
## 35 經驗總結:各種鎖在工作中使用場景和細節
## 引導語
本章主要說一說鎖在工作中的使用場景,主要以 synchronized 和 CountDownLatch 為例,會分別描述一下這兩種鎖的使用場景和姿勢。
### 1 synchronized
synchronized 是可重入的排它鎖,和 ReentrantLock 鎖功能相似,任何使用 synchronized 的地方,幾乎都可以使用 ReentrantLock 來代替,兩者最大的相似點就是:可重入 + 排它鎖,兩者的區別主要有這些:
1. ReentrantLock 的功能更加豐富,比如提供了 Condition,可以打斷的加鎖 API、能滿足鎖 + 隊列的復雜場景等等;
2. ReentrantLock 有公平鎖和非公平鎖之分,而 synchronized 都是非公平鎖;
3. 兩者的使用姿勢也不同,ReentrantLock 需要申明,有加鎖和釋放鎖的 API,而 synchronized 會自動對代碼塊進行加鎖釋放鎖的操作,synchronized 使用起來更加方便。
synchronized 和 ReentrantLock 功能相近,所以我們就以 synchronized 舉例。
#### 1.1 共享資源初始化
在分布式的系統中,我們喜歡把一些死的配置資源在項目啟動的時候加鎖到 JVM 內存里面去,這樣請求在拿這些共享配置資源時,就可直接從內存里面拿,不必每次都從數據庫中拿,減少了時間開銷。
一般這樣的共享資源有:死的業務流程配置 + 死的業務規則配置。
共享資源初始化的步驟一般為:項目啟動 -> 觸發初始化動作 ->單線程從數據庫中撈取數據 -> 組裝成我們需要的數據結構 -> 放到 JVM 內存中。
在項目啟動時,為了防止共享資源被多次加載,我們往往會加上排它鎖,讓一個線程加載共享資源完成之后,另外一個線程才能繼續加載,此時的排它鎖我們可以選擇 synchronized 或者 ReentrantLock,我們以 synchronized 為例,寫了 mock 的代碼,如下:
```
// 共享資源 private static final Map<String, String> SHARED_MAP = Maps.newConcurrentMap(); // 有無初始化完成的標志位 private static boolean loaded = false; /** * 初始化共享資源 */ @PostConstruct public void init(){ if(loaded){ return; } synchronized (this){ // 再次 check if(loaded){ return; }
log.info("SynchronizedDemo init begin"); // 從數據庫中撈取數據,組裝成 SHARED_MAP 的數據格式 loaded = true; log.info("SynchronizedDemo init end"); } }
```
不知道大家有沒有從上述代碼中發現 @PostConstruct 注解,@PostConstruct 注解的作用是在 Spring 容器初始化時,再執行該注解打上的方法,也就是說上圖說的 init 方法觸發的時機,是在 Spring 容器啟動的時候。
大家可以下載演示代碼,找到 DemoApplication 啟動文件,在 DemoApplication 文件上右擊 run,就可以啟動整個 Spring Boot 項目,在 init 方法上打上斷點就可以調試了。
我們在代碼中使用了 synchronized 來保證同一時刻,只有一個線程可以執行初始化共享資源的操作,并且我們加了一個共享資源加載完成的標識位(loaded),來判斷是否加載完成了,如果加載完成,那么其它加載線程直接返回。
如果把 synchronized 換成 ReentrantLock 也是一樣的實現,只不過需要顯示的使用 ReentrantLock 的 API 進行加鎖和釋放鎖,使用 ReentrantLock 有一點需要注意的是,我們需要在 try 方法塊中加鎖,在 finally 方法塊中釋放鎖,這樣保證即使 try 中加鎖后發生異常,在 finally 中也可以正確的釋放鎖。
有的同學可能會問,不是可以直接使用了 ConcurrentHashMap 么,為什么還需要加鎖呢?的確 ConcurrentHashMap 是線程安全的,但它只能夠保證 Map 內部數據操作時的線程安全,是無法保證多線程情況下,查詢數據庫并組裝數據的整個動作只執行一次的,我們加 synchronized 鎖住的是整個操作,保證整個操作只執行一次。
完整 demo 見 SynchronizedDemo。
### 2 CountDownLatch
#### 2.1 場景
1:小明在淘寶上買了一個商品,覺得不好,把這個商品退掉(商品還沒有發貨,只退錢),我們叫做單商品退款,單商品退款在后臺系統中運行時,整體耗時 30 毫秒。
2:雙 11,小明在淘寶上買了 40 個商品,生成了同一個訂單(實際可能會生成多個訂單,為了方便描述,我們說成一個),第二天小明發現其中 30 個商品是自己沖動消費的,需要把 30 個商品一起退掉。
#### 2.2 實現
此時后臺只有單商品退款的功能,沒有批量商品退款的功能(30 個商品一次退我們稱為批量),為了快速實現這個功能,同學 A 按照這樣的方案做的:for 循環調用 30 次單商品退款的接口,在 qa 環境測試的時候發現,如果要退款 30 個商品的話,需要耗時:30 * 30 = 900 毫秒,再加上其它的邏輯,退款 30 個商品差不多需要 1 秒了,這個耗時其實算很久了,當時同學 A 提出了這個問題,希望大家幫忙看看如何優化整個場景的耗時。
同學 B 當時就提出,你可以使用線程池進行執行呀,把任務都提交到線程池里面去,假如機器的 CPU 是 4 核的,最多同時能有 4 個單商品退款可以同時執行,同學 A 覺得很有道理,于是準
備修改方案,為了便于理解,我們把兩個方案都畫出來,對比一下:
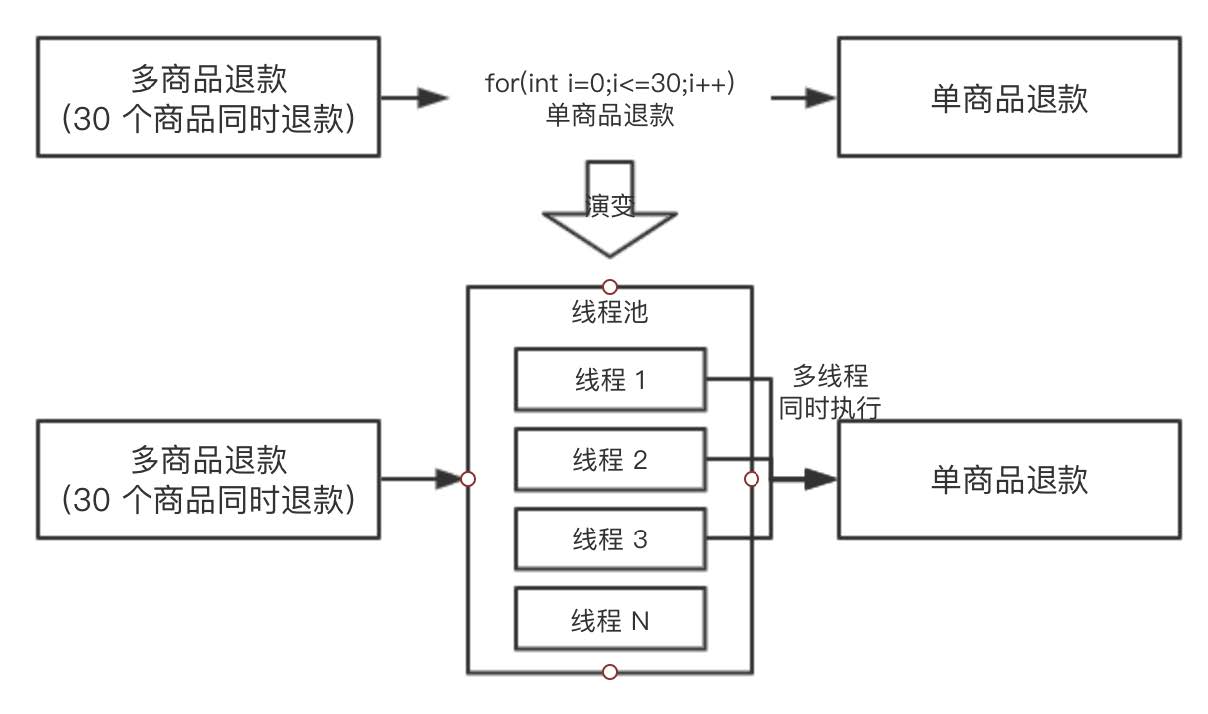
同學 A 于是就按照演變的方案去寫代碼了,過了一天,拋出了一個問題:向線程池提交了 30 個任務后,主線程如何等待 30 個任務都執行完成呢?因為主線程需要收集 30 個子任務的執行情況,并匯總返回給前端。
大家可以先不往下看,自己先思考一下,我們前幾章說的那種鎖可以幫助解決這個問題?
CountDownLatch 可以的,CountDownLatch 具有這種功能,讓主線程去等待子任務全部執行完成之后才繼續執行。
此時還有一個關鍵,我們需要知道子線程執行的結果,所以我們用 Runnable 作為線程任務就不行了,因為 Runnable 是沒有返回值的,我們需要選擇 Callable 作為任務。
我們寫了一個 demo,首先我們來看一下單個商品退款的代碼:
```
// 單商品退款,耗時 30 毫秒,退款成功返回 true,失敗返回 false @Slf4j public class RefundDemo { /**
* 根據商品 ID 進行退款 * @param itemId * @return */ public boolean refundByItem(Long itemId) { try { // 線程沉睡 30 毫秒,模擬單個商品退款過程 Thread.sleep(30); log.info("refund success,itemId is {}", itemId); return true; } catch (Exception e) { log.error("refundByItemError,itemId is {}", itemId); return false; } } }
```
接著我們看下 30 個商品的批量退款,代碼如下:
```
@Slf4j public class BatchRefundDemo { // 定義線程池 public static final ExecutorService EXECUTOR_SERVICE = new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>(20)); @Test public void batchRefund() throws InterruptedException { // state 初始化為 30 CountDownLatch countDownLatch = new CountDownLatch(30); RefundDemo refundDemo = new RefundDemo(); // 準備 30 個商品 List<Long> items = Lists.newArrayListWithCapacity(30);
for (int i = 0; i < 30; i++) { items.add(Long.valueOf(i+"")); } // 準備開始批量退款 List<Future> futures = Lists.newArrayListWithCapacity(30); for (Long item : items) { // 使用 Callable,因為我們需要等到返回值 Future<Boolean> future = EXECUTOR_SERVICE.submit(new Callable<Boolean>() { @Override public Boolean call() throws Exception { boolean result = refundDemo.refundByItem(item); // 每個子線程都會執行 countDown,使 state -1 ,但只有最后一個才能真的喚醒主線程 countDownLatch.countDown(); return result; } }); // 收集批量退款的結果 futures.add(future); } log.info("30 個商品已經在退款中"); // 使主線程阻塞,一直等待 30 個商品都退款完成,才能繼續執行 countDownLatch.await(); log.info("30 個商品已經退款完成"); // 拿到所有結果進行分析 List<Boolean> result = futures.stream().map(fu-> { try { // get 的超時時間設置的是 1 毫秒,是為了說明此時所有的子線程都已經執行完成了 return (Boolean) fu.get(1,TimeUnit.MILLISECONDS); } catch (InterruptedException e) {
e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } catch (TimeoutException e) { e.printStackTrace(); } return false; }).collect(Collectors.toList()); // 打印結果統計 long success = result.stream().filter(r->r.equals(true)).count(); log.info("執行結果成功{},失敗{}",success,result.size()-success); } }
```
上述代碼只是大概的底層思路,真實的項目會在此思路之上加上請求分組,超時打斷等等優化措施。
我們來看一下執行的結果:
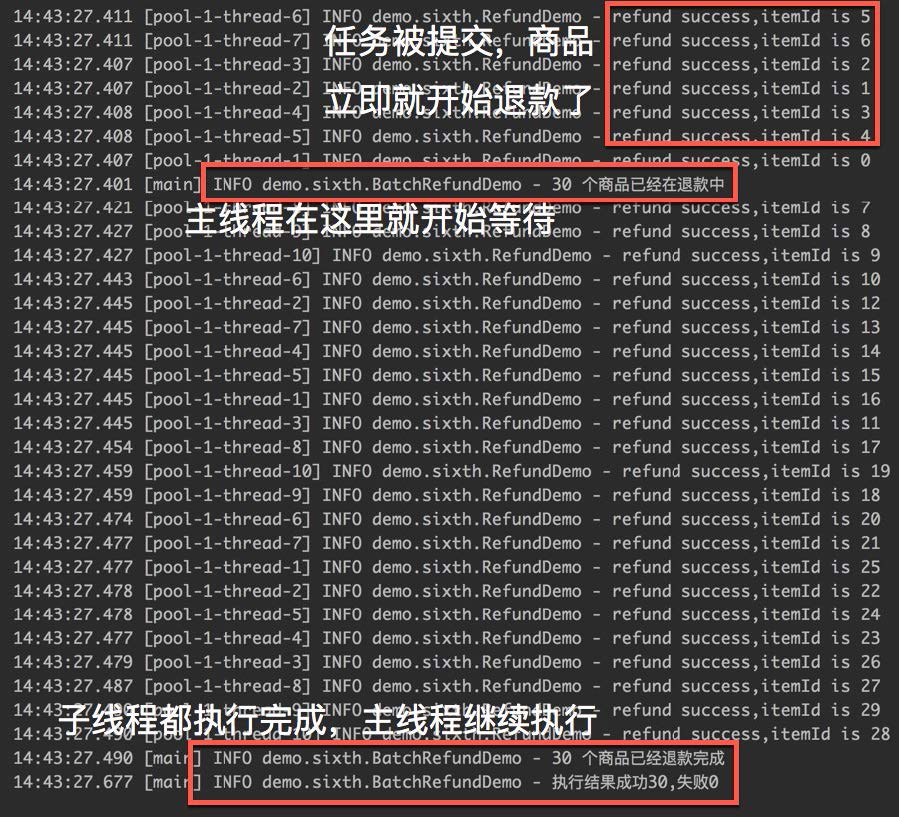
從執行的截圖中,我們可以明顯的看到 CountDownLatch 已經發揮出了作用,主線程會一直等到 30 個商品的退款結果之后才會繼續執行。
接著我們做了一個不嚴謹的實驗(把以上代碼執行很多次,求耗時平均值),通過以上代碼,30 個商品退款完成之后,整體耗時大概在 200 毫秒左右。
而通過 for 循環單商品進行退款,大概耗時在 1 秒左右,前后性能相差 5 倍左右,for 循環退款的代碼如下:
```
long begin1 = System.currentTimeMillis(); for (Long item : items) { refundDemo.refundByItem(item);
} log.info("for 循環單個退款耗時{}",System.currentTimeMillis()-begin1);
```
性能的巨大提升是線程池 + 鎖兩者結合的功勞。
### 3 總結
本章舉了實際工作中的兩個小案列,看到了 CountDownLatch 和 synchronized(ReentrantLock) 是如何結合實際需求進行落地的,特別是 CountDownLatch 的案列,使用線程池 + 鎖結合的方式大大提高了生產效率,所以在工作中如果你也遇到相似的場景,可以毫不猶豫地用起來。
- 前言
- 第1章 基礎
- 01 開篇詞:為什么學習本專欄
- 02 String、Long 源碼解析和面試題
- 03 Java 常用關鍵字理解
- 04 Arrays、Collections、Objects 常用方法源碼解析
- 第2章 集合
- 05 ArrayList 源碼解析和設計思路
- 06 LinkedList 源碼解析
- 07 List 源碼會問哪些面試題
- 08 HashMap 源碼解析
- 09 TreeMap 和 LinkedHashMap 核心源碼解析
- 10 Map源碼會問哪些面試題
- 11 HashSet、TreeSet 源碼解析
- 12 彰顯細節:看集合源碼對我們實際工作的幫助和應用
- 13 差異對比:集合在 Java 7 和 8 有何不同和改進
- 14 簡化工作:Guava Lists Maps 實際工作運用和源碼
- 第3章 并發集合類
- 15 CopyOnWriteArrayList 源碼解析和設計思路
- 16 ConcurrentHashMap 源碼解析和設計思路
- 17 并發 List、Map源碼面試題
- 18 場景集合:并發 List、Map的應用場景
- 第4章 隊列
- 19 LinkedBlockingQueue 源碼解析
- 20 SynchronousQueue 源碼解析
- 21 DelayQueue 源碼解析
- 22 ArrayBlockingQueue 源碼解析
- 23 隊列在源碼方面的面試題
- 24 舉一反三:隊列在 Java 其它源碼中的應用
- 25 整體設計:隊列設計思想、工作中使用場景
- 26 驚嘆面試官:由淺入深手寫隊列
- 第5章 線程
- 27 Thread 源碼解析
- 28 Future、ExecutorService 源碼解析
- 29 押寶線程源碼面試題
- 第6章 鎖
- 30 AbstractQueuedSynchronizer 源碼解析(上)
- 31 AbstractQueuedSynchronizer 源碼解析(下)
- 32 ReentrantLock 源碼解析
- 33 CountDownLatch、Atomic 等其它源碼解析
- 34 只求問倒:連環相扣系列鎖面試題
- 35 經驗總結:各種鎖在工作中使用場景和細節
- 36 從容不迫:重寫鎖的設計結構和細節
- 第7章 線程池
- 37 ThreadPoolExecutor 源碼解析
- 38 線程池源碼面試題
- 39 經驗總結:不同場景,如何使用線程池
- 40 打動面試官:線程池流程編排中的運用實戰
- 第8章 Lambda 流
- 41 突破難點:如何看 Lambda 源碼
- 42 常用的 Lambda 表達式使用場景解析和應用
- 第9章 其他
- 43 ThreadLocal 源碼解析
- 44 場景實戰:ThreadLocal 在上下文傳值場景下的實踐
- 45 Socket 源碼及面試題
- 46 ServerSocket 源碼及面試題
- 47 工作實戰:Socket 結合線程池的使用
- 第10章 專欄總結
- 48 一起看過的 Java 源碼和面試真題