
## 06 LinkedList 源碼解析
> 智慧,不是死的默念,而是生的沉思。
> ——斯賓諾莎
## 引導語
LinkedList 適用于集合元素先入先出和先入后出的場景,在隊列源碼中被頻繁使用,面試也經常問到,本小節讓我們通過源碼來加深對 LinkedList 的了解。
## 1 整體架構
LinkedList 底層數據結構是一個雙向鏈表,整體結構如下圖所示:
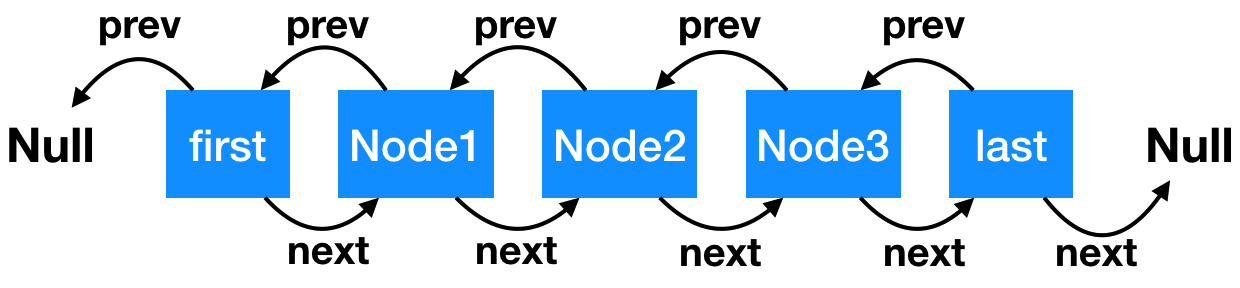上圖代表了一個雙向鏈表結構,鏈表中的每個節點都可以向前或者向后追溯,我們有幾個概念如下:
* 鏈表每個節點我們叫做 Node,Node 有 prev 屬性,代表前一個節點的位置,next 屬性,代表后一個節點的位置;
* first 是雙向鏈表的頭節點,它的前一個節點是 null。
* last 是雙向鏈表的尾節點,它的后一個節點是 null;
* 當鏈表中沒有數據時,first 和 last 是同一個節點,前后指向都是 null;
* 因為是個雙向鏈表,只要機器內存足夠強大,是沒有大小限制的。
鏈表中的元素叫做 Node,我們看下 Node 的組成部分:
~~~java
private static class Node<E> {
E item;// 節點值
Node<E> next; // 指向的下一個節點
Node<E> prev; // 指向的前一個節點
// 初始化參數順序分別是:前一個節點、本身節點值、后一個節點
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
~~~
## 2 源碼解析
### 2.1 追加(新增)
追加節點時,我們可以選擇追加到鏈表頭部,還是追加到鏈表尾部,add 方法默認是從尾部開始追加,addFirst 方法是從頭部開始追加,我們分別來看下兩種不同的追加方式:
**從尾部追加(add)**
~~~java
// 從尾部開始追加節點
void linkLast(E e) {
// 把尾節點數據暫存
final Node<E> l = last;
// 新建新的節點,初始化入參含義:
// l 是新節點的前一個節點,當前值是尾節點值
// e 表示當前新增節點,當前新增節點后一個節點是 null
final Node<E> newNode = new Node<>(l, e, null);
// 新建節點追加到尾部
last = newNode;
//如果鏈表為空(l 是尾節點,尾節點為空,鏈表即空),頭部和尾部是同一個節點,都是新建的節點
if (l == null)
first = newNode;
//否則把前尾節點的下一個節點,指向當前尾節點。
else
l.next = newNode;
//大小和版本更改
size++;
modCount++;
}
~~~
從源碼上來看,尾部追加節點比較簡單,只需要簡單地把指向位置修改下即可,我們做個動圖來描述下整個過程:
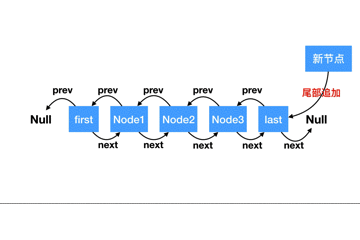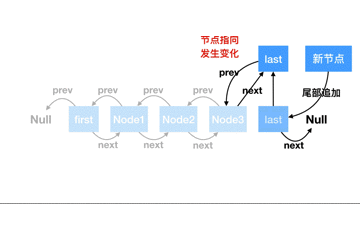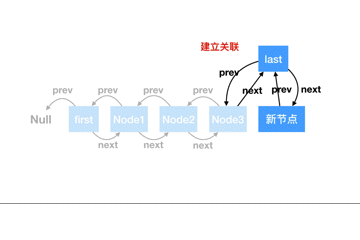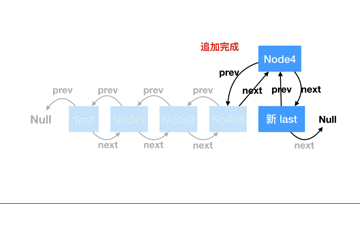
**從頭部追加(addFirst)**
~~~java
// 從頭部追加
private void linkFirst(E e) {
// 頭節點賦值給臨時變量
final Node<E> f = first;
// 新建節點,前一個節點指向null,e 是新建節點,f 是新建節點的下一個節點,目前值是頭節點的值
final Node<E> newNode = new Node<>(null, e, f);
// 新建節點成為頭節點
first = newNode;
// 頭節點為空,就是鏈表為空,頭尾節點是一個節點
if (f == null)
last = newNode;
//上一個頭節點的前一個節點指向當前節點
else
f.prev = newNode;
size++;
modCount++;
}
~~~
頭部追加節點和尾部追加節點非常類似,只是前者是移動頭節點的 prev 指向,后者是移動尾節點的 next 指向。
### 2.2 節點刪除
節點刪除的方式和追加類似,我們可以選擇從頭部刪除,也可以選擇從尾部刪除,刪除操作會把節點的值,前后指向節點都置為 null,幫助 GC 進行回收。
**從頭部刪除**
~~~java
//從頭刪除節點 f 是鏈表頭節點
private E unlinkFirst(Node<E> f) {
// 拿出頭節點的值,作為方法的返回值
final E element = f.item;
// 拿出頭節點的下一個節點
final Node<E> next = f.next;
//幫助 GC 回收頭節點
f.item = null;
f.next = null;
// 頭節點的下一個節點成為頭節點
first = next;
//如果 next 為空,表明鏈表為空
if (next == null)
last = null;
//鏈表不為空,頭節點的前一個節點指向 null
else
next.prev = null;
//修改鏈表大小和版本
size--;
modCount++;
return element;
}
~~~
從尾部刪除節點代碼也是類似的,就不貼了。
**從源碼中我們可以了解到,鏈表結構的節點新增、刪除都非常簡單,僅僅把前后節點的指向修改下就好了,所以 LinkedList 新增和刪除速度很快。**
### 2.3 節點查詢
鏈表查詢某一個節點是比較慢的,需要挨個循環查找才行,我們看看 LinkedList 的源碼是如何尋找節點的:
~~~java
// 根據鏈表索引位置查詢節點
Node<E> node(int index) {
// 如果 index 處于隊列的前半部分,從頭開始找,size >> 1 是 size 除以 2 的意思。
if (index < (size >> 1)) {
Node<E> x = first;
// 直到 for 循環到 index 的前一個 node 停止
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {// 如果 index 處于隊列的后半部分,從尾開始找
Node<E> x = last;
// 直到 for 循環到 index 的后一個 node 停止
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
~~~
從源碼中我們可以發現,LinkedList 并沒有采用從頭循環到尾的做法,而是采取了簡單二分法,首先看看 index 是在鏈表的前半部分,還是后半部分。如果是前半部分,就從頭開始尋找,反之亦然。通過這種方式,使循環的次數至少降低了一半,提高了查找的性能,這種思想值得我們借鑒。
### 2.4 方法對比
LinkedList 實現了 Queue 接口,在新增、刪除、查詢等方面增加了很多新的方法,這些方法在平時特別容易混淆,在鏈表為空的情況下,返回值也不太一樣,我們列一個表格,方便大家記錄:
| 方法含義 | 返回異常 | 返回特殊值 | 底層實現 |
| --- | --- | --- | --- |
| 新增 | add(e) | offer(e) | 底層實現相同 |
| 刪除 | remove() | poll(e) | 鏈表為空時,remove 會拋出異常,poll 返回 null。 |
| 查找 | element() | peek() | 鏈表為空時,element 會拋出異常,peek 返回 null。 |
PS:Queue 接口注釋建議 add 方法操作失敗時拋出異常,但 LinkedList 實現的 add 方法一直返回 true。
LinkedList 也實現了 Deque 接口,對新增、刪除和查找都提供從頭開始,還是從尾開始兩種方向的方法,比如 remove 方法,Deque 提供了 removeFirst 和 removeLast 兩種方向的使用方式,但當鏈表為空時的表現都和 remove 方法一樣,都會拋出異常。
### 2.5 迭代器
因為 LinkedList 要實現雙向的迭代訪問,所以我們使用 Iterator 接口肯定不行了,因為 Iterator 只支持從頭到尾的訪問。Java 新增了一個迭代接口,叫做:ListIterator,這個接口提供了向前和向后的迭代方法,如下所示:
| 迭代順序 | 方法 |
| --- | --- |
| 從尾到頭迭代方法 | hasPrevious、previous、previousIndex |
| 從頭到尾迭代方法 | hasNext、next、nextIndex |
LinkedList 實現了 ListIterator 接口,如下圖所示:
~~~java
// 雙向迭代器
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned;//上一次執行 next() 或者 previos() 方法時的節點位置
private Node<E> next;//下一個節點
private int nextIndex;//下一個節點的位置
//expectedModCount:期望版本號;modCount:目前最新版本號
private int expectedModCount = modCount;
…………
}
~~~
我們先來看下從頭到尾方向的迭代:
~~~java
// 判斷還有沒有下一個元素
public boolean hasNext() {
return nextIndex < size;// 下一個節點的索引小于鏈表的大小,就有
}
// 取下一個元素
public E next() {
//檢查期望版本號有無發生變化
checkForComodification();
if (!hasNext())//再次檢查
throw new NoSuchElementException();
// next 是當前節點,在上一次執行 next() 方法時被賦值的。
// 第一次執行時,是在初始化迭代器的時候,next 被賦值的
lastReturned = next;
// next 是下一個節點了,為下次迭代做準備
next = next.next;
nextIndex++;
return lastReturned.item;
}
~~~
上述源碼的思路就是直接取當前節點的下一個節點,而從尾到頭迭代稍微復雜一點,如下:
~~~java
// 如果上次節點索引位置大于 0,就還有節點可以迭代
public boolean hasPrevious() {
return nextIndex > 0;
}
// 取前一個節點
public E previous() {
checkForComodification();
if (!hasPrevious())
throw new NoSuchElementException();
// next 為空場景:1:說明是第一次迭代,取尾節點(last);2:上一次操作把尾節點刪除掉了
// next 不為空場景:說明已經發生過迭代了,直接取前一個節點即可(next.prev)
lastReturned = next = (next == null) ? last : next.prev;
// 索引位置變化
nextIndex--;
return lastReturned.item;
}
~~~
這里復雜點體現在需要判斷 next 不為空和為空的場景,代碼注釋中有詳細的描述。
**迭代器刪除**
LinkedList 在刪除元素時,也推薦通過迭代器進行刪除,刪除過程如下:
~~~java
public void remove() {
checkForComodification();
// lastReturned 是本次迭代需要刪除的值,分以下空和非空兩種情況:
// lastReturned 為空,說明調用者沒有主動執行過 next() 或者 previos(),直接報錯
// lastReturned 不為空,是在上次執行 next() 或者 previos()方法時賦的值
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
//刪除當前節點
unlink(lastReturned);
// next == lastReturned 的場景分析:從尾到頭遞歸順序,并且是第一次迭代,并且要刪除最后一個元素的情況下
// 這種情況下,previous() 方法里面設置了 lastReturned = next = last,所以 next 和 lastReturned會相等
if (next == lastReturned)
// 這時候 lastReturned 是尾節點,lastNext 是 null,所以 next 也是 null,這樣在 previous() 執行時,發現 next 是 null,就會把尾節點賦值給 next
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
~~~
## 總結
LinkedList 適用于要求有順序、并且會按照順序進行迭代的場景,主要是依賴于底層的鏈表結構,在面試中的頻率還是蠻高的,相信理清楚上面的源碼后,應對面試應該沒有問題。
- 前言
- 第1章 基礎
- 01 開篇詞:為什么學習本專欄
- 02 String、Long 源碼解析和面試題
- 03 Java 常用關鍵字理解
- 04 Arrays、Collections、Objects 常用方法源碼解析
- 第2章 集合
- 05 ArrayList 源碼解析和設計思路
- 06 LinkedList 源碼解析
- 07 List 源碼會問哪些面試題
- 08 HashMap 源碼解析
- 09 TreeMap 和 LinkedHashMap 核心源碼解析
- 10 Map源碼會問哪些面試題
- 11 HashSet、TreeSet 源碼解析
- 12 彰顯細節:看集合源碼對我們實際工作的幫助和應用
- 13 差異對比:集合在 Java 7 和 8 有何不同和改進
- 14 簡化工作:Guava Lists Maps 實際工作運用和源碼
- 第3章 并發集合類
- 15 CopyOnWriteArrayList 源碼解析和設計思路
- 16 ConcurrentHashMap 源碼解析和設計思路
- 17 并發 List、Map源碼面試題
- 18 場景集合:并發 List、Map的應用場景
- 第4章 隊列
- 19 LinkedBlockingQueue 源碼解析
- 20 SynchronousQueue 源碼解析
- 21 DelayQueue 源碼解析
- 22 ArrayBlockingQueue 源碼解析
- 23 隊列在源碼方面的面試題
- 24 舉一反三:隊列在 Java 其它源碼中的應用
- 25 整體設計:隊列設計思想、工作中使用場景
- 26 驚嘆面試官:由淺入深手寫隊列
- 第5章 線程
- 27 Thread 源碼解析
- 28 Future、ExecutorService 源碼解析
- 29 押寶線程源碼面試題
- 第6章 鎖
- 30 AbstractQueuedSynchronizer 源碼解析(上)
- 31 AbstractQueuedSynchronizer 源碼解析(下)
- 32 ReentrantLock 源碼解析
- 33 CountDownLatch、Atomic 等其它源碼解析
- 34 只求問倒:連環相扣系列鎖面試題
- 35 經驗總結:各種鎖在工作中使用場景和細節
- 36 從容不迫:重寫鎖的設計結構和細節
- 第7章 線程池
- 37 ThreadPoolExecutor 源碼解析
- 38 線程池源碼面試題
- 39 經驗總結:不同場景,如何使用線程池
- 40 打動面試官:線程池流程編排中的運用實戰
- 第8章 Lambda 流
- 41 突破難點:如何看 Lambda 源碼
- 42 常用的 Lambda 表達式使用場景解析和應用
- 第9章 其他
- 43 ThreadLocal 源碼解析
- 44 場景實戰:ThreadLocal 在上下文傳值場景下的實踐
- 45 Socket 源碼及面試題
- 46 ServerSocket 源碼及面試題
- 47 工作實戰:Socket 結合線程池的使用
- 第10章 專欄總結
- 48 一起看過的 Java 源碼和面試真題