
JVM(Java Virtual Machine,Java 虛擬機)顧名思義就是用來執行 Java 程序的“虛擬主機”,實際的工作是將編譯的 class 代碼(字節碼)翻譯成底層操作系統可以運行的機器碼并且進行調用執行,這也是 Java 程序能夠“一次編寫,到處運行”的原因(因為它會根據特定的操作系統生成對應的操作指令)。JVM 的功能很強大,像 Java 對象的創建、使用和銷毀,還有垃圾回收以及某些高級的性能優化,例如,熱點代碼檢測等功能都是在 JVM 中進行的。因為 JVM 是 Java 程序能夠運行的根本,因此掌握 JVM 也已經成了一個合格 Java 程序員必備的技能。
我們本課時的面試題是,說一下 JVM 的內存布局和運行原理?
#### 典型回答
JVM 的種類有很多,比如 HotSpot 虛擬機,它是 Sun/OracleJDK 和 OpenJDK 中的默認 JVM,也是目前使用范圍最廣的 JVM。我們常說的 JVM 其實泛指的是 HotSpot 虛擬機,還有曾經與 HotSpot 齊名為“三大商業 JVM”的 JRockit 和 IBM J9 虛擬機。但無論是什么類型的虛擬機都必須遵守 Oracle 官方發布的《Java虛擬機規范》,它是 Java 領域最權威最重要的著作之一,用于規范 JVM 的一些具體“行為”。
同樣對于 JVM 的內存布局也一樣,根據《Java虛擬機規范》的規定,JVM 的內存布局分為以下幾個部分:
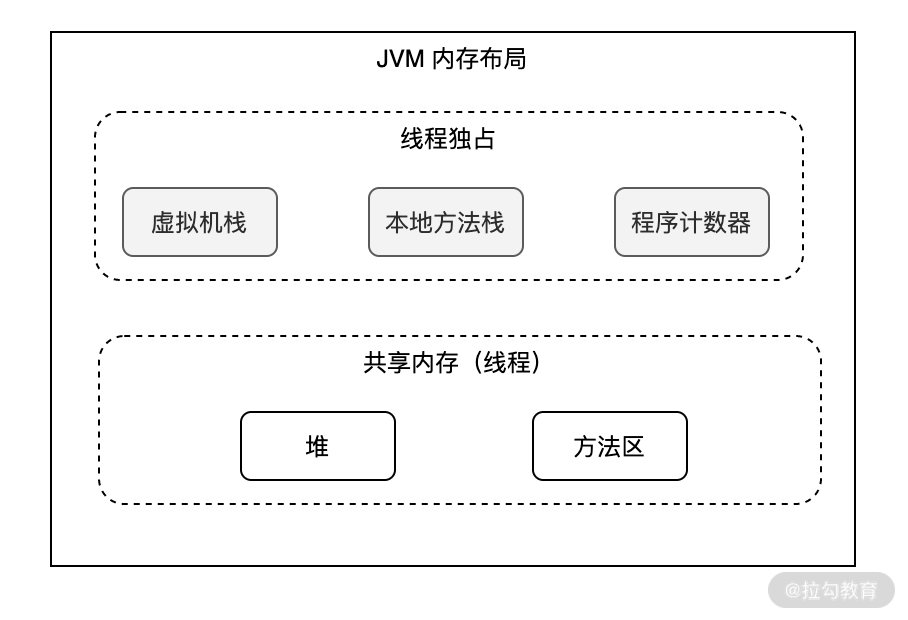
以上 5 個內存區域的主要用途如下。
* [ ] 1. 堆
堆(Java Heap) 也叫 Java 堆或者是 GC 堆,它是一個線程共享的內存區域,也是 JVM 中占用內存最大的一塊區域,Java 中所有的對象都存儲在這里。
《Java虛擬機規范》對 Java 堆的描述是:“所有的對象實例以及數組都應當在堆上分配”。但這在技術日益發展的今天已經有點不那么“準確”了,比如 JIT(Just In Time Compilation,即時編譯 )優化中的逃逸分析,使得變量可以直接在棧上被分配。
當對象或者是變量在方法中被創建之后,其指針可能被線程所引用,而這個對象就被稱作指針逃逸或者是引用逃逸。
比如以下代碼中的 sb 對象的逃逸:
```
public static StringBuffer createString() {
StringBuffer sb = new StringBuffer();
sb.append("Java");
return sb;
}
```
sb 雖然是一個局部變量,但上述代碼可以看出,它被直接 return 出去了,因此可能被賦值給了其他變量,并且被完全修改,于是此 sb 就逃逸到了方法外部。
想要 sb 變量不逃逸也很簡單,可以改為如下代碼:
```
public static String createString() {
StringBuffer sb = new StringBuffer();
sb.append("Java");
return sb.toString();
}
```
> 小貼士:通過逃逸分析可以讓變量或者是對象直接在棧上分配,從而極大地降低了垃圾回收的次數,以及堆分配對象的壓力,進而提高了程序的整體運行效率。
回到主題,堆大小的值可通過 -Xms 和 -Xmx 來設置(設置最小值和最大值),當堆超過最大值時就會拋出 OOM(OutOfMemoryError)異常。
* [ ] 2. 方法區
方法區(Method Area) 也被稱為非堆區,用于和“Java 堆”的概念進行區分,它也是線程共享的內存區域,用于存儲已經被 JVM 加載的類型信息、常量、靜態變量、代碼緩存等數據。
說到方法區有人可能會聯想到“永久代”,但對于《Java虛擬機規范》來說并沒有規定這樣一個區域,同樣它也只是 HotSpot 中特有的一個概念。這是因為 HotSpot 技術團隊把垃圾收集器的分代設計擴展到方法區之后才有的一個概念,可以理解為 HotSpot 技術團隊只是用永久代來實現方法區而已,但這會導致一個致命的問題,這樣設計更容易造成內存溢出。因為永久代有 -XX:MaxPermSize(方法區分配的最大內存)的上限,即使不設置也會有默認的大小。例如,32 位操作系統中的 4GB 內存限制等,并且這樣設計導致了部分的方法在不同類型的 Java 虛擬機下的表現也不同,比如 String::intern() 方法。所以在 JDK 1.7 時 HotSpot 虛擬機已經把原本放在永久代的字符串常量池和靜態變量等移出了方法區,并且在 JDK 1.8 中完全廢棄了永久代的概念。
* [ ] 3. 程序計數器
程序計數器(Program Counter Register) 線程獨有一塊很小的內存區域,保存當前線程所執行字節碼的位置,包括正在執行的指令、跳轉、分支、循環、異常處理等。
* [ ] 4. 虛擬機棧
虛擬機棧也叫 Java 虛擬機棧(Java Virtual Machine Stack),和程序計數器相同它也是線程獨享的,用來描述 Java 方法的執行,在每個方法被執行時就會同步創建一個棧幀,用來存儲局部變量表、操作棧、動態鏈接、方法出口等信息。當調用方法時執行入棧,而方法返回時執行出棧。
* [ ] 5. 本地方法棧
本地方法棧(Native Method Stacks)與虛擬機棧類似,它是線程獨享的,并且作用也和虛擬機棧類似。只不過虛擬機棧是為虛擬機中執行的 Java 方法服務的,而本地方法棧則是為虛擬機使用到的本地(Native)方法服務。
> 小貼士:需要注意的是《Java虛擬機規范》只規定了有這么幾個區域,但沒有規定 JVM 的具體實現細節,因此對于不同的 JVM 來說,實現也是不同的。例如,“永久代”是 HotSpot 中的一個概念,而對于 JRockit 來說就沒有這個概念。所以很多人說的 JDK 1.8 把永久代轉移到了元空間,這其實只是 HotSpot 的實現,而非《Java虛擬機規范》的規定。
JVM 的執行流程是,首先先把 Java 代碼(.java)轉化成字節碼(.class),然后通過類加載器將字節碼加載到內存中,所謂的內存也就是我們上面介紹的運行時數據區,但字節碼并不是可以直接交給操作系統執行的機器碼,而是一套 JVM 的指令集。這個時候需要使用特定的命令解析器也就是我們俗稱的**執行引擎(Execution Engine)**將字節碼翻譯成可以被底層操作系統執行的指令再去執行,這樣就實現了整個 Java 程序的運行,這也是 JVM 的整體執行流程。
#### 考點分析
JVM 的內存布局是一道必考的 Java 面試題,一般會作為 JVM 方面的第一道面試題出現,它也是中高級工程師必須掌握的一個知識點。和此知識點相關的面試題還有這些:類的加載分為幾個階段?每個階段代表什么含義?加載了什么內容?
* [ ] 知識擴展——類加載
類的生命周期會經歷以下 7 個階段:
* 加載階段(Loading)
* 驗證階段(Verification)
* 準備階段(Preparation)
* 解析階段(Resolution)
* 初始化階段(Initialization)
* 使用階段(Using)
* 卸載階段(Unloading)
其中驗證、準備、解析 3 個階段統稱為連接(Linking),如下圖所示:
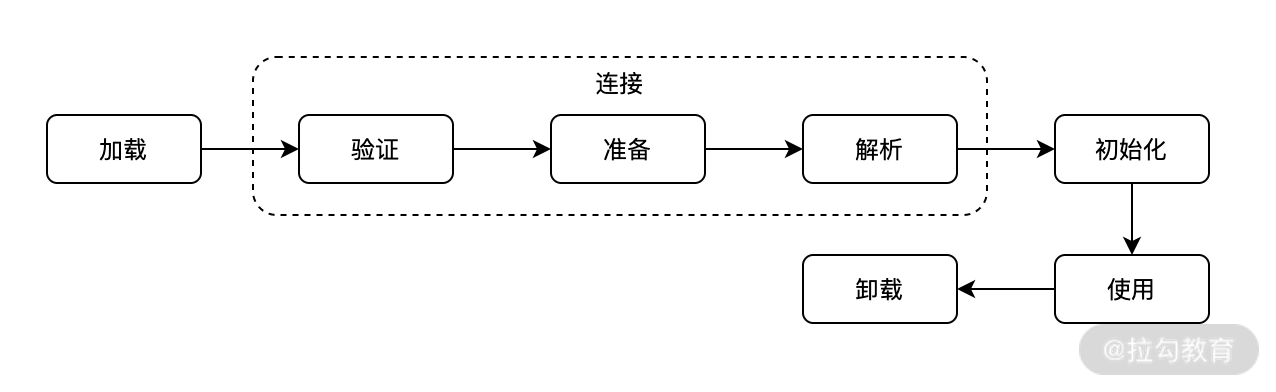
我們平常所說的 JVM 類加載通常指的就是前五個階段:加載、驗證、準備、解析、初始化等,接下來我們分別來看看。
* [ ] 1. 加載階段
此階段用于查到相應的類(通過類名進行查找)并將此類的字節流轉換為方法區運行時的數據結構,然后再在內存中生成一個能代表此類的 java.lang.Class 對象,作為其他數據訪問的入口。
>
小貼士:需要注意的是加載階段和連接階段的部分動作有可能是交叉執行的,比如一部分字節碼文件格式的驗證,在加載階段還未完成時就已經開始驗證了。
* [ ] 2. 驗證階段
此步驟主要是為了驗證字節碼的安全性,如果不做安全校驗的話可能會載入非安全或有錯誤的字節碼,從而導致系統崩潰,它是 JVM 自我保護的一項重要舉措。
驗證的主要動作大概有以下幾個:
* 文件格式校驗包括常量池中的常量類型、Class 文件的各個部分是否被刪除或被追加了其他信息等;
* 元數據校驗包括父類正確性校驗(檢查父類是否有被 final 修飾)、抽象類校驗等;
* 字節碼校驗,此步驟最為關鍵和復雜,主要用于校驗程序中的語義是否合法且符合邏輯;
* 符號引用校驗,對類自身以外比如常量池中的各種符號引用的信息進行匹配性校驗。
* [ ] 3. 準備階段
此階段是用來初始化并為類中定義的靜態變量分配內存的,這些靜態變量會被分配到方法區上。
HotSpot 虛擬機在 JDK 1.7 之前都在方法區,而 JDK 1.8 之后此變量會隨著類對象一起存放到 Java 堆中。
* [ ] 4. 解析階段
此階段主要是用來解析類、接口、字段及方法的,解析時會把符號引用替換成直接引用。
所謂的符號引用是指以一組符號來描述所引用的目標,符號可以是任何形式的字面量,只要使用時能無歧義地定位到目標即可;而直接引用是可以直接指向目標的指針、相對偏移量或者是一個能間接定位到目標的句柄。
符號引用和直接引用有一個重要的區別:使用符號引用時被引用的目標不一定已經加載到內存中;而使用直接引用時,引用的目標必定已經存在虛擬機的內存中了。
* [ ] 5. 初始化
初始化階段 JVM 就正式開始執行類中編寫的 Java 業務代碼了。到這一步驟之后,類的加載過程就算正式完成了。
#### 小結
本課時講了 JVM 的內存布局主要分為:堆、方法區、程序計數器、虛擬機棧和本地方法棧,并講了 JVM 的執行流程,先把 Java 代碼編譯成字節碼,再把字節碼加載到運行時數據區;然后交給 JVM 引擎把字節碼翻譯為操作系統可以執行的指令進行執行;最后還講了類加載的 5 個階段:加載、驗證、準備、解析和初始化。
#### 課后問答
* 1、問一個問題:1、加載階段, 在內存中生成一個能代表此類的 java.lang.Class 對象;3、準備階段, 用來初始化并為類中定義的靜態變量分配內存的;如果按照如上所說,豈不是一個類的構造函數在一個類的靜態代碼塊先執行? 然而實際上靜態代碼塊先于構造函數執行的, 如上所述是否有問題?
講師回復: 是先執行靜態變量再執行構造方法的,Java 對象的創建過程分為初始化和實例化兩個階段哦。
* 2、雙親委派是類加載中的某一個階段的特性,還是只是一種機制?
講師回復: 準確來說雙親委派屬于類加載的一種手段,也就是實現類加載的方法(為了防止重復加載類)。
* 3、替換為直接引用的過程如果沒加載過是不是找不到?會直接觸發符號引用指向類的加載嗎
講師回復: 替換的過程就是加載的過程哈。
- 前言
- 開篇詞
- 開篇詞:大廠技術面試“潛規則”
- 模塊一:Java 基礎
- 第01講:String 的特點是什么?它有哪些重要的方法?
- 第02講:HashMap 底層實現原理是什么?JDK8 做了哪些優化?
- 第03講:線程的狀態有哪些?它是如何工作的?
- 第04講:詳解 ThreadPoolExecutor 的參數含義及源碼執行流程?
- 第05講:synchronized 和 ReentrantLock 的實現原理是什么?它們有什么區別?
- 第06講:談談你對鎖的理解?如何手動模擬一個死鎖?
- 第07講:深克隆和淺克隆有什么區別?它的實現方式有哪些?
- 第08講:動態代理是如何實現的?JDK Proxy 和 CGLib 有什么區別?
- 第09講:如何實現本地緩存和分布式緩存?
- 第10講:如何手寫一個消息隊列和延遲消息隊列?
- 模塊二:熱門框架
- 第11講:底層源碼分析 Spring 的核心功能和執行流程?(上)
- 第12講:底層源碼分析 Spring 的核心功能和執行流程?(下)
- 第13講:MyBatis 使用了哪些設計模式?在源碼中是如何體現的?
- 第14講:SpringBoot 有哪些優點?它和 Spring 有什么區別?
- 第15講:MQ 有什么作用?你都用過哪些 MQ 中間件?
- 模塊三:數據庫相關
- 第16講:MySQL 的運行機制是什么?它有哪些引擎?
- 第17講:MySQL 的優化方案有哪些?
- 第18講:關系型數據和文檔型數據庫有什么區別?
- 第19講:Redis 的過期策略和內存淘汰機制有什么區別?
- 第20講:Redis 怎樣實現的分布式鎖?
- 第21講:Redis 中如何實現的消息隊列?實現的方式有幾種?
- 第22講:Redis 是如何實現高可用的?
- 模塊四:Java 進階
- 第23講:說一下 JVM 的內存布局和運行原理?
- 第24講:垃圾回收算法有哪些?
- 第25講:你用過哪些垃圾回收器?它們有什么區別?
- 第26講:生產環境如何排除和優化 JVM?
- 第27講:單例的實現方式有幾種?它們有什么優缺點?
- 第28講:你知道哪些設計模式?分別對應的應用場景有哪些?
- 第29講:紅黑樹和平衡二叉樹有什么區別?
- 第30講:你知道哪些算法?講一下它的內部實現過程?
- 模塊五:加分項
- 第31講:如何保證接口的冪等性?常見的實現方案有哪些?
- 第32講:TCP 為什么需要三次握手?
- 第33講:Nginx 的負載均衡模式有哪些?它的實現原理是什么?
- 第34講:Docker 有什么優點?使用時需要注意什么問題?
- 彩蛋
- 彩蛋:如何提高面試成功率?