
## 11 [X]HashSet、TreeSet 源碼解析
## 引導語
HashSet、TreeSet 兩個類是在 Map 的基礎上組裝起來的類,我們學習的側重點,主要在于 Set 是如何利用 Map 現有的功能,來達成自己的目標的,也就是說如何基于現有的功能進行創新,然后再看看一些改變的小細節是否值得我們學習。
### 1 HashSet
#### 1.1 類注釋
看源碼先看類注釋上,我們可以得到的信息有:
1. 底層實現基于 HashMap,所以迭代時不能保證按照插入順序,或者其它順序進行迭代;
2. add、remove、contanins、size 等方法的耗時性能,是不會隨著數據量的增加而增加的,這個主要跟 HashMap 底層的數組數據結構有關,不管數據量多大,不考慮 hash 沖突的情況下,時間復雜度都是 O (1);
3. 線程不安全的,如果需要安全請自行加鎖,或者使用 Collections.synchronizedSet;
4. 迭代過程中,如果數據結構被改變,會快速失敗的,會拋出 ConcurrentModificationException 異常。
我們之前也看過 List、Map 的類注釋,我們發現 2、3、4 點信息在類注釋中都有提到,所以如果有人問 List、Map、 Set 三者的共同點,那么就可以說 2、3、4 三點。
#### 1.2 HashSet 是如何組合 HashMap 的
剛才是從類注釋 1 中看到,HashSet 的實現是基于 HashMap 的,在 Java 中,要基于基礎類進行創新實現,有兩種辦法:
* 繼承基礎類,覆寫基礎類的方法,比如說繼承 HashMap , 覆寫其 add 的方法;
* 組合基礎類,通過調用基礎類的方法,來復用基礎類的能力。
HashSet 使用的就是組合 HashMap,其優點如下:
1. 繼承表示父子類是同一個事物,而 Set 和 Map 本來就是想表達兩種事物,所以繼承不妥,而且 Java 語法限制,子類只能繼承一個父類,后續難以擴展。
2. 組合更加靈活,可以任意的組合現有的基礎類,并且可以在基礎類方法的基礎上進行擴展、編排等,而且方法命名可以任意命名,無需和基礎類的方法名稱保持一致。
我們在工作中,如果碰到類似問題,我們的原則也是盡量多用組合,少用繼承。
組合就是把 HashMap 當作自己的一個局部變量,以下是 HashSet 的組合實現:
```
// 把 HashMap 組合進來,key 是 Hashset 的 key,value 是下面的 PRESENT
private transient HashMap<E,Object> map;
// HashMap 中的 value
private static final Object PRESENT = new Object();
```
從這兩行代碼中,我們可以看出兩點:
1. 我們在使用 HashSet 時,比如 add 方法,只有一個入參,但組合的 Map 的 add 方法卻有 key,value 兩個入參,相對應上 Map 的 key 就是我們 add 的入參,value 就是第二行代碼中的 PRESENT,此處設計非常巧妙,用一個默認值 PRESENT 來代替 Map 的 Value;
2. 如果 HashSet 是被共享的,當多個線程訪問的時候,就會有線程安全問題,因為在后續的所有操作中,并沒有加鎖。
HashSet 在以 HashMap 為基礎進行實現的時候,首先選擇組合的方式,接著使用默認值來代替了 Map 中的 Value 值,設計得非常巧妙,給使用者的體驗很好,使用起來簡單方便,我們在工作中也可以借鑒這種思想,可以把底層復雜實現包裝一下,一些默認實現可以自己吃掉,使吐出去的接口盡量簡單好用。
#### 1.2.1 初始化
HashSet 的初始化比較簡單,直接 new HashMap 即可,比較有意思的是,當有原始集合數據進行初始化的情況下,會對 HashMap 的初始容量進行計算,源碼如下:
```
// 對 HashMap 的容量進行了計算
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
```
上述代碼中:Math.max ((int) (c.size ()/.75f) + 1, 16),就是對 HashMap 的容量進行了計算,翻譯成中文就是 取括號中兩個數的最大值(期望的值 / 0.75+1,默認值 16),從計算中,我們可以看出 HashSet 的實現者對 HashMap 的底層實現是非常清楚的,主要體現在兩個方面:
1. 和 16 比較大小的意思是說,如果給定 HashMap 初始容量小于 16 ,就按照 HashMap 默認的 16 初始化好了,如果大于 16,就按照給定值初始化。
2. HashMap 擴容的伐值的計算公式是:Map 的容量 * 0.75f,一旦達到閥值就會擴容,此處用 (int) (c.size ()/.75f) + 1 來表示初始化的值,這樣使我們期望的大小值正好比擴容的閥值還大 1,就不會擴容,符合 HashMap 擴容的公式。
從簡單的構造器中,我們就可以看出要很好的組合 api 接口,并沒有那么簡單,我們可能需要去了解一下被組合的 api 底層的實現,這樣才能用好 api。
同時這種寫法,也提供了一種思路給我們,如果有人問你,往 HashMap 拷貝大集合時,如何給 HashMap 初始化大小時,完全可以借鑒這種寫法:取最大值(期望的值 / 0.75 + 1,默認值 16)。
至于 HashSet 的其他方法就比較簡單了,就是對 Map 的 api 進行了一些包裝,如下的 add 方法實現:
```
public boolean add(E e) {
// 直接使用 HashMap 的 put 方法,進行一些簡單的邏輯判斷
return map.put(e, PRESENT)==null;
}
```
從 add 方法中,我們就可以看到組合的好處,方法的入參、名稱、返回值都可以自定義,如果是繼承的話就不行了。
#### 1.2.2 小結
HashSet 具體實現值得我們借鑒的地方主要有如下地方,我們平時寫代碼的時候,完全可以參考參考:
1. 對組合還是繼承的分析和把握;
2. 對復雜邏輯進行一些包裝,使吐出去的接口盡量簡單好用;
3. 組合其他 api 時,盡量多對組合的 api 多些了解,這樣才能更好的使用 api;
4. HashMap 初始化大小值的模版公式:取括號內兩者的最大值(期望的值 / 0.75+1,默認值 16)。
### 2 TreeSet
TreeSet 大致的結構和 HashSet 相似,底層組合的是 TreeMap,所以繼承了 TreeMap key 能夠排序的功能,迭代的時候,也可以按照 key 的排序順序進行迭代,我們主要來看復用 TreeMap 時,復用的兩種思路:
#### 2.1 復用 TreeMap 的思路一
場景一: TreeSet 的 add 方法,我們來看下其源碼:
```
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
```
可以看到,底層直接使用的是 HashMap 的 put 的能力,直接拿來用就好了。
#### 2.2 復用 TreeMap 的思路二
場景二:需要迭代 TreeSet 中的元素,那應該也是像 add 那樣,直接使用 HashMap 已有的迭代能力,比如像下面這樣:
```
// 模仿思路一的方式實現
public Iterator<E> descendingIterator() {
// 直接使用 HashMap.keySet 的迭代能力
return m.keySet().iterator();
}
```
這種是思路一的實現方式,TreeSet 組合 TreeMap,直接選擇 TreeMap 的底層能力進行包裝,但 TreeSet 實際執行的思路卻完全相反,我們看源碼:
```
// NavigableSet 接口,定義了迭代的一些規范,和一些取值的特殊方法
// TreeSet 實現了該方法,也就是說 TreeSet 本身已經定義了迭代的規范
public interface NavigableSet<E> extends SortedSet<E> {
Iterator<E> iterator();
E lower(E e);
}
// m.navigableKeySet() 是 TreeMap 寫了一個子類實現了 NavigableSet
// 接口,實現了 TreeSet 定義的迭代規范
public Iterator<E> iterator() {
return m.navigableKeySet().iterator();
}
```
TreeMap 中對 NavigableSet 接口的實現源碼截圖如下:
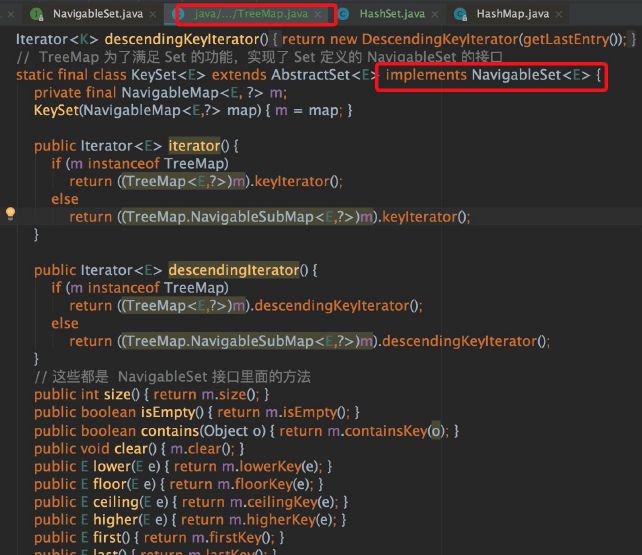
從截圖中(截圖是在 TreeMap 中),我們可以看出 TreeMap 實現了 TreeSet 定義的各種特殊方法。
我們可以看到,這種思路是 TreeSet 定義了接口的規范,TreeMap 負責去實現,實現思路和思路一是相反的。
我們總結下 TreeSet 組合 TreeMap 實現的兩種思路:
1. TreeSet 直接使用 TreeMap 的某些功能,自己包裝成新的 api。
2. TreeSet 定義自己想要的 api,自己定義接口規范,讓 TreeMap 去實現。
方案 1 和 2 的調用關系,都是 TreeSet 調用 TreeMap,但功能的實現關系完全相反,第一種是功能的定義和實現都在 TreeMap,TreeSet 只是簡單的調用而已,第二種 TreeSet 把接口定義出來
后,讓 TreeMap 去實現內部邏輯,TreeSet 負責接口定義,TreeMap 負責具體實現,這樣子的話因為接口是 TreeSet 定義的,所以實現一定是 TreeSet 最想要的,TreeSet 甚至都不用包裝,可以直接把返回值吐出去都行。
我們思考下這兩種復用思路的原因:
1. 像 add 這些簡單的方法,我們直接使用的是思路 1,主要是 add 這些方法實現比較簡單,沒有復雜邏輯,所以 TreeSet 自己實現起來比較簡單;
2. 思路 2 主要適用于復雜場景,比如說迭代場景,TreeSet 的場景復雜,比如要能從頭開始迭代,比如要能取第一個值,比如要能取最后一個值,再加上 TreeMap 底層結構比較復雜,TreeSet 可能并不清楚 TreeMap 底層的復雜邏輯,這時候讓 TreeSet 來實現如此復雜的場景邏輯,TreeSet 就搞不定了,不如接口讓 TreeSet 來定義,讓 TreeMap 去負責實現,TreeMap 對底層的復雜結構非常清楚,實現起來既準確又簡單。
#### 2.3 小結
TreeSet 對 TreeMap 的兩種不同復用思路,很重要,在工作中經常會遇到,特別是思路二,比如說 dubbo 的泛化調用,DDD 中的依賴倒置等等,原理都是 TreeSet 第二種的復用思想。
### 3 面試題
HashSet 和 TreeSet 的面試概率比不上 List 和 Map,但只要有機會,并把本文的內容表達出來,絕對是加分項,因為現在 List 和 Map 面試題太多,面試官認為你能答的出來是應該的,但只要你有機會對 HashSet 和 TreeSet 說出本文見解,并且說自己是看源碼時領悟到的,絕對肯定是加分項,這些就是你超過面試官預期的驚喜,以下是一些常用的題目:
#### 3.1 TreeSet 有用過么,平時都在什么場景下使用?
答:有木有用過如實回答就好了,我們一般都是在需要把元素進行排序的時候使用 TreeSet,使用時需要我們注意元素最好實現 Comparable 接口,這樣方便底層的 TreeMap 根據 key 進行排序。
#### 3.2 追問,如果我想實現根據 key 的新增順序進行遍歷怎么辦?
答:要按照 key 的新增順序進行遍歷,首先想到的應該就是 LinkedHashMap,而 LinkedHashSet 正好是基于 LinkedHashMap 實現的,所以我們可以選擇使用 LinkedHashSet。
#### 3.3 追問,如果我想對 key 進行去重,有什么好的辦法么?
答:我們首先想到的是 TreeSet,TreeSet 底層使用的是 TreeMap,TreeMap 在 put 的時候,如果發現 key 是相同的,會把 value 值進行覆蓋,所有不會產生重復的 key ,利用這一特性,使用 TreeSet 正好可以去重。
#### 3.4 說說 TreeSet 和 HashSet 兩個 Set 的內部實現結構和原理?
答: HashSet 底層對 HashMap 的能力進行封裝,比如說 add 方法,是直接使用 HashMap 的 put 方法,比較簡單,但在初始化的時候,我看源碼有一些感悟:說一下 HashSet 小結的四小點。
TreeSet 主要是對 TreeMap 底層能力進行封裝復用,我發現了兩種非常有意思的復用思路,重復 TreeSet 兩種復用思路。
### 總結
本小節主要說了 Set 源碼中兩處亮點:
1. HashSet 對組合的 HashMap 類擴容的門閥值的深入了解和設計,值得我們借鑒;
2. TreeSet 對 TreeMap 兩種復用思路,值得我們學習,特別是第二種復用思路。
HashSet 和 TreeSet 不會是面試的重點,但通過以上兩點,可以讓我們給面試官一種精益求精的感覺,成為加分項。
- 前言
- 第1章 基礎
- 01 開篇詞:為什么學習本專欄
- 02 String、Long 源碼解析和面試題
- 03 Java 常用關鍵字理解
- 04 Arrays、Collections、Objects 常用方法源碼解析
- 第2章 集合
- 05 ArrayList 源碼解析和設計思路
- 06 LinkedList 源碼解析
- 07 List 源碼會問哪些面試題
- 08 HashMap 源碼解析
- 09 TreeMap 和 LinkedHashMap 核心源碼解析
- 10 Map源碼會問哪些面試題
- 11 HashSet、TreeSet 源碼解析
- 12 彰顯細節:看集合源碼對我們實際工作的幫助和應用
- 13 差異對比:集合在 Java 7 和 8 有何不同和改進
- 14 簡化工作:Guava Lists Maps 實際工作運用和源碼
- 第3章 并發集合類
- 15 CopyOnWriteArrayList 源碼解析和設計思路
- 16 ConcurrentHashMap 源碼解析和設計思路
- 17 并發 List、Map源碼面試題
- 18 場景集合:并發 List、Map的應用場景
- 第4章 隊列
- 19 LinkedBlockingQueue 源碼解析
- 20 SynchronousQueue 源碼解析
- 21 DelayQueue 源碼解析
- 22 ArrayBlockingQueue 源碼解析
- 23 隊列在源碼方面的面試題
- 24 舉一反三:隊列在 Java 其它源碼中的應用
- 25 整體設計:隊列設計思想、工作中使用場景
- 26 驚嘆面試官:由淺入深手寫隊列
- 第5章 線程
- 27 Thread 源碼解析
- 28 Future、ExecutorService 源碼解析
- 29 押寶線程源碼面試題
- 第6章 鎖
- 30 AbstractQueuedSynchronizer 源碼解析(上)
- 31 AbstractQueuedSynchronizer 源碼解析(下)
- 32 ReentrantLock 源碼解析
- 33 CountDownLatch、Atomic 等其它源碼解析
- 34 只求問倒:連環相扣系列鎖面試題
- 35 經驗總結:各種鎖在工作中使用場景和細節
- 36 從容不迫:重寫鎖的設計結構和細節
- 第7章 線程池
- 37 ThreadPoolExecutor 源碼解析
- 38 線程池源碼面試題
- 39 經驗總結:不同場景,如何使用線程池
- 40 打動面試官:線程池流程編排中的運用實戰
- 第8章 Lambda 流
- 41 突破難點:如何看 Lambda 源碼
- 42 常用的 Lambda 表達式使用場景解析和應用
- 第9章 其他
- 43 ThreadLocal 源碼解析
- 44 場景實戰:ThreadLocal 在上下文傳值場景下的實踐
- 45 Socket 源碼及面試題
- 46 ServerSocket 源碼及面試題
- 47 工作實戰:Socket 結合線程池的使用
- 第10章 專欄總結
- 48 一起看過的 Java 源碼和面試真題