + AOF 兩種格式來進行數據持久化,這樣就可以做到揚長避短物盡其用了,混合持久化的存儲示意圖如下圖所示:

我們可以使用“config get aof-use-rdb-preamble”的命令來查詢 Redis 混合持久化的功能是否開啟,執行示例如下:
```
127.0.0.1:6379> config get aof-use-rdb-preamble
1) "aof-use-rdb-preamble"
2) "yes"
```
如果執行結果為“no”則表示混合持久化功能關閉,不過我們可以使用“config set aof-use-rdb-preamble yes”的命令打開此功能。
Redis 混合持久化的存儲模式是,開始的數據以 RDB 的格式進行存儲,因此只會占用少量的空間,并且之后的命令會以 AOF 的方式進行數據追加,這樣就可以減低數據丟失的風險,同時可以提高數據恢復的速度。
* [ ] 2.Redis 主從同步
主從同步是 Redis 多機運行中最基礎的功能,它是把多個 Redis 節點組成一個 Redis 集群,在這個集群當中有一個主節點用來進行數據的操作,其他從節點用于同步主節點的內容,并且提供給客戶端進行數據查詢。
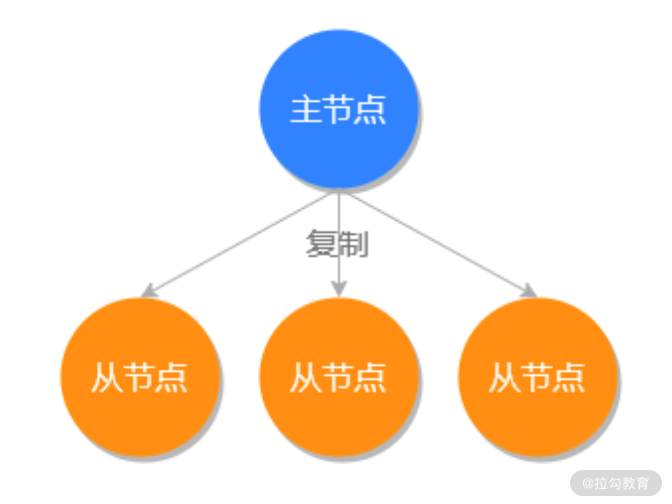
Redis 主從同步分為:主從模式和從從模式。主從模式就是一個主節點和多個一級從節點,如下圖所示:
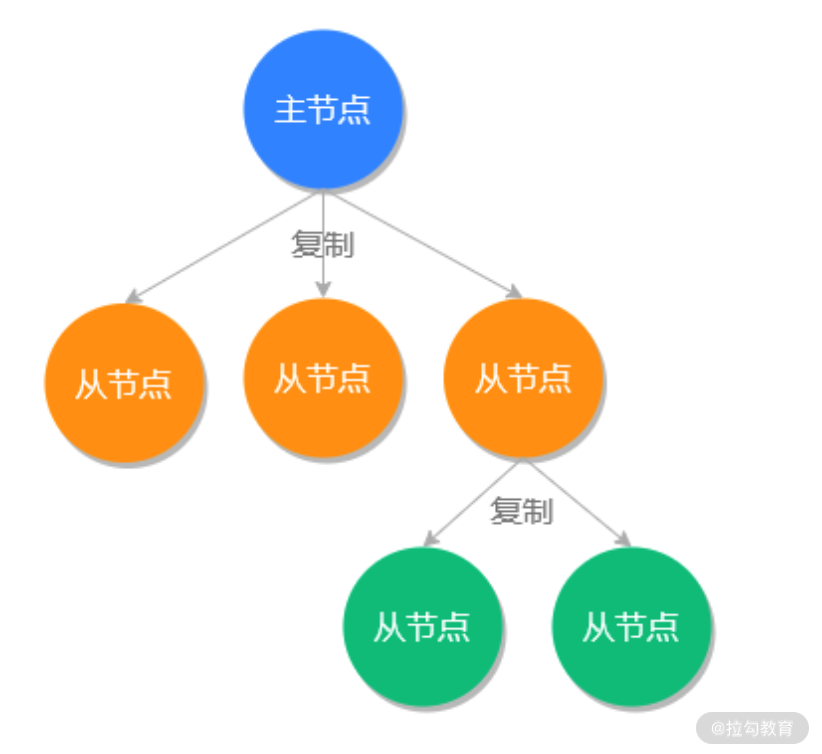
而從從模式是指一級從節點下面還可以擁有更多的從節點,如下圖所示:
主從模式可以提高 Redis 的整體運行速度,因為使用主從模式就可以實現數據的讀寫分離,把寫操作的請求分發到主節點上,把其他的讀操作請求分發到從節點上,這樣就減輕了 Redis 主節點的運行壓力,并且提高了 Redis 的整體運行速度。
不但如此使用主從模式還實現了 Redis 的高可用,當主服務器宕機之后,可以很迅速的把從節點提升為主節點,為 Redis 服務器的宕機恢復節省了寶貴的時間。
并且主從復制還降低了數據丟失的風險,因為數據是完整拷貝在多臺服務器上的,當一個服務器磁盤壞掉之后,可以從其他服務器拿到完整的備份數據。
* [ ] 3.Redis 哨兵模式
Redis 主從復制模式有那么多的優點,但是有一個致命的缺點,就是當 Redis 的主節點宕機之后,必須人工介入手動恢復,那么到特殊時間段,比如公司組織全體團建或者半夜突然發生主節點宕機的問題,此時如果等待人工去處理就會很慢,這個時間是我們不允許的,并且我們還需要招聘專職的人來負責數據恢復的事,同時招聘的人還需要懂得相關的技術才能勝任這份工作。既然如此的麻煩,那有沒有簡單一點的解決方案,這個時候我們就需要用到 Redis 的哨兵模式了。
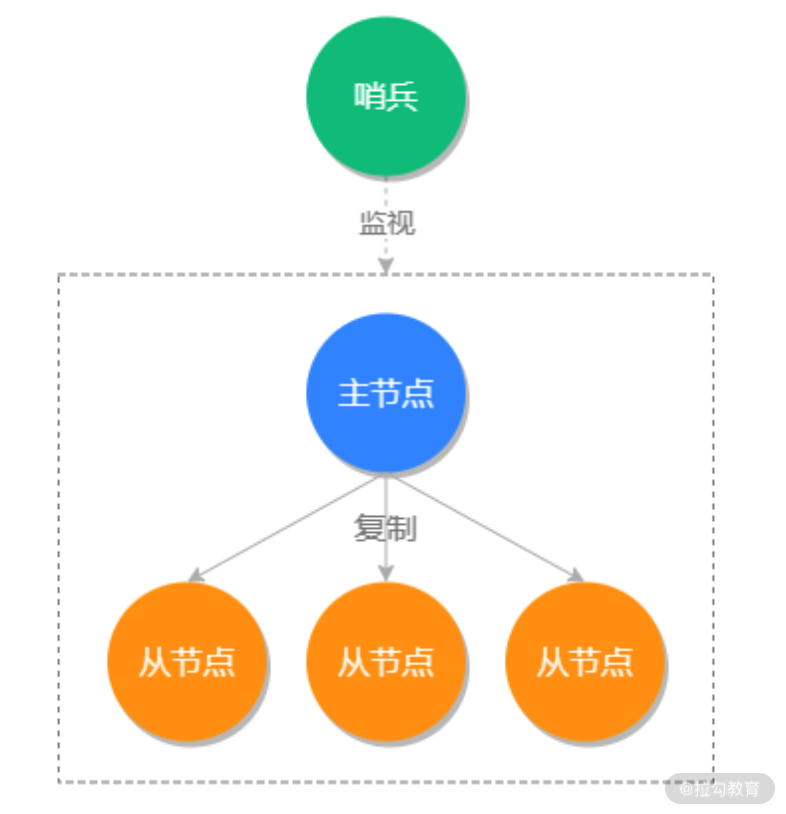
Redis 哨兵模式就是用來監視 Redis 主從服務器的,當 Redis 的主從服務器發生故障之后,Redis 哨兵提供了自動容災修復的功能,如下圖所示:
Redis 哨兵模塊存儲在 Redis 的 src/redis-sentinel 目錄下,如下圖所示:
我們可以使用命令“./src/redis-sentinel sentinel.conf”來啟動哨兵功能。
有了哨兵功能之后,就再也不怕 Redis 主從服務器宕機了。哨兵的工作原理是每個哨兵會以每秒鐘 1 次的頻率,向已知的主服務器和從服務器,發送一個 PING 命令。如果最后一次有效回復 PING 命令的時間,超過了配置的最大下線時間(Down-After-Milliseconds)時,默認是 30s,那么這個實例會被哨兵標記為主觀下線。
如果一個主服務器被標記為主觀下線,那么正在監視這個主服務器的所有哨兵節點,要以每秒 1 次的頻率確認主服務器是否進入了主觀下線的狀態。如果有足夠數量(quorum 配置值)的哨兵證實該主服務器為主觀下線,那么這個主服務器被標記為客觀下線。此時所有的哨兵會按照規則(協商)自動選出新的主節點服務器,并自動完成主服務器的自動切換功能,而整個過程都是無須人工干預的。
* [ ] 4.Redis 集群
Redis 集群也就是 Redis Cluster,它是 Redis 3.0 版本推出的 Redis 集群方案,將數據分布在不同的主服務器上,以此來降低系統對單主節點的依賴,并且可以大大提高 Redis 服務的讀寫性能。Redis 集群除了擁有主從模式 + 哨兵模式的所有功能之外,還提供了多個主從節點的集群功能,實現了真正意義上的分布式集群服務,如下圖所示:
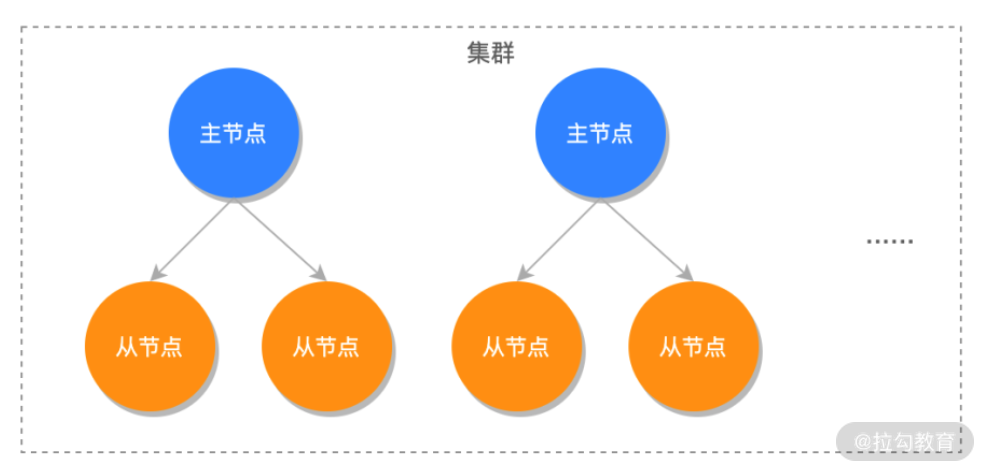
Redis 集群可以實現數據分片服務,也就是說在 Redis 集群中有 16384 個槽位用來存儲所有的數據,當我們有 N 個主節點時,可以把 16384 個槽位平均分配到 N 臺主服務器上。當有鍵值存儲時,Redis 會使用 crc16 算法進行 hash 得到一個整數值,然后用這個整數值對 16384 進行取模來得到具體槽位,再把此鍵值存儲在對應的服務器上,讀取操作也是同樣的道理,這樣我們就實現了數據分片的功能。
#### 小結
本課時我們講了保障 Redis 高可用的 4 種手段:數據持久化保證了數據不丟失;Redis 主從讓 Redis 從單機變成了多機。它有兩種模式:主從模式和從從模式,但當主節點出現問題時,需要人工手動恢復系統;Redis 哨兵模式用來監控 Redis 主從模式,并提供了自動容災恢復的功能。最后是 Redis 集群,除了可以提供主從和哨兵的功能之外,還提供了多個主從節點的集群功能,這樣就可以把數據均勻的存儲各個主機主節點上,實現了系統的橫向擴展,大大提高了 Redis 的并發處理能力。
#### 課后問答
* 1、開始的數據以 RDB 的格式進行存儲,并且之后的命令會以 AOF 的方式進行數據追加。啥是開始的數據,有沒有一個具體的時間節點?2.每個redis集群都有16384個槽位嗎?為啥這么設置,槽位長啥樣
講師回復: 這分為幾種情況,最常見的就是使用 save 和 bgsave 時會生成 rdb 文件,其他操作時會以 aof 方式存儲,可以使用 info Persistence 命令查看 rdb 最后一次生成時間。關于槽位的問題,可以看 redis 作者的回復 https://github.com/antirez/redis/issues/2576
- 前言
- 開篇詞
- 開篇詞:大廠技術面試“潛規則”
- 模塊一:Java 基礎
- 第01講:String 的特點是什么?它有哪些重要的方法?
- 第02講:HashMap 底層實現原理是什么?JDK8 做了哪些優化?
- 第03講:線程的狀態有哪些?它是如何工作的?
- 第04講:詳解 ThreadPoolExecutor 的參數含義及源碼執行流程?
- 第05講:synchronized 和 ReentrantLock 的實現原理是什么?它們有什么區別?
- 第06講:談談你對鎖的理解?如何手動模擬一個死鎖?
- 第07講:深克隆和淺克隆有什么區別?它的實現方式有哪些?
- 第08講:動態代理是如何實現的?JDK Proxy 和 CGLib 有什么區別?
- 第09講:如何實現本地緩存和分布式緩存?
- 第10講:如何手寫一個消息隊列和延遲消息隊列?
- 模塊二:熱門框架
- 第11講:底層源碼分析 Spring 的核心功能和執行流程?(上)
- 第12講:底層源碼分析 Spring 的核心功能和執行流程?(下)
- 第13講:MyBatis 使用了哪些設計模式?在源碼中是如何體現的?
- 第14講:SpringBoot 有哪些優點?它和 Spring 有什么區別?
- 第15講:MQ 有什么作用?你都用過哪些 MQ 中間件?
- 模塊三:數據庫相關
- 第16講:MySQL 的運行機制是什么?它有哪些引擎?
- 第17講:MySQL 的優化方案有哪些?
- 第18講:關系型數據和文檔型數據庫有什么區別?
- 第19講:Redis 的過期策略和內存淘汰機制有什么區別?
- 第20講:Redis 怎樣實現的分布式鎖?
- 第21講:Redis 中如何實現的消息隊列?實現的方式有幾種?
- 第22講:Redis 是如何實現高可用的?
- 模塊四:Java 進階
- 第23講:說一下 JVM 的內存布局和運行原理?
- 第24講:垃圾回收算法有哪些?
- 第25講:你用過哪些垃圾回收器?它們有什么區別?
- 第26講:生產環境如何排除和優化 JVM?
- 第27講:單例的實現方式有幾種?它們有什么優缺點?
- 第28講:你知道哪些設計模式?分別對應的應用場景有哪些?
- 第29講:紅黑樹和平衡二叉樹有什么區別?
- 第30講:你知道哪些算法?講一下它的內部實現過程?
- 模塊五:加分項
- 第31講:如何保證接口的冪等性?常見的實現方案有哪些?
- 第32講:TCP 為什么需要三次握手?
- 第33講:Nginx 的負載均衡模式有哪些?它的實現原理是什么?
- 第34講:Docker 有什么優點?使用時需要注意什么問題?
- 彩蛋
- 彩蛋:如何提高面試成功率?