
## 12 彰顯細節:看集合源碼對我們實際工作的幫助和應用
本節中,我們先跳出源碼的視角,來看看集合類的類圖,看看在設計層面上,是否有可疑借鑒之處,接著通過源碼來找找工作中的集合坑,提前掃雷。
### 1 集合類圖
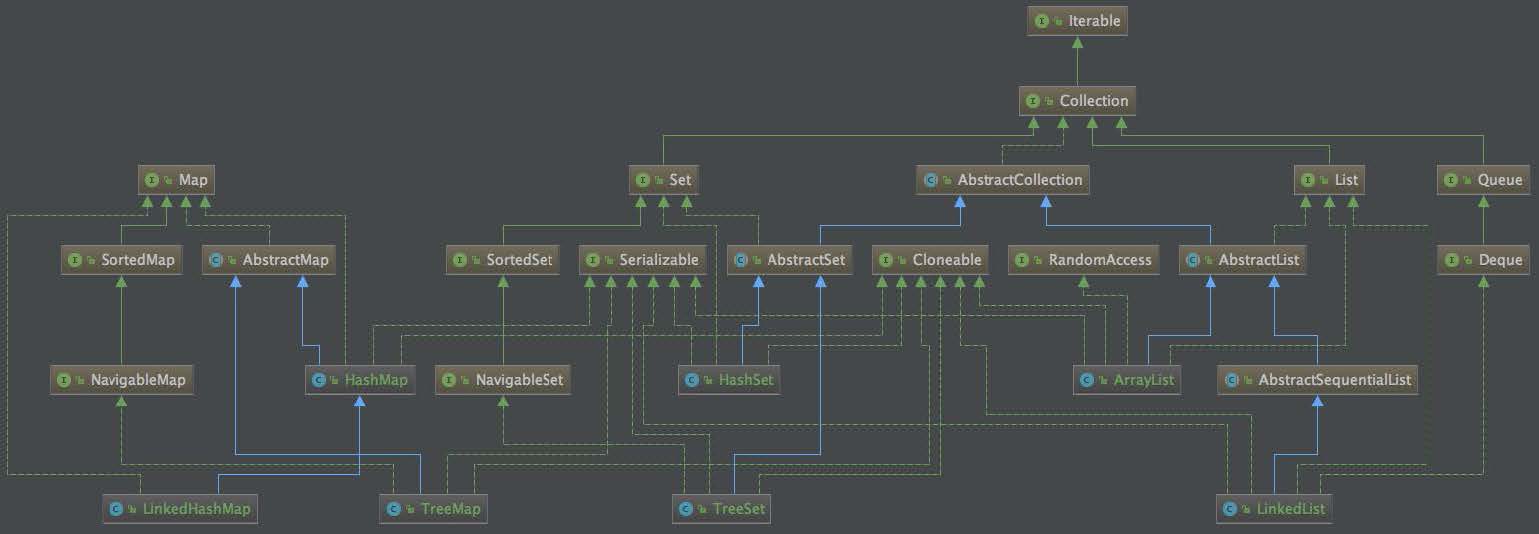
上圖是目前我們已學的集合類圖,大概可以看出以下幾點:
1. 每個接口做的事情非常明確,比如 Serializable,只負責序列化,Cloneable 只負責拷貝,Map 只負責定義 Map 的接口,整個圖看起來雖然接口眾多,但職責都很清晰;
2. 復雜功能通過接口的繼承來實現,比如 ArrayList 通過實現了 Serializable、Cloneable、RandomAccess、AbstractList、List 等接口,從而擁有了序列化、拷貝、對數組各種操作定義等各種功能;
3. 上述類圖只能看見繼承的關系,組合的關系還看不出來,比如說 Set 組合封裝 Map 的底層能力等。
上述設計的最大好處是,每個接口能力職責單一,眾多的接口變成了接口能力的積累,假設我們想再實現一個數據結構類,我們就可以從這些已有的能力接口中,挑選出能滿足需求的能力接口,進行一些簡單的組裝,從而加快開發速度。
這種思想在平時的工作中也經常被使用,我們會把一些通用的代碼塊抽象出來,沉淀成代碼塊池,碰到不同的場景的時候,我們就從代碼塊池中,把我們需要的代碼塊提取出來,進行簡單的編排和組裝,從而實現我們需要的場景功能。
### 2 集合工作中一些注意事項
#### 2.1 線程安全
我們說集合都是非線程安全的,這里說的非線程安全指的是集合類作為共享變量,被多線程讀寫的時候,才是不安全的,如果要實現線程安全的集合,在類注釋中,JDK 統一推薦我們使用 Collections.synchronized* 類, Collections 幫我們實現了 List、Set、Map 對應的線程安全的方法, 如下圖:
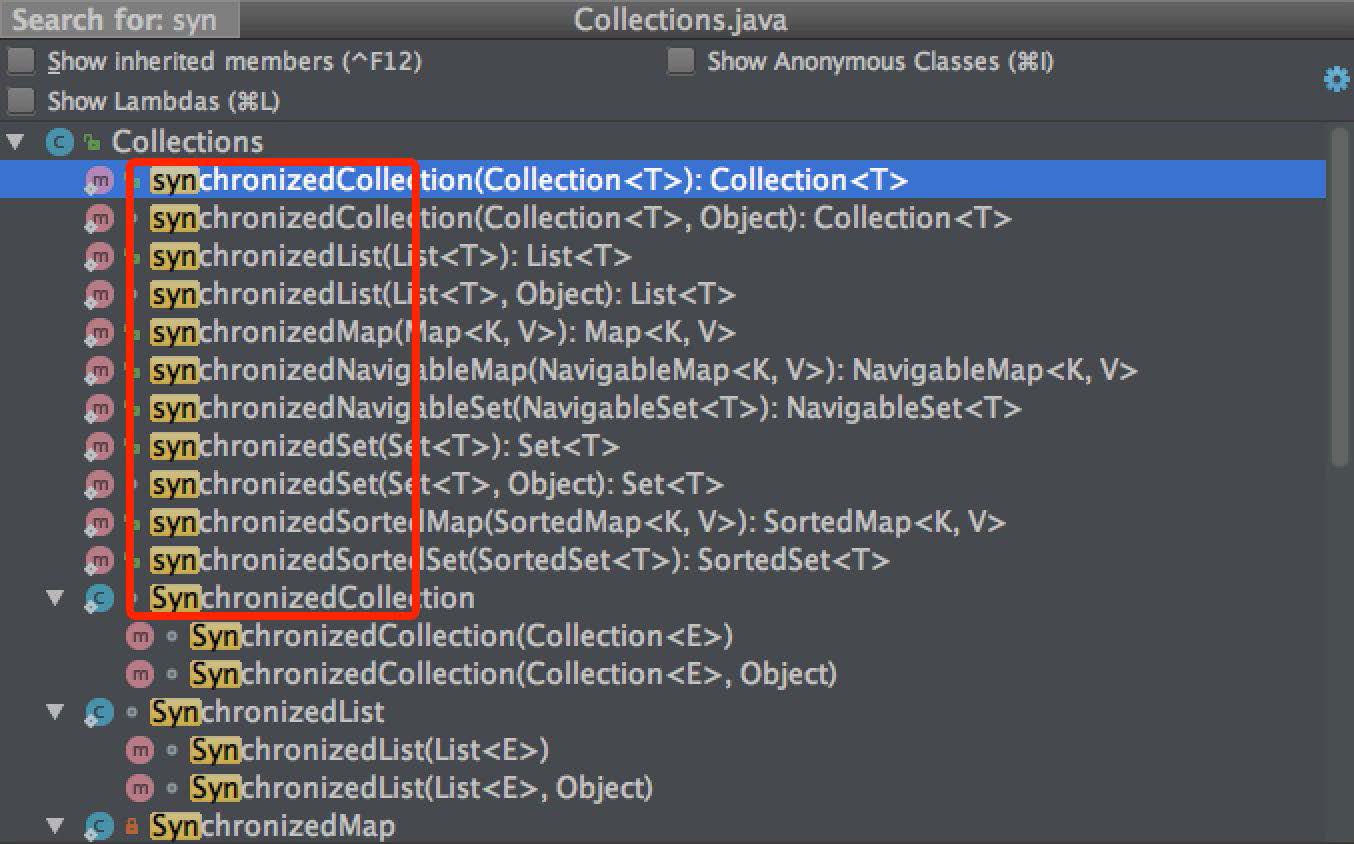
圖中實現了各種集合類型的線程安全的方法,我們以 synchronizedList 為例,從源碼上來看下,Collections 是如何實現線程安全的:
```
// mutex 就是我們需要鎖住的對象 final Object mutex; static class SynchronizedList<E> extends SynchronizedCollection<E> implements List<E> { private static final long serialVersionUID = -7754090372962971524L; // 這個 List 就是我們需要保證線程安全的類 final List<E> list; SynchronizedList(List<E> list, Object mutex) { super(list, mutex); this.list = list; } // 我們可以看到,List 的所有操作都使用了 synchronized 關鍵字,來進行加鎖 // synchronized 是一種悲觀鎖,能夠保證同一時刻,只能有一個線程能夠獲得鎖
public E get(int index) { synchronized (mutex) {return list.get(index);} } public E set(int index, E element) { synchronized (mutex) {return list.set(index, element);} } public void add(int index, E element) { synchronized (mutex) {list.add(index, element);} } ………… }
```
從源碼中我們可以看到 Collections 是通過 synchronized 關鍵字給 List 操作數組的方法加上鎖,來實現線程安全的。
### 2.2 集合性能
集合的單個操作,一般都沒有性能問題,性能問題主要出現的批量操作上。
#### 2.2.1 批量新增
在 List 和 Map 大量數據新增的時候,我們不要使用 for 循環 + add/put 方法新增,這樣子會有很大的擴容成本,我們應該盡量使用 addAll 和 putAll 方法進行新增,以 ArrayList 為例寫了一個 demo 如下,演示了兩種方案的性能對比:
```
@Test public void testBatchInsert(){ // 準備拷貝數據 ArrayList<Integer> list = new ArrayList<>(); for(int i=0;i<3000000;i++){ list.add(i); }
// for 循環 + add ArrayList<Integer> list2 = new ArrayList<>(); long start1 = System.currentTimeMillis(); for(int i=0;i<list.size();i++){ list2.add(list.get(i)); } log.info("單個 for 循環新增 300 w 個,耗時{}",System.currentTimeMillis()-start1); // 批量新增 ArrayList<Integer> list3 = new ArrayList<>(); long start2 = System.currentTimeMillis(); list3.addAll(list); log.info("批量新增 300 w 個,耗時{}",System.currentTimeMillis()-start2); }
```
最后打印出來的日志為:
```
16:52:59.865 [main] INFO demo.one.ArrayListDemo - 單個 for 循環新增 300 w 個,耗時1518 16:52:59.880 [main] INFO demo.one.ArrayListDemo - 批量新增 300 w 個,耗時8
```
可以看到,批量新增方法性能是單個新增方法性能的 189 倍,主要原因在于批量新增,只會擴容一次,大大縮短了運行時間,而單個新增,每次到達擴容閥值時,都會進行擴容,在整個過程中就會不斷的擴容,浪費了很多時間,我們來看下批量新增的源碼:
```
public boolean addAll(Collection<? extends E> c) { Object[] a = c.toArray(); int numNew = a.length; // 確保容量充足,整個過程只會擴容一次 ensureCapacityInternal(size + numNew); // 進行數組的拷貝 System.arraycopy(a, 0, elementData, size, numNew); size += numNew;
return numNew != 0; }
```
以上是 ArrayList 批量新增的演示,我們可以看到,整個批量新增的過程中,只擴容了一次,HashMap 的 putAll 方法也是如此,整個新增過程只會擴容一次,大大縮短了批量新增的時間,提高了性能。
所以如果有人問你當碰到集合批量拷貝,批量新增場景,如何提高新增性能的時候 ,就可以從目標集合初始化方面應答。
這里也提醒了我們,在容器初始化的時候,最好能給容器賦上初始值,這樣可以防止在 put 的過程中不斷的擴容,從而縮短時間,上章 HashSet 的源碼給我們演示了,給 HashMap 賦初始值的公式為:取括號內兩者的最大值(期望的值/0.75+1,默認值 16)。
#### 2.2.2 批量刪除
批量刪除 ArrayList 提供了 removeAll 的方法,HashMap 沒有提供批量刪除的方法,我們一起來看下 removeAll 的源碼實現,是如何提高性能的:
```
// 批量刪除,removeAll 方法底層調用的是 batchRemove 方法 // complement 參數默認是 false,false 的意思是數組中不包含 c 中數據的節點往頭移動 // true 意思是數組中包含 c 中數據的節點往頭移動,這個是根據你要刪除數據和原數組大小的比例來決定的 // 如果你要刪除的數據很多,選擇 false 性能更好,當然 removeAll 方法默認就是 false。 private boolean batchRemove(Collection<?> c, boolean complement) { final Object[] elementData = this.elementData; // r 表示當前循環的位置、w 位置之前都是不需要被刪除的數據,w 位置之后都是需要被刪除的數據 int r = 0, w = 0; boolean modified = false; try { // 從 0 位置開始判斷,當前數組中元素是不是要被刪除的元素,不是的話移到數組頭 for (; r < size; r++)
if (c.contains(elementData[r]) == complement) elementData[w++] = elementData[r]; } finally { // r 和 size 不等,說明在 try 過程中發生了異常,在 r 處斷開 // 把 r 位置之后的數組移動到 w 位置之后(r 位置之后的數組數據都是沒有判斷過的數據,這樣不會影響沒有判斷的數據,判斷過的數據可以被刪除) if (r != size) { System.arraycopy(elementData, r, elementData, w, size - r); w += size - r; } // w != size 說明數組中是有數據需要被刪除的 // 如果 w、size 相等,說明沒有數據需要被刪除 if (w != size) { // w 之后都是需要刪除的數據,賦值為空,幫助 gc。 for (int i = w; i < size; i++) elementData[i] = null; modCount += size - w; size = w; modified = true; } } return modified; }
```
我們看到 ArrayList 在批量刪除時,如果程序執行正常,只有一次 for 循環,如果程序執行異常,才會加一次拷貝,而單個 remove 方法,每次執行的時候都會進行數組的拷貝(當刪除的元素正好是數組最后一個元素時除外),當數組越大,需要刪除的數據越多時,批量刪除的性能會越差,所以在 ArrayList 批量刪除時,強烈建議使用 removeAll 方法進行刪除。
### 2.3 集合的一些坑
1. 當集合的元素是自定義類時,自定義類強制實現 equals 和 hashCode 方法,并且兩個都要實現。
在集合中,除了 TreeMap 和 TreeSet 是通過比較器比較元素大小外,其余的集合類在判斷索引位置和相等時,都會使用到 equals 和 hashCode 方法,這個在之前的源碼解析中,我們有說到,所以當集合的元素是自定義類時,我們強烈建議覆寫 equals 和 hashCode 方法,我們可以直接使用 IDEA 工具覆寫這兩個方法,非常方便;
2. 所有集合類,在 for 循環進行刪除時,如果直接使用集合類的 remove 方法進行刪除,都會快速失敗,報 ConcurrentModificationException 的錯誤,所以在任意循環刪除的場景下,都建議使用迭代器進行刪除;
3. 我們把數組轉化成集合時,常使用 Arrays.asList(array),這個方法有兩個坑,代碼演示坑為:
```
public void testArrayToList(){ Integer[] array = new Integer[]{1,2,3,4,5,6}; List<Integer> list = Arrays.asList(array); // 坑1:修改數組的值,會直接影響原 list log.info("數組被修改之前,集合第一個元素為:{}",list.get(0)); array[0] = 10; log.info("數組被修改之前,集合第一個元素為:{}",list.get(0)); // 坑2:使用 add、remove 等操作 list 的方法時, // 會報 UnsupportedOperationException 異常 list.add(7); }
```
坑 1:數組被修改后,會直接影響到新 List 的值。
坑 2:不能對新 List 進行 add、remove 等操作,否則運行時會報 UnsupportedOperationException 錯誤。
我們來看下 Arrays.asList 的源碼實現,就能知道問題所在了,源碼如下圖:
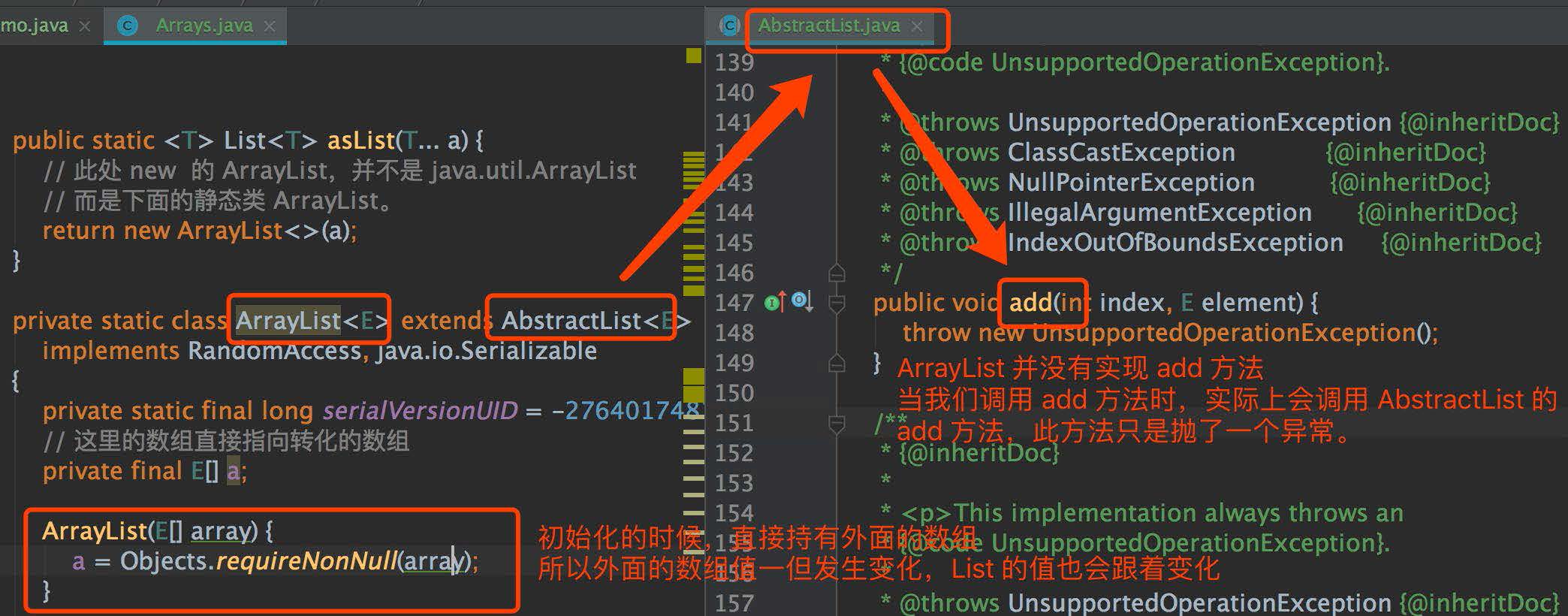
從上圖中,我們可以發現,Arrays.asList 方法返回的 List 并不是 java.util.ArrayList,而是自己內部的一個靜態類,該靜態類直接持有數組的引用,并且沒有實現 add、remove 等方法,這些就是坑 1 和 2 的原因。
4. 集合 List 轉化成數組,我們通常使用 toArray 這個方法,這個方法很危險,稍微不注意,就踩進大坑,我們示例代碼如下:
```
public void testListToArray(){ List<Integer> list = new ArrayList<Integer>(){{ add(1); add(2); add(3); add(4); }}; // 下面這行被注釋的代碼這么寫是無法轉化成數組的,無參 toArray 返回的是 Object[], // 無法向下轉化成 List<Integer>,編譯都無法通過 // List<Integer> list2 = list.toArray(); // 演示有參 toArray 方法,數組大小不夠時,得到數組為 null 情況 Integer[] array0 = new Integer[2]; list.toArray(array0); log.info("toArray 數組大小不夠,array0 數組[0] 值是{},數組[1] 值是
{},",array0[0],array0[1]); // 演示數組初始化大小正好,正好轉化成數組 Integer[] array1 = new Integer[list.size()]; list.toArray(array1); log.info("toArray 數組大小正好,array1 數組[3] 值是{}",array1[3]); // 演示數組初始化大小大于實際所需大小,也可以轉化成數組 Integer[] array2 = new Integer[list.size()+2]; list.toArray(array2); log.info("toArray 數組大小多了,array2 數組[3] 值是{},數組[4] 值是{}",array2[3],array2[4]); }
19:33:07.687 [main] INFO demo.one.ArrayListDemo - toArray 數組大小不夠,array0 數組[0] 值是null,數組[1] 值是null,
19:33:07.697 [main] INFO demo.one.ArrayListDemo - toArray 數組大小正好,array1 數組[3] 值是4
19:33:07.697 [main] INFO demo.one.ArrayListDemo - toArray 數組大小多了,array2 數組[3] 值是4,數組[4] 值是null
```
toArray 的無參方法,無法強轉成具體類型,這個編譯的時候,就會有提醒,我們一般都會去使用帶有參數的 toArray 方法,這時就有一個坑,如果參數數組的大小不夠,這時候返回的數組值竟然是空,上述代碼中的 array0 的返回值就體現了這點,但我們去看 toArray 源碼,發現源碼中返回的是 4 個大小值的數據,返回的并不是空,源碼如下:
```
// List 轉化成數組 public <T> T[] toArray(T[] a) { // 如果數組長度不夠,按照 List 的大小進行拷貝,return 的時候返回的都是正確的數組 if (a.length < size) // Make a new array of a's runtime type, but my contents: return (T[]) Arrays.copyOf(elementData, size, a.getClass()); System.arraycopy(elementData, 0, a, 0, size);
// 數組長度大于 List 大小的,賦值為 null if (a.length > size) a[size] = null; return a; }
```
從源碼中,我們絲毫看不出為什么 array0 的元素值為什么是 null,最后我們去看方法的注釋,發現是這樣子描述的:
> If the list fits in the specified array, it is returned therein. Otherwise, a new array is allocated with the runtime type of the specified array and the size of this list。
翻譯過來的意思就是說:如果返回的數組大小和申明的數組大小一致,那么就會正常返回,否則,一個新數組就會被分配返回。
所以我們在使用有參 toArray 方法時,申明的數組大小一定要大于等于 List 的大小,如果小于的話,你會得到一個空數組。
### 3 總結
本小節,我們詳細描述了集合的線程安全、性能優化和日常工作中一些坑,這些問題我們在工作中經常會碰到,稍不留神就會引發線上故障,面試的時候也經常會通過這些問題,來考察大家的工作經驗,所以閱讀本章時,建議大家自己動手試一試,加深印象。
- 前言
- 第1章 基礎
- 01 開篇詞:為什么學習本專欄
- 02 String、Long 源碼解析和面試題
- 03 Java 常用關鍵字理解
- 04 Arrays、Collections、Objects 常用方法源碼解析
- 第2章 集合
- 05 ArrayList 源碼解析和設計思路
- 06 LinkedList 源碼解析
- 07 List 源碼會問哪些面試題
- 08 HashMap 源碼解析
- 09 TreeMap 和 LinkedHashMap 核心源碼解析
- 10 Map源碼會問哪些面試題
- 11 HashSet、TreeSet 源碼解析
- 12 彰顯細節:看集合源碼對我們實際工作的幫助和應用
- 13 差異對比:集合在 Java 7 和 8 有何不同和改進
- 14 簡化工作:Guava Lists Maps 實際工作運用和源碼
- 第3章 并發集合類
- 15 CopyOnWriteArrayList 源碼解析和設計思路
- 16 ConcurrentHashMap 源碼解析和設計思路
- 17 并發 List、Map源碼面試題
- 18 場景集合:并發 List、Map的應用場景
- 第4章 隊列
- 19 LinkedBlockingQueue 源碼解析
- 20 SynchronousQueue 源碼解析
- 21 DelayQueue 源碼解析
- 22 ArrayBlockingQueue 源碼解析
- 23 隊列在源碼方面的面試題
- 24 舉一反三:隊列在 Java 其它源碼中的應用
- 25 整體設計:隊列設計思想、工作中使用場景
- 26 驚嘆面試官:由淺入深手寫隊列
- 第5章 線程
- 27 Thread 源碼解析
- 28 Future、ExecutorService 源碼解析
- 29 押寶線程源碼面試題
- 第6章 鎖
- 30 AbstractQueuedSynchronizer 源碼解析(上)
- 31 AbstractQueuedSynchronizer 源碼解析(下)
- 32 ReentrantLock 源碼解析
- 33 CountDownLatch、Atomic 等其它源碼解析
- 34 只求問倒:連環相扣系列鎖面試題
- 35 經驗總結:各種鎖在工作中使用場景和細節
- 36 從容不迫:重寫鎖的設計結構和細節
- 第7章 線程池
- 37 ThreadPoolExecutor 源碼解析
- 38 線程池源碼面試題
- 39 經驗總結:不同場景,如何使用線程池
- 40 打動面試官:線程池流程編排中的運用實戰
- 第8章 Lambda 流
- 41 突破難點:如何看 Lambda 源碼
- 42 常用的 Lambda 表達式使用場景解析和應用
- 第9章 其他
- 43 ThreadLocal 源碼解析
- 44 場景實戰:ThreadLocal 在上下文傳值場景下的實踐
- 45 Socket 源碼及面試題
- 46 ServerSocket 源碼及面試題
- 47 工作實戰:Socket 結合線程池的使用
- 第10章 專欄總結
- 48 一起看過的 Java 源碼和面試真題