
數據庫是 Java 程序員面試必問的知識點之一,它和 Java 的核心面試點共同組成了一個完整的技術面試。而數據庫一般泛指的就是 MySQL,因為 MySQL 幾乎占據了數據庫的半壁江山,即使有些公司沒有使用 MySQL 數據庫,如果你對 MySQL 足夠精通的話,也是會被他們錄取的。因為數據庫的核心與原理基本是相通的,所以有了 MySQL 的基礎之后,再去熟悉其他數據庫也是非常快的,那么接下來的幾個課時就讓我們好好的學習一下 MySQL。
我們本課時的面試題是,MySQL 是如何運行的?說一下它有哪些引擎?
#### 典型回答
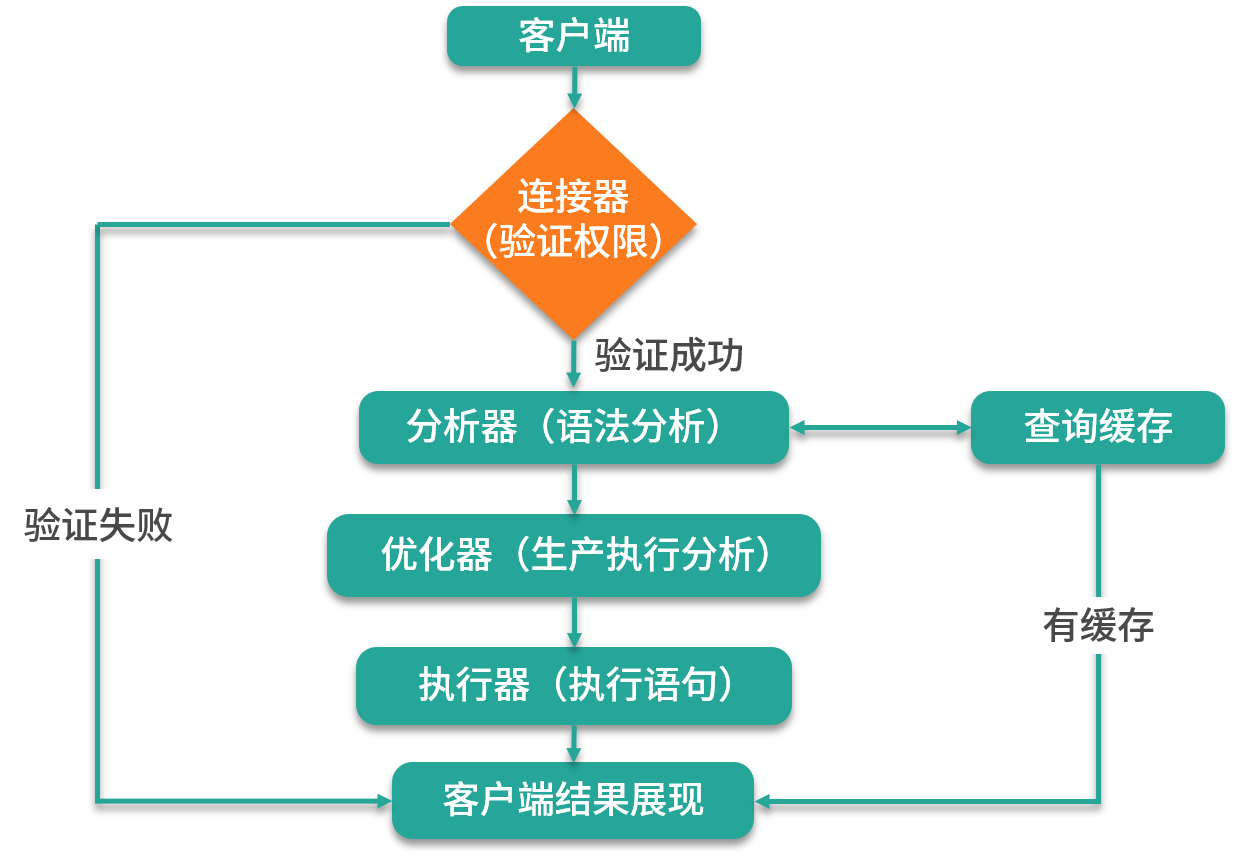
MySQL 的執行流程是這樣的,首先客戶端先要發送用戶信息去服務器端進行授權認證。如果使用的是命令行工具,通常需要輸入如下信息:
```
mysql -h 主機名(IP) -u 用戶名 -P 端口 -p
```
其中:
* -h 表示要連接的數據庫服務器的主機名或者 IP 信息;
* -u 表示數據庫的用戶名稱;
* -P 表示數據庫服務器的端口號,
* 小寫的 -p 表示需要輸入數據庫的密碼。
具體使用示例,如下圖所示:

當輸入正確密碼之后可以連接到數據庫了,如果密碼輸入錯誤,則會提示“Access denied for user 'xxx'@'xxx' (using password: YES)”密碼錯誤信息,如下圖所示:

當連接服務器端成功之后就可以正常的執行 SQL 命令了,MySQL 服務器拿到 SQL 命令之后,會使用 MySQL 的分析器解析 SQL 指令,同時會根據語法分析器驗證 SQL 指令,查詢 SQL 指令是否滿足 MySQL 的語法規則。如果不支持此語法,則會提示“SQL syntax”語法錯誤信息。
當分析器驗證并解析 SQL 命令之后,會進入優化器階段,執行生成計劃,并設置相應的索引;當上面的這些步驟都執行完之后,就進入了執行器階段,并開始正式執行 SQL 命令。同樣在執行命令之前,它會先對你的執行命令進行權限查詢,看看是否有操作某個表的權限,如果有相應的權限,執行器就去調用 MySQL 數據庫引擎提供的接口,執行相應的命令;如果是非查詢操作會記錄對應的操作日志,再命令執行完成之后返回結果給客戶端,這就是整個 MySQL 操作的完整流程。
需要注意的是,如果執行的是 select 語句并且是 MySQL 8.0 之前的版本的話,則會去 MySQL 的查詢緩存中查看之前是否有執行過這條 SQL;如果緩存中可以查到,則會直接返回查詢結果,這樣查詢性能就會提升很高。
整個 SQL 的執行流程,如下圖所示:
我們可以使用 SHOW ENGINES 命令來查看 MySQL 數據庫使用的存儲引擎,如下圖所示:
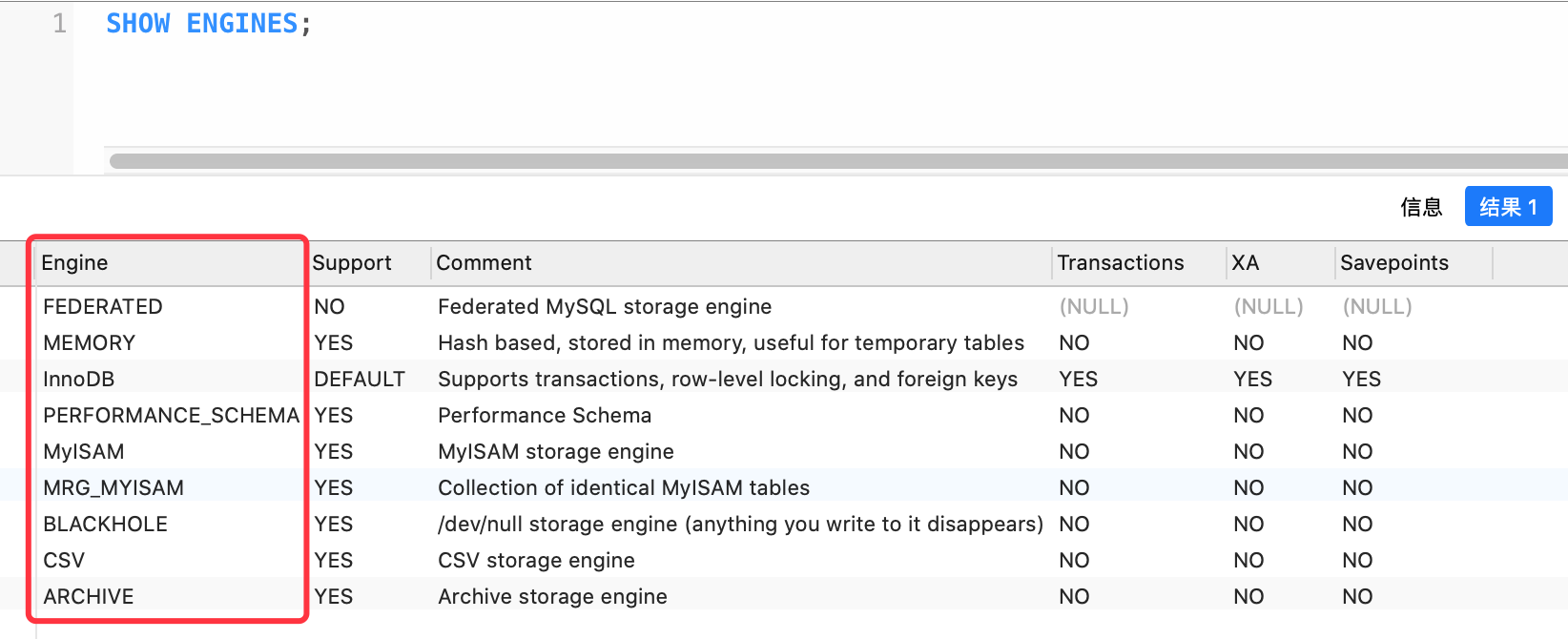
常用的數據庫引擎有 InnoDB、MyISAM、MEMORY 等,其中 InnoDB 支持事務功能,而 MyISAM 不支持事務,但 MyISAM 擁有較高的插入和查詢的速度。而 MEMORY 是內存型的數據庫引擎,它會將表中的數據存儲到內存中,因為它是內存級的數據引擎,因此具備最快速的查詢效率,但它的缺點是,重啟數據庫之后,所有數據都會丟失,因為這些數據是存放在內存中的。
#### 考點分析
此面試題考察的是面試者對 MySQL 基礎知識的掌握程度,以及對于 MySQL 引擎的了解程度,這些都是屬于 MySQL 最核心的原理之一,也是面試中常見的面試問題,它一般作為數據庫面試題的開始題目,和此面試題相關的面試點還有以下幾個:
* 查詢緩存在什么問題?
* 如何選擇數據庫的引擎?
* InnoDB 自增索引的持久化問題。
#### 知識擴展
* [ ] 1.查詢緩存的利弊
MySQL 8.0 之前可以正常的使用查詢緩存的功能,可通過“SHOW GLOBAL VARIABLES LIKE 'query_cache_type'”命令查詢數據庫是否開啟了查詢緩存的功能,它的結果值有以下三項:
* OFF,關閉了查詢緩存功能;
* ON,開啟了查詢緩存功能;
* DEMAND,在 sql 語句中指定 sql_cache 關鍵字才會有查詢緩存,也就是說必須使用 sql_cache 才可以把該 select 語句的查詢結果緩存起來,比如“select sql_cache name from token where tid=1010”語句。
開啟和關閉查詢緩存可以通過修改 MySQL 的配置文件 my.cnf 進行修改,它的配置項如下:
```
query_cache_type = ON
```
注意:配置被更改之后需要重啟 MySQL 服務才能生效。
查詢緩存的功能要根據實際的情況進行使用,建議設置為按需緩存(DEMAND)模式,因為查詢緩存的功能并不是那么好用。比如我們設置了 query_cache_type = ON,當我們好不容易緩存了很多查詢語句之后,任何一條對此表的更新操作都會把和這個表關聯的所有查詢緩存全部清空,那么在更新頻率相對較高的業務中,查詢緩存功能完全是一個雞肋。因此,在 MySQL 8.0 的版本中已經完全移除了此功能,也就是說在 MySQL 8.0 之后就完全沒有查詢緩存這個概念和功能了。
* [ ] 2.如何選擇數據庫引擎
選擇數據庫引擎要從實際的業務情況入手,比如是否需要支持事務?是否需要支持外鍵?是否需要支持持久化?以及是否支持地理位置存儲以及索引等方面進行綜合考量。
我們最常用的數據庫引擎是 InnoDB,它是 MySQL 5.5.5 之后的默認引擎,其優點是支持事務,且支持 4 種隔離級別。
* 讀未提交:也就是一個事務還沒有提交時,它做的變更就能被其他事務看到。
* 讀已提交:指的是一個事務只有提交了之后,其他事務才能看得到它的變更。
* 可重復讀:此方式為默認的隔離級別,它是指一個事務在執行過程中(從開始到結束)看到的數據都是一致的,在這個過程中未提交的變更對其他事務也是不可見的。
* 串行化:是指對同一行記錄的讀、寫都會添加讀鎖和寫鎖,后面訪問的事務必須等前一個事務執行完成之后才能繼續執行,所以這種事務的執行效率很低。
InnoDB 還支持外鍵、崩潰后的快速恢復、支持全文檢索(需要 5.6.4+ 版本)、集群索引,以及地理位置類型的存儲和索引等功能。
MyISAM 引擎是 MySQL 原生的引擎,但它并不支持事務功能,這也是后來被 InnoDB 替代為默認引擎的主要原因。MyISAM 有獨立的索引文件,因此在讀取數據方面的性能很高,它也支持全文索引、地理位置存儲和索引等功能,但不支持外鍵。
InnoDB 和 MyISAM 都支持持久化,但 MEMORY 引擎是將數據直接存儲在內存中了,因此在重啟服務之后數據就會丟失,但它帶來的優點是執行速度很快,可以作為臨時表來使用。
我們可以根據實際的情況設置相關的數據庫引擎,還可以針對不同的表設置不同的數據引擎,只需要在創建表的時候指定 engine=引擎名稱即可,SQL 代碼如下:
```
create table student(
id int primary key auto_increment,
uname varchar(60),
age int
) engine=Memory;
```
* [ ] 3.InnoDB 自增主鍵
在面試的過程中我們經常看到這樣一道面試題:
> 在一個自增表里面一共有 5 條數據,id 從 1 到 5,刪除了最后兩條數據,也就是 id 為 4 和 5 的數據,之后重啟的 MySQL 服務器,又新增了一條數據,請問新增的數據 id 為幾?
我們通常的答案是如果表為 MyISAM 引擎,那么 id 就是 6,如果是 InnoDB 那么 id 就是 4。
但是這個情況在高版本的 InnoDB 中,也就是 MySQL 8.0 之后就不準確了,它的 id 就不是 4 了,而是 6 了。因為在 MySQL 8.0 之后 InnoDB 會把索引持久化到日志中,重啟服務之后自增索引是不會丟失的,因此答案是 6,這個需要面試者注意一下。
#### 小結
本課時我們講了 MySQL 數據庫運行流程的幾個階段,先從連接器授權,再到分析器進行語法分析。如果是 MySQL 8.0 之前的 select 語句可能會先查詢緩存,如果有緩存則會直接返回結果給客戶端,否則會從分析器進入優化器生成 SQL 的執行計劃,然后交給執行器調用操作引擎執行相關的 SQL,再把結果返回給客戶端。我們還講了最常見的三種數據庫引擎 InnoDB、MyISAM、MEMORY,以及它們的利弊分析。最后講了 InnoDB 在高版本(8.0)之后
可以持久化自增主鍵的小特性,希望可以幫助到你。
- 前言
- 開篇詞
- 開篇詞:大廠技術面試“潛規則”
- 模塊一:Java 基礎
- 第01講:String 的特點是什么?它有哪些重要的方法?
- 第02講:HashMap 底層實現原理是什么?JDK8 做了哪些優化?
- 第03講:線程的狀態有哪些?它是如何工作的?
- 第04講:詳解 ThreadPoolExecutor 的參數含義及源碼執行流程?
- 第05講:synchronized 和 ReentrantLock 的實現原理是什么?它們有什么區別?
- 第06講:談談你對鎖的理解?如何手動模擬一個死鎖?
- 第07講:深克隆和淺克隆有什么區別?它的實現方式有哪些?
- 第08講:動態代理是如何實現的?JDK Proxy 和 CGLib 有什么區別?
- 第09講:如何實現本地緩存和分布式緩存?
- 第10講:如何手寫一個消息隊列和延遲消息隊列?
- 模塊二:熱門框架
- 第11講:底層源碼分析 Spring 的核心功能和執行流程?(上)
- 第12講:底層源碼分析 Spring 的核心功能和執行流程?(下)
- 第13講:MyBatis 使用了哪些設計模式?在源碼中是如何體現的?
- 第14講:SpringBoot 有哪些優點?它和 Spring 有什么區別?
- 第15講:MQ 有什么作用?你都用過哪些 MQ 中間件?
- 模塊三:數據庫相關
- 第16講:MySQL 的運行機制是什么?它有哪些引擎?
- 第17講:MySQL 的優化方案有哪些?
- 第18講:關系型數據和文檔型數據庫有什么區別?
- 第19講:Redis 的過期策略和內存淘汰機制有什么區別?
- 第20講:Redis 怎樣實現的分布式鎖?
- 第21講:Redis 中如何實現的消息隊列?實現的方式有幾種?
- 第22講:Redis 是如何實現高可用的?
- 模塊四:Java 進階
- 第23講:說一下 JVM 的內存布局和運行原理?
- 第24講:垃圾回收算法有哪些?
- 第25講:你用過哪些垃圾回收器?它們有什么區別?
- 第26講:生產環境如何排除和優化 JVM?
- 第27講:單例的實現方式有幾種?它們有什么優缺點?
- 第28講:你知道哪些設計模式?分別對應的應用場景有哪些?
- 第29講:紅黑樹和平衡二叉樹有什么區別?
- 第30講:你知道哪些算法?講一下它的內部實現過程?
- 模塊五:加分項
- 第31講:如何保證接口的冪等性?常見的實現方案有哪些?
- 第32講:TCP 為什么需要三次握手?
- 第33講:Nginx 的負載均衡模式有哪些?它的實現原理是什么?
- 第34講:Docker 有什么優點?使用時需要注意什么問題?
- 彩蛋
- 彩蛋:如何提高面試成功率?